Hash-散列类型:H
为什么选择Hash?
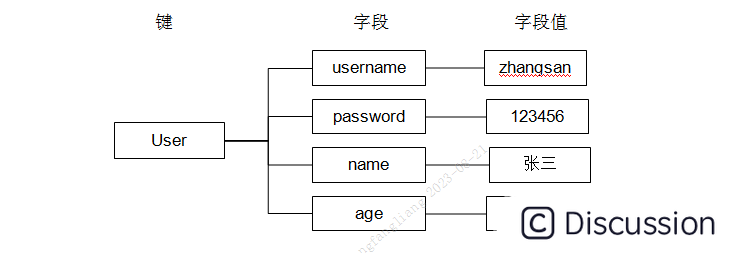
假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下:
保存、更新:
User对象 -> json(string) -> redis
如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,因为只需要更新age属性,使用String却要把User对象全量传输然后覆盖更新。
下边讲的hash可以很好的解决这个问题。
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。如下:
赋值: HSET key field1 value1
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0。
redis 一次只设置一个字段值 语法:HSET key field value 127.0.0.1:6379> hset user username zhangsan (integer) 1
赋值: HMSET key field1 value1 field2 value2
redis 一次可以设置多个字段值 语法:HMSET key field value [field value ...] 127.0.0.1:6379> hmset user age 20 username lisi OK
redis 当字段不存在时赋值,类似HSET,区别在于如果字段已存在,该命令不执行任何操作 如果user中没有age字段则设置age值为30,否则不做任何操作 语法:HSETNX key field value 127.0.0.1:6379> hsetnx user age 30 (integer) 0
取值 :HGET key field
redis 一次只能获取一个字段值 语法:HGET key field 127.0.0.1:6379> hget user username "zhangsan"
取值 :HMGET key field1 field2
redis 一次可以获取多个字段值 语法:HMGET key field [field ...] 127.0.0.1:6379> hmget user age username 1) "20" 2) "lisi" 获取所有字段值 语法:HGETALL key 127.0.0.1:6379> hgetall user 1) "age" 2) "20" 3) "username" 4) "lisi"
删除字段:HDEL key field1 field2
可以删除一个或多个字段,返回值是被删除的字段个数
redis 语法:HDEL key field [field ...] 127.0.0.1:6379> hdel user age (integer) 1 127.0.0.1:6379> hdel user age name (integer) 0 127.0.0.1:6379> hdel user age username (integer) 1
增加数字:HINCRBY key field increment
redis 语法:HINCRBY key field increment 127.0.0.1:6379> hincrby user age 2 将用户的年龄加2 (integer) 22 127.0.0.1:6379> hget user age 获取用户的年龄 "22“
判断属性是否存在HEXISTS key field
redis 语法:HEXISTS key field 127.0.0.1:6379> hexists user age 查看user中是否有age字段 (integer) 1 127.0.0.1:6379> hexists user name 查看user中是否有name字段 (integer) 0
只获取key的字段名HKEYS key
redis 语法: HKEYS key 127.0.0.1:6379> hmset user age 20 name lisi OK 127.0.0.1:6379> hkeys user 1) "age" 2) "name" 127.0.0.1:6379> hvals user 1) "20" 2) "lisi"
只获取key字段值HVALS key
redis 语法: HVALS key 127.0.0.1:6379> hmset user age 20 name lisi OK 127.0.0.1:6379> hkeys user 1) "age" 2) "name" 127.0.0.1:6379> hvals user 1) "20" 2) "lisi"
获取字段数量:HLEN key
redis 语法:HLEN key 127.0.0.1:6379> hlen user (integer) 2
应用-购物车存储商品信息
商品字段
【商品id、商品名称、商品描述、商品库存、商品好评】
定义商品信息的key
商品1001的信息在 Redis中的key为:[items:1001]
缓存商品信息
获取商品信息
redis 192.168.101.3:7003> HGET items:1001 id "3" 192.168.101.3:7003> HGETALL items:1001 1) "id" 2) "3" 3) "name" 4) "apple" 5) "price" 6) "999.9"
应用-分布式锁可重入特性
redisson分布式锁框架选择使用hash作为分布式锁的数据结构。
大key是我们要加锁的业务数据,比如订单号。
小key使用的是我们加锁的机器id+线程id。
value就是可重入的次数。
对应的命令如下:
redis HSET 订单号 6f3d66cd176c:Thread-1 1
底层数据结构-压缩列表和哈希表
压缩列表转化成hash表条件
创建新列表时 redis 默认使用redisencodingziplist编码,当以下任意一个条件被满足时, 列表会被转换成 redisencodinglinkedlist 编码:
- 试图往列表新添加一个字符串值,且这个字符串的长度超过 server.listmaxziplist_value :默认值为 64字节。
- ziplist 包含的节点超过server.listmaxziplist_entries:默认值为 512
Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢?
其实,Hash类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。
这两个阈值分别对应以下两个配置项:
hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数 512。
hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度 64字节。
注意:这两个条件是可以修改的,在 redis.conf 中:
redis list-max-ziplist-value 64 list-max-ziplist-entries 512
如果我们往 Hash 集合中写入的元素个数超过了 hash-max-ziplist-entries ,或者写入的单个元素大小超过了 hash-max-ziplist-value,Redis就会自动把Hash类型的实现结构由压缩列表转为哈希表。
一旦从压缩列表转为了哈希表,Hash 类型就会一直用哈希表进行保存,而不会再转回压缩列表了。在节省内存空间方面,哈希表就没有压缩列表那么高效了。