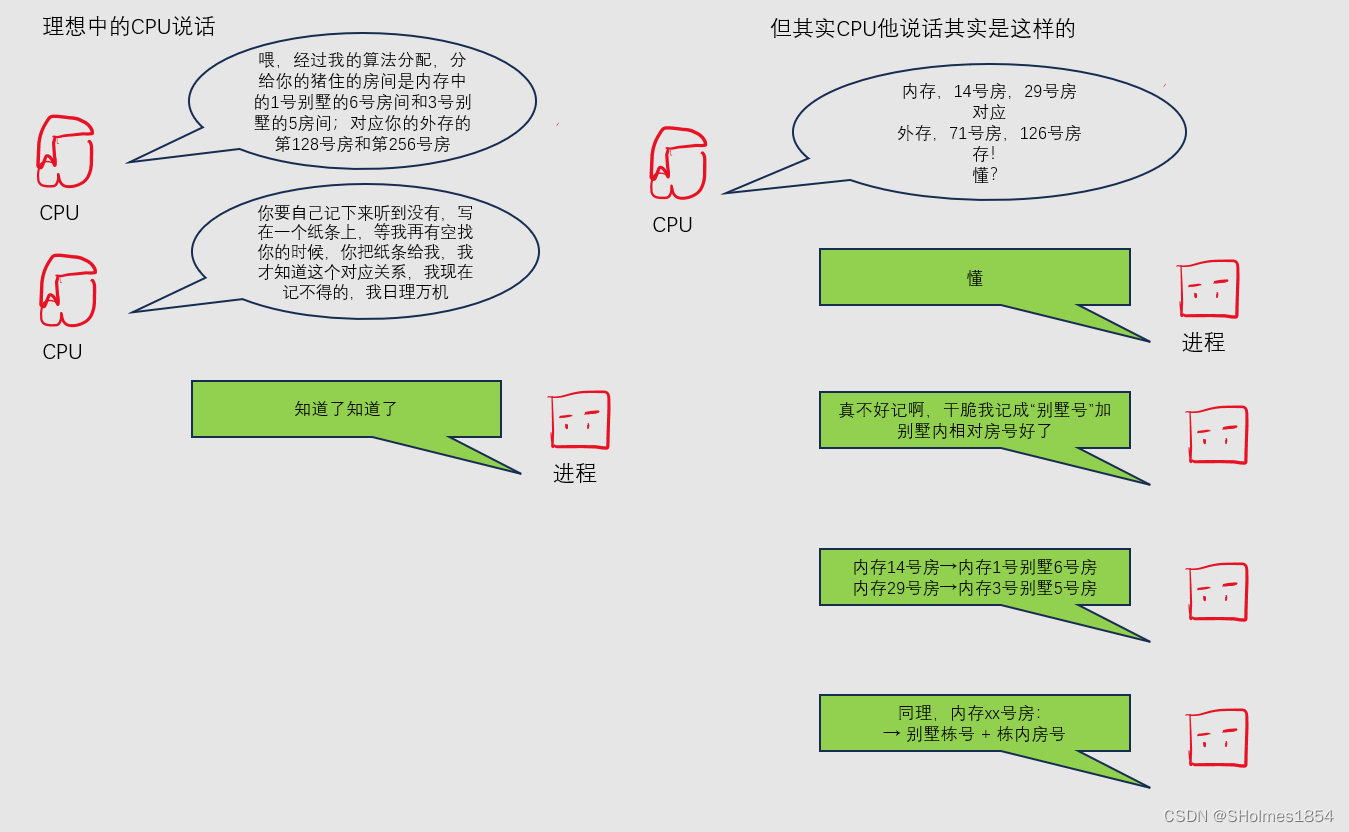
一、DDL
1、数据库操作
1)、创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];案例:
(1)创建一个数据库,不指定路径
hive (default)> create database db_hive1;
注:若不指定路径,其默认路径为${hive.metastore.warehouse.dir}/database_name.db
(2)创建一个数据库,指定路径
hive (default)> create database db_hive2 location '/db_hive2';
(3)创建一个数据库,带有dbproperties
hive (default)> create database db_hive3 with dbproperties('create_date'='2022-11-18');2)、查询数据库
语法:
SHOW DATABASES [LIKE 'identifier_with_wildcards'];案例:
hive> show databases like 'db_hive*';
OK
db_hive_1
db_hive_2查看数据库信息:
语法:
DESCRIBE DATABASE [EXTENDED] db_name;案例:
hive> desc database extended db_hive3;
OK
db_name comment location owner_name owner_type parameters
db_hive3 hdfs://hadoop102:8020/user/hive/warehouse/db_hive3.db atguigu USER {create_date=2022-11-18}3)、修改数据库
用户可以使用alter database命令修改数据库某些信息,其中能够修改的信息包括dbproperties、location、owner user。需要注意的是:修改数据库location,不会改变当前已有表的路径信息,而只是改变后续创建的新表的默认的父目录。
语法:
--修改dbproperties
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...);
--修改location
ALTER DATABASE database_name SET LOCATION hdfs_path;
--修改owner user
ALTER DATABASE database_name SET OWNER USER user_name;案例:
hive> ALTER DATABASE db_hive3 SET DBPROPERTIES ('create_date'='2022-11-20');4)、删除数据库
语法:
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];注:RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。
CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除。
案例:
(1)删除空数据库
hive> drop database db_hive2;
(2)删除非空数据库
hive> drop database db_hive3 cascade;5)、切换数据库
USE database_name;
二、表操作
1)、普通建表
完整语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]关键字说明:
(1)、TEMPORARY
临时表,该表只在当前会话可见,会话结束,表会被删除。
(2)、EXTERNAL(重点)
外部表,与之相对应的是内部表(管理表)。管理表意味着Hive会完全接管该表,包括元数据和HDFS中的数据。而外部表则意味着Hive只接管元数据,而不完全接管HDFS中的数据。
(3)、data_type(重点)
Hive中的字段类型可分为基本数据类型和复杂数据类型。
基本数据类型如下:
| Hive | 说明 | 定义 |
| tinyint | 1byte有符号整数 | |
| smallint | 2byte有符号整数 | |
| int | 4byte有符号整数 | |
| bigint | 8byte有符号整数 | |
| boolean | 布尔类型,true或者false | |
| float | 单精度浮点数 | |
| double | 双精度浮点数 | |
| decimal | 十进制精准数字类型 | decimal(16,2) |
| varchar | 字符序列,需指定最大长度,最大长度的范围是[1,65535] | varchar(32) |
| string | 字符串,无需指定最大长度 | |
| timestamp | 时间类型 | |
| binary | 二进制数据 |
复杂类型如下:
| 类型 | 说明 | 定义 | 取值 |
| array | 数组是一组相同类型的值的集合 | array<string> | arr[0] |
| map | map是一组相同类型的键-值对集合 | map<string, int> | map['key'] |
| struct | 结构体由多个属性组成,每个属性都有自己的属性名和数据类型 | struct<id:int, name:string> | struct.id |
注:类型转换
Hive的基本数据类型可以做类型转换,转换的方式包括隐式转换以及显示转换。
方式一:隐式转换
具体规则如下:
a. 任何整数类型都可以隐式地转换为一个范围更广的类型,如tinyint可以转换成int,int可以转换成bigint。
b. 所有整数类型、float和string类型都可以隐式地转换成double。
c. tinyint、smallint、int都可以转换为float。
d. boolean类型不可以转换为任何其它的类型。
详情可参考Hive官方说明:Allowed Implicit Conversions
方式二:显示转换
可以借助cast函数完成显示的类型转换
a.语法
cast(expr as <type>)
b.案例
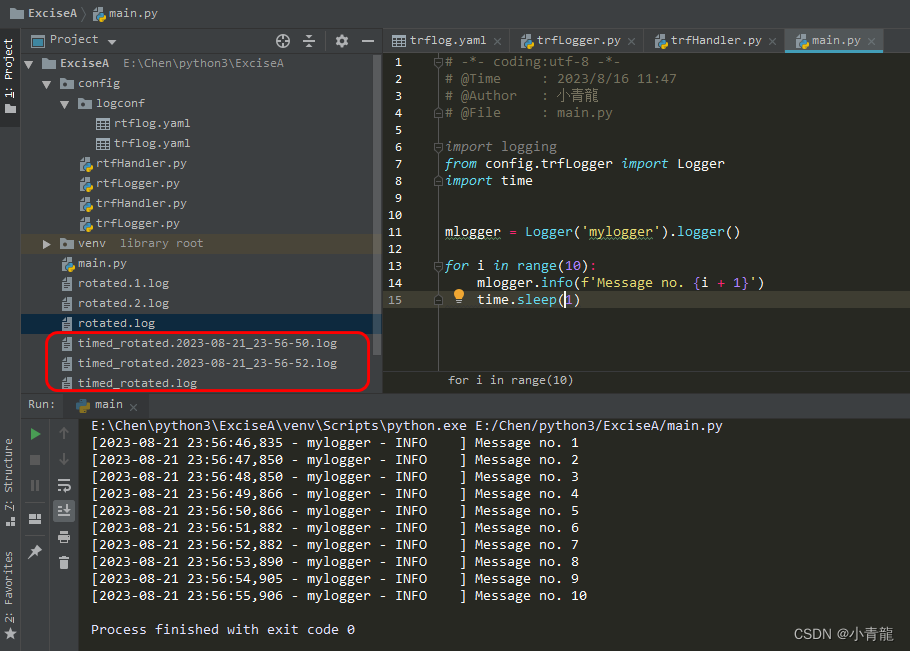
hive (default)> select '1' + 2, cast('1' as int) + 2;
_c0 _c1
3.0 3
(4)、PARTITIONED BY(重点)
创建分区表
(5)、CLUSTERED BY ... SORTED BY...INTO ... BUCKETS(重点)
创建分桶表
(6)、ROW FORMAT(重点)
指定SERDE,SERDE是Serializer and Deserializer的简写。Hive使用SERDE序列化和反序列化每行数据。详情可参考 Hive-Serde。语法说明如下:
语法一:DELIMITED关键字表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的SERDE对每行数据进行序列化和反序列化。
ROW FORAMT DELIMITED
[FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
注:
- fields terminated by :列分隔符
- collection items terminated by : map、struct和array中每个元素之间的分隔符
- map keys terminated by :map中的key与value的分隔符
- lines terminated by :行分隔符
语法二:SERDE关键字可用于指定其他内置的SERDE或者用户自定义的SERDE。例如JSON SERDE,可用于处理JSON字符串。
ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, ...)]
(7)、STORED AS(重点)
指定文件格式,常用的文件格式有,textfile(默认值),sequence file,orc file、parquet file等等。
(8)、LOCATION
指定表所对应的HDFS路径,若不指定路径,其默认值为
${hive.metastore.warehouse.dir}/db_name.db/table_name
(9)、TBLPROPERTIES
用于配置表的一些KV键值对参数
2)、Create Table As Select(CTAS)建表
该语法允许用户利用select查询语句返回的结果,直接建表,表的结构和查询语句的结构保持一致,且保证包含select查询语句放回的内容。
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]3)Create Table Like语法建表
该语法允许用户复刻一张已经存在的表结构,与上述的CTAS语法不同,该语法创建出来的表中不包含数据。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[LIKE exist_table_name]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]------内部表与外部表:
(1)内部表
Hive中默认创建的表都是的内部表,有时也被称为管理表。对于内部表,Hive会完全管理表的元数据和数据文件。
创建内部表如下:
create table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';(2)外部表
外部表通常可用于处理其他工具上传的数据文件,对于外部表,Hive只负责管理元数据,不负责管理HDFS中的数据文件。
创建外部表如下:
create external table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';--------SERDE和复杂数据类型案例:
本案例重点练习SERDE和复杂数据类型的使用。
若现有如下格式的JSON文件需要由Hive进行分析处理,请考虑如何设计表?
注:以下内容为格式化之后的结果,文件中每行数据为一个完整的JSON字符串。
{
"name": "dasongsong",
"friends": [
"bingbing",
"lili"
],
"students": {
"xiaohaihai": 18,
"xiaoyangyang": 16
},
"address": {
"street": "hui long guan",
"city": "beijing",
"postal_code": 10010
}
}我们可以考虑使用专门负责JSON文件的JSON Serde,设计表字段时,表的字段与JSON字符串中的一级字段保持一致,对于具有嵌套结构的JSON字符串,考虑使用合适复杂数据类型保存其内容。最终设计出的表结构如下:
hive>
create table teacher
(
name string,
friends array<string>,
students map<string,int>,
address struct<city:string,street:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/user/hive/warehouse/teacher';2)、查看表
语法:
SHOW TABLES [IN database_name] LIKE ['identifier_with_wildcards'];
注:like通配表达式说明:*表示任意个任意字符,|表示或的关系。案例:
hive> show tables like 'stu*';查看表信息:
语法:
DESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name
注:EXTENDED:展示详细信息
FORMATTED:对详细信息进行格式化的展示案例:
hive> desc formatted stu;3)、修改表
重命名表语法:
ALTER TABLE table_name RENAME TO new_table_name案例:
hive (default)> alter table stu rename to stu1;修改列信息:
(1)增加列
该语句允许用户增加新的列,新增列的位置位于末尾。
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)
(2)更新列
该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
(3)替换列
该语句允许用户用新的列集替换表中原有的全部列。
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
案例:
(1)查询表结构
hive (default)> desc stu;
(2)添加列
hive (default)> alter table stu add columns(age int);
(3)查询表结构
hive (default)> desc stu;
(4)更新列
hive (default)> alter table stu change column age ages double;
(6)替换列
hive (default)> alter table stu replace columns(id int, name string);4)、删除表(数据+结构都删除)
语法:
DROP TABLE [IF EXISTS] table_name;案例:
hive (default)> drop table stu;5)、清空表(只清理数据,不删除数据结构)
语法:
TRUNCATE [TABLE] table_name
注意:truncate只能清空管理表,不能删除外部表中数据。案例:
hive (default)> truncate table student;========================================================================
二、DML操作
一、load
Load语句可将文件导入到Hive表中。
1)语法
hive>
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)];
关键字说明:
(1)local:表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表。
(2)overwrite:表示覆盖表中已有数据,否则表示追加。
(3)partition:表示上传到指定分区,若目标是分区表,需指定分区。
案例:
(0)创建一张表
hive (default)>
create table student(
id int,
name string
)
row format delimited fields terminated by '\t';
(1)加载本地文件到hive
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table student;
(2)加载HDFS文件到hive中
①上传文件到HDFS
[atguigu@hadoop102 ~]$ hadoop fs -put /opt/module/datas/student.txt /user/atguigu
②加载HDFS上数据,导入完成后去HDFS上查看文件是否还存在
hive (default)>
load data inpath '/user/atguigu/student.txt'
into table student;
(3)加载数据覆盖表中已有的数据
①上传文件到HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu;
②加载数据覆盖表中已有的数据
hive (default)>
load data inpath '/user/atguigu/student.txt'
overwrite into table student;二、Insert
1、将查询结果插入表中
)语法
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement;
关键字说明:
(1)INTO:将结果追加到目标表
(2)OVERWRITE:用结果覆盖原有数据
案例:
(1)新建一张表
hive (default)>
create table student1(
id int,
name string
)
row format delimited fields terminated by '\t';
(2)根据查询结果插入数据
hive (default)> insert overwrite table student3
select
id,
name
from student;2、将给定Values插入表中
1)语法
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
2)案例
hive (default)> insert into table student1 values(1,'wangwu'),(2,'zhaoliu');
3、将查询结果写入目标路径
1)语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory
[ROW FORMAT row_format] [STORED AS file_format] select_statement;
2)案例
insert overwrite local directory '/opt/module/datas/student' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
select id,name from student;三、Export&Import
Export导出语句可将表的数据和元数据信息一并到处的HDFS路径,Import可将Export导出的内容导入Hive,表的数据和元数据信息都会恢复。Export和Import可用于两个Hive实例之间的数据迁移。
1)语法
--导出
EXPORT TABLE tablename TO 'export_target_path'
--导入
IMPORT [EXTERNAL] TABLE new_or_original_tablename FROM 'source_path' [LOCATION 'import_target_path']
2)案例
--导出
hive>export table default.student to '/user/hive/warehouse/export/student';
--导入
hive>import table student2 from '/user/hive/warehouse/export/student';
四、基本查询
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行。
(3)关键字不能被缩写也不能分行。
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
基本查询语句和mysql差不多,这里只讲和mysql不太一样的查询语法
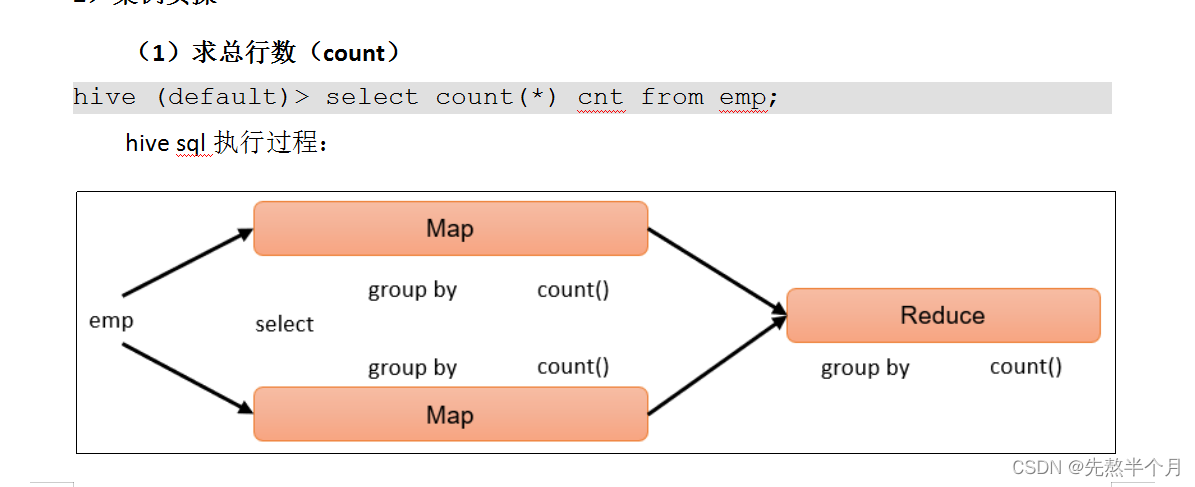
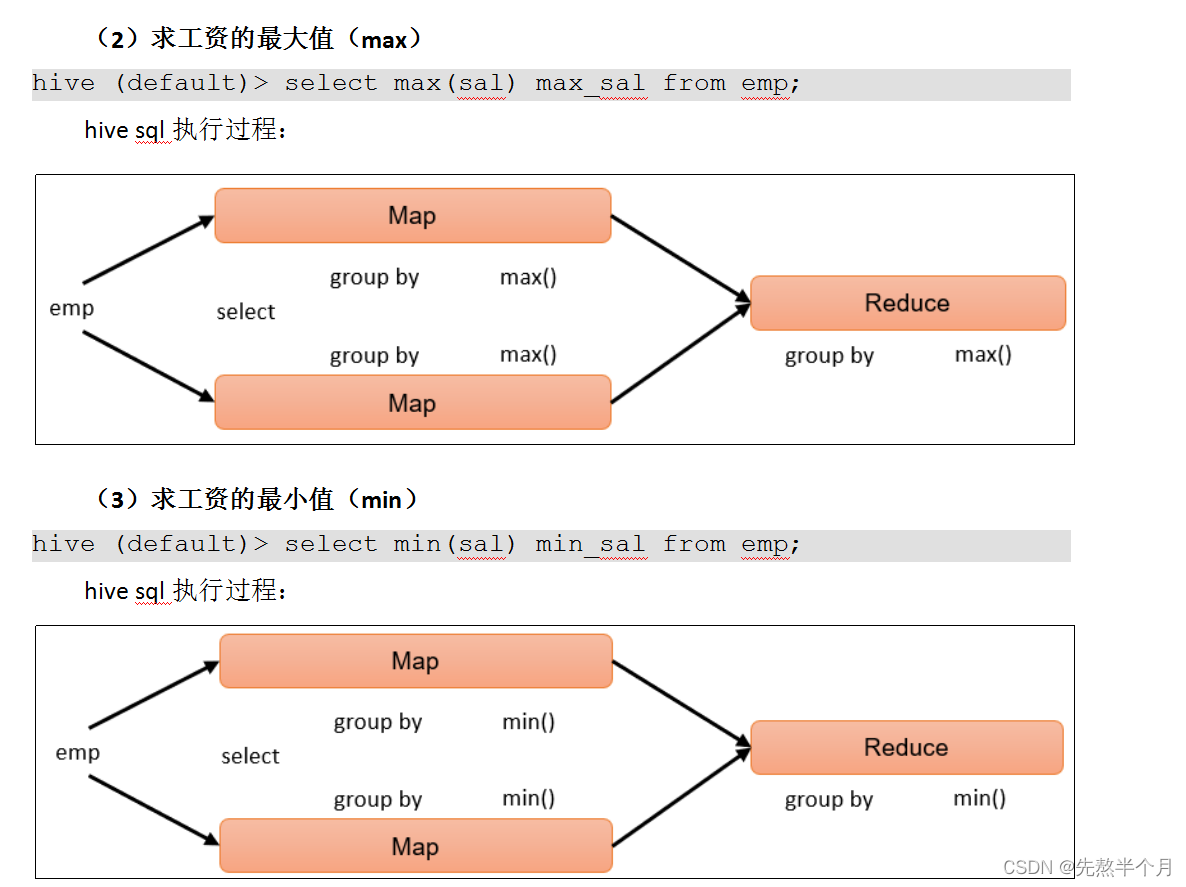
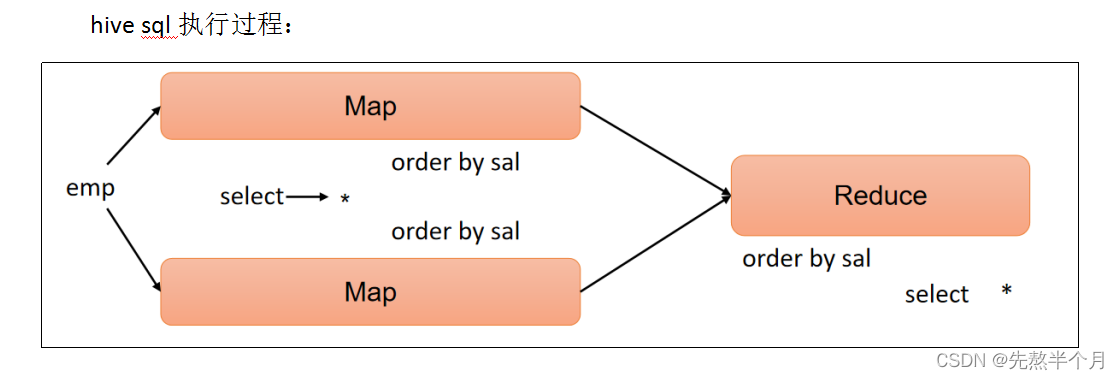
1、聚合函数时,hive执行sql的过程:
2、分组group by在hive中的执行

3、having
having与where不同点
(1)where后面不能写分组聚合函数,而having后面可以使用分组聚合函数。
(2)having只用于group by分组统计语句。
4、join
Hive支持通常的sql join语句,但是只支持等值连接,不支持非等值连接。
多表连接:
hive (default)>
select
e.ename,
d.dname,
l.loc_name
from emp e
join dept d
on d.deptno = e.deptno
join location l
on d.loc = l.loc;大多数情况下,Hive会对每对join连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l进行连接操作。
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
其他的连接写法基本和mysql的类似
5、联合(union & union all)
1)union&union all上下拼接
union和union all都是上下拼接sql的结果,这点是和join有区别的,join是左右关联,union和union all是上下拼接。union去重,union all不去重。
union和union all在上下拼接sql结果时有两个要求:
(1)两个sql的结果,列的个数必须相同
(2)两个sql的结果,上下所对应列的类型必须一致
案例:
将员工表30部门的员工信息和40部门的员工信息,利用union进行拼接显示。
hive (default)>
select
*
from emp
where deptno=30
union
select
*
from emp
where deptno=40;6、排序
1)、全局排序
Order By:全局排序,只有一个Reduce。
asc(ascend):升序(默认)
desc(descend):降序
2)、Sort By(每个Reduce内部排序)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用Sort by。Sort by为每个reduce产生一个排序文件。每个Reduce内部进行排序,对全局结果集来说不是排序(即对部分进行排序,不是全局进行排序)

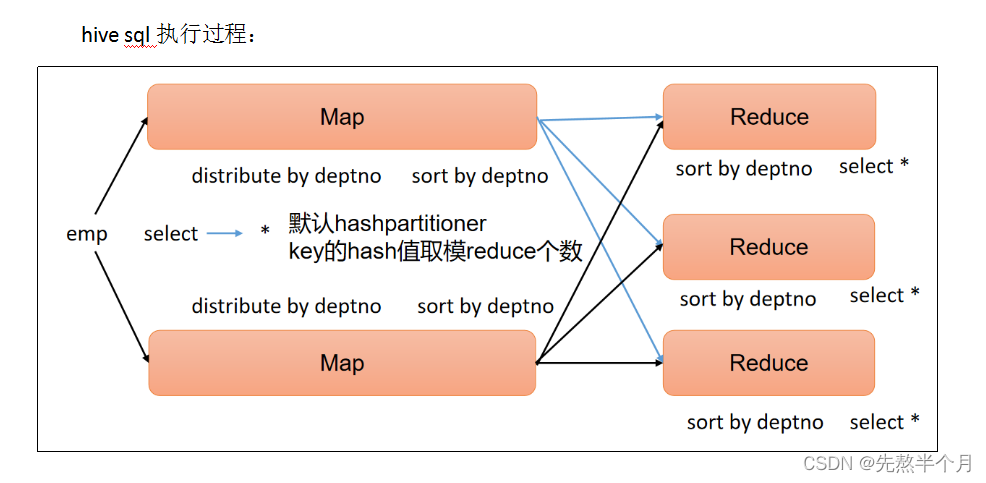
3)、分区(Distribute By)
Distribute By:在有些情况下,我们需要控制某个特定行应该到哪个Reducer,通常是为了进行后续的聚集操作。distribute by子句可以做这件事。distribute by类似MapReduce中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。

4)、分区排序(Cluster By)
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为asc或者desc。
(1)以下两种写法等价
hive (default)>
select
*
from emp
cluster by deptno;
hive (default)>
select
*
from emp
distribute by deptno
sort by deptno;注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
aa