[oneAPI] 基于BERT预训练模型的命名体识别任务
- Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
- 基于BERT预训练模型的命名体识别任务
- 语料介绍
- 数据集构建
- 使用示例
- 命名体识别模型
- 前向传播
- 模型训练
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
在本次实验中,我们在Intel® DevCloud for oneAPI上搭建实验,借助完全虚拟化的环境,专注于模型开发与优化,无需关心底层配置。使用Intel® Optimization for PyTorch,对PyTorch模型进行高效优化。
我们充分发挥了PyTorch和Intel® Optimization for PyTorch的强大功能,经过仔细的优化和拓展。这些优化措施极大地提升了PyTorch在各种任务中的性能,尤其是在英特尔硬件上的表现更为卓越。通过这些优化方法,我们的模型在训练和推断过程中变得更加敏捷高效,大幅缩短了计算时间,从而提升了整体效率。借助深度融合硬件与软件的巧妙设计,我们成功地释放了硬件潜力,使模型的训练和应用变得更加迅速高效。这些优化举措为人工智能应用开辟了崭新的前景,带来了全新的可能性。
基于BERT预训练模型的命名体识别任务
基于BERT预训练模型的第五个下游任务场景,即如何完成命名体识别(Named Entity Recognition, NER)任务。所谓命名体指的是给模型输入一句文本,最后需要模型将其中的实体(例如人名、地名、组织等等)标记出来。
1 句子:涂伊说,如果有机会他想去黄州赤壁看一看!
2 标签:['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O']
3 实体:涂伊(人名)、黄州(地名)、赤壁(地名)
通常来讲,对于任意一个NLP任务来说模型最后所要完成的基本上都是一个分类任务,尽管表面上看起来可能不太像。根据给出的标签来看,对于原始句子中的每个字符来说其都有一个对应的类别标签,因此对于NER任务来说只需要对原始句子里的每个字符进行分类即可,然后再将预测后的结果进行后处理便能够得到句子从存在的相应实体。
原始数据输入为一个句子,我们只需要在句子的首尾分别加上[CLS]和[SEP],然后输入到模型当中进行特征提取并最终通过一个分类层对输出的每个Token进行分类即可,最后只需要对各个Token的预测结果进行后处理便能够实现整个NER任务。
语料介绍
一个中文命名体识别数据集https://github.com/zjy-ucas/ChineseNER,如下所示便是原始数据的存储形式:
1 涂 B-PER
2 伊 I-PER
3 说 O
4 , O
5 如 O
6 果 O
7 有 O
8 机 O
9 会 O
10 他 O
11 想 O
12 去 O
13 黄 B-LOC
14 州 I-LOC
15 赤 B-LOC
16 壁 I-LOC
17 看 O
18 一 O
19 看 O
20 !O
其中每一行包含一个字符和其对应的所属类别,B-表示该类实体的开始标志,I-表示该类实体的延续标志。例如对于13-16行来说其对应了“黄州”和“赤壁”这两个实体。同时,对于这个数据集来说,其一共包含有3类实体(人名、地名和组织),因此其对应的分类总数便为7,如下所示:
1 {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
对于数据预处理部分我们可以继续继承之前文本分类处理中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法即可。
数据集构建
在说完数据集构造的整理思路后,下面我们就来正式编码实现整个数据集的构造过程。同样,对于数据预处理部分我们可以继续继承之前文本分类处理中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法即可。
class LoadChineseNERDataset(LoadSingleSentenceClassificationDataset):
def __init__(self, entities=None, num_labels=None, ignore_idx=-100, **kwargs):
super(LoadChineseNERDataset, self).__init__(**kwargs)
self.entities = entities
self.num_labels = num_labels
self.IGNORE_IDX = ignore_idx
if self.entities is None or self.num_labels is None:
raise ValueError(f"类 {self.__class__.__name__} 中参数 entities 或 num_labels 不能为空!")
@cache
def data_process(self, filepath, postfix='cache'):
raw_iter = open(filepath, encoding="utf8").readlines()
data = []
max_len = 0
tmp_token_ids = []
tmp_sentence = ""
tmp_label = []
tmp_entity = []
for raw in tqdm(raw_iter, ncols=80):
line = raw.rstrip("\n").split(self.split_sep)
if len(line) != 1 and len(line) != 2:
raise ValueError(f"数据标注有误{line}")
if len(line) == 1: # 表示得到一个完整的token id样本
if len(tmp_token_ids) > self.max_position_embeddings - 2:
tmp_token_ids = tmp_token_ids[:self.max_position_embeddings - 2]
tmp_label = tmp_label[:self.max_position_embeddings - 2]
max_len = max(max_len, len(tmp_label) + 2)
token_ids = torch.tensor([self.CLS_IDX] + tmp_token_ids +
[self.SEP_IDX], dtype=torch.long)
labels = torch.tensor([self.IGNORE_IDX] + tmp_label +
[self.IGNORE_IDX], dtype=torch.long)
data.append([tmp_sentence, token_ids, labels])
logging.debug(" ### 样本构造结果为:")
logging.debug(f" ## 句子: {tmp_sentence}")
logging.debug(f" ## 实体: {tmp_entity}")
logging.debug(f" ## input_ids: {token_ids.tolist()}")
logging.debug(f" ## label: {labels.tolist()}")
logging.debug(f" ================================\n")
assert len(tmp_token_ids) == len(tmp_label)
tmp_token_ids = []
tmp_sentence = ""
tmp_label = []
tmp_entity = []
continue
tmp_sentence += line[0]
tmp_token_ids.append(self.vocab[line[0]])
tmp_label.append(self.entities[line[-1]])
tmp_entity.append(line[-1])
return data, max_len
def generate_batch(self, data_batch):
batch_sentence, batch_token_ids, batch_label = [], [], []
for (sen, token_ids, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。
batch_sentence.append(sen)
batch_token_ids.append(token_ids)
batch_label.append(label)
batch_token_ids = pad_sequence(batch_token_ids, # [batch_size,max_len]
padding_value=self.PAD_IDX,
batch_first=False,
max_len=self.max_sen_len)
batch_label = pad_sequence(batch_label, # [batch_size,max_len]
padding_value=self.IGNORE_IDX,
batch_first=False,
max_len=self.max_sen_len)
# ① 因为label的长度各不相同,所以同一个batch中的label需要padding到相同的长度;
# ② 因为进行了padding操作,所以在计算损失的时候需要把padding部分的损失忽略掉;
# ③ 又因为label中有0这个类别的存在,所以不能用词表中的PAD_IDX进行padding(PAD_IDX为0),所以要另外取一个IGNORE_IDX
return batch_sentence, batch_token_ids, batch_label
def make_inference_samples(self, sentences):
if not isinstance(sentences, list):
sentences = [sentences]
data = []
for sen in sentences:
tokens = [self.vocab[word] for word in sen]
label = [-1] * len(tokens)
token_ids = torch.tensor([self.CLS_IDX] + tokens + [self.SEP_IDX], dtype=torch.long)
labels = torch.tensor([self.IGNORE_IDX] + label + [self.IGNORE_IDX], dtype=torch.long)
data.append([sen, token_ids, labels])
return self.generate_batch(data)
使用示例
在完成数据集构造部分的相关代码实现之后,便可以通过如下所示的方式进行使用,代码如下:
class ModelConfig:
def __init__(self):
self.project_dir = os.path.dirname(os.path.abspath(__file__))
self.dataset_dir = os.path.join(self.project_dir, 'ChineseNERdata')
self.pretrained_model_dir = os.path.join(self.project_dir, "pretraining")
self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')
self.device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
self.train_file_path = os.path.join(self.dataset_dir, 'example_train.txt')
self.val_file_path = os.path.join(self.dataset_dir, 'example_dev.txt')
self.test_file_path = os.path.join(self.dataset_dir, 'example_test.txt')
self.model_save_dir = os.path.join(self.project_dir, 'cache')
self.model_save_name = "ner_model.pt"
self.logs_save_dir = os.path.join(self.project_dir, 'logs')
self.split_sep = ' '
self.is_sample_shuffle = True
self.batch_size = 6
self.max_sen_len = None
self.epochs = 10
self.learning_rate = 1e-5
self.model_val_per_epoch = 2
self.entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
self.num_labels = len(self.entities)
self.ignore_idx = -100
logger_init(log_file_name='ner', log_level=logging.DEBUG,
log_dir=self.logs_save_dir)
if not os.path.exists(self.model_save_dir):
os.makedirs(self.model_save_dir)
# 把原始bert中的配置参数也导入进来
bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")
bert_config = BertConfig.from_json_file(bert_config_path)
for key, value in bert_config.__dict__.items():
self.__dict__[key] = value
# 将当前配置打印到日志文件中
logging.info(" ### 将当前配置打印到日志文件中 ")
for key, value in self.__dict__.items():
logging.info(f"### {key} = {value}")
命名体识别模型
前向传播
我们只需要在原始BERT模型的基础上再加一个对所有Token进行分类的分类层即可,因此这部分代码相对来说也比较容易理解。首先需要在DownstreamTasks目录下新建一个BertForTokenClassification模块,并完成整个模型的初始化和前向传播过程,代码如下:
from ..BasicBert.Bert import BertModel
import torch.nn as nn
class BertForTokenClassification(nn.Module):
def __init__(self, config, bert_pretrained_model_dir=None):
super(BertForTokenClassification, self).__init__()
self.num_labels = config.num_labels
if bert_pretrained_model_dir is not None:
self.bert = BertModel.from_pretrained(config, bert_pretrained_model_dir)
else:
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.num_labels)
self.config = config
def forward(self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
labels=None):
"""
:param input_ids: [src_len,batch_size]
:param attention_mask: [batch_size, src_len]
:param token_type_ids:
:param position_ids:
:param labels: [src_len,batch_size]
:return:
"""
_, all_encoder_outputs = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids) # [batch_size,hidden_size]
sequence_output = all_encoder_outputs[-1] # 取最后一层
# sequence_output: [src_len, batch_size, hidden_size]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
# logit: [src_len, batch_size, num_labels]
if labels is not None: # [src_len,batch_size]
loss_fct = nn.CrossEntropyLoss(ignore_index=self.config.ignore_idx)
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return loss, logits
else:
return logits
模型训练
对于模型训练这部分内容来说,首先我们需要在Tasks目录下新建一个TaskForChineseNER.py模块,并新建一个配置类ModelConfig来管理整个模型需要用到的参数,代码实现如下:
class ModelConfig:
def __init__(self):
self.project_dir = os.path.dirname(os.path.abspath(__file__))
self.dataset_dir = os.path.join(self.project_dir, 'ChineseNERdata')
self.pretrained_model_dir = os.path.join(self.project_dir, "pretraining")
self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')
self.device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
self.train_file_path = os.path.join(self.dataset_dir, 'example_train.txt')
self.val_file_path = os.path.join(self.dataset_dir, 'example_dev.txt')
self.test_file_path = os.path.join(self.dataset_dir, 'example_test.txt')
self.model_save_dir = os.path.join(self.project_dir, 'cache')
self.model_save_name = "ner_model.pt"
self.logs_save_dir = os.path.join(self.project_dir, 'logs')
self.split_sep = ' '
self.is_sample_shuffle = True
self.batch_size = 6
self.max_sen_len = None
self.epochs = 10
self.learning_rate = 1e-5
self.model_val_per_epoch = 2
self.entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
self.num_labels = len(self.entities)
self.ignore_idx = -100
logger_init(log_file_name='ner', log_level=logging.DEBUG,
log_dir=self.logs_save_dir)
if not os.path.exists(self.model_save_dir):
os.makedirs(self.model_save_dir)
# 把原始bert中的配置参数也导入进来
bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")
bert_config = BertConfig.from_json_file(bert_config_path)
for key, value in bert_config.__dict__.items():
self.__dict__[key] = value
# 将当前配置打印到日志文件中
logging.info(" ### 将当前配置打印到日志文件中 ")
for key, value in self.__dict__.items():
logging.info(f"### {key} = {value}")
因为在模型训练过程中需要计算相关的评价指标,如准确率、精确率和召回率等,因此需要对这部分进行实现,代码如下
def accuracy(logits, y_true, ignore_idx=-100):
"""
:param logits: [src_len,batch_size,num_labels]
:param y_true: [src_len,batch_size]
:param ignore_idx: 默认情况为-100
:return:
e.g.
y_true = torch.tensor([[-100, 0, 0, 1, -100],
[-100, 2, 0, -100, -100]]).transpose(0, 1)
logits = torch.tensor([[[0.5, 0.1, 0.2], [0.5, 0.4, 0.1], [0.7, 0.2, 0.3], [0.5, 0.7, 0.2], [0.1, 0.2, 0.5]],
[[0.3, 0.2, 0.5], [0.7, 0.2, 0.4], [0.8, 0.1, 0.3], [0.9, 0.2, 0.1], [0.1, 0.5, 0.2]]])
logits = logits.transpose(0, 1)
print(accuracy(logits, y_true, -100)) # (0.8, 4, 5)
"""
y_pred = logits.transpose(0, 1).argmax(axis=2).reshape(-1).tolist()
# 将 [src_len,batch_size,num_labels] 转成 [batch_size, src_len,num_labels]
y_true = y_true.transpose(0, 1).reshape(-1).tolist()
real_pred, real_true = [], []
for item in zip(y_pred, y_true):
if item[1] != ignore_idx:
real_pred.append(item[0])
real_true.append(item[1])
return accuracy_score(real_true, real_pred), real_true, real_pred
为了能够在模型训练或推理过程中输入模型的预测结果,因此我们需要实现3个辅助函数来完成。首先需要实现根据logits和input_token_ids来得到每个预测值对应的实体标签,代码如下:
def get_ner_tags(logits, token_ids, entities, SEP_IDX=102):
"""
:param logits: [src_len,batch_size,num_samples]
:param token_ids: # [src_len,batch_size]
:return:
e.g.
logits = torch.tensor([[[0.4, 0.7, 0.2],[0.5, 0.4, 0.1],[0.1, 0.2, 0.3],[0.5, 0.7, 0.2],[0.1, 0.2, 0.5]],
[[0.3, 0.2, 0.5],[0.7, 0.8, 0.4],[0.1, 0.1, 0.3],[0.9, 0.2, 0.1],[0.1, 0.5,0.2]]])
logits = logits.transpose(0, 1) # [src_len,batch_size,num_samples]
token_ids = torch.tensor([[101, 2769, 511, 102, 0],
[101, 56, 33, 22, 102]]).transpose(0, 1) # [src_len,batch_size]
labels, probs = get_ner_tags(logits, token_ids, entities)
[['O', 'B-LOC'], ['B-ORG', 'B-LOC', 'O']]
[[0.5, 0.30000001192092896], [0.800000011920929, 0.30000001192092896, 0.8999999761581421]]
"""
# entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
label_list = list(entities.keys())
logits = logits[1:].transpose(0, 1) # [batch_size,src_len-1,num_samples]
prob, y_pred = torch.max(logits, dim=-1) # prob, y_pred: [batch_size,src_len-1]
token_ids = token_ids[1:].transpose(0, 1) # [ batch_size,src_len-1], 去掉[cls]
assert y_pred.shape == token_ids.shape
labels = []
probs = []
for sample in zip(y_pred, token_ids, prob):
tmp_label, tmp_prob = [], []
for item in zip(*sample):
if item[1] == SEP_IDX: # 忽略最后一个[SEP]字符
break
tmp_label.append(label_list[item[0]])
tmp_prob.append(item[2].item())
labels.append(tmp_label)
probs.append(tmp_prob)
return labels, probs
进一步,在得到每个输入句子的预测结果后,还需要将其进行格式化处理得到最终的预测结果,实现代码如下:
def pretty_print(sentences, labels, entities):
"""
:param sentences:
:param labels:
:param entities:
:return:
e.g.
labels = [['B-PER','I-PER', 'O','O','O','O','O','O','O','O','O','O','B-LOC','I-LOC','B-LOC','I-LOC','O','O','O','O'],
['B-LOC','I-LOC','O','B-LOC','I-LOC','O','B-LOC','I-LOC','I-LOC','O','B-LOC','I-LOC','O','O','O','B-PER','I-PER','O','O','O','O','O','O']]
sentences=["涂伊说,如果有机会他想去赤壁看一看!",
"丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!"]
entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
句子:涂伊说,如果有机会他想去黄州赤壁看一看!
涂伊: PER
黄州: LOC
赤壁: LOC
句子:丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!
丽江: LOC
大理: LOC
九寨沟: LOC
黄龙: LOC
涂伊: PER
"""
sep_tag = [tag for tag in list(entities.keys()) if 'I' not in tag]
result = []
for sen, label in zip(sentences, labels):
logging.info(f"句子:{sen}")
last_tag = None
for item in zip(sen + "O", label + ['O']):
if item[1] in sep_tag: #
if len(result) > 0:
entity = "".join(result)
logging.info(f"\t{entity}: {last_tag.split('-')[-1]}")
result = []
if item[1] != 'O':
result.append(item[0])
last_tag = item[1]
else:
result.append(item[0])
last_tag = item[1]
输出结果如下:
1 句子:涂伊说,如果有机会他想去黄州赤壁看一看!
2 涂伊: PER
3 黄州: LOC
4 赤壁: LOC
5 句子:丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!
6 丽江: LOC
7 大理: LOC
8 九寨沟: LOC
9 黄龙: LOC
10 涂伊: PER
在完成上述所有铺垫之后,便可以来实现模型的训练部分,代码如下(下面只摘录核心部分进行介绍):
def train(config):
model = BertForTokenClassification(config,
config.pretrained_model_dir)
model_save_path = os.path.join(config.model_save_dir,
config.model_save_name)
global_steps = 0
if os.path.exists(model_save_path):
checkpoint = torch.load(model_save_path)
global_steps = checkpoint['last_epoch']
loaded_paras = checkpoint['model_state_dict']
model.load_state_dict(loaded_paras)
logging.info("## 成功载入已有模型,进行追加训练......")
model = model.to(config.device)
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)
model.train()
data_loader = LoadChineseNERDataset(
entities=config.entities,
num_labels=config.num_labels,
ignore_idx=config.ignore_idx,
vocab_path=config.vocab_path,
tokenizer=BertTokenizer.from_pretrained(
config.pretrained_model_dir).tokenize,
batch_size=config.batch_size,
max_sen_len=config.max_sen_len,
split_sep=config.split_sep,
max_position_embeddings=config.max_position_embeddings,
pad_index=config.pad_token_id,
is_sample_shuffle=config.is_sample_shuffle)
train_iter, test_iter, val_iter = \
data_loader.load_train_val_test_data(train_file_path=config.train_file_path,
val_file_path=config.val_file_path,
test_file_path=config.test_file_path,
only_test=False)
max_acc = 0
for epoch in range(config.epochs):
losses = 0
start_time = time.time()
for idx, (sen, token_ids, labels) in enumerate(train_iter):
token_ids = token_ids.to(config.device)
labels = labels.to(config.device)
padding_mask = (token_ids == data_loader.PAD_IDX).transpose(0, 1)
loss, logits = model(input_ids=token_ids, # [src_len, batch_size]
attention_mask=padding_mask, # [batch_size,src_len]
token_type_ids=None,
position_ids=None,
labels=labels) # [src_len, batch_size]
# logit: [src_len, batch_size, num_labels]
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses += loss.item()
global_steps += 1
acc, _, _ = accuracy(logits, labels, config.ignore_idx)
if idx % 20 == 0:
logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "
f"Train loss :{loss.item():.3f}, Train acc: {round(acc, 5)}")
if idx % 100 == 0:
show_result(sen[:10], logits[:, :10], token_ids[:, :10], config.entities)
end_time = time.time()
train_loss = losses / len(train_iter)
logging.info(f"Epoch: [{epoch + 1}/{config.epochs}],"
f" Train loss: {train_loss:.3f}, Epoch time = {(end_time - start_time):.3f}s")
if (epoch + 1) % config.model_val_per_epoch == 0:
acc = evaluate(config, val_iter, model, data_loader)
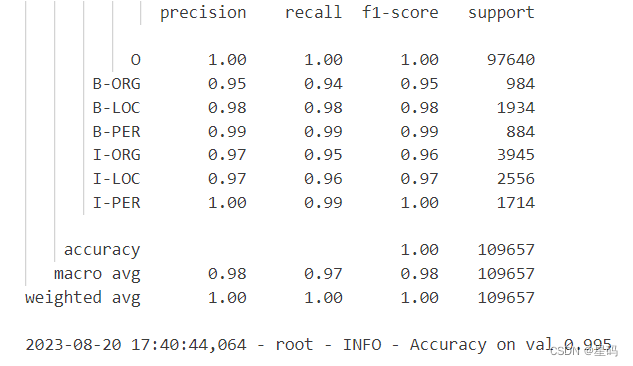
logging.info(f"Accuracy on val {acc:.3f}")
if acc > max_acc:
max_acc = acc
state_dict = deepcopy(model.state_dict())
torch.save({'last_epoch': global_steps,
'model_state_dict': state_dict},
model_save_path)
结果

参考资料
基于BERT预训练模型的中文文本分类任务: https://mp.weixin.qq.com/s/bbeN95mlLaE05dFndUAxgA