『论文精读』FastViT(ICCV 2023,Apple开源)论文解读
『论文精读』FastViT(ICCV 2023,Apple开源)论文解读
文章目录
一. FastViT简介 二. 模型架构 2.1. Stage 的内部架构 2.2. Stem 的结构 2.3. Patch Embedding 的架构 2.4. 位置编码 三. 参考文献
论文下载链接:https://arxiv.org/pdf/2303.14189.pdf 论文代码链接:https://github.com/apple/ml-fastvit 关于VIT论文的解读可以关注我之前的文章:『论文精读』Vision Transformer(VIT)论文解读 关于Deit论文的解读可以关注我之前的文章:『论文精读』Data-efficient image Transformers(DeiT)论文解读
最近transformer和卷积设计的融合导致了模型的准确性和效率的稳步提高。本文提出FastViT,一种混合视觉transformer架构,可获得最先进的延迟-精度权衡 所提出模型比最近最先进的混合transformer架构CMT快3.5x,比EfficientNet快4.9×,比ConvNeXt在移动设备上快1.9× ,以获得在ImageNer数据集上的相同精度。在相似的延迟下,该模型在ImageNet上的Top-1准确率比MobileOne高出4.2%。所提出模型在图像分类、检测、分割和3D网格回归等任务中始终优于竞争架构,在移动设备和桌面GPU上的延迟都有显著改善。此外,该模型对分布外样本和损坏具有高度的鲁棒性,优于竞争的鲁棒模型。
本文提出基于三个关键设计原则的FastViT :①使用RepMixer块来删除跳跃连接(skip-connections);②使用线性训练时间过参数化来提高精度;③在早期阶段使用大型卷积核来替代自注意力层。
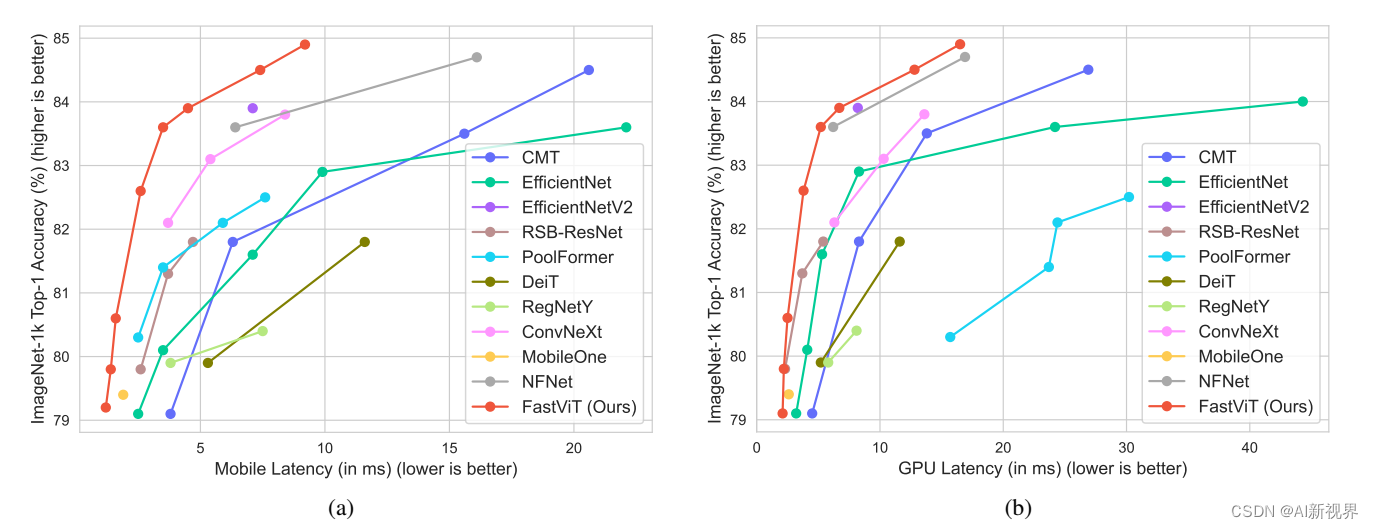
FastViT 性能对比: iPhone 12 Pro 设备和 NVIDIA RTX-2080Ti desktop GPU
最近最先进的移动架构和 FastViT 变体的准确性与移动延迟缩放曲线。 这些模型使用表 16 中描述的适当图像尺寸在 iPhone 12 Pro 上进行基准测试。
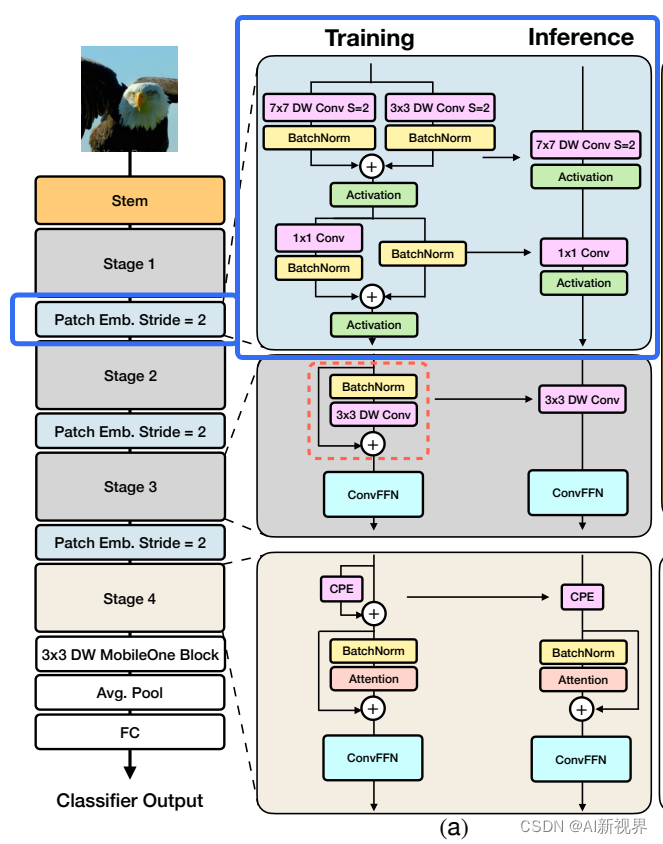
FastViT 整体框架图2:
FastViT 采用了4个 stage 的架构,每个 stage 相对于前一个的分辨率减半,通道数加倍。前3个 stage 的内部架构是一样的,都是训练的时候采用下式:
Y
=
DWConv(BN
(
X
)
)
+
X
(1)
\bf Y=\text{DWConv(BN}(X))+X \tag{1}
Y = DWConv(BN ( X )) + X ( 1 ) 推理的时候采用结构重参数化得到下式:
Y
=
DWConv
(
X
)
(2)
\bf Y=\text{DWConv}(X) \tag{2}
Y = DWConv ( X ) ( 2 )
RepMixer 卷积混合首先在ConvMixer中引入。 对于输入张量
X
\bf X
X
Y
=
BN
(
σ
(DWConv
(
X
)
)
+
X
(3)
\bf Y=\text{BN}\left(\sigma\text{(DWConv}\left(\bf X\right)\right)+\bf X \tag{3}
Y = BN ( σ (DWConv ( X ) ) + X ( 3 ) 其中
σ
\sigma
σ 但在RepMixer中,我们只是重新安排操作并删除非线性激活函数,如下所示:
Y
=
DWConv(BN
(
X
)
)
+
X
(4)
\bf Y=\text{DWConv(BN}(X))+X \tag{4}
Y = DWConv(BN ( X )) + X ( 4 ) 我们设计的主要好处是,它可以在推理时重新参数化到单个深度卷积层,如下所示,如图2d所示。
Y
=
DWConv
(
X
)
(5)
\bf Y=\text{DWConv}(X) \tag{5}
Y = DWConv ( X ) ( 5 )
第4个 stage 的内部架构如图2 (a) 所示,采用 Attention 来作为 token mixer,可能是为了性能考虑,宁愿不采用结构重参数化,牺牲延时成本,以换取更好的性能。 值得注意的是,每个 Stage 中的 FFN 使用的并不是传统的 FFN 架构,而是如图2(c)所示的,带有大核 7×7 卷积的 ConvFFN 架构。
Stem 是整个模型的起点,如图2 (b) 所示,FastViT 的 Stem 在推理时的结构是 3×3 卷积 + 3×3 Depth-wise 卷积 + 1×1 卷积 。在训练时分别加上 1×1 分支或者 Identity 分支 做结构重参数化。
Patch Embedding 是模型在 Stage 之间过渡的部分,FastViT 的 Patch Embedding 如图2 (a) 所示,在推理时的结构是 7×7 大 Kernel 的 Depth-wise 卷积 + 1×1 卷积。在训练时分别加上 3×3 分支做结构重参数化。
位置编码使用条件位置编码,它是动态生成的,并以输入 token 的局部邻域为条件。这些编码是由 depth-wise 运算符生成的,并添加到 Patch Embedding 中。
MobileOne 原班人马打造!FastViT:快速卷积 Transformer 的混合视觉架构 即插即用! | 苹果推出新型网络架构 FastViT: 又快又强又稳,端侧一键部署毫无压力!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/912769.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!