阿丹:
查阅了很多资料了解到,使用了spring-boot中整合的kafka的使用是被封装好的。也就是说这些使用其实和在linux中的使用kafka代码的使用其实没有太大关系。但是逻辑是一样的。这点要注意!
使用spring-boot整合kafka
1、导入依赖
核心配置为:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>如果在下面规定了spring-boot的版本那么就不需要再使用版本号,如果没有的话就需要规定版本号。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<!--配置文件报错问题-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
</dependencies>2、写入配置
#服务端口号
server:
port: 8025
spring:
main:
allow-circular-references: true
application:
name: producer
kafka:
bootstrap-servers: kafka的ip地址:9092
producer:
# 发生错误后,消息重发的次数。
retries: 1
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
3、生产者
将发送封装为一个工具类
public void send(Object obj){
String obj2String = JSON.toJSONString(obj);
log.info("准备发送消息为:{}",obj2String);
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj2String);
//回调
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable ex) {
//发送失败的处理
log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + ex.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> result) {
//成功的处理
log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + result.toString());
}
});4、消费者
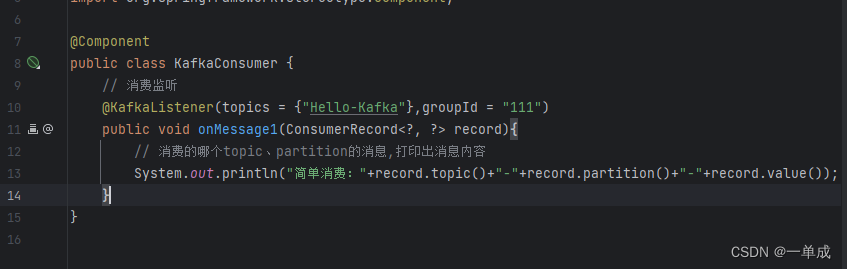
如果需要使用多线程来监听的话使用这个策略。
@KafkaListener(topics = "Hello-Kafka", groupId = "group1")
public void onMessage1(ConsumerRecord<?, ?> record) {
// 消息处理逻辑
}
@KafkaListener(topics = "Hello-Kafka", groupId = "group2")
public void onMessage2(ConsumerRecord<?, ?> record) {
// 消息处理逻辑
}
以上就可以简单实现一个kafka的监听消费。



![java八股文面试[JVM]——类加载器](https://img-blog.csdnimg.cn/7a478168f1c649029829e68945891a2c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcXFfMzkwOTM0NzQ=,size_20,color_FFFFFF,t_70,g_se,x_16)