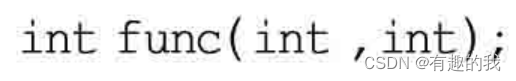目录
- 泛型
- 内置泛型的使用
- 切片泛型和泛型函数
- map泛型
- 泛型约束
- 泛型完整代码
- 接口
- 反射
- 协程
- 特点
- WaitGroup
- goroutine的调度模型:MPG模型
- channel
- 介绍
- 语法:
- 举例:
- channel遍历
- 基本使用
- 和协程一起使用
- 案例一
- 案例二
- select...case
- main.go 完整代码
- 文件
go往期文章笔记:
【Java转Go】快速上手学习笔记(一)之环境安装篇
【Java转Go】快速上手学习笔记(二)之基础篇一
【Java转Go】快速上手学习笔记(三)之基础篇二
这篇主要是泛型、接口、反射、协程、管道、文件操作的笔记,因为我的笔记都是按照视频说的来记的,可能大家光看的话会有些看不明白,所以建议大家可以把代码复制下来,配合里面的注释一起,自己去运行一遍,加深理解😘
泛型
定义泛型:func 函数名 [泛型参数类型] (函数参数) {}
内置泛型的使用
Go内置的两个泛型:any 和 comparable
- any:表示go里面所有的内置基本类型,等价于
interface{} - comparable:表示go里面所有内置的可比较类型:
int、uint、float、booi.struct、指针等一切可以比较的类型
func printArr[T any](arr []T) {
for _, item := range arr {
fmt.Println(item)
}
}
// 泛型的使用
func 泛型的基本使用() {
strArr := []string{"白夜", "炽翎"}
intArr := []int{1, 2}
printArr(strArr)
printArr(intArr)
}
切片泛型和泛型函数
// 自定义一个切片泛型
type mySlice[T int | float64] []T
// 给自定义的切片泛型添加一个求和方法
func (s mySlice[T]) sum() T {
var sum T
for _, v := range s {
sum += v
}
return sum
}
// 定义一个泛型函数
func add[T int | float64 | float32 | string](a T, b T) T {
return a + b
}
// 泛型函数与方法
func 切片泛型的使用() {
// 往自定义的切片泛型里,添加int类型的值
var i mySlice[int] = []int{1, 2, 3, 4}
fmt.Println(i.sum()) // 可以直接调用为切片泛型添加的一个求和方法
// 往自定义的切片泛型里,添加float64类型的值
var f mySlice[float64] = []float64{1.5, 2.7, 3.89, 4.55}
fmt.Println(f.sum())
//fmt.Println(add[int](1, 2))
fmt.Println(add(1, 2)) // 调用时,可以自动推导传入的参数的类型
//fmt.Println(add[string]("hh", "66"))
fmt.Println(add("hh", "66"))
//fmt.Println(add[float64](1.6, 2.8))
fmt.Println(add(1.6, 2.8))
}
map泛型
// 泛型map
type myMap[K string | int, V any] map[K]V
type User struct {
Name string
}
func map泛型的使用() {
m1 := myMap[string, string]{
"key": "符华",
}
fmt.Println(m1)
m2 := myMap[int, User]{
0: User{"符华"},
}
fmt.Println(m2)
}
泛型约束
// 自定义一个类型别名(将int8类型设置一个别名)
type int8A int8
// 自定义一个泛型约束
type myInt interface {
// 当类型设置了别名,在使用的时候要么在后面把这个别名约束也加进去
//int | int8 | int16 | int32 | int64 | int8A
// 要么在这个类型前面,加一个 ~ 符号,因为类型的别名是这个类型的衍生类型,在类型前面加 ~ 号就可以适配这个类型的全部衍生类型了
int | ~int8 | int16 | int32 | int64
}
// 给泛型约束定义一个比较大小的泛型函数
func getMaxNum[T myInt](a, b T) T {
if a > b {
return a
}
return b
}
func 泛型约束的使用() {
//var a int = 10
var a int8A = 10
//var b int = 20
var b int8A = 20
fmt.Println(getMaxNum(a, b))
}
泛型完整代码
package main
import "fmt"
/*
泛型:内置的泛型类型 any 和 comparable
any:表示go里面所有的内置基本类型,等价于 interface{}
comparable:表示go里面所有内置的可比较类型:`int、uint、float、booi.struct、指针` 等一切可以比较的类型
*/
func printArr[T any](arr []T) {
for _, item := range arr {
fmt.Println(item)
}
}
// 自定义一个切片泛型
type mySlice[T int | float64] []T
// 给自定义的切片泛型添加一个求和方法
func (s mySlice[T]) sum() T {
var sum T
for _, v := range s {
sum += v
}
return sum
}
// 泛型函数
func add[T int | float64 | float32 | string](a T, b T) T {
return a + b
}
// 泛型map
type myMap[K string | int, V any] map[K]V
type User struct {
Name string
}
// 自定义一个类型别名(将int8类型设置一个别名)
type int8A int8
// 自定义一个泛型约束
type myInt interface {
// 当类型设置了别名,在使用的时候要么在后面把这个别名约束也加进去
//int | int8 | int16 | int32 | int64 | int8A
// 要么在这个类型前面,加一个 ~ 符号,因为类型的别名是这个类型的衍生类型,在类型前面加 ~ 号就可以适配这个类型的全部衍生类型了
int | ~int8 | int16 | int32 | int64
}
// 给泛型约束定义一个比较大小的泛型函数
func getMaxNum[T myInt](a, b T) T {
if a > b {
return a
}
return b
}
func main() {
//泛型的基本使用()
//切片泛型的使用()
//map泛型的使用()
泛型约束的使用()
}
// 泛型的使用
func 泛型的基本使用() {
strArr := []string{"白夜", "炽翎"}
intArr := []int{1, 2}
printArr(strArr)
printArr(intArr)
}
// 泛型函数与方法
func 切片泛型的使用() {
// 往自定义的切片泛型里,添加int类型的值
var i mySlice[int] = []int{1, 2, 3, 4}
fmt.Println(i.sum()) // 可以直接调用为切片泛型添加的一个求和方法
// 往自定义的切片泛型里,添加float64类型的值
var f mySlice[float64] = []float64{1.5, 2.7, 3.89, 4.55}
fmt.Println(f.sum())
//fmt.Println(add[int](1, 2))
fmt.Println(add(1, 2)) // 调用时,可以自动推导传入的参数的类型
//fmt.Println(add[string]("hh", "66"))
fmt.Println(add("hh", "66"))
//fmt.Println(add[float64](1.6, 2.8))
fmt.Println(add(1.6, 2.8))
}
func map泛型的使用() {
m1 := myMap[string, string]{
"key": "符华",
}
fmt.Println(m1)
m2 := myMap[int, User]{
0: User{"符华"},
}
fmt.Println(m2)
}
func 泛型约束的使用() {
//var a int = 10
var a int8A = 10
//var b int = 20
var b int8A = 20
fmt.Println(getMaxNum(a, b))
}
接口
接口:用 type 和 interface 关键字定义
定义格式:
type 接口名 interface {
接口方法1(参数1 参数类型.....) [返回类型]
接口方法2() [返回类型]
接口方法3()
...
接口方法n() [返回类型]
}
接口可以将不同的类型绑定到一组公共的方法上,从而实现多态。(提高代码的复用率)
Go中的接口是隐式实现的,也就是说,如果一个类型实现了一个接口定义的所有方法,那么它就自动地实现了该接口。(不用像Java一样,用implements关键字指定实现哪个接口)
因此,我们可以通过将接口作为参数来实现对不同类型的调用,从而实现多态。
// 定义一个 寸劲 接口
type 寸劲 interface {
// 这个接口里面有这几个方法
寸劲开天(days int) string // 有参数,有返回值的方法
寸劲山崩() string // 无参数,有返回值的方法
寸劲岩破() // 无参数,无返回值的方法
}
// 定义一个 太虚剑气 接口
type 太虚剑气 interface {
太虚剑神(days int) string
}
// 定义一个函数,以空接口作为参数(可以传任何类型的参数)
func dataPrint(datas ...interface{}) {
for i, x := range datas {
switch x.(type) {
case bool:
fmt.Printf("参数 #%d 是一个bool类型,它的值是:%v\n", i, x)
case string:
fmt.Printf("参数 #%d 是一个string类型,它的值是:%v\n", i, x)
case int:
fmt.Printf("参数 #%d 是一个int类型,它的值是:%v\n", i, x)
case float64:
fmt.Printf("参数 #%d 是一个float64类型,它的值是:%v\n", i, x)
case nil:
fmt.Printf("参数 #%d 是一个nil类型,它的值是:%v\n", i, x)
default:
fmt.Printf("参数 #%d 是其他类型,它的值是:%v\n", i, x)
}
}
}
// 定义一个用户学习结构体,来实现接口所有个方法(一个类型实现了接口的所有方法,即实现了该接口)
type 学习 struct {
name string
}
// 定义一个结构体特有的方法
func (x 学习) 开始学习() string {
return fmt.Sprint(x.name, "现在要开始学习了.....")
}
// 实现 寸劲开天 接口(这里也可以用指针 x *学习,用了指针后,那么赋值的时候也需要传指针类型:&学习{"符华"})
func (x *学习) 寸劲开天(days int) string {
return fmt.Sprint(x.name, "学了", days, "天,学完了寸劲开天")
}
// 实现 寸劲山崩 接口
func (x 学习) 寸劲山崩() string {
return fmt.Sprint(x.name, "学完了寸劲山崩")
}
// 实现 寸劲岩破 接口
func (x 学习) 寸劲岩破() {
fmt.Println(x.name, "学完了寸劲岩破")
}
// 实现 太虚剑神 接口
func (x *学习) 太虚剑神(days int) string {
return fmt.Sprint(x.name, "学了", days, "天,学完了太虚剑神")
}
func main() {
接口的使用()
}
func 接口的使用() {
u := 学习{"符华"}
var cj 寸劲
//cj = u // 接口赋值为 学习 结构体,只有当实现了接口的全部方法才能赋值给接口,否则无法赋值
cj = &u // 只要接口方法有一个指针实现,则此处必须是指针
if u1, ok := cj.(*学习); ok { // 通过类型断言,来调用 结构体 独有的方法
fmt.Println(u1.开始学习())
}
cj.寸劲岩破()
fmt.Println(cj.寸劲山崩())
fmt.Println(cj.寸劲开天(2))
/*
类型断言:由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言
语法:接口.(类型),类型不是什么类型都可以传,必须要 接口 原先指向什么类型,那么就传什么类型
返回两个值,可以通过返回的 true、false 来判断断言(转换)是否成功
*/
//var jq 太虚剑气
//jq, ok := cj.(太虚剑气)
if jq, ok := cj.(太虚剑气); ok { // 如果转换成功,ok为true
fmt.Println(jq.太虚剑神(10))
} else {
fmt.Println("转换失败")
}
var a interface{}
a = u // 将 u 赋值给a,然后将 a 重新赋值给一个 学习 类型的变量,这就需要用 类型断言
var u1 学习
//u1 = a // 这里不可以直接赋值,需要使用类型断言
u1 = a.(学习) // a 原先指向 学习 类型,所以传类型时也必须要传 学习 类型
fmt.Println(u1)
// 空接口
dataPrint(u, "空接口", 123, 12.65, []int{1, 2, 3}, make(map[string]string, 2))
}
反射
Go中,使用反射需要导入 reflect 包
使用反射时,主要有两个很重要的方法:
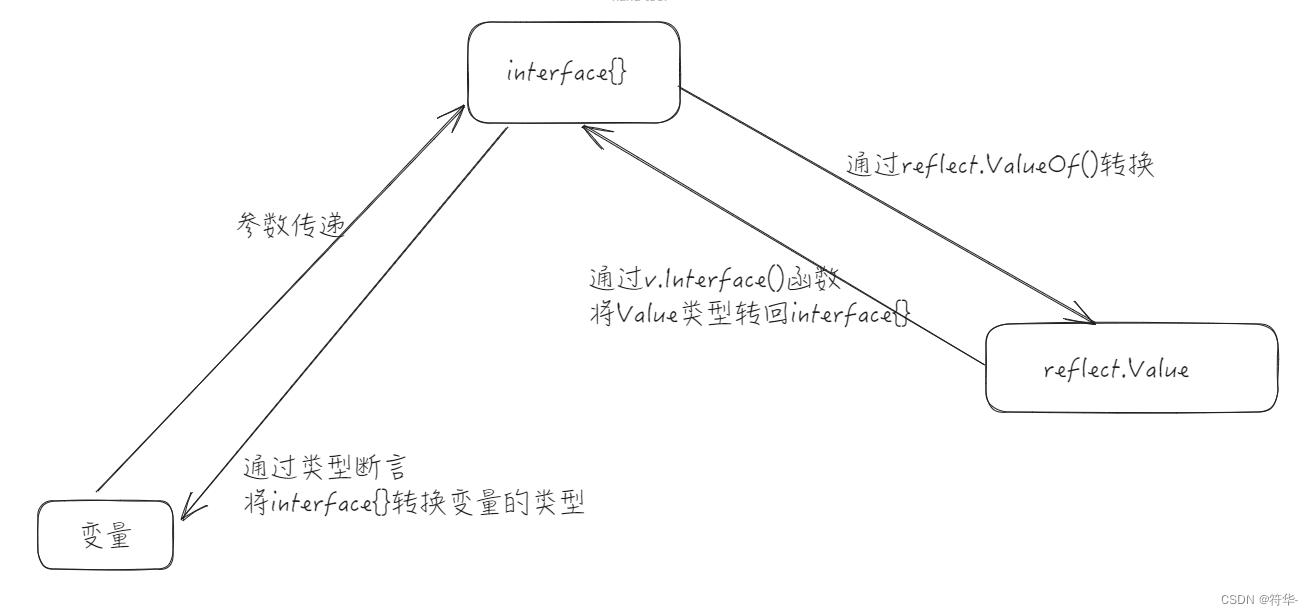
reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型(是一个接口)reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型(是一个结构体类型)
变量、interface{} 和 reflect.Value 是可以相互转换的,如下图:
package main
import (
"fmt"
"reflect"
)
/*
反射:需要导入 reflect 包
主要有两个函数:
reflect.TypeOf(变量名),获取变量的类型,返回 reflect.Type 类型(是一个接口)
reflect.ValueOf(变量名),获取变量的值,返回 reflect.Value 类型(是一个结构体类型)
变量、interface{}和 reflect.Value 是可以相互转换的
*/
type student struct {
Name string `json:"name"`
Age int
}
// 给 student 结构体绑定方法
func (s student) PrintStu() {
fmt.Println(s)
}
func (s student) GetSum(a, b int) {
fmt.Println(a + b)
}
// 基本数据类型、interface{}、reflect.Value 相互转换
func reflectTest01(a interface{}) {
// 通过反射获取传入的变量的 type
rTyp := reflect.TypeOf(a)
fmt.Println("rTyp=", rTyp)
// 获取到 reflect.Value
rVal := reflect.ValueOf(a)
n1 := 10 + rVal.Int() // 通过反射来获取变量的值,要求数据类型匹配:reflect.Value.Int()、reflect.Value.String()、reflect.Value.Float()......
fmt.Println(n1)
fmt.Printf("rVal=%v , rVal的类型=%T\n", rVal, rVal)
// 将 reflect.Value 转回 interface{}
iV := rVal.Interface()
// 将 interface{} 通过断言转回 需要的类型
n2 := iV.(int)
fmt.Println(n2)
}
// 对结构体的反射
func reflectTest02(a interface{}) {
// 通过反射获取传入的变量的 type
rTyp := reflect.TypeOf(a)
fmt.Println("rTyp=", rTyp)
// 获取到 reflect.Value
rVal := reflect.ValueOf(a)
fmt.Printf("rVal=%v , rVal的类型=%T\n", rVal, rVal)
fmt.Println("kind=", rVal.Kind(), rTyp.Kind())
// 将 reflect.Value 转回 interface{}
iV := rVal.Interface()
// 通过反射来获取结构体的值,需要先断言
// 将 interface{} 通过断言转回 需要的类型
stu := iV.(student)
fmt.Println(stu)
}
// 通过反射改变值(必须传入指针,才能改变值)
func reflectTest03(a interface{}) {
rTyp := reflect.TypeOf(a) // 通过反射获取传入的变量的 type
fmt.Println("rTyp=", rTyp)
rVal := reflect.ValueOf(a) // 获取到 reflect.Value
switch a.(type) { // 判断传入的参数的类型
case *int:
n1 := 10 + rVal.Elem().Int() // 通过反射来获取变量的值,因为传入的是指针,所以要先用 Elem() 再获取值
fmt.Println(n1)
fmt.Printf("rVal=%v , rVal的类型=%T\n", rVal.Elem(), rVal)
rVal.Elem().SetInt(200) // 通过反射改变值
case *student:
e := rVal.Elem()
e.FieldByName("Name").SetString("白夜") // 给指定的字段名改变值
}
}
// 通过反射遍历结构体的方法和属性
func reflectTest04(a interface{}) {
rTyp := reflect.TypeOf(a)
if rTyp.Kind() != reflect.Struct { // 判断传入的参数是否是结构体
return
}
rVal := reflect.ValueOf(a)
// 遍历结构体字段
numField := rTyp.NumField() // 获取结构体字段的数量
fmt.Println("numField =", numField)
for i := 0; i < numField; i++ {
// 打印字段的类型、字段名、字段值、字段标签
fmt.Println(rTyp.Field(i).Type, rTyp.Field(i).Name, "=", rVal.Field(i), rTyp.Field(i).Tag.Get("json"))
}
// 遍历结构体方法
numMethod := rTyp.NumMethod() // 获取结构体方法的数量
// 关于方法遍历时,方法的索引:是根据方法名称的ACSII码来排序的
for i := 0; i < numMethod; i++ {
// 打印方法的类型、方法名
//fmt.Println(rTyp.Method(i).Type, rTyp.Method(i).Name)
if i == 0 {
var params []reflect.Value
params = append(params, reflect.ValueOf(10))
params = append(params, reflect.ValueOf(20))
rVal.Method(i).Call(params)
} else {
rVal.Method(i).Call(nil)
}
}
}
func main() {
// 基本数据类型、interface{}、reflect.Value 相互转换
//var num int = 100
//reflectTest01(num)
//reflectTest03(&num) // 修改值必须传指针
//fmt.Println("通过反射改变num的值", num)
stu := student{"符华", 20}
//reflectTest02(stu)
//reflectTest03(&stu) // 修改值必须传指针
//fmt.Println("通过反射改变stu的值", stu)
reflectTest04(stu)
}
协程
接下来我们讲协程
协程:一个进程有多个线程,一个线程可以起多个协程
特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
主线程结束后,协程会被中断,这时需要一个有效的阻塞机制。
WaitGroup
如果主线程退出了,即使协程还没有执行完毕,也会退出。这时,我们可以使用WaitGroup,它用于等待一组协程的结束。
- 父线程调用Add方法来设定应等待的协程的数量。
- 每个被等待的协程在结束时应调用Done方法。
- 同时,主线程里可以调用Wait方法阻塞至所有协程结束。
goroutine的调度模型:MPG模型
- M:操作系统的主线程(是物理线程)
- P:协程执行需要的上下文
- G:协程
使用 goroutine 效率高,但是会出现并发/并行安全问题,需要加锁解决这个问题。
如果协程发生异常,可以用recover来捕获异常,进行除了。这样主函数不会受到影响,可以继续执行。
package main
import (
"fmt"
"strconv"
"sync"
"time"
)
// 一个函数,每隔1秒输出
func goroutineTest01() {
for i := 0; i < 10; i++ {
fmt.Println("test() hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
var (
myMap = make(map[int]int, 10)
// 定义一个全局的互斥锁
lock sync.Mutex // sync 同步的意思,Mutex 互斥的意思
wg sync.WaitGroup // 用于等待一组线程的结束
)
func goroutineTest02(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
lock.Lock() // 写之前加锁
myMap[n] = res // concurrent map writes 并发写入问题
lock.Unlock() // 写完之后解锁
//wg.Add()中有20个需要执行的协程,每执行完一个后调用wg.Done(),让协程数量-1,直到协程数量为0,表示全部协程执行完毕
wg.Done() // 这里表示每执行完一个协程,wg.Add()里面的数量-1
}
func main() {
协程()
}
func 协程() {
//goroutineTest01() // 如果这样调用,这里是先执行完goroutineTest01,再执行main里面的打印
//go goroutineTest01() // 开启了一个线程,这样goroutineTest01和main就是同时执行
//for i := 0; i < 10; i++ {
// fmt.Println("main() hello,world " + strconv.Itoa(i))
// time.Sleep(time.Second)
//}
//cpuNum := runtime.NumCPU() //获取电脑的cpu数量
//fmt.Println("cpu个数:", cpuNum)
// 可以自己设置使用多少个cpu
//runtime.GOMAXPROCS(cpuNum - 1) // 预留一个cpu
wg.Add(20) // 这里表示有20个协程需要执行
// 开启多个协程
for i := 1; i <= 20; i++ {
go goroutineTest02(i)
}
wg.Wait() // 告诉主线程要等一下,等协程全部执行完了载退出
fmt.Println("全部协程执行完毕")
// 遍历输出map结果
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
}
func 协程异常捕获() {
// 这里我们可以使用defer + recover来捕获异常
defer func() {
if err := recover(); err != nil {
fmt.Println("发生错误,错误信息:", err)
}
}()
var myMap map[int]string
myMap[0] = "Go" // map没有make,出现error
}
channel
channel也就是管道,一般情况下,我们是配合协程一起使用的。
channel管道:本质就是一个数据结构——队列
介绍
- 数据是先进先出:FIFO:first in first out
- 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的
- channel是有类型的,一个string的channel只能存放string类型数据
- channel必须是引用类型,必须初始化才能写入数据,也就是需要make后才能使用
语法:
var 变量名 chan 数据类型,变量名 = make(chan 数据类型, 容量) (使用make进行初始化)
举例:
var intChan chan int // 用于存放int数据
var mapChan chan map[int]string // 用于存放map[int]string数据
var perChan chan Pserson // 用于存放Pserson结构体数据
var perChan1 chan *Pserson //用于存放Pserson结构体指针数据
var perChan1 chan interface{} //可以存放任何类型数据,但是取的时候要注意用类型断言
channel遍历
-
通常使用for-range方式进行遍历,不用取长度的方式来遍历管道是因为管道每取一次,长度就会变。
-
在遍历时,如果管道没有关闭,会出现deadlock的错误;如果管道已经关闭,则正常遍历数据,遍历完后,退出遍历。
管道可以声明为只读或只写(默认情况下是双向的,也就是可读可写)
- 只写:
var intChan chan<- int - 只读:
var intChan <-chan int
基本使用
func 管道() {
// 创建一个可以存放3个int类型的管道
var intChan chan int
// 因为channel是引用类型,它的值其实是一个地址,然后这个地址指向的就是管道队列;然后intChan本身也有一个地址
intChan = make(chan int, 3)
fmt.Printf("intChan 的值=%v intChan 本身的地址=%p\n", intChan, &intChan) // intChan 的值=0xc00006e080 intChan 本身的地址=0xc00004c020
// 向管道写入数据,写入、读取管道数据时,用 <- 表达式
intChan <- 10
num := 200
intChan <- num
// 设置的管道容量是3,最多只能往里面写入3条数据(长度不能超过容量)
intChan <- 100
// 管道的长度和cap(容量)
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 3,3
// 读取管道的数据。从管道中取出了数据,可以再往里面放数据
//<-intChan // 可以直接这么写,也是取出数据;不用变量接收,把取出的数据扔了不要
n1 := <-intChan // 这里取出来的是最先写入到管道里的数据(先进先出)
fmt.Println("n1=", n1) // 10
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 2,3
// 取出了一条数据后再往里面放一条数据
intChan <- 500
close(intChan) // 关闭管道,这时就不能再往管道里面写入数据了,但是读取没问题
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 3,3
// 在没有使用协程的情况下,如果管道数据已经全部取出,再取会报错
n2 := <-intChan
n3 := <-intChan
fmt.Printf("n2 = %v n3 = %v\n", n2, n3) // 200,100
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 1,3
// 遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2 <- i * 2
}
close(intChan2) // 管道写完数据后,先将管道关闭,再进行遍历
// 不能用取长度的方式来遍历管道,因为管道每取一次,长度就会变,要用 range 方式遍历
for v := range intChan2 { // 这里只返回一个数据,管道里面没有下标
fmt.Println("v =", v)
}
}
和协程一起使用
案例一
package main
import (
"fmt"
"sync"
)
// 全局 WaitGroup 变量
var wg sync.WaitGroup // 用于等待一组线程的结束
// 管道写入数据
func writeData(intChan chan int) {
for i := 0; i < 50; i++ {
intChan <- i
fmt.Printf("writeData 写入数据=%v\n", i)
}
close(intChan)
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
// 管道读取数据
func readData(intChan chan int) {
for {
v, ok := <-intChan
if !ok {
break
}
fmt.Printf("readData 读到数据=%v\n", v)
}
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
func main() {
协程和管道应用1()
}
func 协程和管道应用1() {
// 创建两个管道
intChan := make(chan int, 10)
wg.Add(2) // 说明开启了两个线程
// 开启了两个协程,writeData和readData应该是交叉执行的
go writeData(intChan) // 开启一个协程,往 intChan 中写入数据
go readData(intChan) // 开启一个协程,读取 intChan 的数据
wg.Wait() // 告诉主线程需要等待协程执行完毕
fmt.Println("程序执行完毕!")
}
案例二
-
需求:要求统计1-8000的数字中,哪些是素数
-
将统计素数的任务,分配给4个协程去完成
// 判断是否为素数
func isPrime(intChan, primeChan chan int) {
var isPrime bool // 标识是否是素数
for v := range intChan {
isPrime = true
for i := 2; i < v; i++ {
if v%i == 0 {
isPrime = false
break
}
}
if isPrime { // 如果为素数,则往primeChan中写入数据
primeChan <- v
}
}
fmt.Println("isPrime 读取素数完毕")
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
func 协程和管道应用2() {
// 需求:要求统计1-8000的数字中,哪些是素数
// 将统计素数的任务,分配给4个协程去完成
intChan := make(chan int, 1000) // 读写1-8000数字的管道
primeChan := make(chan int, 2000) // 存储素数的管道
wg.Add(5) // 下面开启了5个协程
// 开启写入 1-8000 数字的协程
go func() {
for i := 1; i <= 8000; i++ {
intChan <- i
}
close(intChan)
wg.Done()
}()
// 开启4个读取 1-8000 数字,并统计素数的协程
for i := 0; i < 4; i++ {
go isPrime(intChan, primeChan)
}
wg.Wait() // 等待协程执行完毕
close(primeChan) // 关闭 primeChan 管道
// 遍历primeChan,把结果取出来
for v := range primeChan {
fmt.Printf("素数是 = %v\n", v)
}
}
select…case
传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock。
在实际开发中,可能不好确定什么时候关闭管道,这时可以使用select方式解决。
func 管道注意细节() {
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
// 传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
// 在实际开发中,可能不好确定什么时候关闭管道,这时可以使用select方式解决
for {
select {
// 这里如果intChan一直没有关闭,也不会一直阻塞而导致deadlock
// 如果一个case取不到数据,会自动到下一个case中取
case v := <-intChan:
fmt.Println("从intChan读取的数据=", v)
case v := <-stringChan:
fmt.Println("从stringChan读取的数据=", v)
default:
fmt.Println("都取不到了")
return
}
}
}
main.go 完整代码
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup // 用于等待一组线程的结束
// 管道写入数据
func writeData(intChan chan int) {
for i := 0; i < 50; i++ {
intChan <- i
fmt.Printf("writeData 写入数据=%v\n", i)
}
close(intChan)
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
// 管道读取数据
func readData(intChan chan int) {
for {
v, ok := <-intChan
if !ok {
break
}
fmt.Printf("readData 读到数据=%v\n", v)
}
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
// 判断是否为素数
func isPrime(intChan, primeChan chan int) {
var isPrime bool // 标识是否是素数
for v := range intChan {
isPrime = true
for i := 2; i < v; i++ {
if v%i == 0 {
isPrime = false
break
}
}
if isPrime { // 如果为素数,则往primeChan中写入数据
primeChan <- v
}
}
fmt.Println("isPrime 读取素数完毕")
wg.Done() // 执行完一个线程后,调用这个方法,主线程中需要等待执行的协程数量-1
}
func main() {
//管道()
//协程和管道应用1()
//协程和管道应用2()
//管道注意细节()
}
func 管道() {
// 创建一个可以存放3个int类型的管道
var intChan chan int
// 因为channel是引用类型,它的值其实是一个地址,然后这个地址指向的就是管道队列;然后intChan本身也有一个地址
intChan = make(chan int, 3)
fmt.Printf("intChan 的值=%v intChan 本身的地址=%p\n", intChan, &intChan) // intChan 的值=0xc00006e080 intChan 本身的地址=0xc00004c020
// 向管道写入数据,写入、读取管道数据时,用 <- 表达式
intChan <- 10
num := 200
intChan <- num
// 设置的管道容量是3,最多只能往里面写入3条数据(长度不能超过容量)
intChan <- 100
// 管道的长度和cap(容量)
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 3,3
// 读取管道的数据。从管道中取出了数据,可以再往里面放数据
//<-intChan // 可以直接这么写,也是取出数据;不用变量接收,把取出的数据扔了不要
n1 := <-intChan // 这里取出来的是最先写入到管道里的数据(先进先出)
fmt.Println("n1=", n1) // 10
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 2,3
// 取出了一条数据后再往里面放一条数据
intChan <- 500
close(intChan) // 关闭管道,这时就不能再往管道里面写入数据了,但是读取没问题
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 3,3
// 在没有使用协程的情况下,如果管道数据已经全部取出,再取会报错
n2 := <-intChan
n3 := <-intChan
fmt.Printf("n2 = %v n3 = %v\n", n2, n3) // 200,100
fmt.Printf("管道 长度 = %v 容量 = %v\n", len(intChan), cap(intChan)) // 1,3
// 遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2 <- i * 2
}
close(intChan2) // 管道写完数据后,先将管道关闭,再进行遍历
// 不能用取长度的方式来遍历管道,因为管道每取一次,长度就会变,要用 range 方式遍历
for v := range intChan2 { // 这里只返回一个数据,管道里面没有下标
fmt.Println("v =", v)
}
}
func 协程和管道应用1() {
// 创建两个管道
intChan := make(chan int, 10)
wg.Add(2) // 说明开启了两个线程
// 开启了两个协程,writeData和readData应该是交叉执行的
go writeData(intChan) // 开启一个协程,往 intChan 中写入数据
go readData(intChan) // 开启一个协程,读取 intChan 的数据
wg.Wait() // 告诉主线程需要等待协程执行完毕
fmt.Println("程序执行完毕!")
}
func 协程和管道应用2() {
// 需求:要求统计1-8000的数字中,哪些是素数
// 将统计素数的任务,分配给4个协程去完成
intChan := make(chan int, 1000) // 读写1-8000数字的管道
primeChan := make(chan int, 2000) // 存储素数的管道
wg.Add(5) // 下面开启了5个协程
// 开启写入 1-8000 数字的协程
go func() {
for i := 1; i <= 8000; i++ {
intChan <- i
}
close(intChan)
wg.Done()
}()
// 开启4个读取 1-8000 数字,并统计素数的协程
for i := 0; i < 4; i++ {
go isPrime(intChan, primeChan)
}
wg.Wait() // 等待协程执行完毕
close(primeChan) // 关闭 primeChan 管道
// 遍历primeChan,把结果取出来
for v := range primeChan {
fmt.Printf("素数是 = %v\n", v)
}
}
func 管道注意细节() {
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
// 传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
// 在实际开发中,可能不好确定什么时候关闭管道,这时可以使用select方式解决
for {
select {
// 这里如果intChan一直没有关闭,也不会一直阻塞而导致deadlock
// 如果一个case取不到数据,会自动到下一个case中取
case v := <-intChan:
fmt.Println("从intChan读取的数据=", v)
case v := <-stringChan:
fmt.Println("从stringChan读取的数据=", v)
default:
fmt.Println("都取不到了")
return
}
}
}
文件
文件这块没啥好说的,拿到函数直接用就行。需要注意一点就是文件file是一个指针类型。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
//基本使用读()
基本使用写()
}
func 基本使用读() {
// 打开文件
file, err := os.Open("C:\\Users\\Administrator\\Desktop\\1.txt")
if err != nil {
fmt.Println("文件打开错误:", err)
}
//fmt.Printf("file=%v", file) // 输出的是一个地址
defer file.Close() // 当函数退出时,要关闭file,否则会有内存泄露
// 创建一个Reader,是带缓冲,默认缓冲区为4096(这种方式比较适合大文件读取)
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { // io.EOF表示读到了文件末尾,这时就可以退出循环了
break
}
fmt.Print(str)
}
fmt.Println("文件读取完成")
// ioutil.ReaderFile,一次性将文件读取到位 这种方法适合读取比较小的文件
// 不过新版本 ioutil.ReadFile 已经弃用了,这个函数其实调用的就是 os.ReadFile
content, err := os.ReadFile("C:\\Users\\Administrator\\Desktop\\学习计划.txt")
if err != nil {
fmt.Printf("文件读取失败:%v", err)
}
//fmt.Println(content) // content是一个 []byte
fmt.Println(string(content)) // 所以要转成string
}
func 基本使用写() {
filePath := "C:\\Users\\Administrator\\Desktop\\测试.txt"
/*
OpenFile 第二个参数:文件打开模式
O_RDONLY int = syscall.O_RDONLY // 只读
O_WRONLY int = syscall.O_WRONLY // 只写
O_RDWR int = syscall.O_RDWR // 读写
O_APPEND int = syscall.O_APPEND // 追加
O_CREATE int = syscall.O_CREAT // 如果不存在就创建
O_EXCL int = syscall.O_EXCL // 文件必须不存在
O_SYNC int = syscall.O_SYNC // 同步io
O_TRUNC int = syscall.O_TRUNC // 打开时清空文件(一般用于覆盖写入)
第三个参数只作用于linux系统,Windows系统不起作用
*/
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("文件打开失败:%v", err)
}
defer file.Close()
str := "hello,Golang\n"
// NewWriter 带缓冲区的写入,写完之后要用flush刷新。
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
writer.Flush()
}
ok,以上就是本篇的全部内容了。下一篇可能是关于网络请求相关的,也有可能是Gorm相关的。