提出一个GAN
(Generative Adversarial Nets)
1 方法
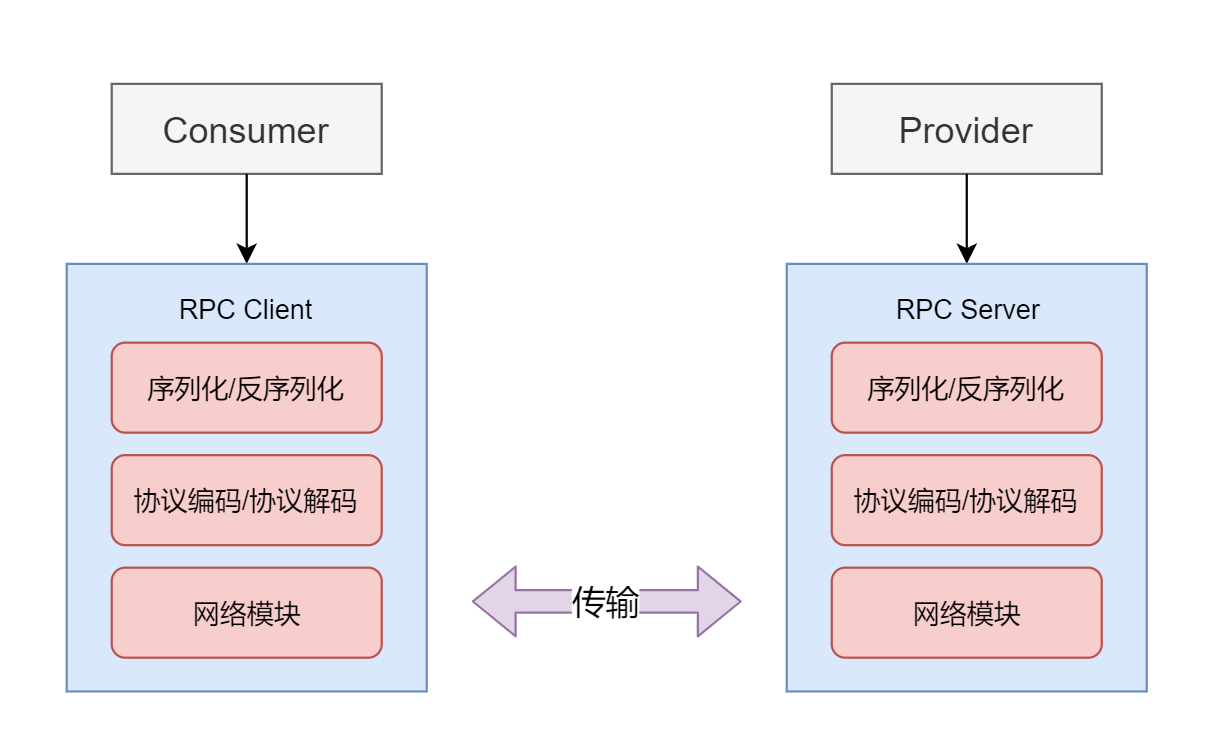
(1)生成模型G(Generative),是用来得到分布的,在统计学眼里,整个世界是通过采样不同的分布得到的,生成东西的话,目前就是要抓住一个数据的分布,
(2)辨别模型D(D) ,他是来辨别你的样本究竟是从真实世界来的呢,还是来自于G
李沐老师把型G是造假币的人,然后D是鉴别假币的人
两个人相互对抗,提升各自的能力
两个网络相互对抗,提升各自的能力
生成模型有两种
第一种生成模型是 我明明白白把一个模型给学出来,知道我们要求的分布的均值和方差之类的
第二种生成模型是,我去近似就好,坏处是不知道分布长什么样子,好处是这个东西算起来会比较容易
GAN用到的就是第二种
2 可视化举例
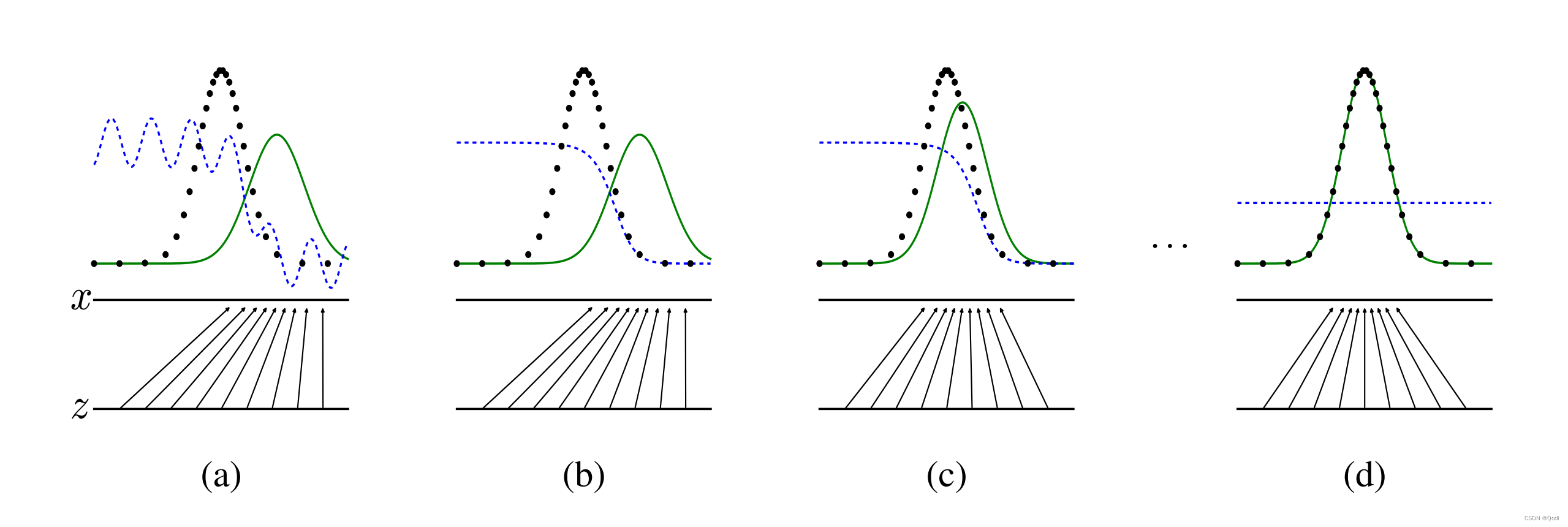
以一维度数据做可视化
紫色线条是判别器D,绿色线条是生成器G,黑色线条是真实分布
图(a)初始状态 此时可以观察到 真实分布(黑色)和生成器(绿色)的分布差别较大,判别器(紫色)
图(b)更新判别器(紫色) 此时可以观察到 判别器(紫色)可以分辨的比较好了,黑色线附近为1 ,绿色线附近为0
图(c)更新生成器(绿色) 此时可以观察到 生成器(绿色)像真实数据分布靠近,为了使得判别器不分别出来
图(d)不断反复,可以看到 绿色生成器要尽量靠近黑色生成数据,当足够接近的时候,会发现判别器输出就是0.5了,此时就无法分辨了
3 算法流程

最简单的应用是G和D是MLP
如图所示
(1)从噪声中采样m个样本得到z,从真实数据中采样m个样本得到x
(2)先更新判别器,增强判别器
D(x) 表示把真实分布采样得到的数据放到辨别器里,假如辨别器是完美的,那么D(x)是1 log(D(x))是0,如果不完美,则 log(D(x))为负数
G(z)表示把噪音分布采样得到的噪音放到生成器里,会生成伪真实x,再放入D判别器,假如辨别器是完美的,那么D(x)是0 整体log(1-D(G(x)))是0 ,如果不完美的话,也会输出负数
所以要最大化如下函数,使得接近0
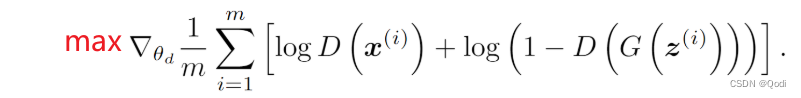
使得判别器函数输出尽可能正确,尽可能完美区分
(3)再更新生成器,使得生成器尽可能糊弄判别器
使得后面一项尽可能小
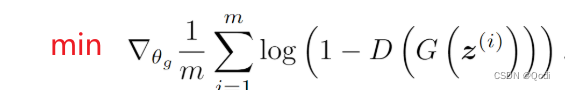
这样就会导致生成器尽可能糊弄判别器
k是一个超参数,要保证我们的G和D每次进步差不多,这样才能保证我们自己的一个有效性
外面的这个for loop就是说我们要迭代N次
怎么判断收敛是一个比较难的点,因而有些时候不是很有效