部署参考:https://github.com/PaddlePaddle/FastDeploy/blob/develop/tutorials/multi_thread/python/pipeline/README_CN.md
安装
cpu: pip install fastdeploy-python
gpu :pip install fastdeploy-gpu-python
#下载部署示例代码
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd FastDeploy/tutorials/multi_thread/python/pipeline
# 下载模型,图片和字典文件
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
tar xvf ch_PP-OCRv3_det_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
tar xvf ch_PP-OCRv3_rec_infer.tar
wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
命令:
多线程
python multi_thread_process_ocr.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image_path xxx/xxx --device gpu --thread_num 3
多进程
python multi_thread_process_ocr.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image_path xxx/xxx --device gpu --use_multi_process True --process_num 3
问题
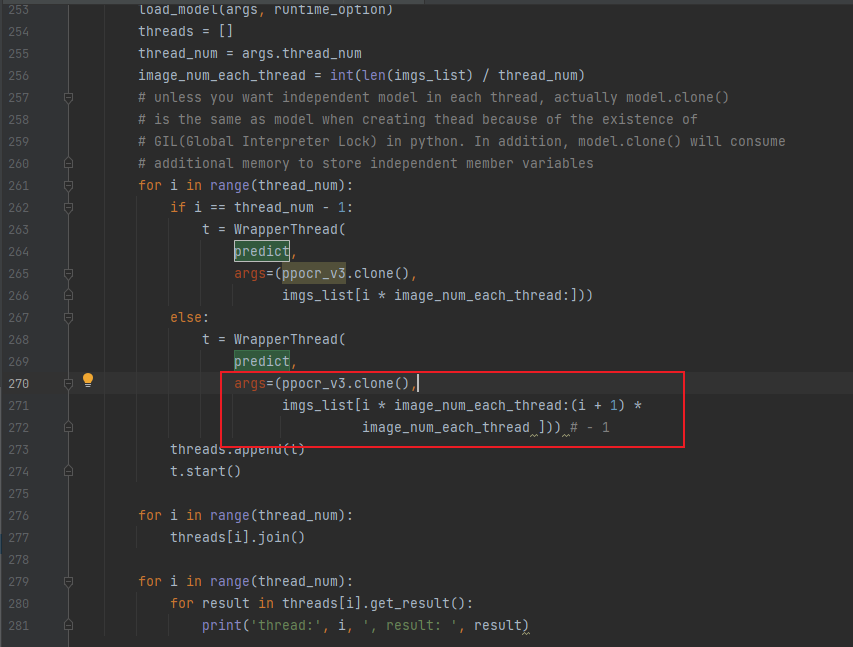
多进程图片分配有bug
文件:multi_thread_process_ocr.py
原始代码:270行
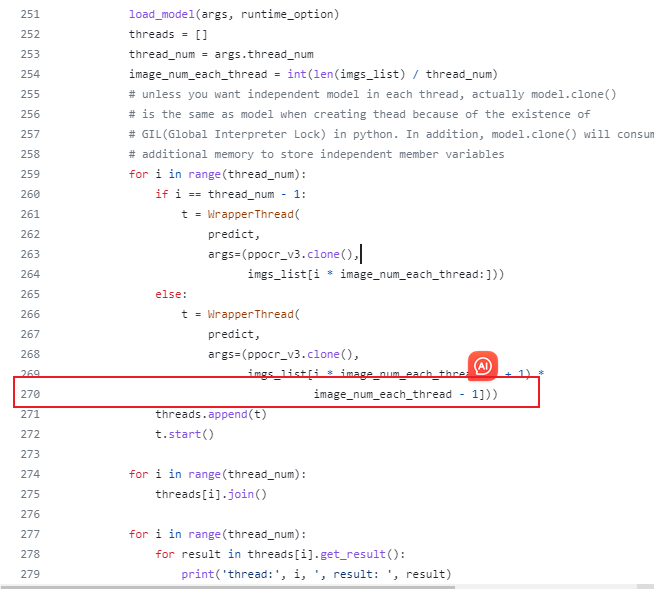
修改为如下,去掉1
ModuleNotFoundError: No module named ‘example’
因为安装包不对,fastdeploy与fastdeploy-python不是同一个包
CUDA error(3), initialization error.
----------------------
Error Message Summary:
----------------------
ExternalError: CUDA error(3), initialization error.
[Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /home/fastdeploy/develop/paddle_build/v0.0.0/Paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:251)
参考:
PaddlePaddle——问题解决:使用Python multiprocessing时报错:CUDA error(3), initialization error.
https://github.com/PaddlePaddle/PaddleDetection/issues/2241
paddle 相关模块只在方法里面引用,要在多进程外有 import 这些模块
flask部署
发送列表类型的图片base64编码,返回列表类型的字符串
注意server端文件放在FastDeploy/tutorials/multi_thread/python/pipeline目录下
创建server端
from threading import Thread
import cv2
import os
from multiprocessing import Pool
import sys
import fastdeploy as fd
import numpy as np
import base64
from PIL import Image
from io import BytesIO
from sqlalchemy import create_engine, text
from flask import Flask, request, jsonify
import argparse
import ast
# watch -n 0.1 nvidia-smi
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument(
"--det_model",
# required=True,
type=str,
default='ch_PP-OCRv3_det_infer',
help="Path of Detection model of PPOCR.")
parser.add_argument(
"--cls_model",
# required=True,
type=str,
default='ch_ppocr_mobile_v2.0_cls_infer',
help="Path of Classification model of PPOCR.")
parser.add_argument(
"--rec_model",
# required=True,
type=str,
default='ch_PP-OCRv3_rec_infer',
help="Path of Recognization model of PPOCR.")
parser.add_argument(
"--rec_label_file",
# required=True,
type=str,
default='ppocr_keys_v1.txt',
help="Path of Recognization model of PPOCR.")
# parser.add_argument(
# "--image_path",
# type=str,
# required=True,
# help="The directory or path or file list of the images to be predicted."
# )
parser.add_argument(
"--device",
type=str,
default='gpu', # cpu
help="Type of inference device, support 'cpu', 'kunlunxin' or 'gpu'.")
parser.add_argument(
"--backend",
type=str,
default="default",
help="Type of inference backend, support ort/trt/paddle/openvino, default 'openvino' for cpu, 'tensorrt' for gpu"
)
parser.add_argument(
"--device_id",
type=int,
default=0,
help="Define which GPU card used to run model.")
parser.add_argument(
"--cpu_thread_num",
type=int,
default=9,
help="Number of threads while inference on CPU.")
parser.add_argument(
"--cls_bs",
type=int,
default=1,
help="Classification model inference batch size.")
parser.add_argument(
"--rec_bs",
type=int,
default=6,
help="Recognition model inference batch size")
parser.add_argument("--thread_num", type=int, default=1, help="thread num")
parser.add_argument(
"--use_multi_process",
type=ast.literal_eval,
default=True,
help="Wether to use multi process.")
parser.add_argument(
"--process_num", type=int, default=5, help="process num")
return parser.parse_args()
def get_image_list(image_path):
image_list = []
if os.path.isfile(image_path):
image_list.append(image_path)
# load image in a directory
elif os.path.isdir(image_path):
for root, dirs, files in os.walk(image_path):
for f in files:
image_list.append(os.path.join(root, f))
else:
raise FileNotFoundError(
'{} is not found. it should be a path of image, or a directory including images.'.
format(image_path))
if len(image_list) == 0:
raise RuntimeError(
'There are not image file in `--image_path`={}'.format(image_path))
return image_list
def build_option(args):
option = fd.RuntimeOption()
if args.device.lower() == "gpu":
option.use_gpu(args.device_id)
option.set_cpu_thread_num(args.cpu_thread_num)
if args.device.lower() == "kunlunxin":
option.use_kunlunxin()
return option
if args.backend.lower() == "trt":
assert args.device.lower(
) == "gpu", "TensorRT backend require inference on device GPU."
option.use_trt_backend()
elif args.backend.lower() == "pptrt":
assert args.device.lower(
) == "gpu", "Paddle-TensorRT backend require inference on device GPU."
option.use_trt_backend()
option.enable_paddle_trt_collect_shape()
option.enable_paddle_to_trt()
elif args.backend.lower() == "ort":
option.use_ort_backend()
elif args.backend.lower() == "paddle":
option.use_paddle_infer_backend()
elif args.backend.lower() == "openvino":
assert args.device.lower(
) == "cpu", "OpenVINO backend require inference on device CPU."
option.use_openvino_backend()
return option
def load_model(args, runtime_option):
# Detection模型, 检测文字框
det_model_file = os.path.join(args.det_model, "inference.pdmodel")
det_params_file = os.path.join(args.det_model, "inference.pdiparams")
# Classification模型,方向分类,可选
cls_model_file = os.path.join(args.cls_model, "inference.pdmodel")
cls_params_file = os.path.join(args.cls_model, "inference.pdiparams")
# Recognition模型,文字识别模型
rec_model_file = os.path.join(args.rec_model, "inference.pdmodel")
rec_params_file = os.path.join(args.rec_model, "inference.pdiparams")
rec_label_file = args.rec_label_file
# PPOCR的cls和rec模型现在已经支持推理一个Batch的数据
# 定义下面两个变量后, 可用于设置trt输入shape, 并在PPOCR模型初始化后, 完成Batch推理设置
cls_batch_size = 1
rec_batch_size = 6
# 当使用TRT时,分别给三个模型的runtime设置动态shape,并完成模型的创建.
# 注意: 需要在检测模型创建完成后,再设置分类模型的动态输入并创建分类模型, 识别模型同理.
# 如果用户想要自己改动检测模型的输入shape, 我们建议用户把检测模型的长和高设置为32的倍数.
det_option = runtime_option
det_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],
[1, 3, 960, 960])
# 用户可以把TRT引擎文件保存至本地
#det_option.set_trt_cache_file(args.det_model + "/det_trt_cache.trt")
global det_model
det_model = fd.vision.ocr.DBDetector(
det_model_file, det_params_file, runtime_option=det_option)
cls_option = runtime_option
cls_option.set_trt_input_shape("x", [1, 3, 48, 10],
[cls_batch_size, 3, 48, 320],
[cls_batch_size, 3, 48, 1024])
# 用户可以把TRT引擎文件保存至本地
# cls_option.set_trt_cache_file(args.cls_model + "/cls_trt_cache.trt")
global cls_model
cls_model = fd.vision.ocr.Classifier(
cls_model_file, cls_params_file, runtime_option=cls_option)
rec_option = runtime_option
rec_option.set_trt_input_shape("x", [1, 3, 48, 10],
[rec_batch_size, 3, 48, 320],
[rec_batch_size, 3, 48, 2304])
# 用户可以把TRT引擎文件保存至本地
#rec_option.set_trt_cache_file(args.rec_model + "/rec_trt_cache.trt")
global rec_model
rec_model = fd.vision.ocr.Recognizer(
rec_model_file,
rec_params_file,
rec_label_file,
runtime_option=rec_option)
# 创建PP-OCR,串联3个模型,其中cls_model可选,如无需求,可设置为None
global ppocr_v3
ppocr_v3 = fd.vision.ocr.PPOCRv3(
det_model=det_model, cls_model=cls_model, rec_model=rec_model)
# 给cls和rec模型设置推理时的batch size
# 此值能为-1, 和1到正无穷
# 当此值为-1时, cls和rec模型的batch size将默认和det模型检测出的框的数量相同
ppocr_v3.cls_batch_size = cls_batch_size
ppocr_v3.rec_batch_size = rec_batch_size
def predict(model, img_list):
result_list = []
# predict ppocr result
for image in img_list:
im = cv2.imread(image)
result = model.predict(im)
result_list.append(result)
return result_list
def process_predict(image):
# predict ppocr result
im = cv2.imread(image)
result = ppocr_v3.predict(im)
print(result)
def process_predict_text(base64_str):
image = base64_to_bgr(base64_str)
result = ppocr_v3.predict(image)
# print(result)
return ''.join(result.text) #不能直接返回OCR对象序列化会失败
def cv_show(img):
'''
展示图片
@param img:
@param name:
@return:
'''
cv2.namedWindow('name', cv2.WINDOW_KEEPRATIO) # cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO
cv2.imshow('name', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def base64_to_bgr(base64_str):
base64_hex = base64.b64decode(base64_str)
image = BytesIO(base64_hex)
img = Image.open(image)
if img.mode=='RGBA':
width = img.width
height = img.height
img2 = Image.new('RGB', size=(width, height), color=(255, 255, 255))
img2.paste(img, (0, 0), mask=img)
image_array = np.array(img2)
else:
image_array = np.array(img)
image = cv2.cvtColor(image_array, cv2.COLOR_RGB2BGR)
return image
class WrapperThread(Thread):
def __init__(self, func, args):
super(WrapperThread, self).__init__()
self.func = func
self.args = args
# self.result = self.func(*self.args)
def run(self):
self.result = self.func(*self.args)
def get_result(self):
return self.result
def ocr_image_list(imgs_list):
args = parse_arguments()
# 对于三个模型,均采用同样的部署配置
# 用户也可根据自行需求分别配置
runtime_option = build_option(args)
if args.use_multi_process:
process_num = args.process_num
with Pool(
process_num,
initializer=load_model,
initargs=(args, runtime_option)) as pool:
#
results = pool.map(process_predict_text, imgs_list)
# pool.map(process_predict, imgs_list)
# 进一步处理结果
for i, result in enumerate(results):
print(i, result)
else:
load_model(args, runtime_option)
threads = []
thread_num = args.thread_num
image_num_each_thread = int(len(imgs_list) / thread_num)
# unless you want independent model in each thread, actually model.clone()
# is the same as model when creating thead because of the existence of
# GIL(Global Interpreter Lock) in python. In addition, model.clone() will consume
# additional memory to store independent member variables
for i in range(thread_num):
if i == thread_num - 1:
t = WrapperThread(
predict,
args=(ppocr_v3.clone(),
imgs_list[i * image_num_each_thread:]))
else:
t = WrapperThread(
predict,
args=(ppocr_v3.clone(),
imgs_list[i * image_num_each_thread:(i + 1) *
image_num_each_thread])) # - 1
threads.append(t)
t.start()
for i in range(thread_num):
threads[i].join()
for i in range(thread_num):
for result in threads[i].get_result():
print('thread:', i, ', result: ', result)
@app.route('/ocr/submit', methods=['POST'])
def ocr():
args = parse_arguments()
process_num = 1#args.process_num
runtime_option = build_option(args)
data = request.get_json()
# 获取 Base64 数据
base64_str = data['img_base64']
with Pool(
process_num, initializer=load_model, initargs=(args, runtime_option)) as pool:
results = pool.map(process_predict_text, base64_str)
# 返回响应
response = {'message': 'Data received', 'result': results}
return jsonify(response)
import json
import pandas as pd
import time
if __name__ == '__main__':
app.run(host='192.168.xxx.xxx', port=5000)
client 端
import base64
import sys
import requests
import json
# 读取图像文件
with open('./pic/img.png', 'rb') as image_file:
# 将图像文件内容读取为字节流
image_data = image_file.read()
# 将图像字节流进行 Base64 编码
img_base64 = base64.b64encode(image_data)
data = {
'img_base64': [img_base64.decode('utf-8')]
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post("http://192.168.xxx.xxx:5000/ocr/submit", data=json.dumps(data),headers = headers)
if response.status_code == 200:
result = response.json()
print(result['result'])
else:
print('Error:', response.status_code)