PyTorch深度学习实战(13)——可视化神经网络中间层输出
- 0. 前言
- 1. 可视化特征学习的结果
- 2. 可视化第一个卷积层的输出
- 3. 可视化不同网络层的特征图
- 小结
- 系列链接
0. 前言
随着深度学习的快速发展,神经网络已成为解决各种复杂任务的重要工具。然而,神经网络的黑盒特性使得我们对其内部运作过程和学到的表示仍然不够了解。为了更好地理解神经网络的工作原理,研究者们提出了各种可视化方法来探索网络中间层的输出。特征学习是神经网络最关键的一项任务之一,神经网络通过逐层的变换和学习,能够从原始数据中提取出高级、抽象的特征表示,这些特征表示能够捕捉到数据中的重要信息。然而,这些中间层的输出对于人类来说是难以理解的,因为它们是高维、抽象的向量。
通过可视化特征学习的结果,我们可以以直观的方式观察网络在处理数据时发生的变化,利用可视化方法能够探索中间层的输出,理解网络如何对输入数据进行编码和转换。我们可以通过观察特征图、梯度分布、降维可视化等手段来揭示网络中学到的有用模式、边缘检测、颜色分布等。在本节中,我们将探索神经网络究竟学到了什么,使用卷积神经网络 (Convolutional Neural Networks, CNN) 对包含 X 和 O 图像的数据集进行分类,并检查网络层输出了解激活结果。
1. 可视化特征学习的结果
可视化特征学习的结果具有多方面的应用。首先,可视化可以帮助我们评估和调整神经网络的设计,通过观察特征图和梯度分布,可以判断网络是否学到了有效的特征表示,从而优化网络结构和参数设置;其次,可视化还可以帮助我们解释网络的预测结果,通过观察中间层的输出,我们可以了解网络对不同类别或输入样本的响应模式,解释其预测的依据;最后,通过观察网络学到的特征表示,可以借鉴其中的思想,设计更好的手工特征或特征提取算法。
(1) 为了可视化特征学习的结果,我们将使用包含 X 和 O 图像的数据集,相关数据集可以在 gitcode 链接中下载,下载完成后进行解压,解压完成后,可以看到文件夹中的图像如下:

图像的类别可以从图像的名称中获得,其中图像名称的第一个字符指定图像所属的类别。
(2) 导入所需库:
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.optim import SGD, Adam
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import numpy as np, cv2
import matplotlib.pyplot as plt
from glob import glob
from imgaug import augmenters as iaa
(3) 定义获取数据的类,确保图像形状已调整为 28 x 28,并且目标类别转换为数值形式。
定义图像增强方法,将图像形状调整为 28 x 28:
tfm = iaa.Sequential(iaa.Resize(28))
定义一个将文件夹路径作为输入的类,并在 __init__ 方法中遍历该路径中的文件:
class XO(Dataset):
def __init__(self, folder):
self.files = glob(folder)
定义 __len__ 方法,返回数据集的长度:
def __len__(self):
return len(self.files)
定义 __getitem__ 方法获取索引,返回该索引处存在的文件,读取图像文件并对图像执行增强。在这里并未使用 collate_fn,因为小数据集不会显着影响训练时间:
def __getitem__(self, ix):
f = self.files[ix]
im = tfm.augment_image(cv2.imread(f)[:,:,0])
在图像形状(每个图像的形状为 28 x 28 )前创建通道尺寸:
im = im[None]
根据文件名中的字符 “/” 和 “@” 之间的字符确定每个图像的类别:
cl = f.split('/')[-1].split('@')[0] == 'x'
最后,返回图像及其对应的类别:
return torch.tensor(1 - im/255).to(device).float(), torch.tensor([cl]).float().to(device)
(4) 显示图像样本,通过上述定义的类提取图像及其对应的类:
data = XO('images/*')
根据获得的数据集绘制图像样本:
R, C = 7,7
fig, ax = plt.subplots(R, C, figsize=(5,5))
for label_class, plot_row in enumerate(ax):
for plot_cell in plot_row:
plot_cell.grid(False); plot_cell.axis('off')
ix = np.random.choice(1000)
im, label = data[ix]
plot_cell.imshow(im[0].cpu(), cmap='gray')
plt.tight_layout()
plt.show()

(5) 定义模型架构、损失函数和优化器:
from torch.optim import SGD, Adam
def get_model():
model = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Flatten(),
nn.Linear(3200, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
).to(device)
loss_fn = nn.BCELoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
由于是二分类问题,此处使用二元交叉熵损失 (nn.BCELoss()),打印模型摘要:
from torchsummary import summary
model, loss_fn, optimizer = get_model()
"""
summary(model, input_size=(1,28,28))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 26, 26] 640
MaxPool2d-2 [-1, 64, 13, 13] 0
ReLU-3 [-1, 64, 13, 13] 0
Conv2d-4 [-1, 128, 11, 11] 73,856
MaxPool2d-5 [-1, 128, 5, 5] 0
ReLU-6 [-1, 128, 5, 5] 0
Flatten-7 [-1, 3200] 0
Linear-8 [-1, 256] 819,456
ReLU-9 [-1, 256] 0
Linear-10 [-1, 1] 257
Sigmoid-11 [-1, 1] 0
================================================================
Total params: 894,209
Trainable params: 894,209
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.69
Params size (MB): 3.41
Estimated Total Size (MB): 4.10
"""
----------------------------------------------------------------
(6) 定义用于批训练的函数,该函数使用图像及其类作为输入,并在对给定的批数据上执行反向传播后返回其损失值和准确率:
def train_batch(x, y, model, optimizer, loss_fn):
prediction = model(x)
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
def accuracy(x, y, model):
with torch.no_grad():
prediction = model(x)
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
@torch.no_grad()
def val_loss(x, y, model, loss_fn):
prediction = model(x)
val_loss = loss_fn(prediction, y)
return val_loss.item()
(7) 定义 DataLoader,其中输入是 Dataset 类:
trn_dl = DataLoader(data, batch_size=32, drop_last=True)
(8) 初始化并训练模型:
model, loss_fn, optimizer = get_model()
for epoch in range(10):
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, loss_fn)
(9) 获取图像以查看滤波器学习到的图像内容:
im, c = trn_dl.dataset[2]
plt.imshow(im[0].cpu())
plt.show()

2. 可视化第一个卷积层的输出
(1) 将图像通过训练后的模型并获取第一层的输出,将其存储在 intermiddle_output 变量中:
print(list(model.children()))
[Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1)), MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), ReLU(), Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1)), MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), ReLU(), Flatten(start_dim=1, end_dim=-1), Linear(in_features=3200, out_features=256, bias=True), ReLU(), Linear(in_features=256, out_features=1, bias=True), Sigmoid()]
first_layer = nn.Sequential(*list(model.children())[:1])
intermediate_output = first_layer(im[None])[0].detach()
(2) 绘制 64 个滤波器的输出,itermiddle_output 中每个元素对应于一个滤波器的卷积输出:
n = 8
fig, ax = plt.subplots(n, n, figsize=(10,10))
for ix, axis in enumerate(ax.flat):
axis.set_title('Filter: '+str(ix))
axis.imshow(intermediate_output[ix].cpu())
plt.tight_layout()
plt.show()

在以上输出中,可以看到一些滤波器(例如滤波器 0、4、6 和 7 )学习到了图像中存在的边缘。
(3) 输入多个 O 图像并使用第 4 个滤波器执行卷积观察输出结果。
从数据集中获取多张 O 图像:
x, y = next(iter(trn_dl))
x2 = x[y==0]
print(len(x2))
# 15
调整 x2 形状使其能够作为卷积神经网络的输入,即批大小 x 通道 x 高度 x 宽度:
x2 = x2.view(-1,1,28,28)
定义用于存储模型输出的变量:
first_layer = nn.Sequential(*list(model.children())[:1])
提取 O 图像 (x2) 在第一层 (first_layer) 后的输出:
first_layer_output = first_layer(x2).detach()
(4) 绘制图像通过第一层后的输出:
n = 4
fig, ax = plt.subplots(n, n, figsize=(10,10))
for ix, axis in enumerate(ax.flat):
if ix < n**2-1:
axis.imshow(first_layer_output[ix,4,:,:].cpu())
axis.set_title(str(ix))
plt.tight_layout()
plt.show()

可以看到,给定滤波器的行为在不同图像之间具有一致性。
3. 可视化不同网络层的特征图
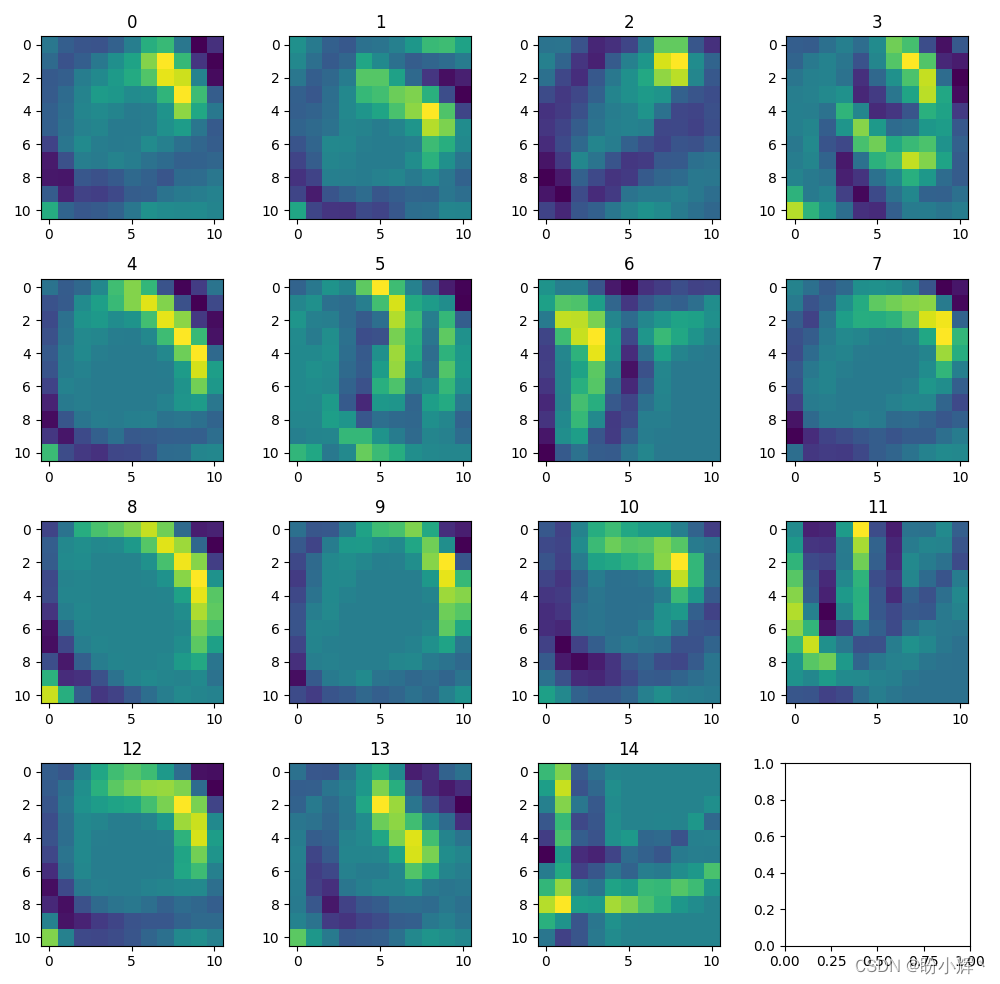
(1) 提取原始 O 图像从输入层到第 2 个卷积层的输出,绘制第 2 层中的滤波器与输入 O 图像进行卷积后的输出。
绘制滤波器与相应图像的卷积输出:
second_layer = nn.Sequential(*list(model.children())[:4])
second_intermediate_output = second_layer(im[None])[0].detach()
print(second_intermediate_output.shape)
# torch.Size([128, 11, 11])
n = 11
fig, ax = plt.subplots(n, n, figsize=(10,10))
for ix, axis in enumerate(ax.flat):
axis.imshow(second_intermediate_output[ix].cpu())
axis.set_title(str(ix))
plt.tight_layout()
plt.show()
print(im.shape)
# torch.Size([1, 28, 28])

以第 34 个滤波器的输出为例,当我们通过滤波器 34 传递多个 O 图像时,可以在不同图像之间看到相似的激活:
second_layer = nn.Sequential(*list(model.children())[:4])
second_intermediate_output = second_layer(x2).detach()
print(second_intermediate_output.shape)
# torch.Size([15, 128, 11, 11])
n = 4
fig, ax = plt.subplots(n, n, figsize=(10,10))
for ix, axis in enumerate(ax.flat):
if ix < n**2-1:
axis.imshow(second_intermediate_output[ix,34,:,:].cpu())
axis.set_title(str(ix))
plt.tight_layout()
plt.show()
print(len(data))
# 2498
(2) 绘制全连接层的激活。
首先,获取图像样本:
custom_dl = DataLoader(data, batch_size=2498, drop_last=True)
接下来,从数据集中选择 O 图像,对它们进行整形后,作为输入传递到 CNN 模型中:
x, y = next(iter(custom_dl))
x2 = x[y==0]
print(len(x2))
# 1245
x2 = x2.view(len(x2),1,28,28)
将以上图像通过 CNN 模型,获取全连接层输出:
flatten_layer = nn.Sequential(*list(model.children())[:7])
flatten_layer_output = flatten_layer(x2).detach()
print(flatten_layer_output.shape)
# torch.Size([1245, 3200])
绘制全连接层输出:
plt.figure(figsize=(100,10))
plt.imshow(flatten_layer_output.cpu())
plt.show()
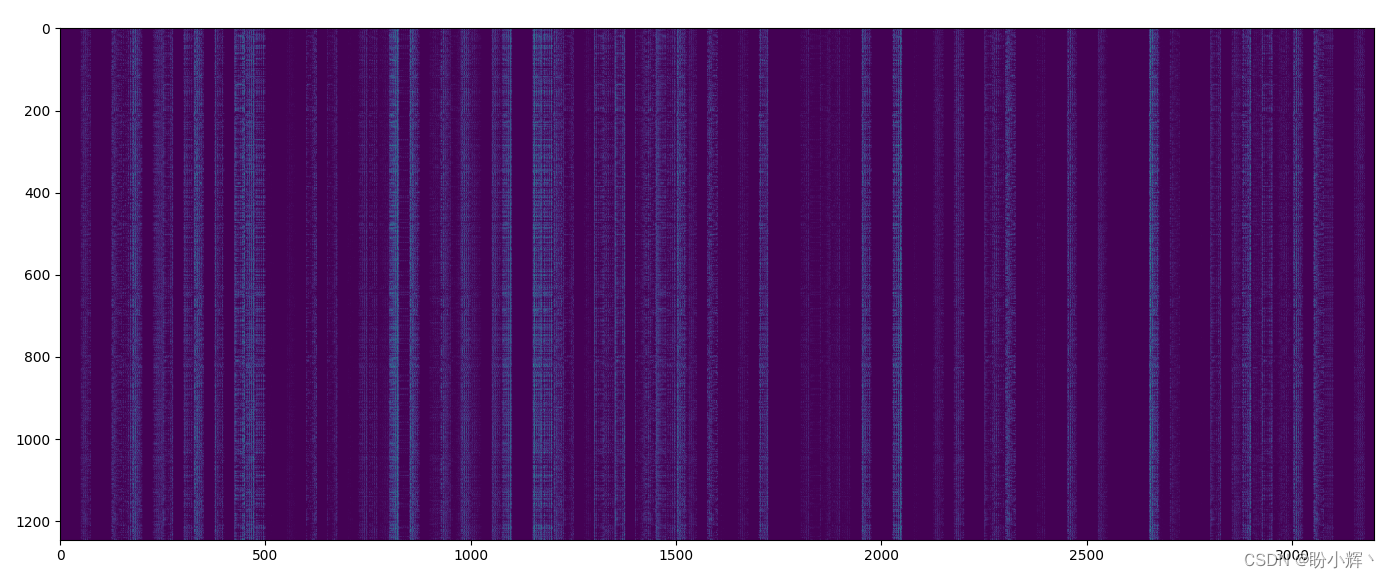
输出的形状为 1245 x 3200,因为数据集中有 1,245 个 O 图像,且在全连接层中的每个图像的输出为 3,200 维。当输入为 O 时,全连接层中大于零的激活值会突出显示,在图像中显示为白色像素。可以看到,模型已经学习了图像中的结构信息,即使属于同一类别的输入图像存在较大的风格差异。
小结
在探索神经网络内部的特征学习过程中,可视化起着重要作用。它为我们提供了一种直观、可解释的方式来理解网络的运行机制和学习的特征表示。通过可视化特征学习的结果,可以深入了解神经网络,并为网络的优化、解释和改进提供参考。本节中,通过介绍如何可视化神经网络中间层输出,加深了对网络行为和学到的特征表示的认识。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强