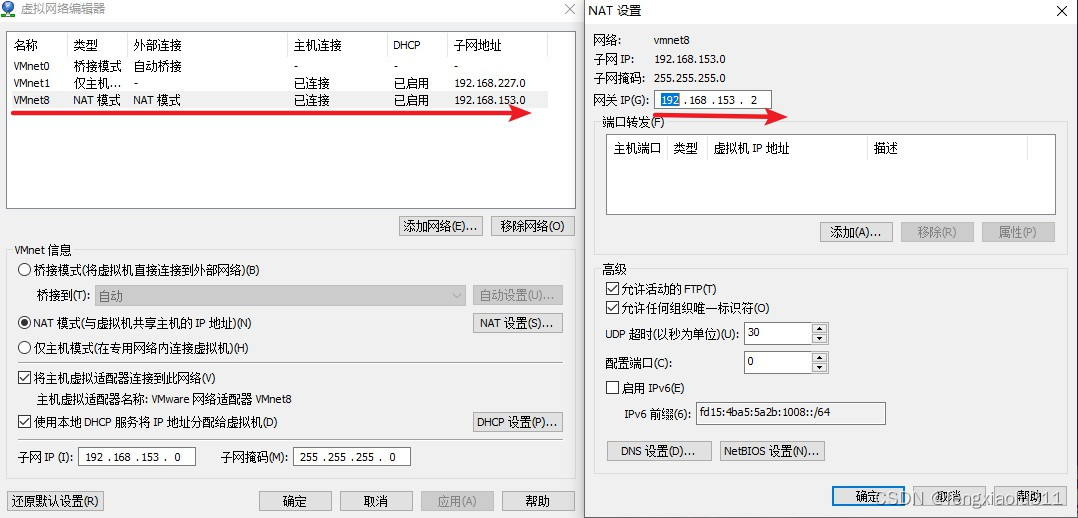
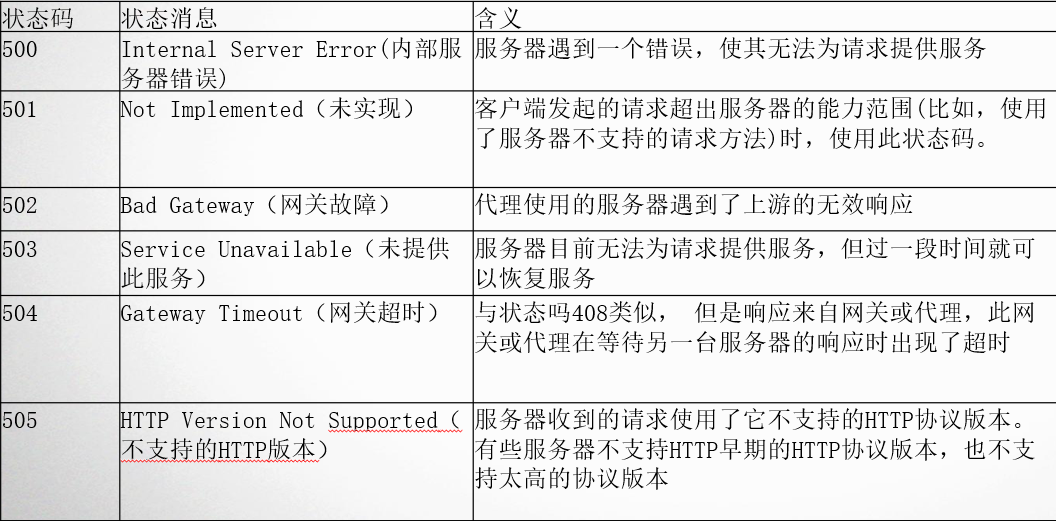
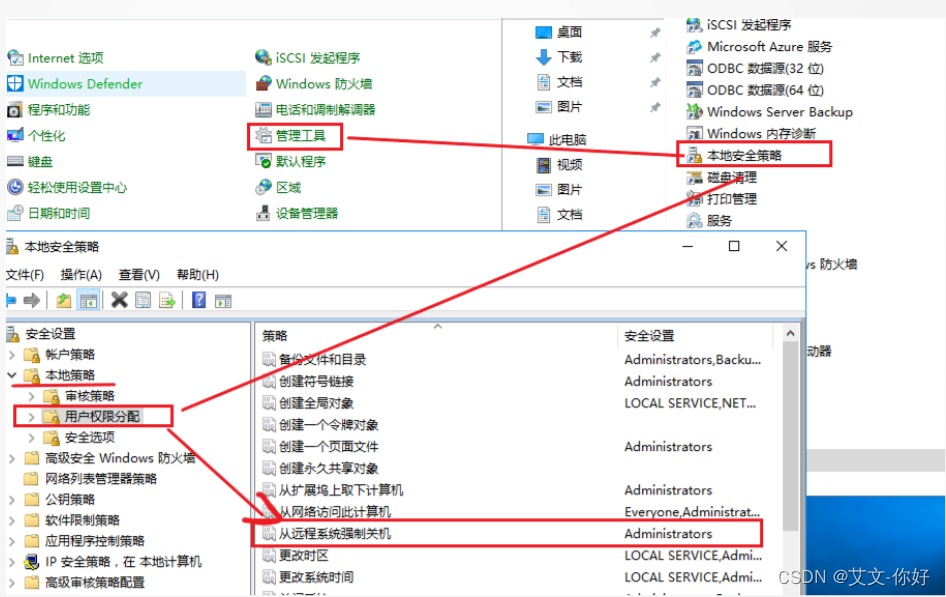
目前有许多开源的大型AI模型,这些模型在自然语言处理、图像识别、语音处理等领域取得了显著的成果。以下是一些常见的开源大模型及其特点,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。
1.GPT-3(Generative Pre-trained Transformer 3):
特点:由OpenAI开发的最大型自然语言处理模型,具有1750亿个参数。能够生成高质量的文本、回答问题、实现翻译等多种任务。
优势:生成文本的流利性和多样性,广泛的应用领域,支持零样本学习(通过少量示例进行学习)。
2.BERT(Bidirectional Encoder Representations from Transformers):
特点:由Google开发的预训练模型,具有1.1亿个参数。通过双向编码器进行训练,适用于多种自然语言处理任务。
优势:理解文本的上下文,能够生成更有上下文连贯性的输出,适用范围广。
3.ResNet(Residual Network):
特点:用于图像识别的深度卷积神经网络,具有多个层级。引入残差连接,解决了深层网络的退化问题,提高了训练效果。
优势:能够训练非常深的神经网络,提升图像识别的性能。
4.VGG(Visual Geometry Group):
特点:另一个用于图像识别的卷积神经网络,具有统一的结构,所有卷积层都采用相同大小的卷积核。
优势:简单明了的结构,易于理解和实现,适用于教学和实验。
5.DenseNet(Densely Connected Convolutional Networks):
特点:图像识别网络,引入密集连接的概念,每一层都与前面所有层连接。
优势:减轻梯度消失问题,提高信息流动性,更高的参数利用率。
6.WaveNet:
特点:由DeepMind开发的音频生成模型,基于深层卷积神经网络,能够生成高质量的语音和音频效果。
优势:逼真的音频生成,用于语音合成和音频处理领域。
7.OpenNMT(Open-Source Neural Machine Translation):
特点:开源的神经机器翻译框架,支持多种翻译模型,可用于实现自动翻译任务。
优势:支持自定义翻译模型,适用于各种语言翻译任务。
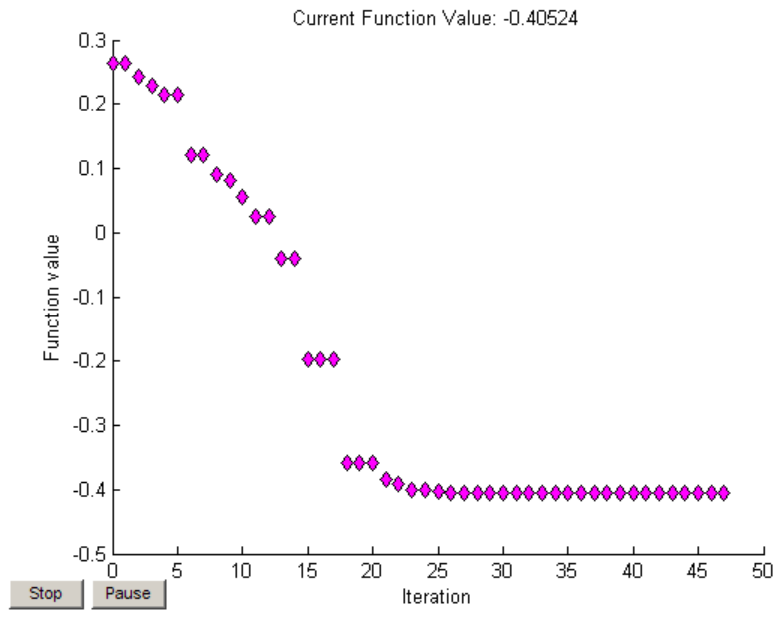
这些开源大模型在不同领域和任务中有着各自的应用优势,开发者可以根据项目需求选择合适的模型进行使用和调整。同时,这些模型通常需要大量的计算资源进行训练和部署,所以在使用时需要考虑硬件和时间成本。