1、应用大模型
AIGC 是基于大模型的,而大模型的基础是深度学习。上一篇文章对深度学习进行了初步介绍,首先是深度学习的神经元起源,引发了基于线性函数的模拟,又因为线性函数无法习得逻辑异或,因此引入了非线性的激活函数,再通过三层神经网络给出了MNIST手写数字识别的模型,接着又介绍了神经网络是如何通过数据与反向传播来学习与调整参数的,最后给出了神经网络的分层结构。
大模型的直观应用当然首先体现在包括ChatGPT、文心一言、讯飞星火等问答型产品的使用上,另一方面也体现在编程上,在此先给出大模型的编程应用。以下使用的模型、库与样例均来自于Hugging Face。
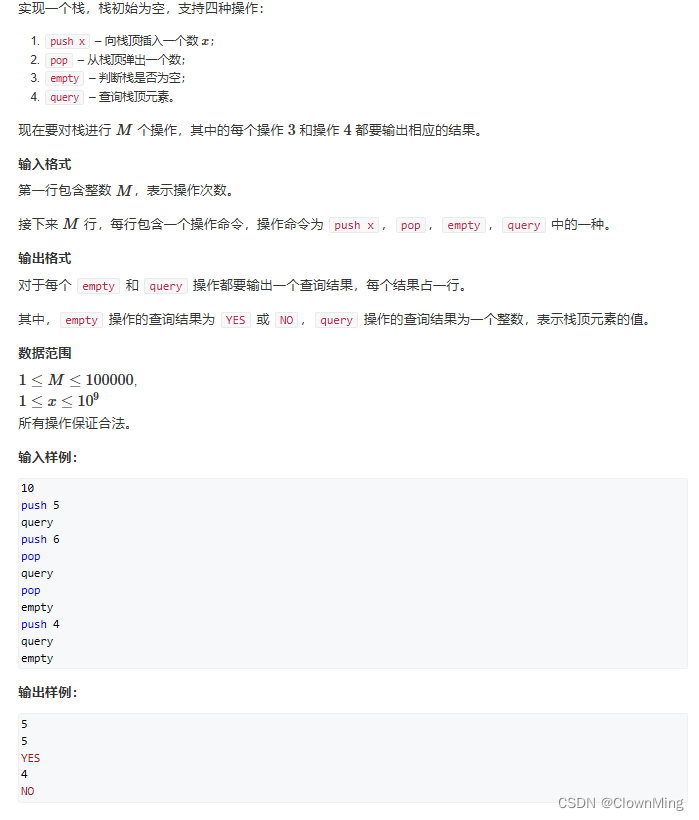
图1给出了基于大模型的英中翻译代码与运行结果。从图1中可以看到,真实的翻译代码只有14、15两行,其逻辑是使用了Helsinki-NLP的opus-mt-en-zh模型,其中mt代表机器翻译(machine translation)、en和zh分别表示英文和中文。从图1中同样可以看到,翻译结果相对还是比较准确的。
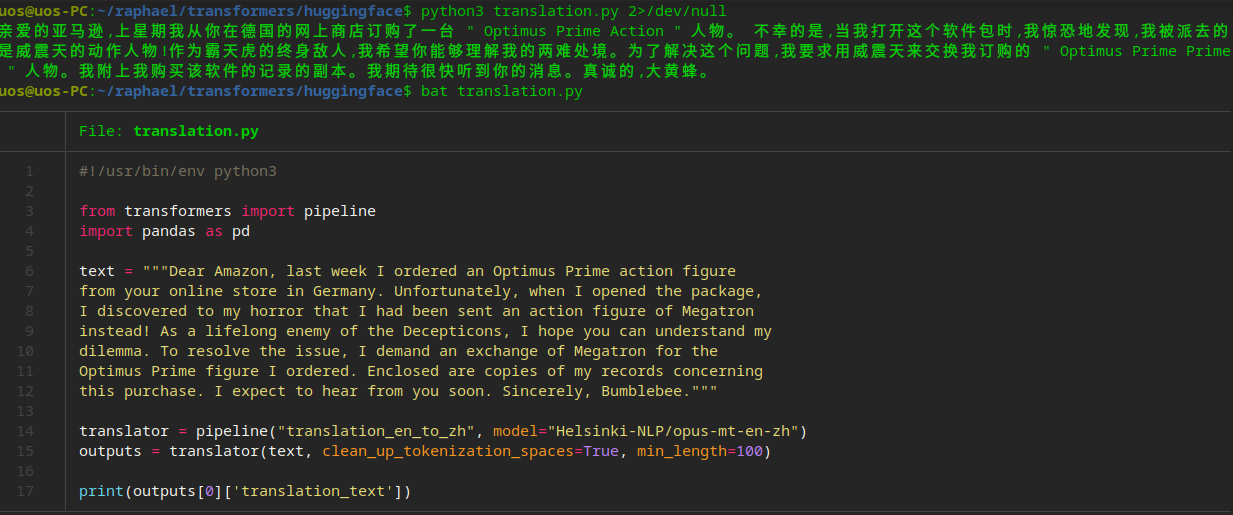
图1 基于大模型的英翻中
图2给出了基于大模型的文本情感分析的代码与运行结果。从图2中可以看到,实际有用的代码也仅需14、16两行,而且这次没有指定具体模型,只给出了需要text-classification这种模型。代码运行结果是认为文本情绪是负面的(NEGATIVE),准确度大概是90.1546%,这显然是符合实际的,因为文本是对商家发错货的抱怨。
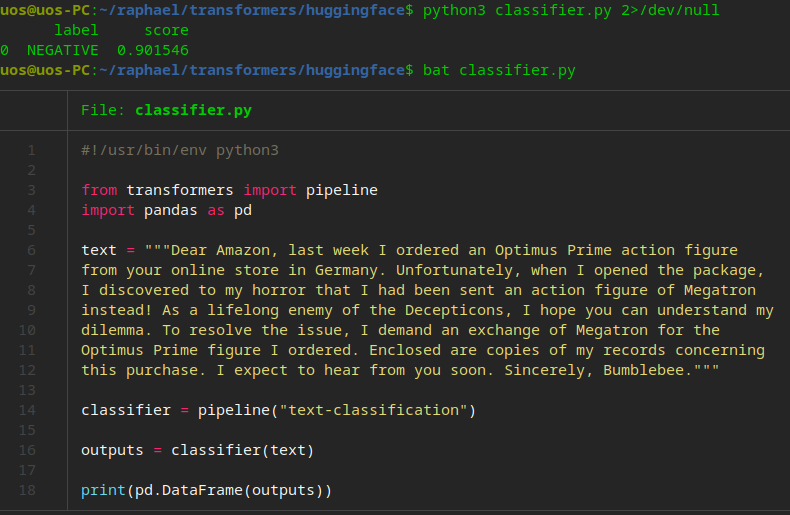
图2 基于大模型的文本情感分析
图3给出了基于大模型的问答。这次的代码稍多一点,但实际的代码也只有三行。第14行给出了需要一个问答(question-answering)的大模型,但是没有指定大模型的名字,第15行是提问的字符串“What does the customer want”,即用户到底想要什么。第16行则使用上述文本作为上下文,提问字符串作为问题,传给问答大模型获取答案。从运行结果看来,答案还是蛮靠谱的。
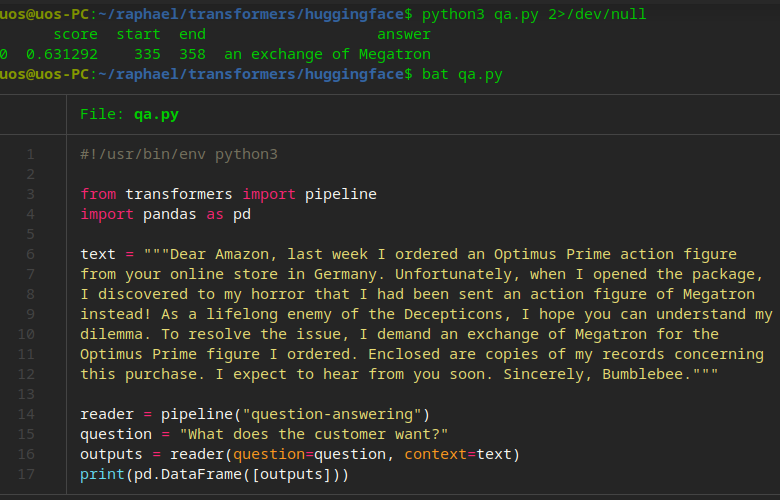
图3 基于大模型的问答
当然,基于大模型的程序还有很多,但是从上面三个例子已经可以看出,基于大模型可以写出简短而强大的自然语言处理的程序,下面让我们走进大模型,看看它究竟是如何做到这一点的。
2、走进大模型
大模型在自然语言处理领域里大放异彩,因此首先需要了解自然语言的特点。
自然语言的显著特点(也是难点),那就是词与词之间有着广泛的关联。比如下面两句英文:
-
Go to the bank to get some money.
-
Go to the bank to get some water.
只有看到每一句的最后一个词,才能分辨出 bank 到底是银行还是堤坝。再比如下面这两句中文:
-
今天太冷了,能穿多少穿多少。
-
今天太热了,能穿多少穿多少。
整句话唯一不同的就是冷与热这两个字,但也就是这句话的一字之差,就导致了整句话的意义完全不同了。
因此,自然语言处理的关键点就在于如何能准确地判断词与词之间的关系,如果能准确地知道所有词之间的关系,那即使缺了一个词,也能根据关系推出缺的词应该是什么词。当下处理这一问题的主流技术是transformer,这个词不好翻译,主要因为它和变形金刚的英文一模一样。transformer的核心概念是注意力(attention),即每个词到底在注意其它的哪个词,或者说哪些词之间有什么关系。
注意力具体由以下关键概念组成:
-
每个词(实际上是词元,token)均有对应的 q/query(查询)、k/key(键值)与 v/value(值)这三个矩阵变量
-
q[i]用来查询本词(i)与其它词(j)之间的注意力
-
k[j]是词j回应查询的键值,具体是q[i]与k[j]相乘后缩放,接着用softmax激活函数处理,再乘以v[j],这就得到了词i针对词j的注意力att[i,j]。
-
词i的对应输出为计算得到的注意力之和,即 y[i] = att[i,1] + att[i,2] + ... + att[i,n]
-
注意力可以有多个(multi-head),每个注意力可以关注不同的方向,例如有的注意力关注的是词与词之间的意义,有的关注的是押韵,等等
图4给出了一个句子中各个词注意力的计算过程。
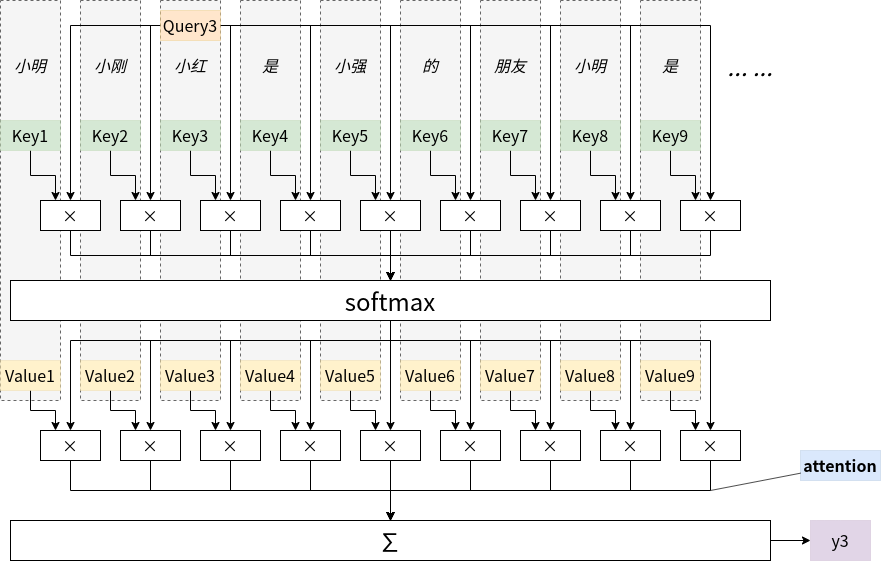
图4 注意力计算过程
句子是“小明、小刚、小红是小强的朋友,小明是...”,当前的词是“小红”,序号是3,可以看到小红的q值与每个词的k值相乘之后再用softmax处理(缩放操作在这里省略了),接着再与每个词的q值相乘,最后相加即可得到序号为3的输出。
那么这些k、q、v 等的值如何确定呢?当然是通过上一篇文章里提到的反向传播进行学习的,那反向传播学习自然语言的正确输出是什么呢?在大语言模型中,其训练手段是使用大量的高质量语料,将词语按序逐批输入大模型,以原句子中的下一个词或者特意被空缺出来的词为正确输出来学习的。例如在上面的句子中,大模型在输入了“小明、小刚、小红是小强的”之后,应该能计算输出“朋友”这个词,如果输出错误,则通过反向传播调整各个参数。也就是说,大模型就是根据一个词之前的词或者周围的词是什么来计算出这个词的,这就是大模型的理论基础和学习方法。
注意力虽然是大模型的核心概念,但除此之外,大模型还用到了其他技术,它们包括:
第一步需要将词转为数值向量(vector)的嵌入层(embedding),这也是现在很火的向量数据库的那个向量,向量数据库就是用来查询哪些文本向量比较相似,从而提取出对应的文字材料的
给词向量加上含位置信息的位置编码,以分辨出词的先后顺序,显然“我爱你”与“你爱我”的意义截然不同,因此词序是很重要的,而注意力本身并没有用到词序
在注意力层之后的残差处理与归一化处理,技术原理并不难,感兴趣的读者可以看参考资料
现在我们已经对大模型的主要技术原理有了粗浅的了解,下面来看看深度学习与大模型的特点。
3、大模型的特点
从对深度学习以及大模型的初步应用与原理了解,其实我们已经可以得出一些结论。
首先,深度学习的算法模型是神经网络及其节点上的参数/权重构成的,深度学习是端到端的机器学习,它不用由人类专家预先设计特征算法,例如不用苦思冥想怎么设计一个提取图像中线条的算法,只需要用大量的高质量标注数据对其进行投喂,就有可能最终训练出质量不错的神经网络(中的各个参数)来。
其次,它是一个黑盒子,因为没有特征设计,因此这么多数值构成的神经网络,它为什么能达到最终的目标,为什么某个参数就必须是最后训练出来的那个数值,为什么有的时候识别会失败或者生成会出错,是否可以手工修改某些特定的参数使得其成功率上升,同时又不会导致原来成功的事例失败,这些问题在现阶段都是难以回答的,这就是深度学习的可解释性问题。
在ChatGPT之前,大模型其实也在发展,但是ChatGPT表现出来的多领域通用性和流畅性与之前的产品相比有明显的超越,所以造成了轰动。其后的GPT-4表现更为优异,在《Sparks of Artificial General Intelligence:Early Experiments with GPT-4》这篇论文里,微软团队给出了这样的一个示例:
提问:Can you write a proof that there are infinitely many primes, with every line that rhymes?
GPT4:Yes, I think I can, Though it might take a clever plan.
I’ll start by noting Euclid’s proof, Which shows that primes aren’t just aloof.
Assume we have a finite list, Of primes, and that none have been missed.
Multiply them all together, And add one, just to be clever.
The result will be a number, That has no prime factors, oh wonder!
But every number has a prime, That divides it, it’s just a matter of time.
So we’ve found a contradiction, And our finite list needs eviction.
There must be infinitely many primes, And that’s the end of my rhyming lines.
提问者让GPT-4写一首诗,来证明素数有无限多个,然后GPT-4很快就完成了这首诗,每两行押韵,而且用欧几里得的经典方法给出了证明。当然,在论文中还有很多让人印象深刻的例子,但是上面的例子已能说明GPT-4确实有了很强的能力。
GPT中的G表示生成(Generative),这表示它主要的工作方式是生成内容,内容在这里主要是自然语言文本。按照OpenAI首席执行官Sam Altman的说法,The most important difference between ChatGPT and GPT-4, is that the GPT-4 predicts the next word with greater accuracy,即 ChatGPT与GPT-4最大的差异就在于GPT-4在预测下一个词的准确度比ChatGPT更高。
GPT中的P表示预训练(Pretrain),即首先用大量语料训练出基础模型(foundation model),然后再用下游任务相关的语料进行精调(FT,即finetuning)。这些下游任务可能是文本分类、翻译、对话等等,这样就可以不用单独为某个特定任务从头训练了。我们可以把中学教育和通识教育看作是预训练,它为大学最终的专业选择,以及以后更细的工作分工打下了坚实的基础。反过来看,在小学年龄阶段没有上学可能会对以后的择业带来很大的限制,这也可以看成是大脑在应预训练的阶段没有进行有效的预训练导致的问题。
GPT中的T表示transformer,这个已经在上文中介绍了。
一般认为,GPT-4有更强能力的原因在于:
-
它提供了大量的高质量数据,原始数据有45T,清洗后的语料是570G,清洗比例接近1%,这是之前几乎没有团队做到的
-
数据中混合了大量的代码,原始数据中有830G代码,这一般被认为是推理能力提升的关键点之一,当然另一方面也大大提升了它的代码能力
-
展开了大量不同种类的下游任务,如生成、问答、脑暴、闲聊、摘要、分类、提取等等,以上两点也属于多样化工作,它为GPT4的通用性打下了基础
-
使用了基于人工反馈的增强学习(RLHF)方法,召集了40个众包团队,撰写了数十万的提示数据以对齐主流价值观
一般认为,大模型的表现之所以如此智能,但是之前的小模型神经网络却那么智障,其原因可能在于涌现(emergence)。涌现可以简单认为是单个个体微观上简单的行为,在宏观上大量复合呈现出难以预料的规律。比如每只蚂蚁其行为其实是挺简单的,但是一群蚂蚁在一起,就可以表现出复杂的规律。又如每个神经元的行为都很简单,但是这么多神经元聚集在一起,就形成了聪明的人类大脑,这也算是一种涌现。
涌现最直观的例子可能就是康威的生命游戏(Conwey’s Life Game)了,这个游戏是在一个网格平面(类似围棋棋盘)上发生的,每个个里要么有一个存活的细胞,(用黑色格表示),要么就是一个死亡的细胞(用白色格表示),其规则也很简单,只有以下四条:
-
当前细胞存活时,当周围存活细胞<2时,该细胞死亡(模拟生命数量稀少)
-
当前细胞存活时,当周围有2个或3个存活细胞时,该细胞保持存活
-
当前细胞存活时,当周围存活细胞>3时,该细胞死亡(模拟生命数量拥挤)
-
当前细胞死亡时,当周围存活细胞=3时,该细胞复活(模拟繁殖)
那么图5里的四个样式就表示绝对静止的细胞群体。
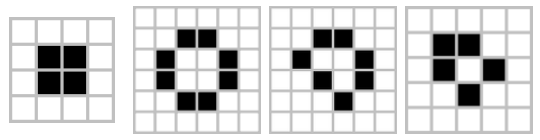
图5 康威生命游戏中绝对静止的细胞群体
对每个样式进行分析很快就会知道为什么它们会绝对静止。以第二个样式为例,其每个存活细胞周围都刚好有两个存活细胞,按照规则2,它们都应该保持存活。而任何一个死亡细胞周围都没有四个存活细胞,因此此样式将永远不变。
图6给出了震荡循环的细胞群体。
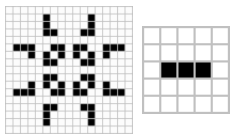
图6 康威生命游戏中震荡循环的细胞群体
按照康威生命游戏的规则,可以发现图6中的两个样式会演变几步之后又变成当前的样式。以第二个样式为例,其一共有左中右三个存活细胞。左侧与右侧的存活细胞附近只有一个存活细胞,因此按照规则1,会在下一轮死亡。中间的存活细胞附近有两个存活细胞,因此按照规则2,保持存活。同时又可以发现,中间的存活细胞上侧和下侧的死亡细胞由于其附近有三个存活细胞,因此根据规则4,在下一轮它们将复活。以此类推,样式会由横三转为纵三,又转回横三,永远震荡循环。
康威生命游戏有着远超过上述样式的复杂度,在宏观上甚至可以看到游走、巡回、扩张、凋零等多种细胞社群的样式,因此四条简单的微观规则就衍生出了让人事先难以预料的宏观样式上的复杂度,是涌现的一个生动形象的例子。
以ChatGPT与GPT-4为代表的大模型由于其使用了自然语言对话而引发了轰动,让普通人都能直观感受到大模型的魅力,但同时它作为一个基础设施,也提出了一个难题,就是它的编程接口是基于自然语言的,所以需要做所谓的提示工程(prompt engineering)。所谓提示工程,指的就是想让大模型好好干活,那就需要自己好好琢磨怎么和大模型好好说话。俗话说见人下菜,或者说见人说人话,见鬼说鬼话,那见了ChatGPT,当然就得说ChatGPT话了,不然它就没法理解问题,自然也没法给出好的回答了。Linux圈子里有Linus大佬的一句名言:“talk is cheap, show me your code”,中文翻译也很传神:“废话少说,放码过来”,俗一点的话那就是“少哔哔,秀代码”,但是自打GPT横空出世,以后可能就是“code is cheap, show me your talk”了,毕竟,给GPT一个提示,它可以还你百行代码。
不过神经网络毕竟是一种信息压缩,或说是一种函数拟合,因此中间肯定会有信息损失,或说是自己瞎想的填补空白,那就避免不了GPT一本正经的胡说八道,也就是所谓的幻觉(hallucination)了。幻觉是当前大模型应用的主要障碍之一,一般认为,大模型近期的发展将沿着消减幻觉、工具集成(即能使用外部工具)、多模态(即除了文本以外,也能理解和生成图形、语音、视频等内容)、垂直领域、类脑智能、具身(embodied)智能等方向发展。