SchNet 在2018年的面世彻底引爆了神经网络势函数(NNP, Neural Network Potential)领域,虽然说NNP的开山鼻祖还要更早,但均未像 SchNet 这样真正被物理化学家接受,引发变革。
这篇博客浅浅记录下自己阅读SchNet代码的心得。2023年的今天,网上有关SchNet的解读已经出现了很多,也有很多论文从更高的维度审视这一框架,有很多优秀的代码框架对SchNet代码进行了重构。
本文就按照自己的思路去解析这篇文献。主要参考:
DIG框架中的代码:选择DIG的二创,是因为DIG代码写得清晰,套用了SphereNet的架构,更容易理解。
GNN Expressive:这篇论文和论文附带的幻灯片对理解SchNet有很大帮助。
SchNet JCP原文:看看作者是怎么讲故事的。
GNN 语境下的 SchNet
SchNet 是图神经网络,势函数和力场中的哪一种?这个目前框架很混乱。
在那篇著名的 4 generation of Neural Network Potential 论文里,SchNet 是高维势函数(HDNNP)
在近期的 Forces are not enough 里,SchNet 被叫做机器学习力场(MLFF)
在 GNN Expressive 这篇论文里,SchNet 又变成了 GNN。
按笔者个人理解,力场一般指:相对传统的分子动力学模拟。力场二字源于传统的二体,三体力场函数的拟合。常见于分子体系,溶液体系的分子动力学模拟(MD)。体系中原子坐标给定,求解原子的受力,是一个动力学方程。
势函数脱胎于材料,金属,半导体领域的密度泛函理论计算,源头可以追溯到均匀电子气,体系中各原子坐标给定,求解整个体系的基态能量,是一个能量方程。
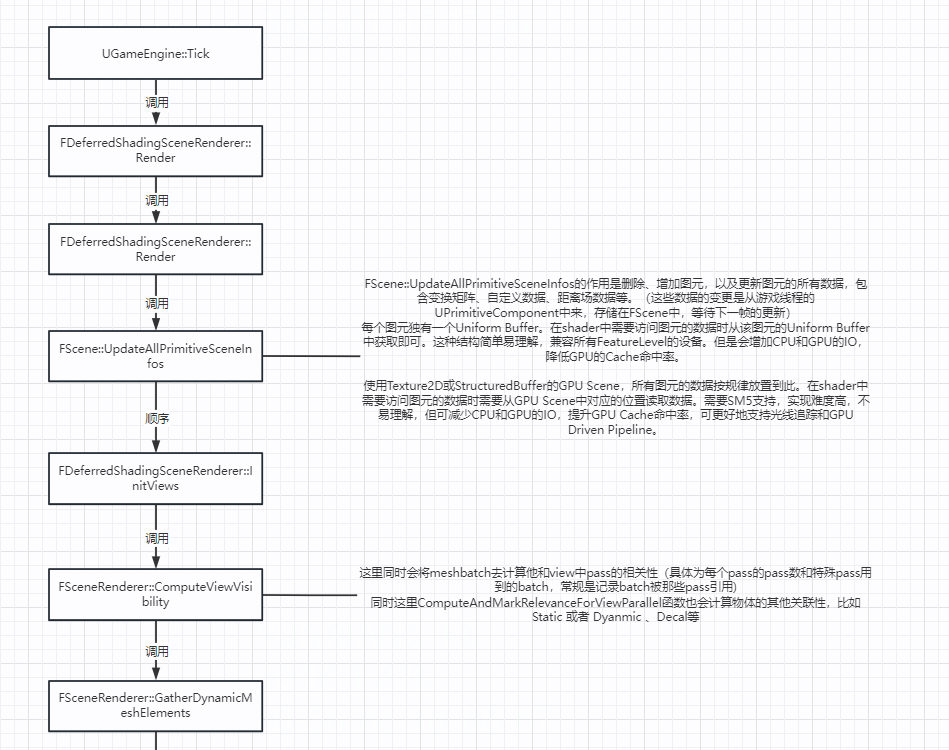
读者不必纠结具体的名词,我们暂且将 SchNet 当做一个 GNN,那么 GNN 的核心流程,前文已经讲过了,这里再放一下 GNN 的整体流程:
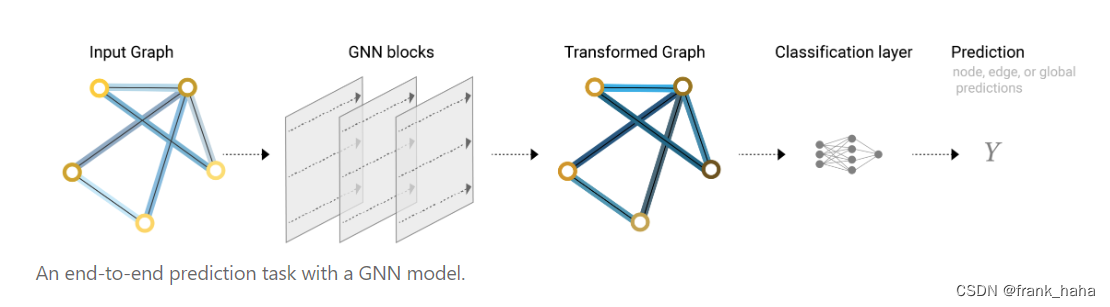
输入分子图在经过多次的信息聚合和迭代之后(message passing),变成了一张新的图,最后再使用这张图上的信息去对目标性质做预测。
在 DIG 框架中,SchNet 被改写成了一个典型的 GNN 框架,其流程与上图大致对应:
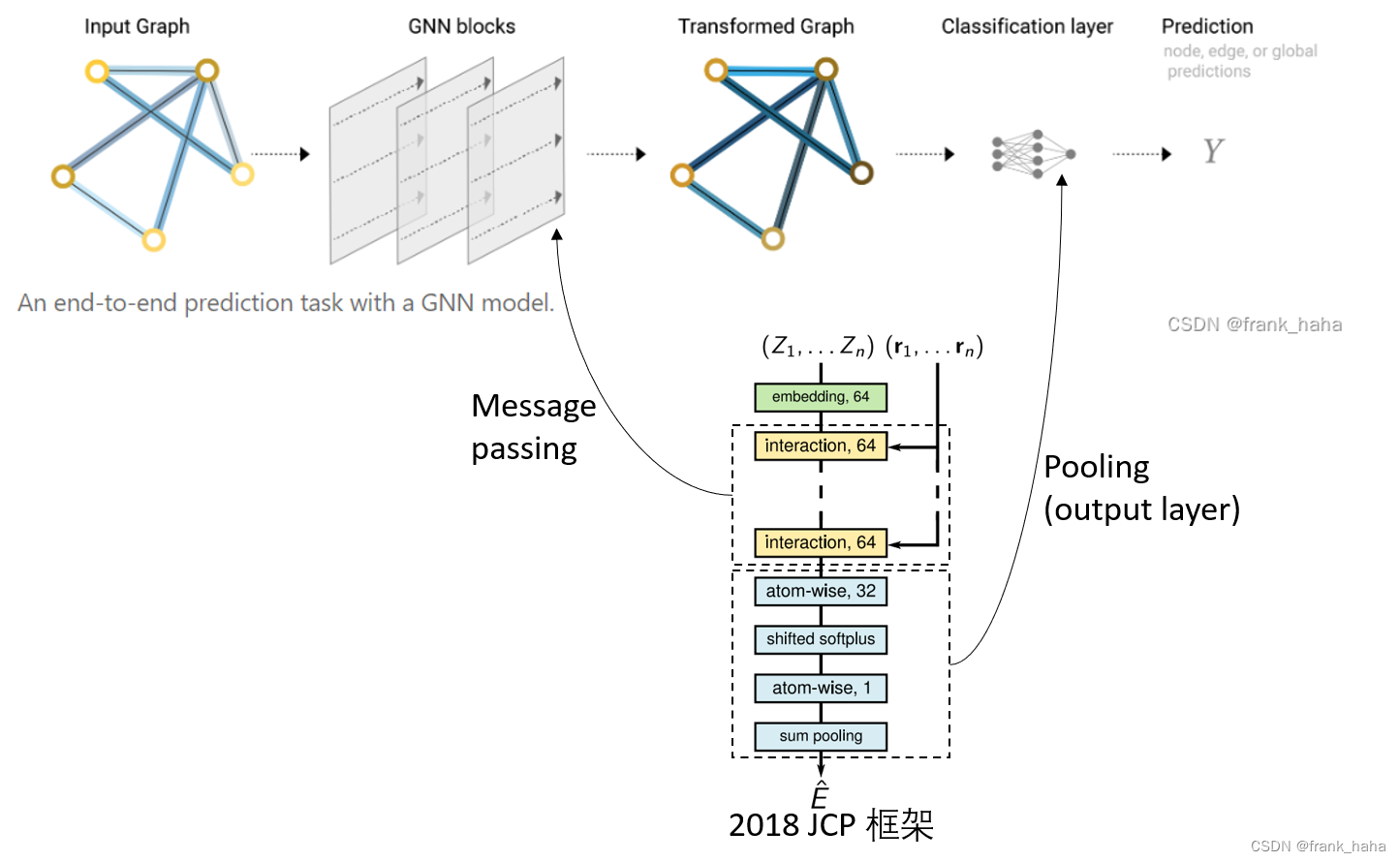
即,SchNet 是一个以点集为核心的框架:
- 先根据每个原子的元素种类去对该原子做一个映射,这一映射可以被看做是点的初始特征向量。
- 随后经过巧妙设计的 message passing layers,该特征向量聚合了周围节点的诸多信息,整张图获得了迭代更新。如何去设计 message passing layers 是整个 SchNet 模型的重中之重。
- 基于更新后的图对目标性质做预测,这一操作在 AI 领域叫 Pooling ,在SchNetPack 中叫 Output layer,就是一个简单的前向传递。
下面结合代码看一下各个步骤。
DIG 框架下的代码
DIG 改写后的 SchNet 代码仅有168行,非常适合入门阅读!
我们直接跳到主类的 forward 阶段:

可以看到,经过改写后的框架还是清晰易懂的,能够跟原文献的几个模块一一对应。
值得注意的是,此处的 update_e 在原文里是 interaction 的意思,在传统的 GNN 框架中就是 message passing.
此外,对元素的 embedding 也是参照了 NLP 的做法,初始化了一个 look up table ,这样可以保证,同样元素的原子初始化向量是一致的。
最后,整张图去进行预测时,也仅仅是保留的点的 feature (这套代码里的edge可以说是聊胜于无,就当成 message 看就行)
OK,下面我们重点看一下 message passing 是如何实现的。
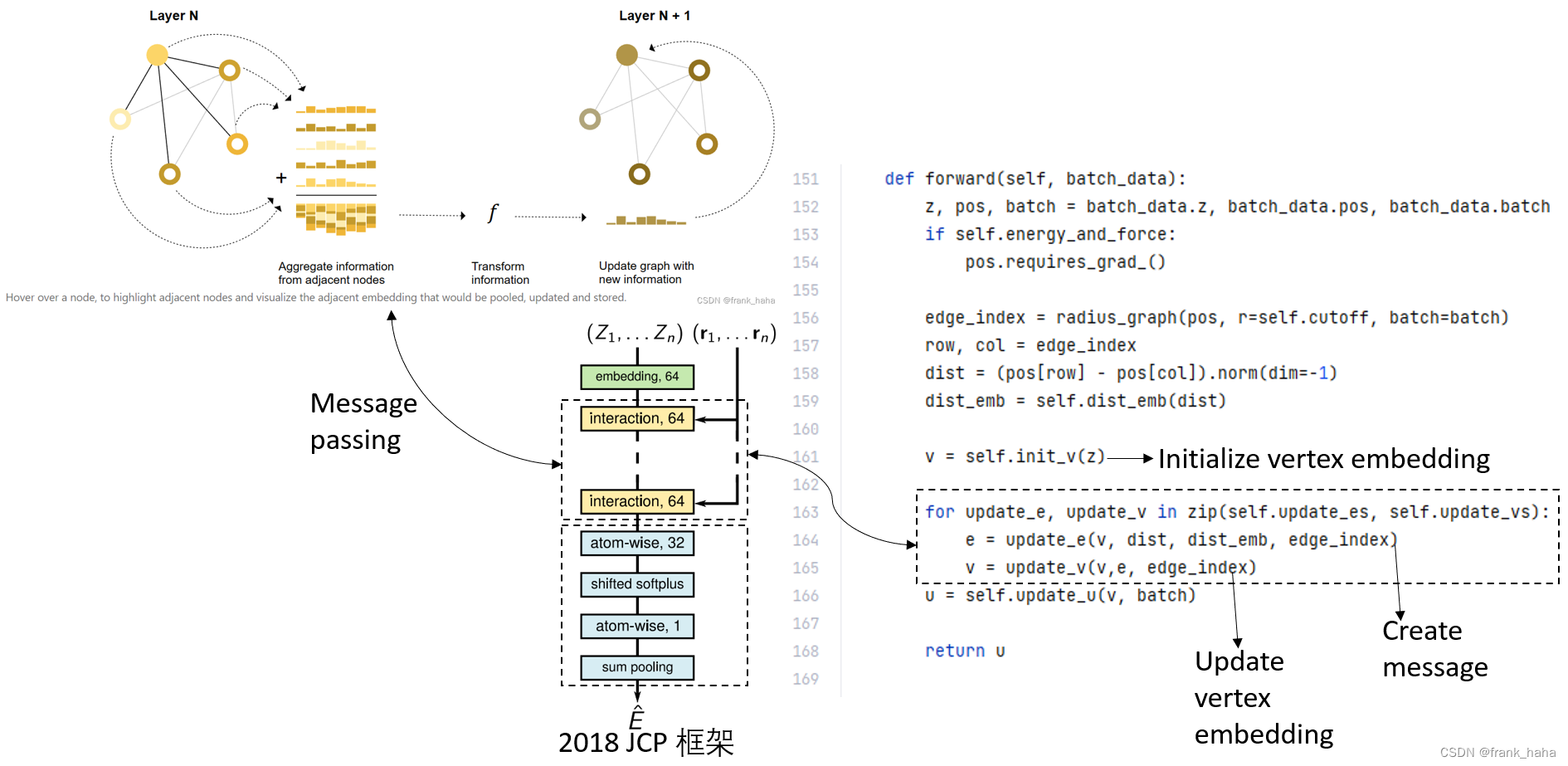
从 forward 主程序中可以看到,message passing 是由一个 for 循环构成的。在这个 for 循环下面,第一句话是构建 message ,第二句话是 节点feature的迭代。
其实与本专栏第一篇文章中提到的点集上的消息传递框架类似,某一节点根据其邻居节点的 feature 进行更新。这种方式是最简单的消息传递模型。
在 GNN expressive 这篇论文里,SchNet 框架如下所示:
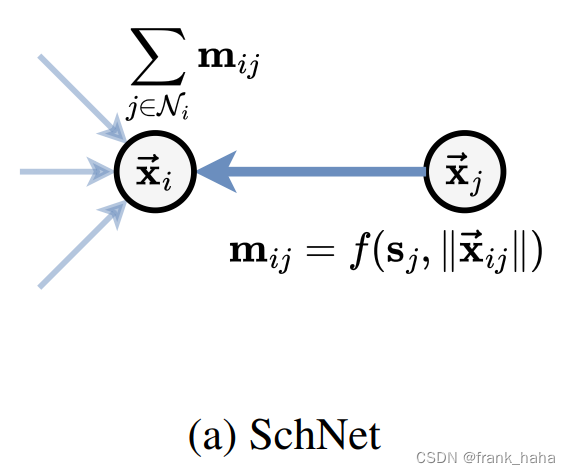
每个原子(i)有 Ni 个邻居(邻居指在截断半径内),每个邻居在迭代时会创造一个 message ,节点的 feature 在融合诸多 message 后进行下一次的迭代。
SchNet 模型被认为是一个 二体的 不变模型,其原因在于,其每次迭代只涉及 1-hop 的邻居,而且使用不变的距离信息(标量)。
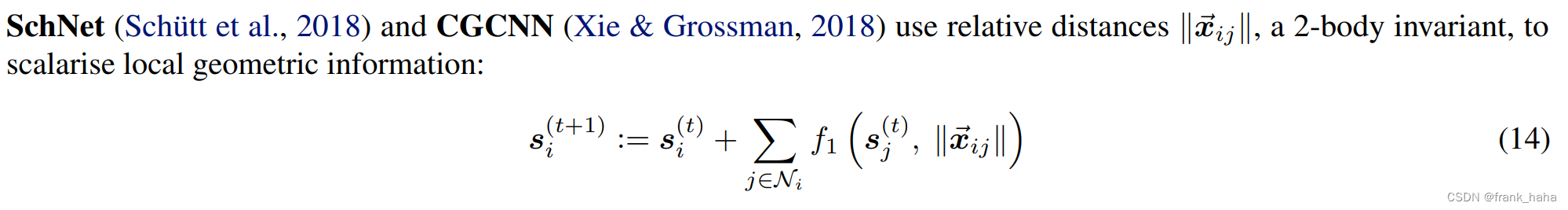
我们继续看原文中提到的 interaction 模块,其中的 filter generator 在代码中的 update_e 模块。
该模块的物理意义是,邻居原子对目标原子的影响力会随着距离的增大而衰减(C矩阵)。同时,邻居原子对目标原子的影响是一个距离的函数,而且该函数是可学的一个MLP模块(self.mlp(dist_emb))
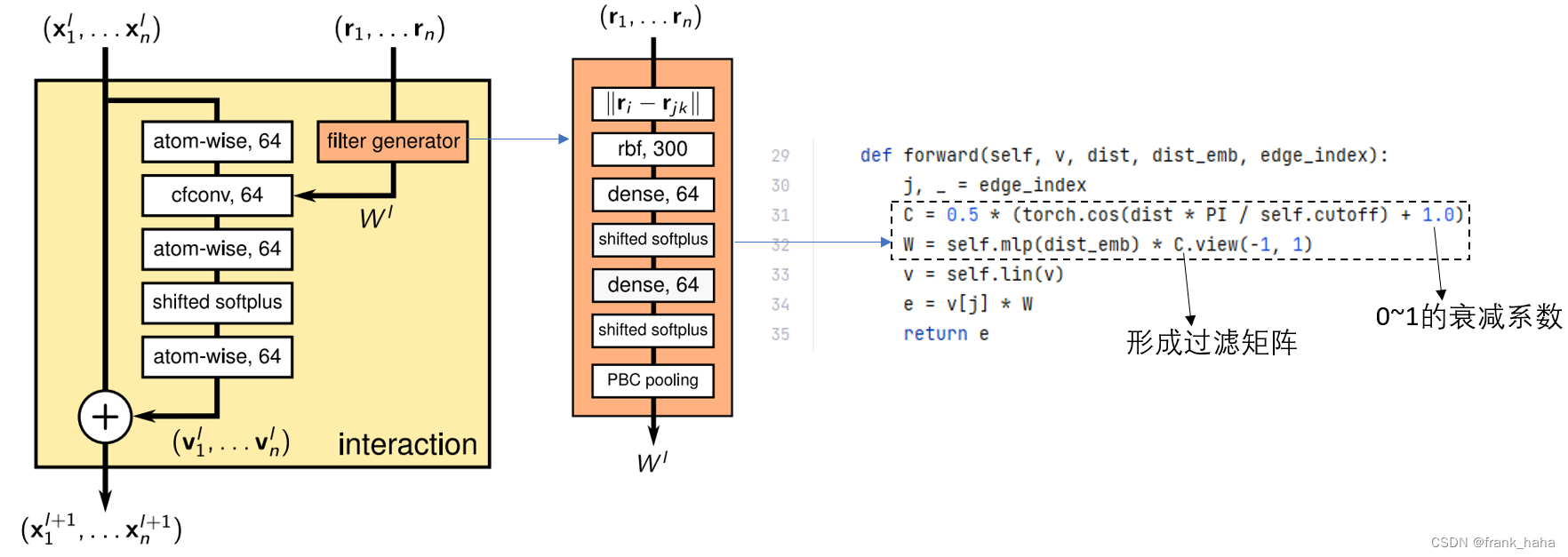
在理解了过滤矩阵后,我们再回头看 interaction 模块。其实这里 DIG 的代码和图中所示不太匹配,这里我们需要将 update_e 和 update_v 两个模块的 forward 连起来看。

两句话连起来对应一个 interaction 模块这一点应该很好理解。整个 interaction 的输入是 vertex embedding + distance embedding。
我们从下往上看,首先,比较明显的是 vertex update 含有一个短接,这一短接在 update_v 的 return 中是可以对上的。
那这个 out 再网上过了一个线性层+激活层+线性层,这也分别可以和 56,57,58对应,55 行则对应message的聚合,所以我前面一直强调 message 就是DIG框架中的e。
最后就剩下最开始的一块了。filter generator 是一个相对独立的小块儿,只与距离有关,对应31,32行,前文以提过。
有了 filter 以后,我们看 33 行。33行的线性层显然是 cfconv 层上面的 atom-wise 64
cfconv 层则对应 34 行,即,卷积核与邻居embedding的乘积。
至此,SchNet 模型中的核心代码已经全部能跟文献对应了。
一些感悟
下面我说一下自己的感悟。
我们深入学习一个模型,在读文献、看代码时,首先要看到整个模型大的模块。本例中,我首先将 SchNet 套到了一个 GNN 的框架里,然后用消息传递去近似原文中晦涩难懂的 interaction 模块。其次,我们要将文献中重点提及的模块跟代码进行一个映射,希望大家不要害怕扒代码。本例中,比较核心的代码加起来不到20句,在多读多思考的情况下,还是可以慢慢理解的(本人看了一天啊啊啊啊!!)。最后是一些 technical 的感悟,我们可以先把代码跑起来,然后在小batch size,debug 模式下进行观察,这将有利于从数据结构的角度理解算法模型!
希望大家看完这篇文章有所收获!!