文章目录
- 引言
- 1. 从找规律说起
- 2. 机器学习应用
- 2.1 有监督学习
- 2.2 无监督学习
- 2.2.1 聚类
- 2.2.2 降维
- 3. 机器学习一般流程
- 4. 机器学习常用概念
- 5. 深度学习简介
- 5.1 引入 -- 猜数字
- 5.2 深度学习
- 5.2.1 隐含层/中间层
- 5.2.2 随机初始化
- 5.2.3 损失函数
- 5.2.4 导数与梯度
- 5.2.5 梯度下降
- 5.2.6 优化器
- 5.2.7 Mini Batch & epoch
- 5.2.8 深度学习总结
- 6. 总结
引言
机器学习是人工智能(AI)的一个子领域,专注于使用算法和统计模型使计算机系统能够执行特定任务,而无需使用明确的指令。相反,它依赖于模式和推断。其核心思想是:给予机器大量数据,让机器从这些数据中学习,并逐渐改进它的预测或决策。
1. 从找规律说起
-
2 4 6 8 ?
-
机器学习视角

-
找到一个函数y = f(x) 使得 yi = f(xi)
-
到这个函数后,用于预测其他x对应的y值
-
y = 2 * x
找规律
- 复杂一点
- X可以是多个值
- X:(1,2) (10,20) (34,65) (79,43)
- Y: 3 30 99 122
- Y = ∑xi 或 Y = W * X, W=[1,1]
- [1,1] * [1,2] = 11 + 12 = 3
还能再复杂
- Y也可以是一个矩阵
- X可以是多个矩阵
- Y可以是多个矩阵
- X可以是不同维度的多个向量
- Y可以是不同维度的多个向量
- X可以是多个不同维度矩阵
- ……
2. 机器学习应用
- 很多时候,我们有数据,希望找到规律,但规律很复杂,所以希望靠机器来挖掘规律
- 知道花朵的大小、颜色等信息,来判断花的种类
- 知道身体血压、血脂等指标,来预测是否患病
- 知道房屋的大小、位置等信息,来预测房价
- 知道企业的业务、规模等信息,来预测股价
- 知道国家的人口、经济发展等信息,预测未来GDP
2.1 有监督学习
- 核心目标:建立一个模型(函数),来描述输入(X)和输出(Y)之间的映射关系
- 价值:对于新的输入,通过模型给出预测的输出
有监督学习要点
- 需要有一定数量的训练样本
- 输入和输出之间有关联关系
- 输入和输出可以数值化表示
- 任务需要有预测价值
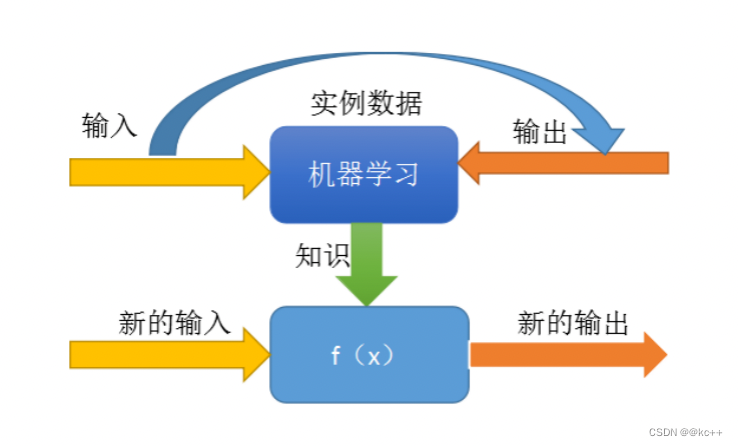
有监督学习在人工智能中的应用
文本分类任务
输入:文本 输出:类别
关系:文本的内容决定了文本的类别
机器翻译任务
输入:A语种文本 输出:B语种文本
关系:A语种表达的意思,在B语种中有对应的方式
图像识别任务
输入:图像 输出:类别
关系:图中的像素排列,决定了图像的的内容
语音识别任务
输入:音频 输出:文本
关系:声音信号在特定语言中对应特定的文本
2.2 无监督学习
给予机器的数据没有标注信息,通过算法对数据进行一定的自动分析处理,得到一些结论
常见任务:聚类、降维、找特征值等等
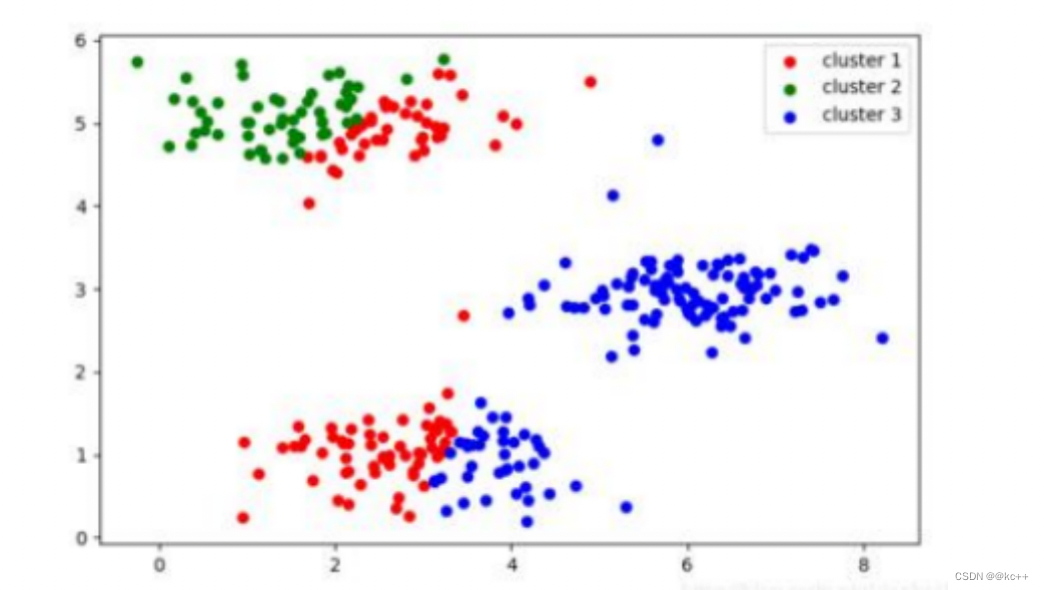
2.2.1 聚类
此处可参考我的另一篇文章 K - Means聚类算法
聚类旨在将数据点组织成几个相似的群组或“簇”,这些群组内的成员比与其他群组的成员更相似。
核心概念:
- 簇:由相似的数据点组成的一个集合。
- 质心:一个簇中所有点的平均值或中心位置。
主要方法:
- K-均值聚类:预先设定要形成的簇的数量(K),然后迭代地将每个数据点分配给最近的质心,并重新计算质心。
- 层次聚类:形成一个由层次组成的树状图。它可以从每个数据点为一个簇开始,然后合并最相近的簇,或者开始时将所有点视为一个簇,然后逐渐分裂。
- DBSCAN:基于密度的聚类方法,它将高密度的区域划分为簇,并可以识别并忽略噪音点。
- GMM (高斯混合模型):假设所有数据由几个高斯分布组成,并使用期望最大化来估计这些分布。
2.2.2 降维
此处可参考我的另一篇文章 PCA主成分分析
降维是机器学习和数据分析中的一个重要概念,它涉及将数据从高维空间转换到低维空间,同时尽量保留数据的重要信息或结构。降维通常用于数据可视化、性能优化、噪声消减以及避免“维度的诅咒”。
维度的诅咒:
随着维度的增加,数据的稀疏性增加,导致需要更多的数据来进行有效的学习,这使得高维数据变得难以处理。
常用的降维方法:
- 主成分分析(PCA):
- 通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,这些不相关的变量称为“主成分”。
- 第一个主成分解释了原始数据中的最大方差,每个后续的成分都有尽可能小的方差。
- PCA 是线性方法,可能不适合捕捉非线性关系。
- 线性判别分析(LDA):
- 监督学习的降维技术,与PCA类似,但同时考虑类别信息。
- 目标是最大化类间方差并最小化类内方差,以提高类的可分性。
- t-SNE (t-分布随机邻域嵌入):
- 用于高维数据的可视化。
- 通过概率分布将相似的对象映射到相似的位置,尤其适合捕捉数据中的复杂结构。
- 自编码器:
- 是深度学习模型,通过尝试复制其输入来学习数据的有效表示。
- 编码器部分将输入压缩到低维表示,解码器部分尝试从这个表示中重构输入。
- 奇异值分解(SVD):
- 用于矩阵分解。
- 可用于PCA的实现,也常用于推荐系统。
为什么要降维:
- 速度与存储:减少计算量和存储需求。
- 可视化:更容易地将高维数据映射到2D或3D,以进行可视化。
- 噪声减少:通过消除不重要的特征来减少噪声。
- 避免过拟合:减少特征的数量可以帮助模型避免过拟合。
3. 机器学习一般流程
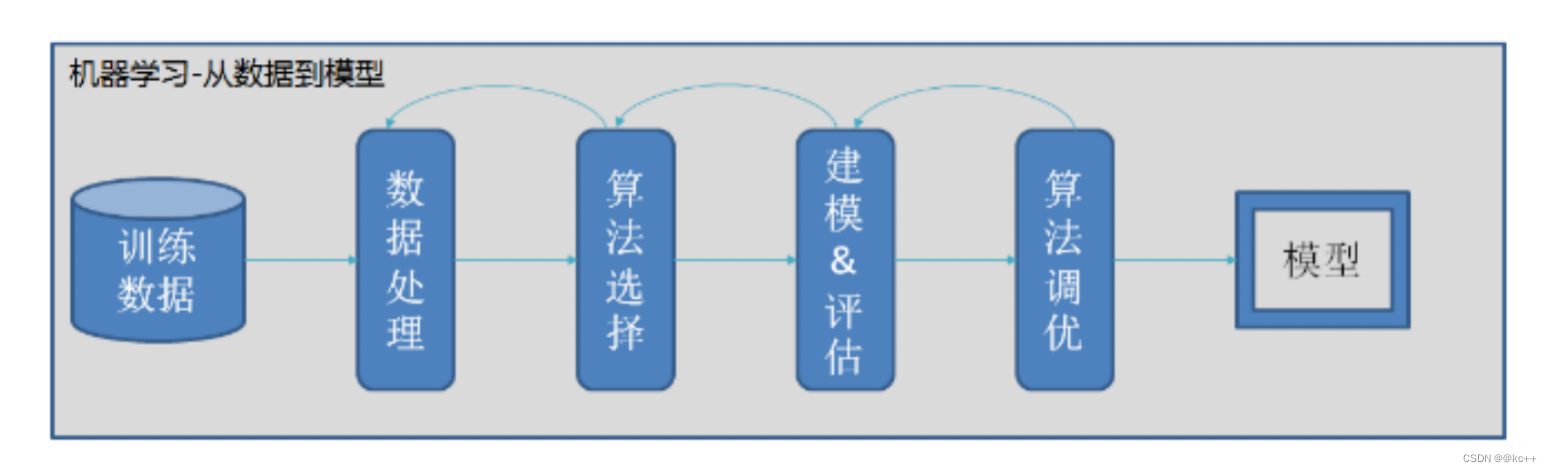
4. 机器学习常用概念
- 训练集
用于模型训练的训练数据集合 - 验证集
对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异 - 测试集
最终用于评判算法模型效果的数据集合 - K折交叉验证(K fold cross validation)
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果 - 过拟合
模型失去了泛化能力。如果模型在训练集和验证集上都有很好的表现,但在测试集上表现很差,一般认为是发生了过拟合 - 欠拟合
模型没能建立起合理的输入输出之间的映射。当输入训练集中的样本时,预测结果与标注结果依然相差很大
评价指标
为了评价算法效果的好坏,需要找到一种评价模型效果的计算指标。不同的任务会使用不同的评价指标。常用的评价指标有:
- 准确率
- 召回率
- F1值
- TopK
- BLEU…
回归问题
预测值为数值型(连续值)。如预测房价。
分类问题
预测值为类别(离散值)或在类别上的概率的分布。
- 特征
模型输入需要数值化,对于较为抽象的输入,如声音,文字,情绪等信息,需要将其转化为数值,才能输入模型。转化后的输入,被称作特征。 - 特征工程
筛选哪些信息值得(以特征的形式)输入模型,以及应当以何种形式输入的工作过程。对于机器学习而言非常重要。模型的输入,决定了模型能力的上限。
5. 深度学习简介
5.1 引入 – 猜数字
A: 我现在心里想了一个0-100之间的整数,你猜一下?
B: 60。
A: 低了。
B:80。
A:低了。
B:90。
A:高了
B:88。
A:对了!
- 假如0~100内,A选取的数字是88
- 在0~1000内,A选取的数字是888
- 那么在0~10000内选取呢?
- 可以认为,A先生选取数字是有规律的,这个规律与他选取范围的上限有关
- 构建模型预测A心里想的数字
- 模型输入:A给出的上限数值
- 模型输出:A心里想的数值
首先B随便猜一个数 ----模型随机初始化
模型函数 :Y = k * x (此样本x = 100)
此例子中B选择的初始k值为0.6
计算B的猜测与真正答案的差距 ----计算loss
损失函数 = sign(y_true – y_pred)
A告诉B偏大或偏小 ----得到loss值
B调整了自己的“模型参数” ----反向传播
参数调整幅度依照B自定的策略 ----优化器&学习率
重复以上过程
最终B的猜测与A的答案一致 ----loss = 0
- 想要快速获得正确的模型,AB可以有哪些可以优化的地方?
- 1.随机初始化。
- 假如B一开始选择的k值为88,则直接loss=0
- NLP中的预训练模型实际上就是对随机初始化的技术优化
- 2.优化损失函数
- 假如损失函数为loss = y_true – y_pred
- 即当B猜测60的时候,A告知低了28
- 3.B调整参数的策略
- B采取二分法调整,50 -> 75 -> 88
- 4.调整模型结构
- 不同模型能够拟合不同的数据集
5.2 深度学习
人工神经网络(Artificial Neural Networks,简称ANNs),也简称为神经网络(NN)。它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
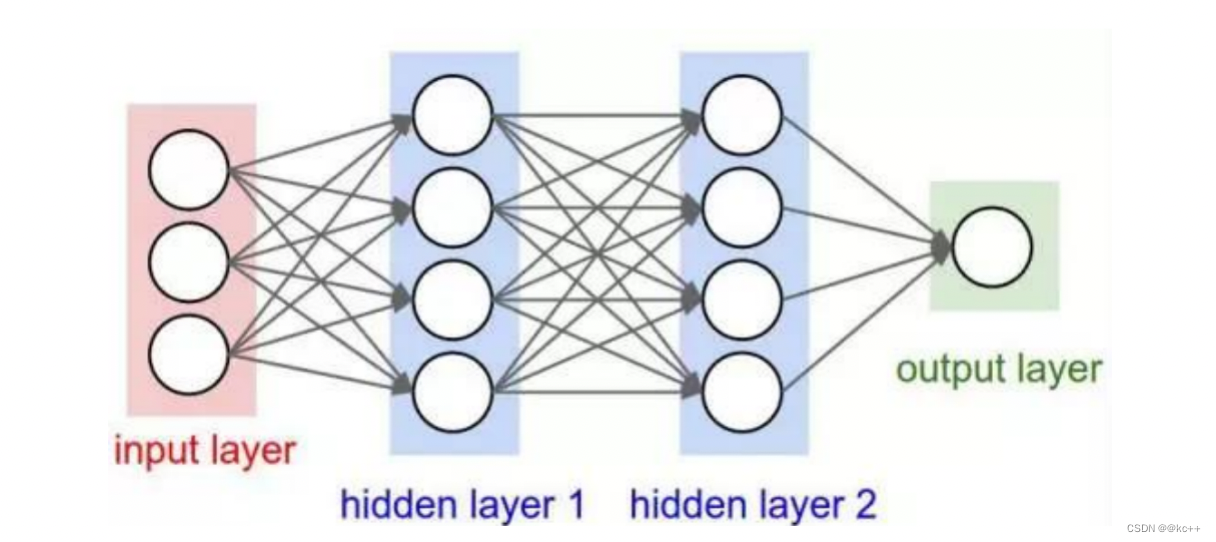
5.2.1 隐含层/中间层
神经网络模型输入层和输出层之间的部分
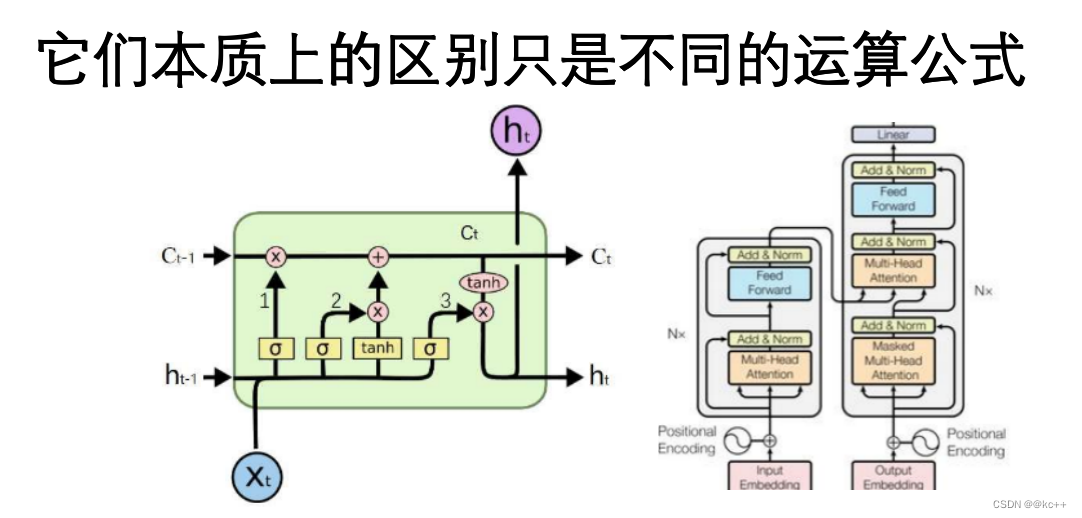
隐含层可以有不同的结构:
RNN
CNN
DNN
LSTM
Transformer
5.2.2 随机初始化
- 隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
- 初始值的选取会影响最终的结果
- 一般情况下,模型会采取随机初始化,但参数会在一定范围内
- 在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
5.2.3 损失函数
- 损失函数(loss function或cost function)用来计算模型的预测值与真实值之间的误差。
- 模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。
- 损失函数有很多,选择合理的损失函数是模型训练的必要条件。
5.2.4 导数与梯度
导数表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率。
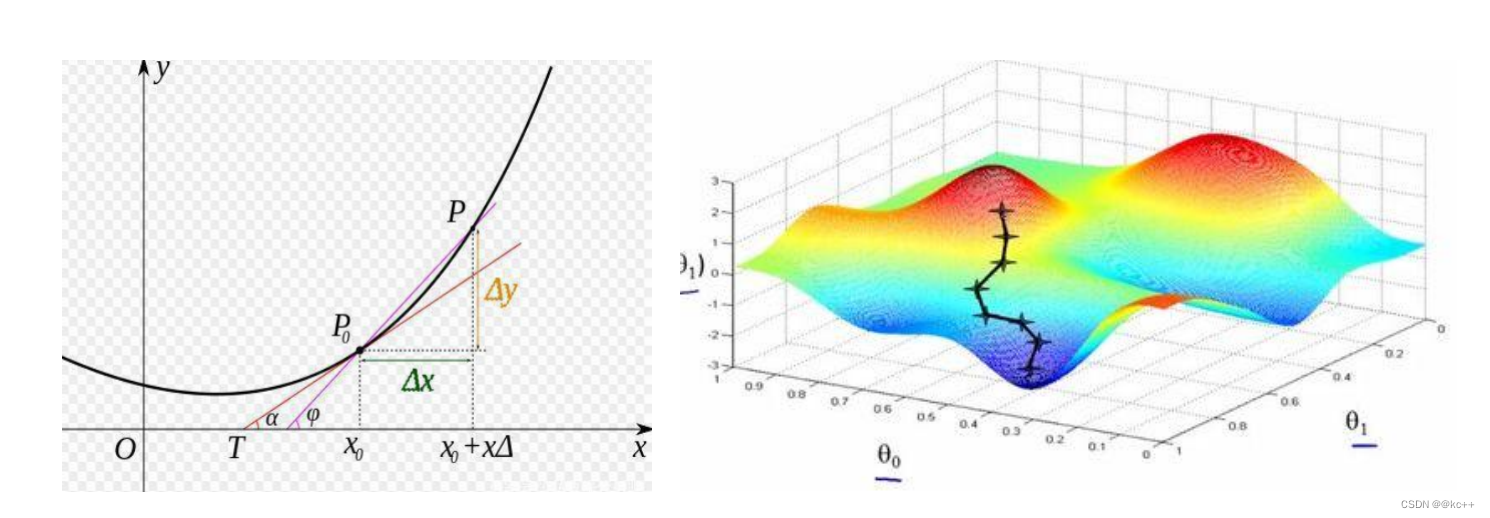
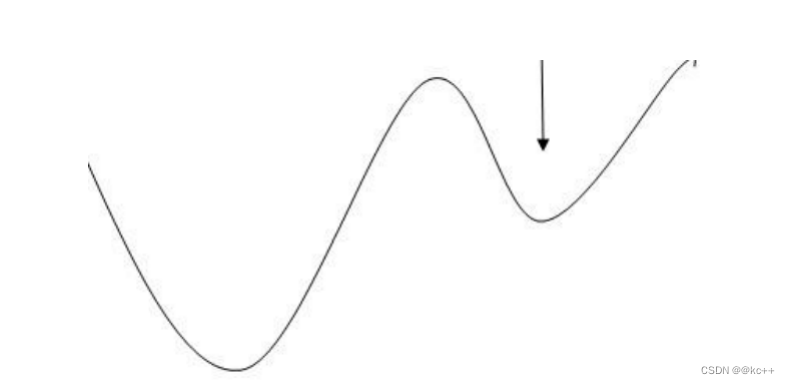
5.2.5 梯度下降
- 梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
- 梯度下降的目的是找到函数的极小值
- 为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小
5.2.6 优化器
- 知道走的方向,还需要知道走多远
- 如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
- 学习率(learning rate),动量(Momentum)都是优化器相关的概念
5.2.7 Mini Batch & epoch
- 一次训练数据集的一小部分,而不是整个训练集,或单条数据
- 它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。
- 它是一个可调节的参数,会对最终结果造成影响
- 不能太大,因为太大了会速度很慢。 也不能太小,太小了以后可能算法永远不会收敛。
- 我们将遍历一次所有样本的行为叫做一个 epoch
5.2.8 深度学习总结
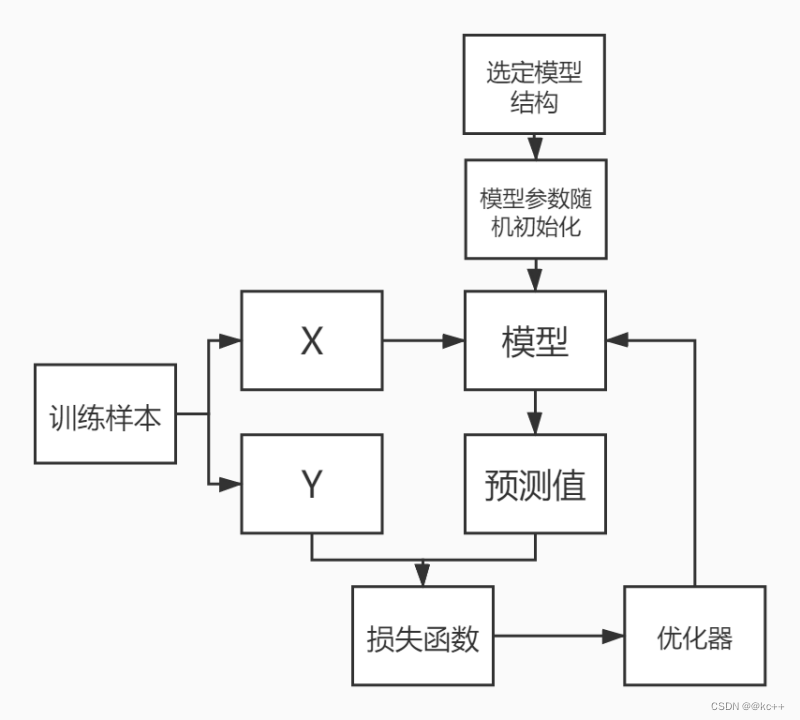
- 训练迭代进行 模型训练好后把参数保存即可用于对新样本的预测
- 要点:
- 模型结构选择
- 初始化方式选择
- 损失函数选择
- 优化器选择
- 样本质量数量
6. 总结
- 机器学习的本质,是从已知的数据中寻找规律,用来预测未知的样本
- 深度学习是机器学习的一种方法
- 度学习的基本思想,是先建立模型,并将模型权重随机初始化,之后将训练样本输入模型,可以得到模型预测值。使用模型预测值和真实标签可以计算loss。通过loss可以计算梯度,调整权重参数。简而言之,“先蒙后调”