如果像 ChatGPT 这样的大模型人工智能领域最热门的东西,那么世界模型就是旗帜。
历史上三位最有影响力的人工智能研究人员中的两位 Yann LeCun 和 Yoshua Bengio 被誉为通往人工智能超级智能的最有可能的途径,他们代表了人工智能的愿景,即人工智能不通过蛮力或死记硬背(如 ChatGPT)来了解我们的世界,而是通过形成它的抽象表征,就像人类思考一样。
在这个叙述中,Meta 构建的基于图像的联合嵌入预测架构(I-JEPA) 成为实现这一愿景的第一个切实成功。
它需要的资源少了十倍,而且不需要人为的技巧来帮助机器理解我们这个世界最简单的概念,让我们一睹人工智能以人类方式学习的未来。
关于 GPT-4 及其成为 AGI(通用人工智能)的第一个先驱的潜力,或者超级智能、有感知力的 AI 生命在我们的世界诞生的时刻,人们已经讨论了很多。
但 GPT-4 到底有多智能呢?
Meta 首席科学家 Yann LeCun 表示,“还不如狗”。
但是,一个能够完美模仿莎士比亚的模特怎么会被认为是愚蠢的呢?
例如自动驾驶
想想学习驾驶汽车。
平均而言,一个人需要大约 20 个小时的时间才能学会正确地做这件事。
而自动驾驶系统需要数千小时的训练和数十亿个数据点,其驾驶能力却逊色于人类。
因此,我们人类如何以比我们最先进的模型更有效的方式学习?
其原因可能是世界模型,这一理论最近在科学界越来越受欢迎。
世界模型是人脑根据世界创建的抽象表示,以帮助人类互动,并基本上在其环境中生存。
这些世界模型有一个关键概念:它们能够预测不可预见的事件,以帮助推动我们的行动并最大限度地减少伤害或死亡的机会。
换句话说,它们被假设为我们所说的“常识”,这种感觉可以帮助我们思考在生活的每一步中什么决定是最好的。
如果说像 ChatGPT 这样的大模型有什么明确的事情的话,那就是,截至今天,他们完全缺乏常识。
狗会向你证明原因。
狗和GPT
将 ChatGPT 与 Yann 所做的狗进行比较,我们可以清楚地了解学习方法有多么不同。
例如,一只狗知道,就生存而言,从三楼阳台跳下并不是最好的主意,尽管那只狗从未或永远不会经历过从这样的高度跳下的感觉。
然而,要训练人工智能机器人,你必须引诱它跳跃,让它明白,为了保持其完整性,它必须避免从高处跳下。
然而,狗就像人类一样,必须面对生活中的决定,没有尝试的可能性,没有犯错的余地。
在这种情况下,常识就会发挥作用,通过告诉你“如果你跳下去,你就看不到第二天”来消除不确定性,从而挽救局面。
但这实际上意味着什么?
很简单,与当今最先进的模型不同,我们不需要通过反复试验来学习所有内容。
事实上,我们的很多学习都来自于对世界的片面观察。
最能证明这一点的就是我们年轻的自己,婴儿。
从观察中暗示原因
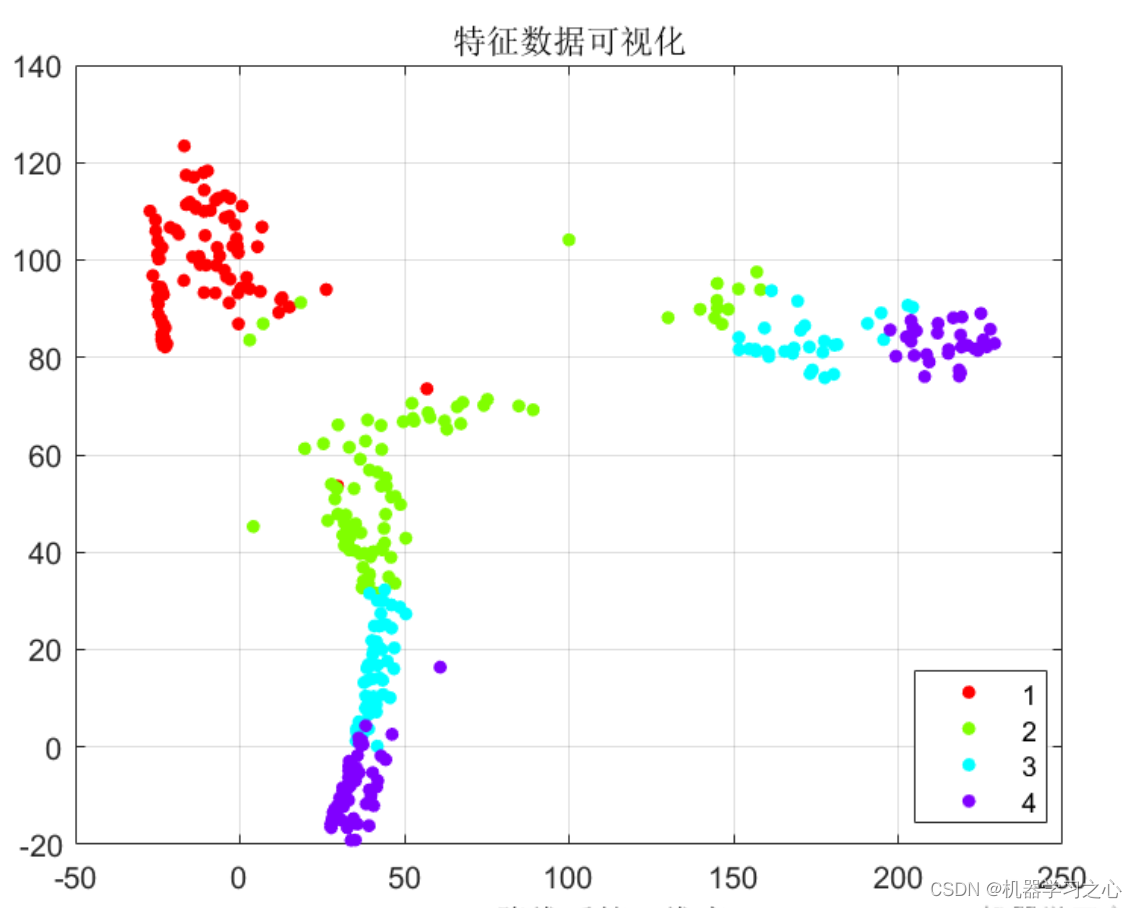
下图描绘了婴儿学习一系列人类基本概念所需的平均时间:

正如 Yann 在他关于该主题的第一篇论文中所解释的那样,上图表明婴儿通常在什么年龄获得有关世界如何运作的各种概念。
它与抽象概念(例如物体受到重力和惯性的事实)是在不抽象的概念(例如物体持久性和物体分配到广泛类别)之上获得的想法是一致的。
这里的关键概念是,大部分知识主要是通过观察获得的,几乎没有直接干预,特别是在最初的几周和几个月。
因此,我们可以清楚地了解当前的最先进的人工智能所缺少的是什么:通过观察进行有效学习的能力,使其能够扎根于我们的世界,并帮助它克服统治世界的不确定性。
通俗地说,为人工智能创建一个世界模型就是赋予它常识。
那么,Meta 打算如何赋予人工智能最强大的力量呢?
人工世界模型
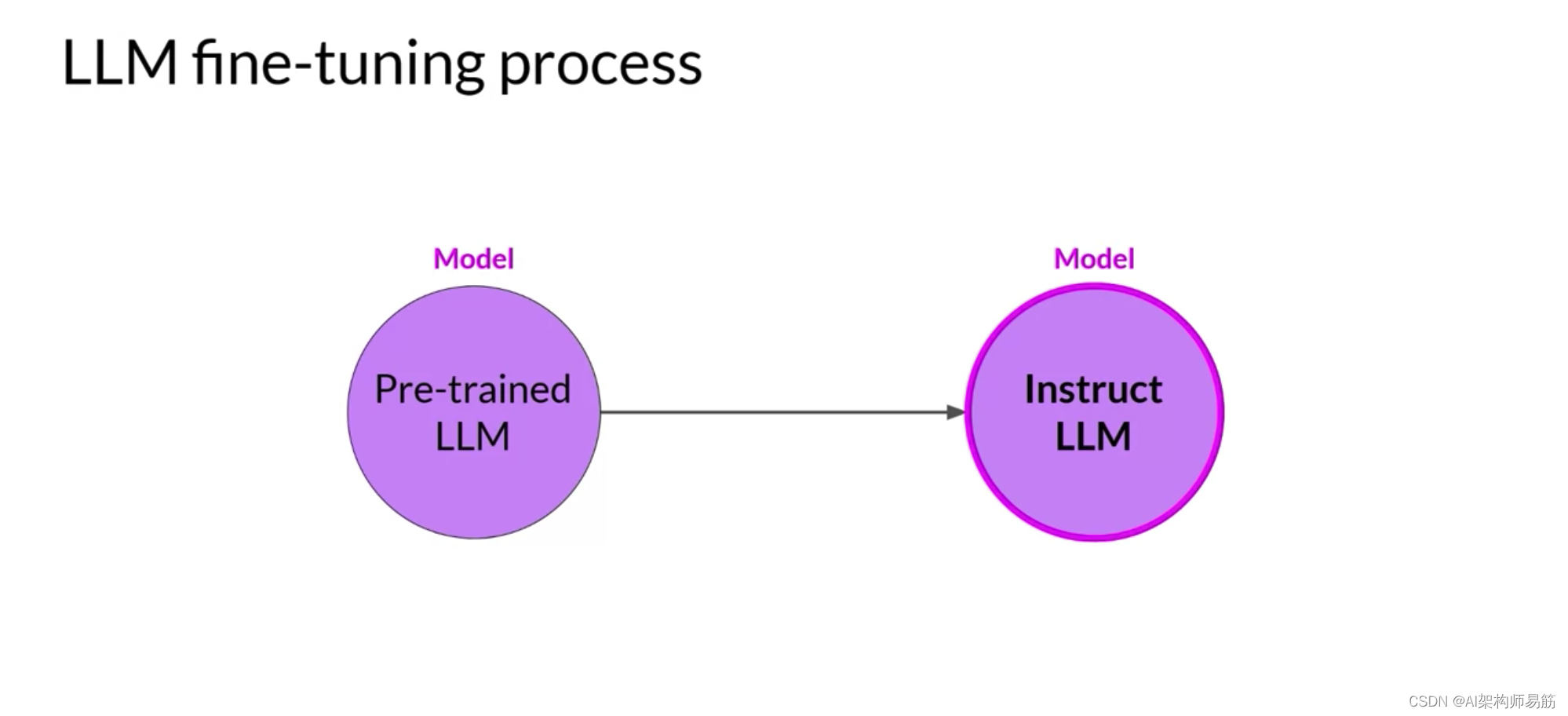
如果你问 Meta 的首席人工智能科学家,自主智能会是什么样子,他会给你看下图:

资料来源:Yann LeCun
我不会详细介绍,但基本上您需要了解的是世界模型的作用有两个:
- 估计感知模块未提供的有关世界状态的缺失信息(从世界接收的传感数据作为输入)
- 预测世界可能的未来状态
换句话说,它是帮助人工智能系统(无论是否是大模型)做出更好决策的必要元素,这些决策假设世界存在模型需要解决的不确定结果才能生存。
你的基于 ChatGPT 的系统可能可以像大多数人类一样书写,但它也能够做出有史以来最愚蠢的假设,仅仅是因为它们天生不了解我们的世界;他们只是学会了模仿语言。
例如,如果我们以 MidJourney 为例,直到最近,这种文本到图像的模型在人手方面都存在严重问题,因为它几乎总是在绘制的每只手上添加/缺少随机数量的手指。
原因是显而易见的。
尽管它能够生成令人印象深刻的图画和照片,但它并不自然地理解它在画什么。
这是一个矛盾的范例,人工智能能够以最佳水平绘制事物,但绝对无法理解它所绘制的内容。
这就是你了解人生的方式吗?当然不是。
您只是了解了手是什么,您已经学习了手的抽象表示,这足以让我们识别它们,并且知道它们通常有五个手指。
然而,机器需要分析图像中的每个像素才能得出结论,在所有这数千个像素中,其中一定数量的像素以描绘手的方式分组,而手通常有五个手指。
因此,为了避免像手指问题这样的过多错误,这些模型被输入了大量的数据,以至于它们成为了惊人的模仿者。
但这里显然存在知识空白,因为它是通过死记硬背来学习的。
但 I-JEPA 是第一个真正类似于我们学习方式的模型。
I-JEPA模型
I-JEPA 是让人工智能学习我们世界的复杂、抽象表征的首次尝试。
只需很少的训练(就像人类需要的那样),人工智能模型应该能够在任何可能的情况下看到狗,并且仍然能够理解那是一只狗。
为此,I-JEPA 具有以下架构:
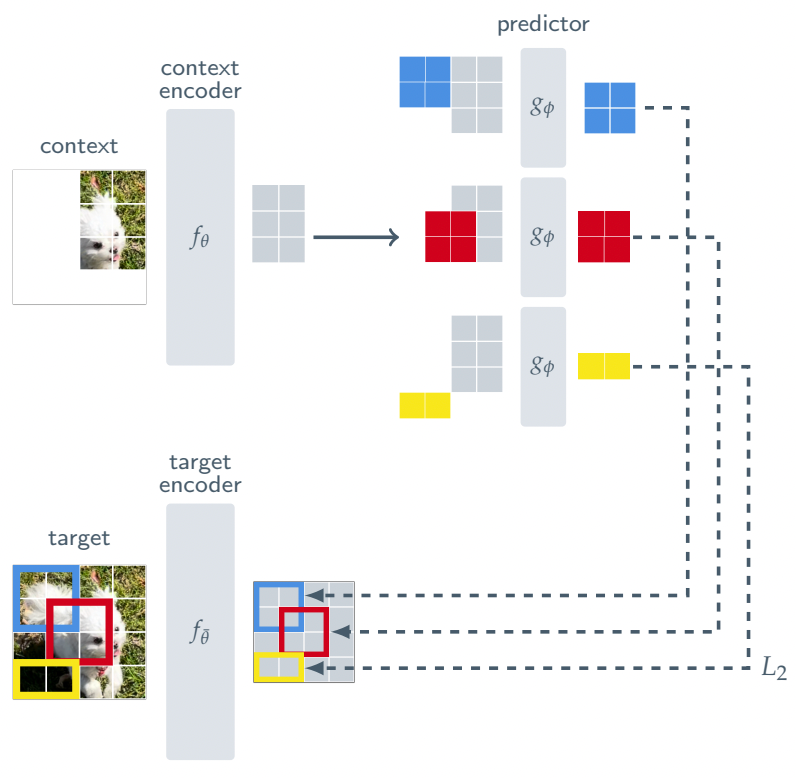
I-JEPA不像今天的生成模型那样尝试重建图像中的每个像素,迫使它们在训练过程中仔细检查每个像素,而是只查看图像的一小部分,并且经过训练来预测图像中其他块的表示。图像(上面用颜色表示)。
这样,就不必一遍又一遍地重建完整的图像来隐藏越来越深的理解不足,而是可以防止模型看到它必须学习的对象的完整观察结果,迫使它真正理解它们背后的语义。
更重要的是,I-JEPA 可以预测这些补丁的缺失表示。通俗地说,这意味着它需要避免不必要的细节,专注于理解图像中真正重要的元素,否则就会失败。
更重要的是,通过将模型暴露在部分可观察的现实视图中,您可以训练这些模型来处理不确定性。
例如,如果你看到你的狗的脸潜伏在你卧室的门外,你不需要看到整只狗就知道它在那里,因为即使你只能看到它的一半脸,你已经开发出的抽象表示狗的身体其他部分也在那里就足够了。
如果你训练一个模型来检测狗,但你没有在数据集中包含数千张被裁剪的狗的图像,那么它会严重失败。
即使是它们,结果最多也还不错,因为对于该模型来说,那不是狗,因为它们的语义表示不够好,尽管它显然是足够好的。
抽象即智能
这种世界模型的想法在我心中不断成长。
毫无疑问,训练人工智能系统通过处理部分观察产生的不确定性来真正理解他们所看到的东西是我们追求通用人工智能不可否认的下一步。
此外,I-JEPA 基本上击败了业内几乎所有其他图像分类模型,其训练要求是其十倍,这一事实也有所帮助。
但这里的关键不是结果,而是 Meta 试图通过 I-JEPA 实现的愿景。
由于 I-JEPA 对它所看到的内容有了更深入的理解,它不需要数百万张图像和训练时间来理解它所看到的内容……就像人类一样。
我不认为大模型、通过阅读描述世界的文本来了解我们的世界的模型是通往超级智能的道路。
但如果我们设法将世界模型嵌入到大模型中……那就是另一回事了。
Meta 和 I-JEPA 开始引领潮流。