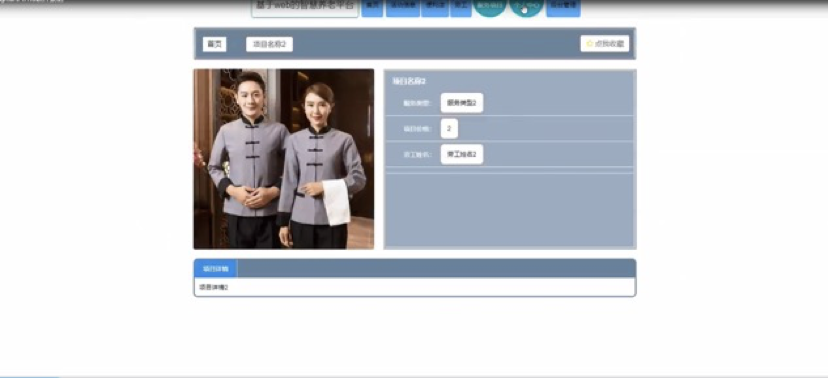
当您尝试训练大型语言模型时,您仍然经常遇到的最常见问题之一是内存不足。如果您曾尝试在Nvidia GPU上训练或甚至只是加载模型,那么这个错误消息可能看起来很熟悉。

CUDA,即Compute Unified Device Architecture的缩写,是为Nvidia GPU开发的库和工具集合。像PyTorch和TensorFlow这样的库使用CUDA来提高深度学习中常见操作的性能。
您会遇到这些内存不足的问题,因为大多数LLM都很大,需要大量的内存来存储和训练它们的所有参数。
让我们快速做些数学计算,以了解问题的规模。单个参数通常由32位浮点数表示,这是计算机表示实数的一种方式。您将很快看到如何以此格式存储数字的更多详细信息。32位浮点数占用四个字节的内存。因此,要存储十亿个参数,您需要四个字节乘以十亿个参数,或32位全精度下的4GB的GPU RAM。

这是很多的内存,注意,到目前为止,我们只计算了存储模型权重所需的内存。如果您想训练模型,您还必须为训练期间使用的GPU内存的其他组件做计划。这些包括两个Adam优化器状态、梯度、激活以及函数所需的临时变量。这可以轻松地导致每个模型参数需要额外的20个字节的内存。

实际上,为了考虑到训练期间的所有这些开销,您实际上需要的GPU RAM量是模型权重单独占用的大约20倍。

要在32位全精度下训练一个十亿参数的模型,您需要大约80GB的GPU RAM。

这对于消费者硬件来说绝对太大了,即使对于数据中心使用的硬件来说,如果您想使用单个处理器进行训练,也是具有挑战性的。80GB是单个Nvidia A100 GPU的内存容量,这是云中用于机器学习任务的常见处理器。
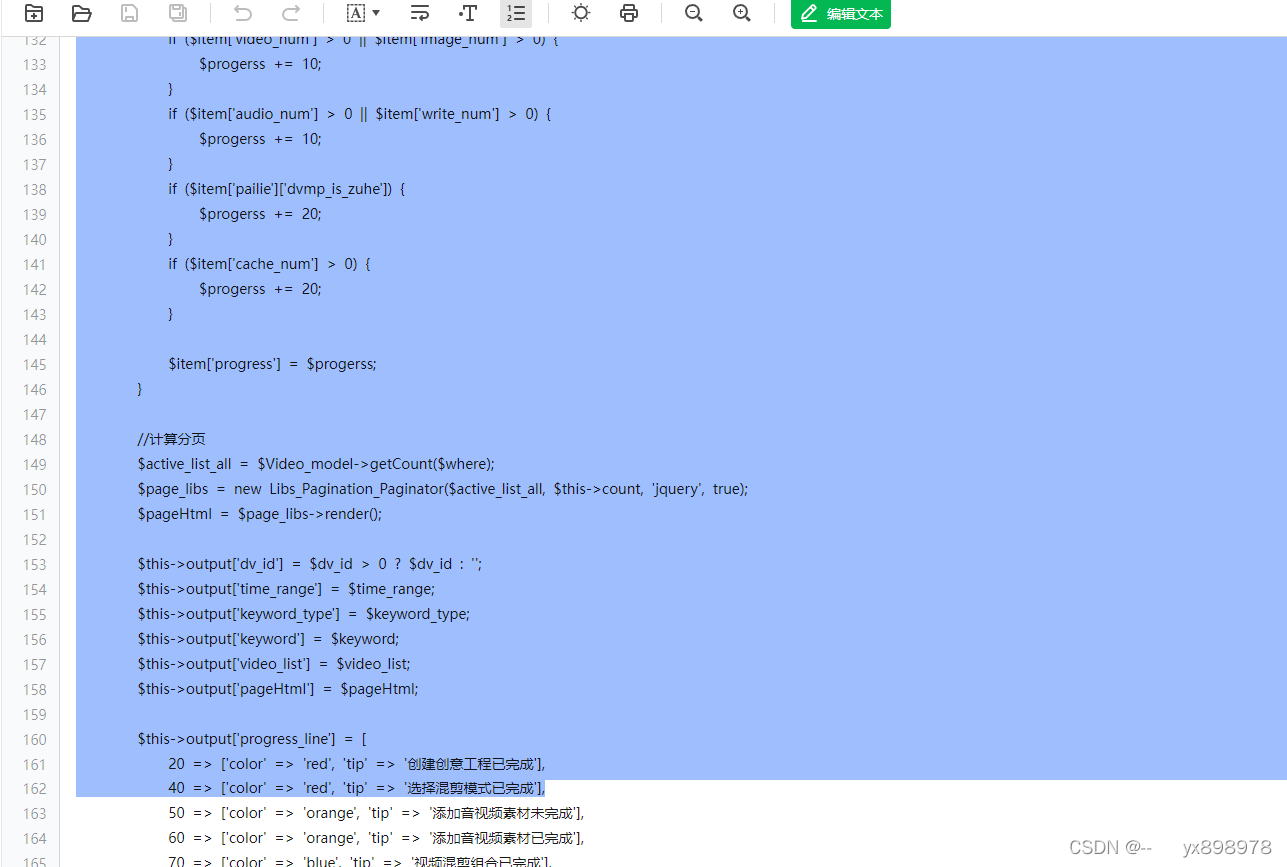
您有哪些选择来减少训练所需的内存?您可以使用的一种减少内存的技术称为量化。这里的主要思想是,通过将它们的精度从32位浮点数减少到16位浮点数或8位整数,来减少存储模型权重所需的内存。
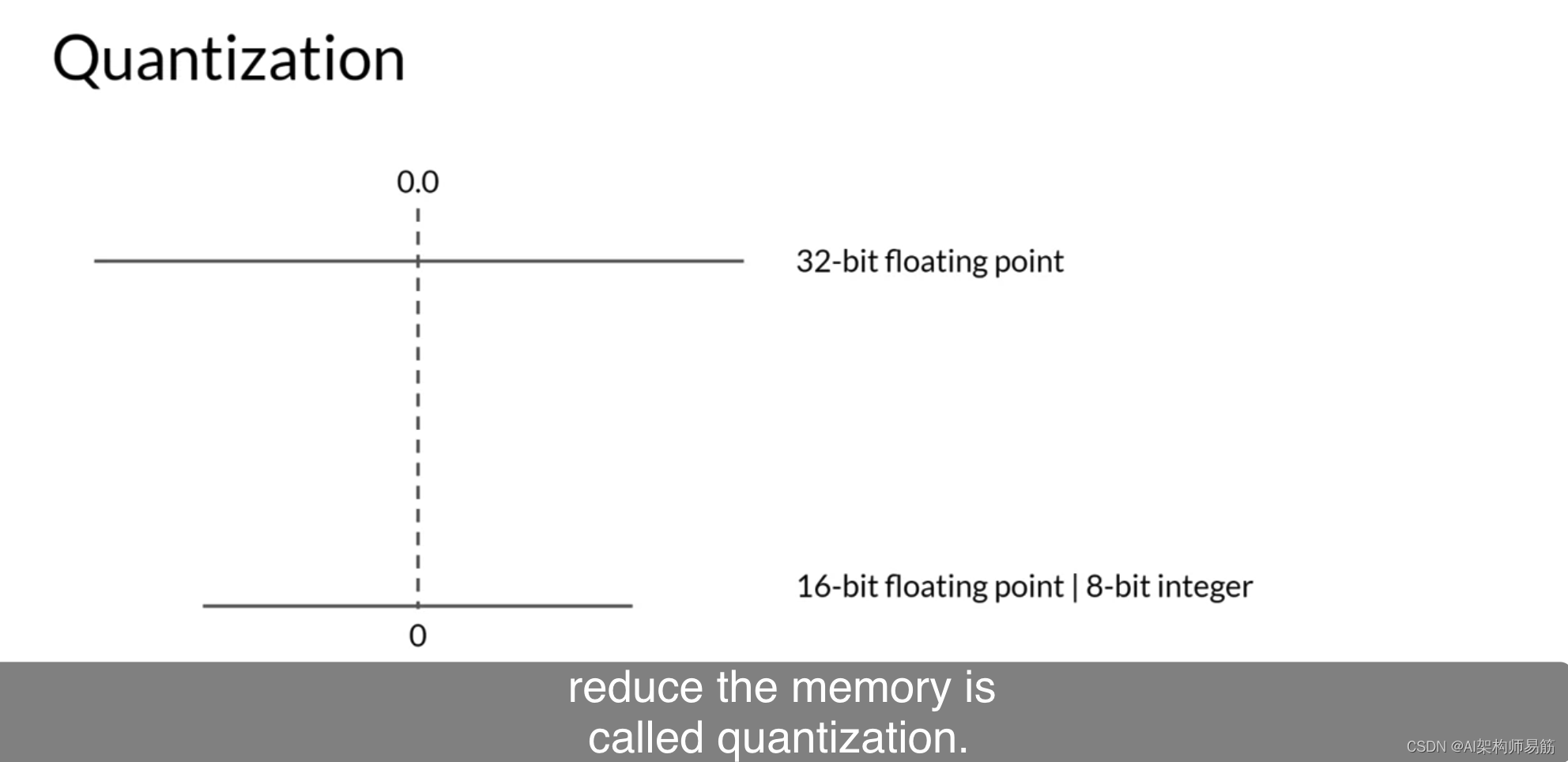
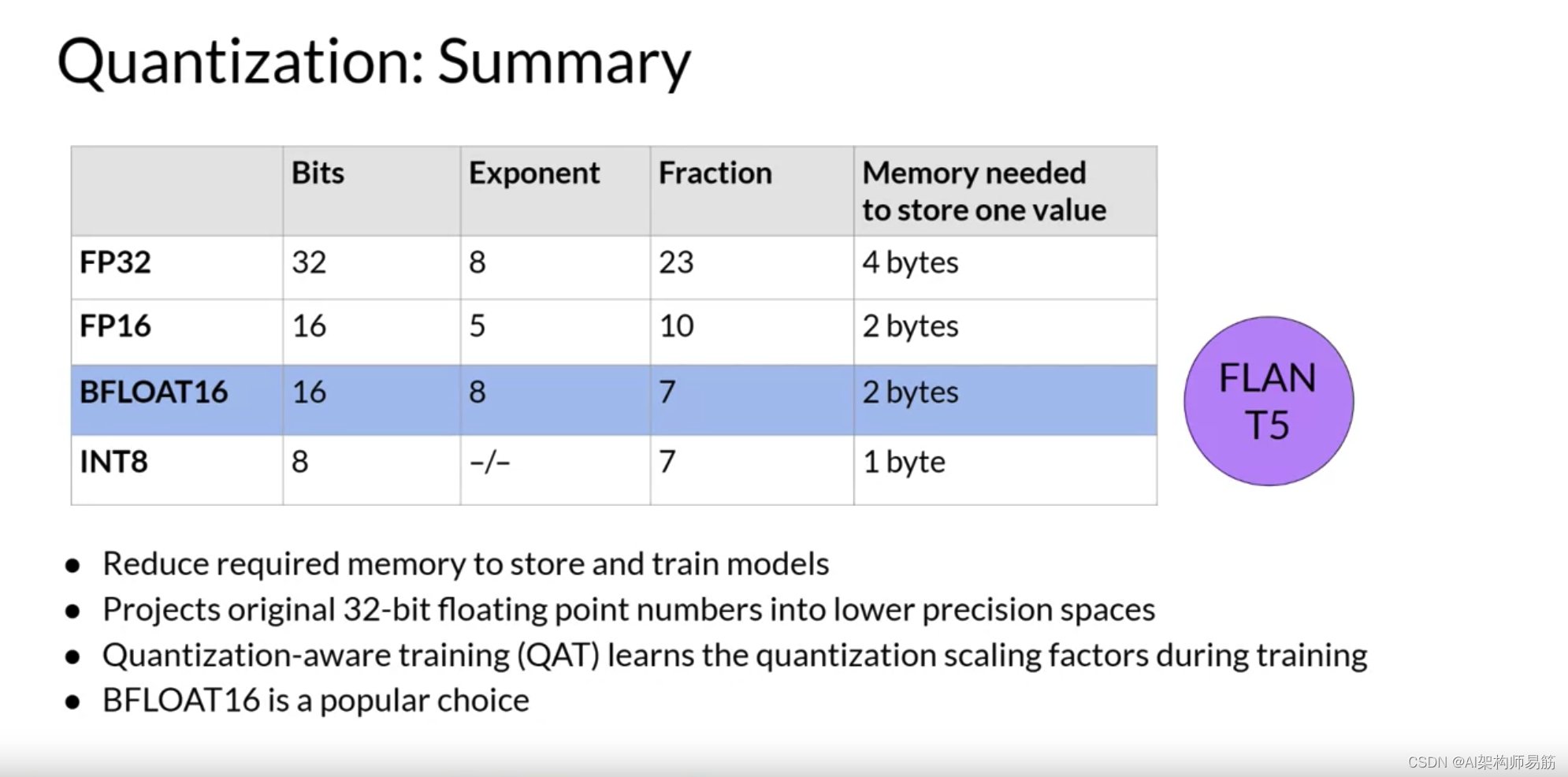
深度学习框架和库中使用的相应数据类型是FP32用于32位全位置,FP16或Bfloat16用于16位半精度,以及int8 eight-bit整数。
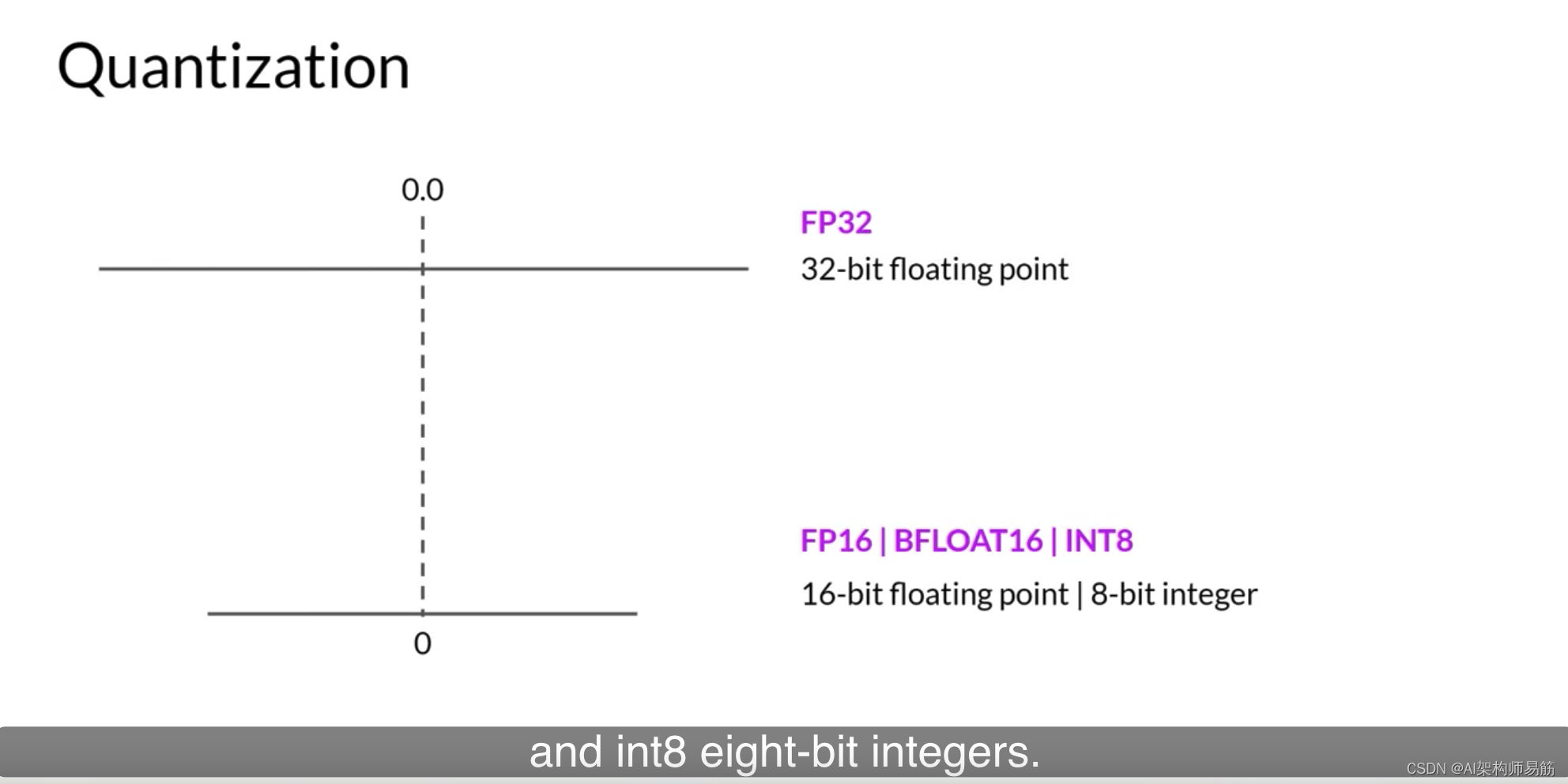
您可以使用FP32表示的数字范围从大约 3 ∗ 1 0 − 38 3 * 10^{-38} 3∗10−38到 3 ∗ 1 0 38 3 * 10^{38} 3∗1038。
默认情况下,模型权重、激活和其他模型参数都存储在FP32中。量化统计地将原始32位浮点数投影到基于原始32位浮点数范围计算的缩放因子的低精度空间。
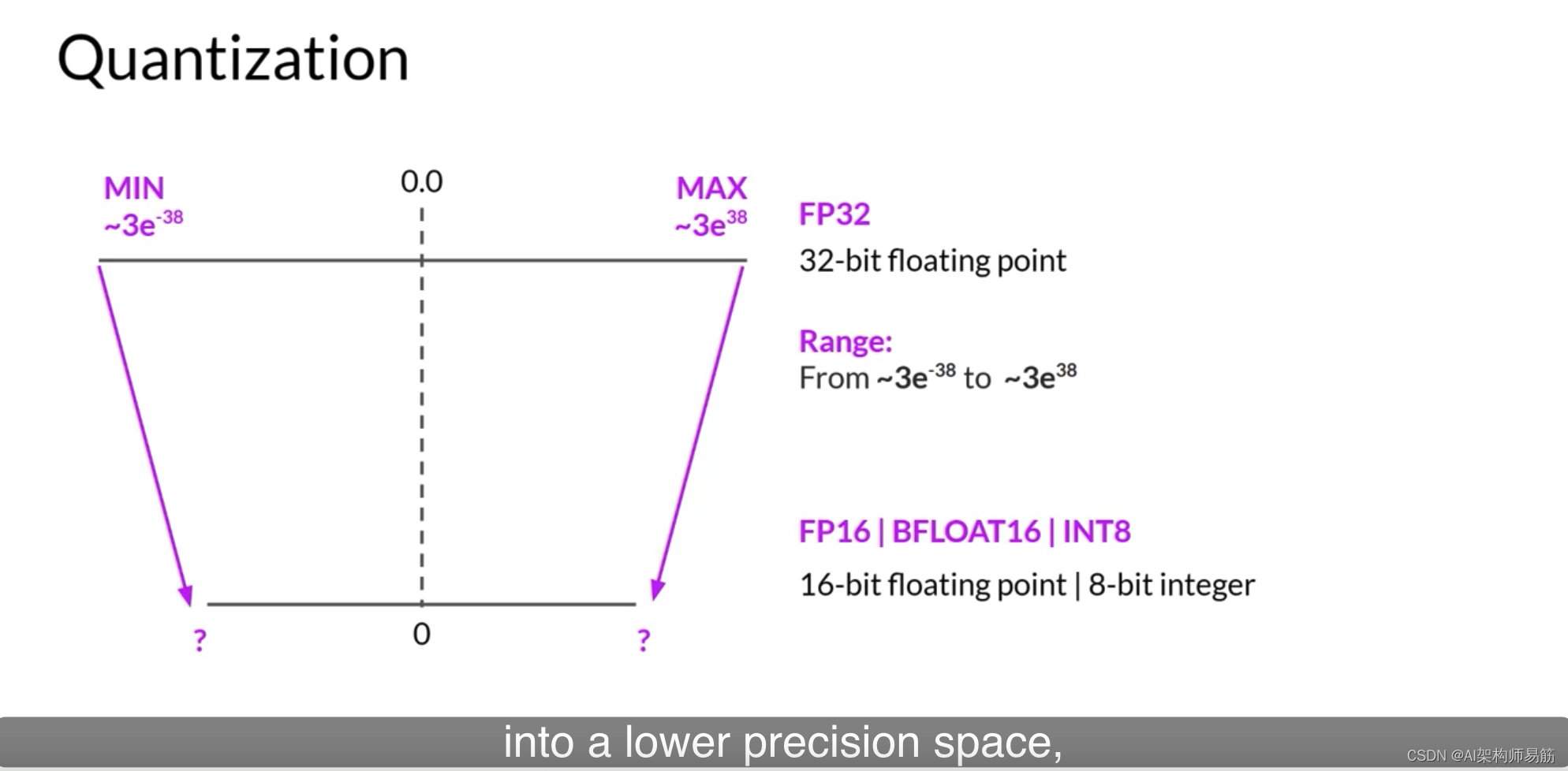
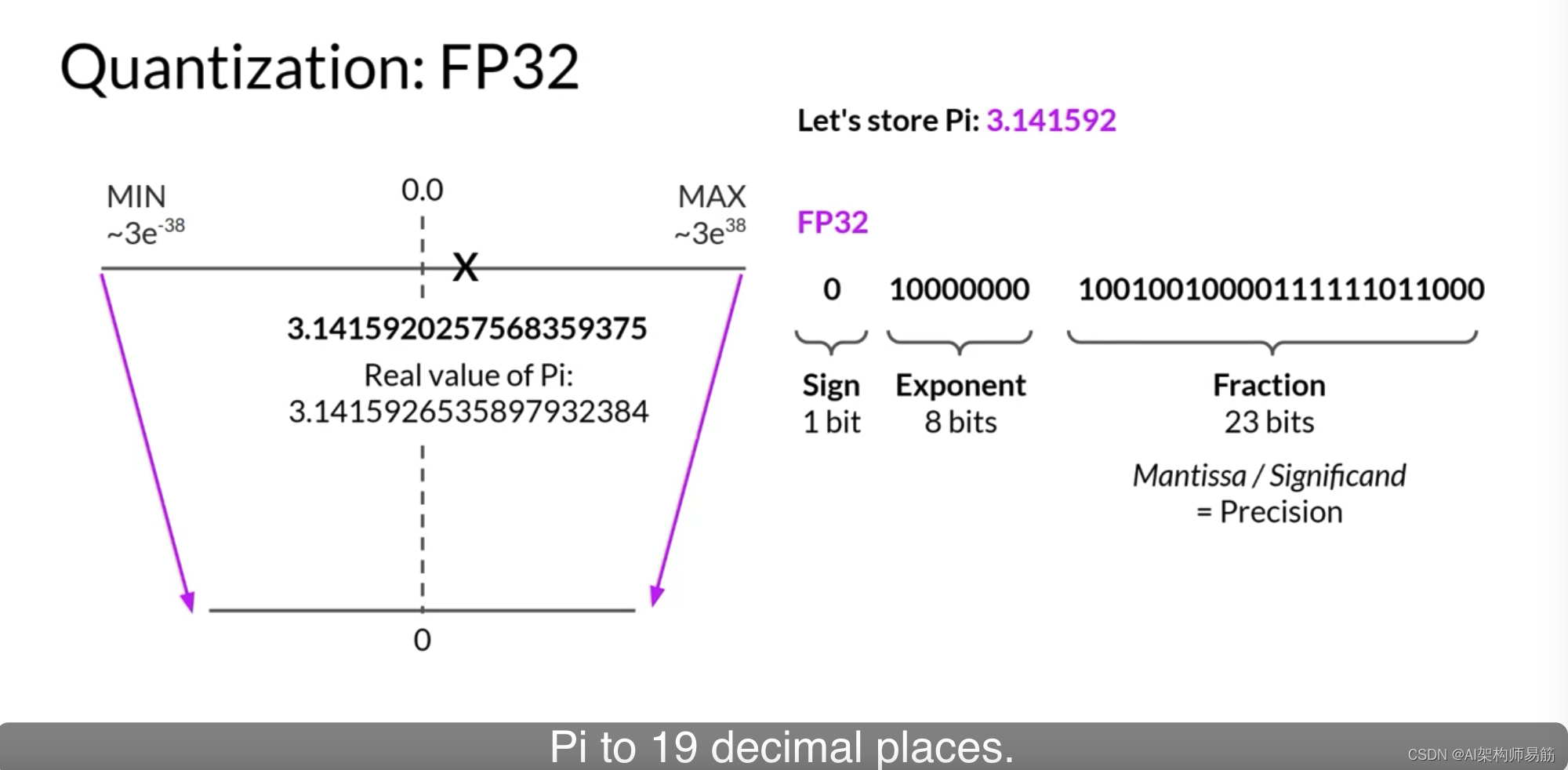
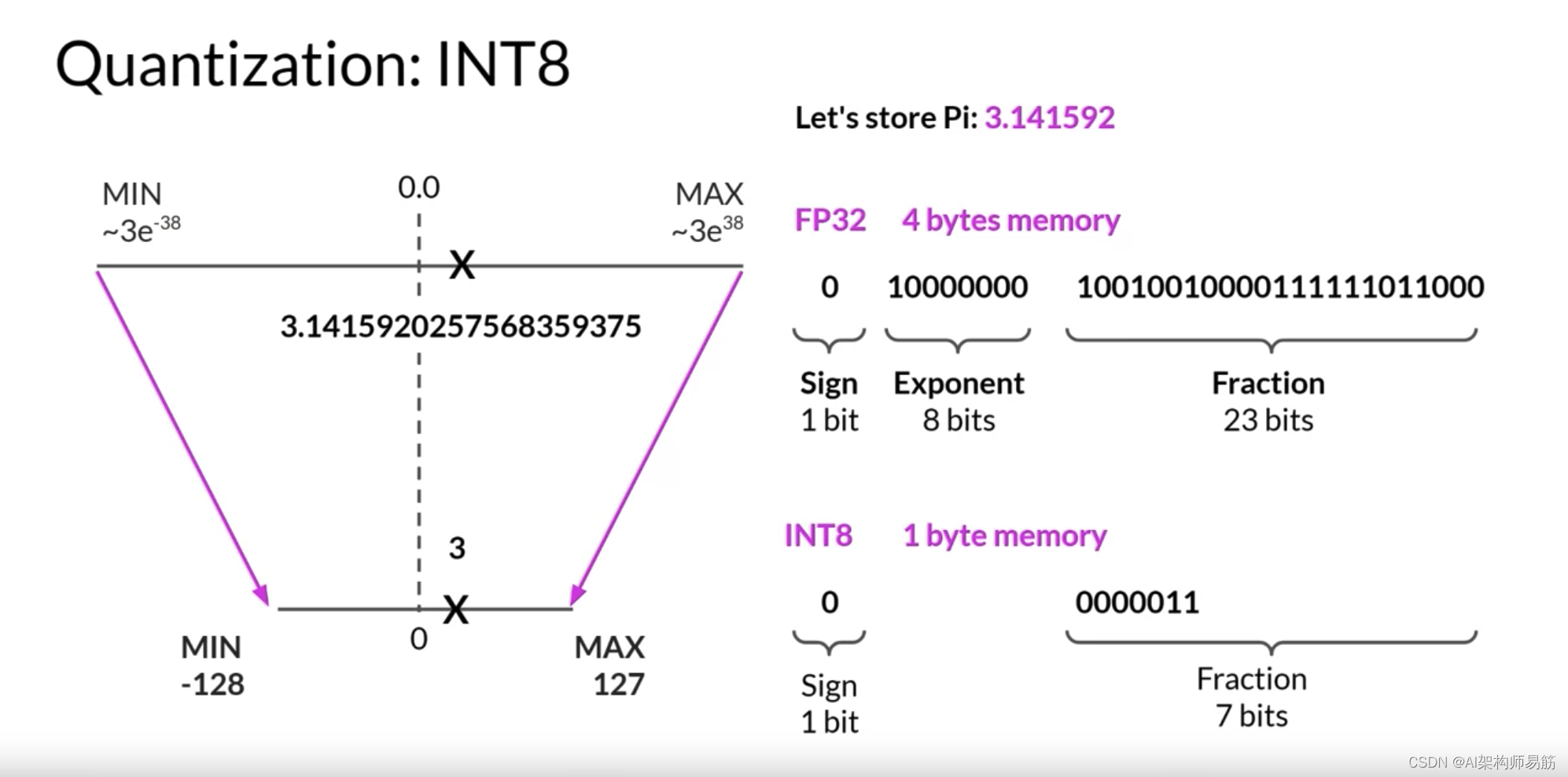
让我们看一个例子。假设您想在不同的位置存储PI到小数点后六位。浮点数存储为一系列位,零和一。在FP32中存储数字的32位由一个位表示符号,其中零表示正数,而一表示负数。然后是8位表示数字的指数,以及表示数字的小数的23位。小数也称为尾数或有效数字。它表示数字的精确位。如果您将32位浮点值转换回十进制值,您会注意到精度的轻微损失。为了参考,这是Pi的实际值,精确到19位小数。
现在,让我们看看如果您将这个FP32表示的Pi投影到FP16,16位低精度空间会发生什么。16位由一个位表示符号,如您所见的FP32,但现在FP16只分配五位来表示指数和10位来表示小数。因此,您可以使用FP16表示的数字范围远远小于从负65,504到正65,504。原始FP32值在16位空间中被投影到3.140625。注意,您在这个投影中失去了一些精度。
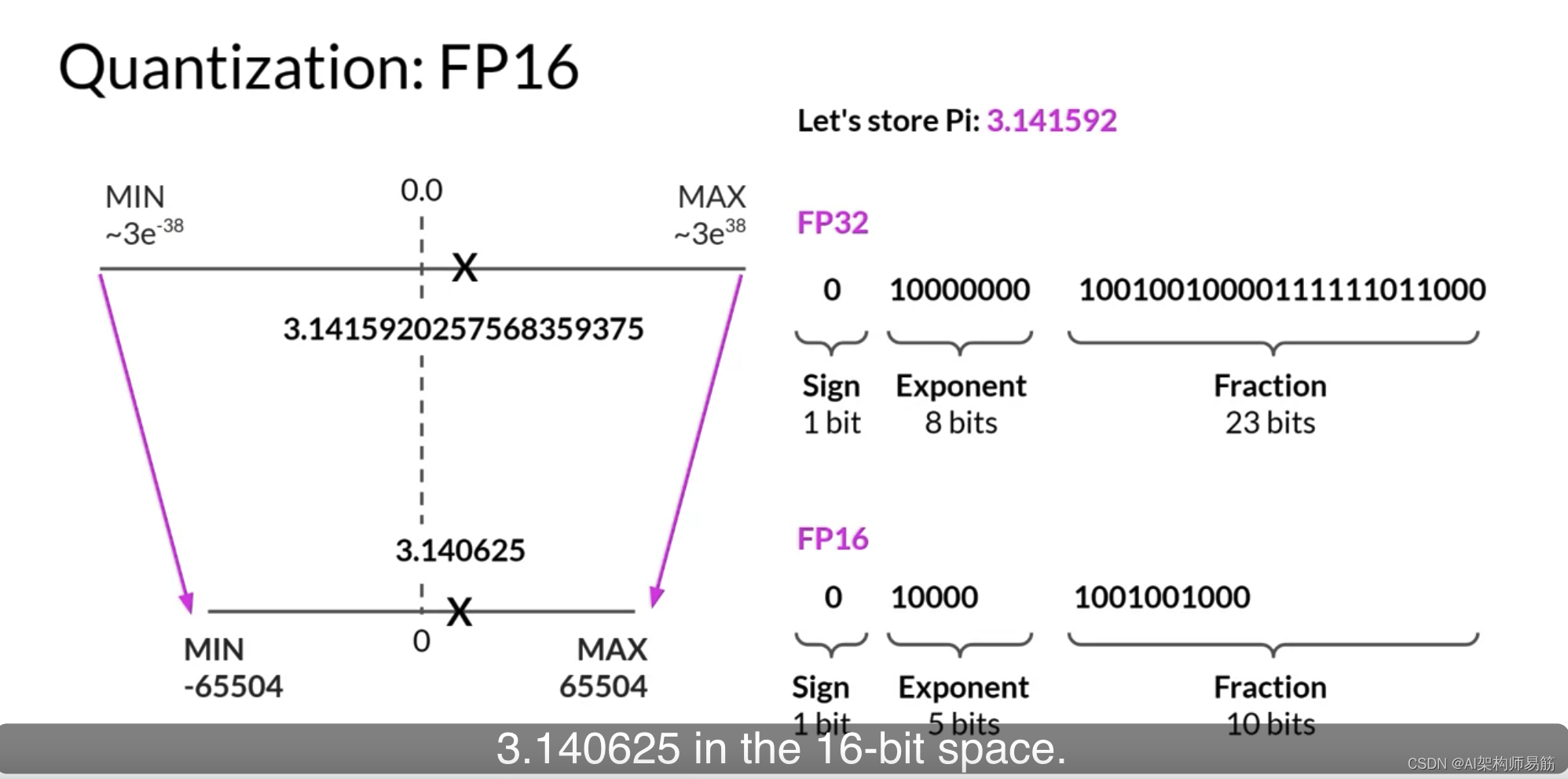
您会发现,在大多数情况下,这种精度损失是可以接受的,因为您正在优化内存占用。
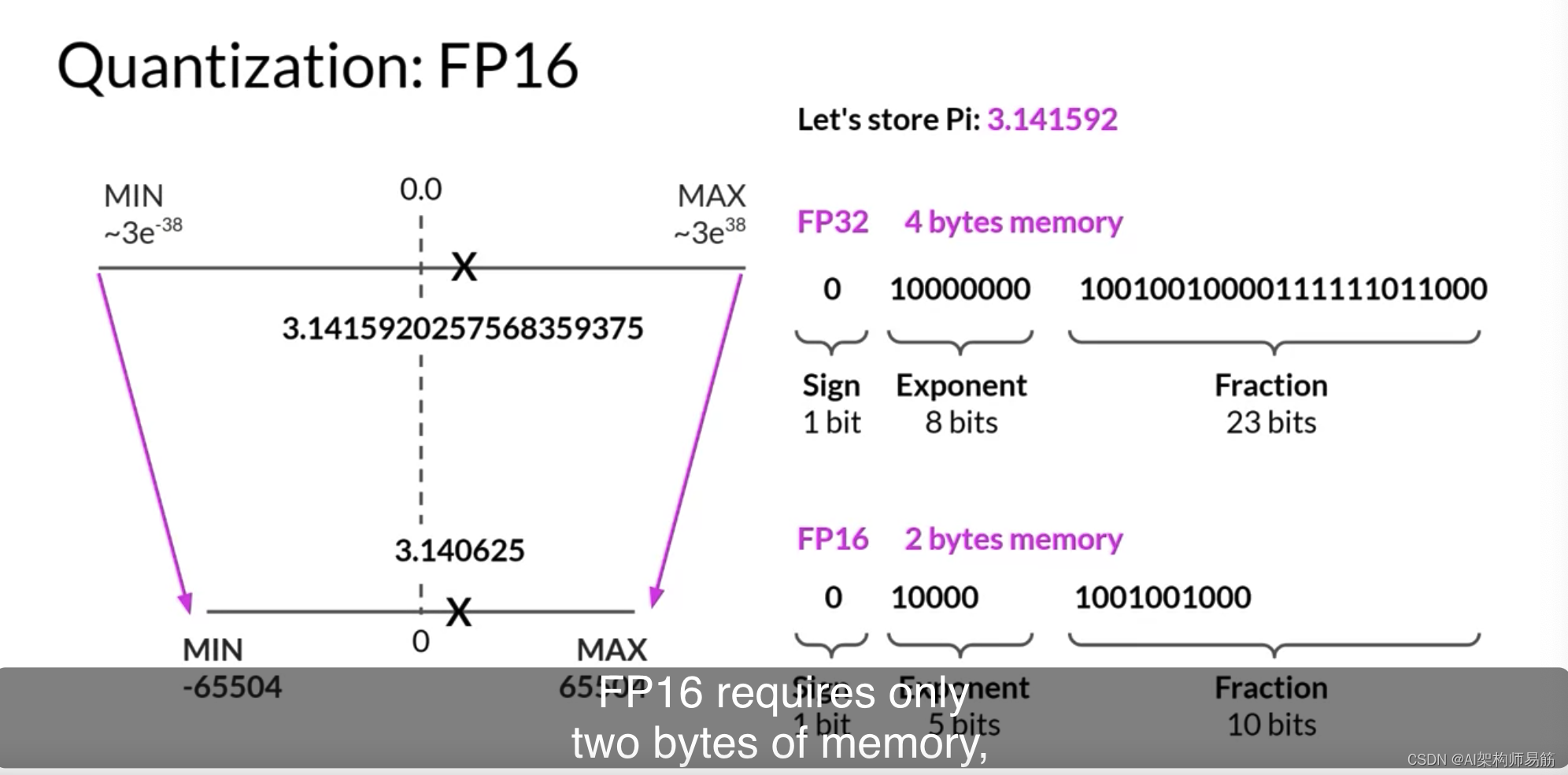
在FP32中存储一个值需要四个字节的内存。相反,以FP16存储一个值只需要两个字节的内存,所以通过量化,您将内存需求减少了一半。
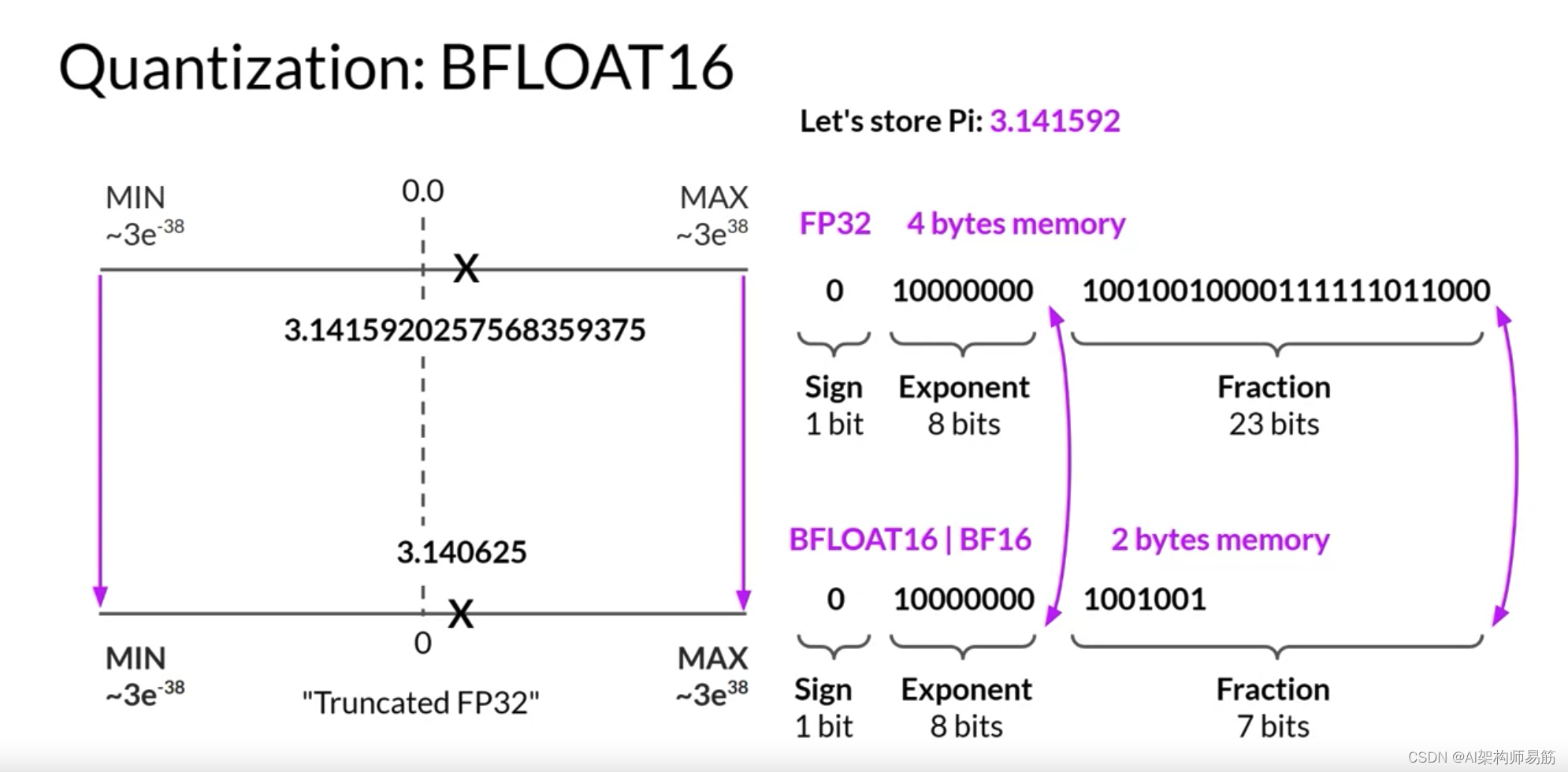
AI研究社区已经探索了如何优化16位量化的方法。尤其是BFLOAT16,最近已经成为FP16的流行替代品。BFLOAT16,简称Brain Floating Point Format,是在Google Brain开发的,已经成为深度学习中的流行选择。许多LLM,包括FLAN-T5,都使用BFLOAT16进行了预训练。
BFLOAT16或BF16是半精度FP16和全精度FP32之间的混合体。BF16显著地帮助训练稳定性,并得到了NVIDIA的A100等较新GPU的支持。BFLOAT16通常被描述为一个截断的32位浮点数,因为它捕获了完整的32位浮点数的完整动态范围,但只使用了16位。
BFLOAT16使用完整的八位来表示指数,但将小数截断为只有七位。这不仅节省了内存,而且通过加速计算提高了模型性能。缺点是BF16不适合整数计算,但在深度学习中这些相对较少。
为了完整起见,让我们看看如果您将Pi从32位量化到更低精度的8位空间会发生什么。如果您使用一个位表示符号,INT8值由其余的七位表示。这给了你一个范围来表示从负128到正127的数字,不出所料,Pi在8位低精度空间中被投影到或3。这将新的内存需求从原来的四个字节减少到只有一个字节,但显然导致了相当大的精度损失。
让我们总结一下您在这里学到的内容,并强调您应该从这次讨论中得到的关键点。
请记住,
- 量化的目标是通过减少模型权重的精度来减少存储和训练模型所需的内存。
- 量化统计地将原始32位浮点数投影到使用基于原始32位浮点数范围计算的缩放因子的低精度空间。
- 现代深度学习框架和库支持量化感知训练,该训练在训练过程中学习量化缩放因子。这个过程的细节超出了这门课程的范围。但您已经看到了这里的关键点,即您可以使用量化来减少训练期间模型的内存占用。
- BFLOAT16已经成为深度学习中的流行选择,因为它保持了FP32的动态范围,但将内存占用减少了一半。许多LLM,包括FLAN-T5,都使用BFOLAT16进行了预训练。
请在下周的实验室中注意BFLOAT16的提及。
现在,让我们回到将模型适应GPU内存的挑战,并看看量化可能带来的影响。通过应用量化,您可以将存储模型参数所需的内存消耗减少到只有2GB,使用16位半精度,节省了50%。您可以通过将模型参数表示为8位整数,进一步减少内存占用,这只需要1GB的GPU RAM。请注意,在所有这些情况下,您仍然有一个拥有十亿参数的模型。正如您所看到的,代表模型的圆圈大小相同。

量化在训练时也会给您带来同样程度的节省。正如您之前听到的,当您尝试在32位全精度下训练一个十亿参数的模型时,您很快就会达到单个NVIDIA A100 GPU的80 GB内存的限制。当您尝试在单个GPU上进行训练时,如果您想使用16位或8位量化,您需要考虑使用它。

请记住,现在许多模型的大小超过了500亿甚至1000亿参数。这意味着您需要更多的内存容量来训练它们,数万GB。这些巨大的模型使我们一直在考虑的十亿参数模型相形见绌,

如左图所示。当模型规模超过几十亿参数时,使用单个GPU进行训练变得不可能。相反,您需要转向分布式计算技术,同时在多个GPU上训练模型。这可能需要访问数百个GPU,这是非常昂贵的。

这也是为什么您大多数时候不会从头开始预训练自己的模型的另一个原因。
但是,还有一个额外的训练过程叫做微调,您将在下周了解。也需要在内存中存储所有训练参数,而且您很可能希望在某个时候微调模型。
为了帮助您更多地了解跨GPU训练的技术方面,我们为您准备了一个可选的视频。它非常详细,但它将帮助您了解一些为开发人员提供的训练更大模型的选项。您应该随意跳过这个视频。但如果您有兴趣了解更多,我希望您会查看它。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/gZArr/computational-challenges-of-training-llms

![[保研/考研机试] KY223 二叉排序树 华中科技大学复试上机题 C++实现](https://img-blog.csdnimg.cn/7fae8385e78d4a24832e005ef566c00a.png)