前言
本文着重介绍Redis中的有序集合的底层实现中的跳表
有序集合 Sorted Set
Redis中的Sorted Set 是一个有序的无重复值的集合,他底层是使用压缩列表和跳表实现的,和Java中的HashMap底层数据结构(1.8)链表+红黑树异曲同工之妙
什么是跳表
跳跃表(Skip List)是一种有序的数据结构,它由多层有序链表组成。每一层链表中的节点是有序排列的,而每一层链表中的节点指针可以跨越若干个节点,这样就提高了查询效率。
跳跃表最底层的链表包含了所有的元素,而每一层链表都是下一层链表的子集。最顶层链表只有两个节点,即头节点和尾节点。每一层链表中的节点包含了一个成员(Member)和一个指向同样成员的下一层链表节点的指针。
通过使用跳跃表,可以在时间复杂度O(logN)的情况下执行插入、删除和查找操作。这相比于传统链表的时间复杂度O(N)来说更加高效。同时,跳跃表还相对于平衡二叉树来说更加简单,容易实现。
其实就是经典的空间换时间,利用“跳跃节点”在层级间跳跃,每层都保留数据,从下往上,数据越来越少,图示如下:
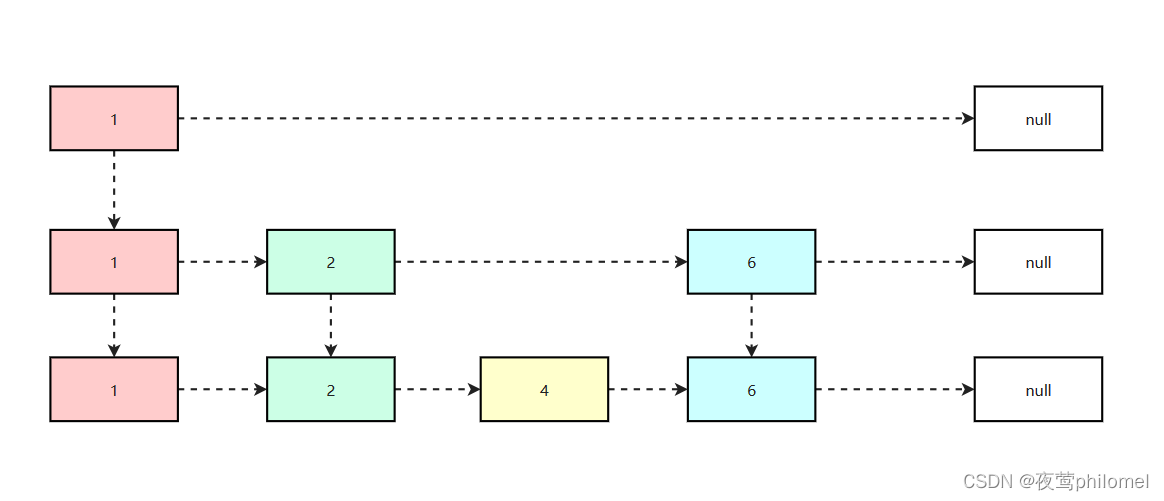
跳表的查询流程
跳表的查询流程其实很简单,举个例子假如我们要查找value == 6,正常链表需要遍历4次才能找到,而跳表3次就可以了。
其过程就是,1->1->2->6,1->1这个直接过去的,不需要额外判断,也就是1->2->6这个过程,图示如下:
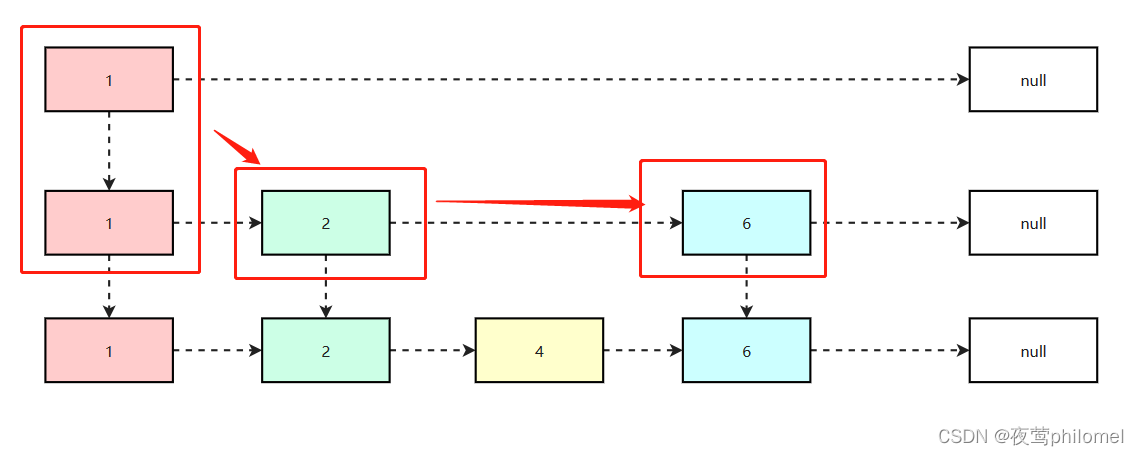
其原理就和二分查找一样,首先顶层的1节点判断小于就往下右走到第二层的2节点,然后往右走,就找到6了
同样的,如果查找4节点,1->1->2->2->4,在一层中如果下一个节点的值比目标值还大的值就直接往下走,因为下层的数据的范围一定在[Node.value,Node.next.value]之间,当前例子中就是4一定在下一层的[2,6]节点中。这样就可以做到快速访问了,在数据量大的情况下,他的时间复杂度就是O(logN)。
跳表的插入
在Redis中,跳表的每一层链表都有一个编号,从下往上是0~31,当我们要进行插入操作的时候,Redis 会生成一个随机数,这个随机数的范围是[1,32],这个随机数越大,生成的概率就越小,意思就是生成1的概率为50%,2的概率为25%,逐层减半。源码如下:
static unsigned int ziplistLength(unsigned char *zl) {
return ziplistLen((unsigned char*)zl);
}
// 生成一个介于1和2^32之间的随机数
static unsigned int zrandom(void) {
// 以秒为种子生成随机数
srand(time(0));
return rand();
}
typedef struct zskiplistNode {
// 成员对象
sds ele;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度(跨过的节点数量)
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 头节点和尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 层数
int level;
} zskiplist;
// 创建并返回一个新节点
static zskiplistNode *zslCreateNode(int level, double score, sds ele) {
// 分配节点空间
zskiplistNode *zn = zmalloc(sizeof(*zn) + level * sizeof(struct zskiplistLevel));
// 设置节点成员
zn->score = score;
zn->ele = ele;
return zn;
}
// 创建并返回一个新的跳跃表
zskiplist *zslCreate(void) {
int j;
// 分配空间
zskiplist *zsl = zmalloc(sizeof(*zsl));
// 初始化头节点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL, 0, NULL);
// 设置尾节点
zsl->tail = NULL;
// 初始化长度和层数
zsl->length = 0;
zsl->level = 1;
// 初始化头节点的 forward 和 span
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
// 初始化尾节点
zsl->header->backward = NULL;
return zsl;
}
// 随机生成节点层数
int zslRandomLevel(void) {
int level = 1;
// 每隔2个节点,层数+1(以1/4的概率)
while ((zrandom() & 0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) {
level += 1;
}
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
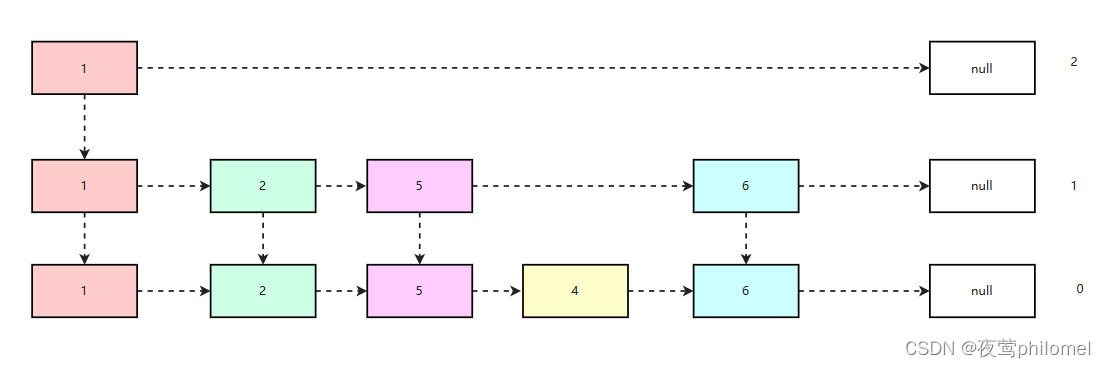
这个随机数的意义就是数据在插多少层,举个例子,假如我随机到5,那么就意味着我的数据要从的0~4层进插入,这样才能保证我新来的数据不会影响到我跳表下层兼容上层的特性,也能保证数据访问的快速性(因为不一定要到底层查数据有可能我上一层就查到了),图示如下(random== 2,value== 5):
压缩列表升级为跳表
在Java的HashMap中,是要到table.length >= 64 && list.length >= 8 时才会出现一个从链表升级到红黑树的过程,在我们的Redis中也是如此,只要不满足其中一个,就会升级 (||运算)
1. 有序集合中的元素个数小于128个
2. 有序集合保存的元素成员长度都必须小于64字节
当以上任意一个不满足时,就会从压缩列表升级为跳表