堆叠聚合模型是处理非平衡数据的理想算法
堆叠聚合模型的设计是通过训练多个模型,然后使用原模型,将多个模型的输出结果整合在一起以实现更准确的预测。这叠聚合模型在多个临床场景上都表现出优于单一模型的效能[1]。是构建临床预测模型过程中值得考察的一种算法。这里使用的堆叠聚合模型是堆叠了逻辑回归和随机森林两个模型。
非平衡数据是指结局变量中的类别比例不均匀,有的类别的数量会远远少于其他的类别,而医学数据往往是非平衡的数据,比如肿瘤转移患者的数量往往是小于肿瘤不转移患者的数量。
这里使用SEER来源的食管癌非平衡数据构建堆叠聚合模型,并与单纯的逻辑回归模型进行比较,体现堆叠聚合模型在处理非平衡数据中的一些特点。
1.整体评价方面
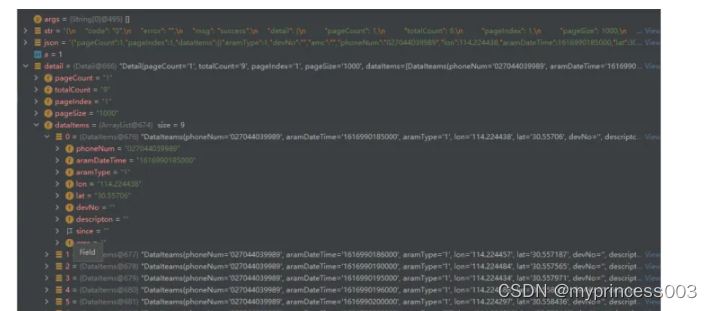
许多研究都提到对接聚合模型可以在区分度优于单一的模型。而对于非平衡数据来说,有的意见推荐使用PRC曲线来替代ROC曲线来比较模型之间的效能。图1所示,在食管癌数据中,ROC曲线下面积(AUROC)和PRC曲线下面积(AUPRC),堆叠聚合模型都是高于逻辑回归模型。

图1. 模型的整体评价。ABC逻辑回归模型的评价参数;DEF堆叠聚合模型的评价参数。
2.局部评价方面
对于非平衡数据来说,有的资料会推荐使用局部评价[2]。如图2所示,这里使用局部ROC曲线下面积和局部PRC曲线下面积来进行评价,结果上有一些不一致,堆叠聚合模型在局部ROC曲线下面积高于逻辑回归模型,但是在局部PRC曲线下面积的结果反之。局部评价参数用于非平衡数据的评价还有待于进一步发展,表现在其计算的方法还没有统一。这里使用的局部ROC曲线下面积的计算是参考文献中的计算方法[2]。

图2.模型的局部评价。ABC逻辑回归模型的评价参数;DEF堆叠聚合模型的评价参数。红线标注局部评价的阈值范围0.02~0.2。
3.校准度评价
非平衡数据对校准度的影响比较大,即使是逻辑回归模型也不能获得一个很好的校准度。这时候需要进行概率校正。概率校准比较常用的一个办法就是保序回归(isotonic regression)。此次分析过程中值得一提的一个发现,就是叠聚合模型的不需要进行概率的校准就能够达到一个比较良好的校准度,体现在校准曲线上就是预测的曲线和实际的理想的曲线比较贴合(图2F),甚至优于经过概率校准的单一的逻辑回归模型。但是当我们使用H-L 检验,对校准度进行评价的时候逻辑回归和堆叠聚合模型的结果都是P<0.05,代表校准度不佳。校准曲线是H-L检验结果之间的矛盾如何进行解释并没有答案,但是校准曲线是似乎是更加全面的一种评价,应该以校准曲线的结果为准。所以这里倾向于认为堆叠聚合模型可以产生一个比较理想的校准度。
总之,堆叠聚合模型是在临床预测模型过程中非常是值得考察的一个算法。
参考文献:
[1]Hwangbo L, Kang YJ, Kwon H, Lee JI, Cho HJ, Ko JK, Sung SM, Lee TH. Stacking ensemble learning model to predict 6-month mortality in ischemic stroke patients. Sci Rep. 2022 Oct 17;12(1):17389. doi: 10.1038/s41598-022-22323-9. Erratum in: Sci Rep. 2022 Dec 21;12(1):22112. PMID: 36253488; PMCID: PMC9576722.
[2]Carrington AM, Fieguth PW, Qazi H, Holzinger A, Chen HH, Mayr F, Manuel DG. A new concordant partial AUC and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med Inform Decis Mak. 2020 Jan 6;20(1):4. doi: 10.1186/s12911-019-1014-6.