什么是开窗函数?
开窗函数对一组值进行操作,它不像普通聚合函数那样需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列
开窗函数的语法形式为:函数 + over(partition by <分组用列> order by <排序用列>),表示对数据集按照分组用列进行分区,并且并且对每个分区按照函数聚合计算,最终将计算结果按照排序用列排序后返回到该行。括号中的两个关键词partition by 和order by 可以只出现一个。
注意:开窗函数不会互相干扰,因此在同一个查询语句中可以同时使用多个开窗函数
开窗函数适用于 mysql 8.0以上版本, sql sever 、hive、oracle 等
测试数据
create table score (
grade VARCHAR(10) not null,
subject VARCHAR(10) not null,
name VARCHAR(50) not null,
score int not null
);
INSERT INTO score (grade, subject, name, score) VALUES ('Grade1', '语文', 'John', 90),
('Grade2', '语文', 'Amy', 70),
('Grade1', '语文', 'Mike', 80),
('Grade2', '语文', 'Lisa', 80),
('Grade2', '语文', 'Tom', 90),
('Grade1', '英语', 'John', 80),
('Grade2', '英语', 'Amy', 90),
('Grade1', '英语', 'Mike', 80),
('Grade2', '英语', 'Lisa', 90),
('Grade2', '英语', 'Tom', 100);
一、排序开窗函数
-- 一、排序开窗函数
-- ① row_number() -- 相同值排名连续,返回结果1、2、3、4
-- ② rank() -- 相同值排名相同,后续排名不连续,返回结果为 1、2、2、4
-- ③ dense_rank() -- 相同值排名相同,后续排名连续,返回结果为 1、2、2、3
-- ④ ntile(n) -- 分组排名,将数据分为n组并返回对应组号1、2......n
select grade
,subject
,score
-- ,row_number() over(partition by subject order by score desc) as row_numbers
-- ,rank() over(partition by subject order by score desc) as ranks
-- ,dense_rank() over(partition by subject order by score desc) as dense_ranks
,ntile(2) over(partition by subject order by score desc) as ntiles
from score;1.1、row_number
,row_number() over(partition by subject order by score desc) as row_numbers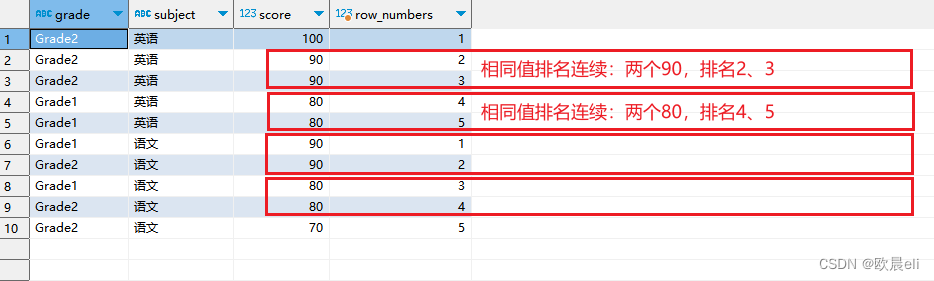
1.2、rank
,rank() over(partition by subject order by score desc) as ranks
1.3、dense_rank
,dense_rank() over(partition by subject order by score desc) as dense_ranks
1.4、ntile
,ntile(2) over(partition by subject order by score desc) as ntiles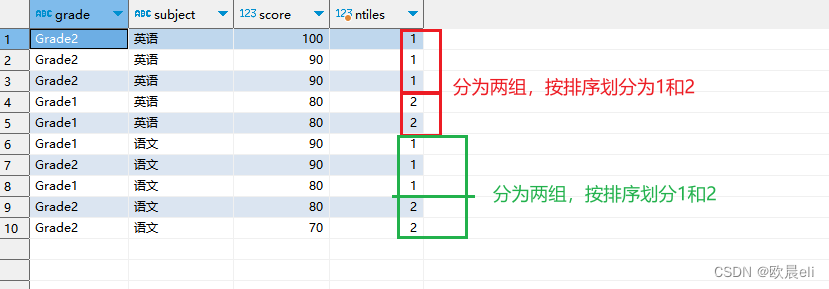
二、聚合开窗函数
-- 二、聚合开窗函数, 【有order by ,依不连续次序聚合;无order by 分组聚合】
-- ① sum() -- 分组求和
-- ② count() -- 分组求总数
-- ③ min() -- 分组求最小值
-- ④ max() -- 分组求最大值
-- ⑤ avg() --分组求均值
select grade
,subject
,score
-- ,sum(score) over(partition by subject) as sum聚合no_order_by
-- ,sum(score) over(partition by subject order by score desc) as sum聚合order_by
-- ,count(score) over(partition by subject) as count聚合no_order_by
-- ,count(score) over(partition by subject order by score desc) as count聚合order_by
-- ,min(score) over(partition by subject) as min聚合no_order_by
-- ,min(score) over(partition by subject order by score desc) as min聚合order_by
-- ,max(score) over(partition by subject) as max聚合no_order_by
-- ,max(score) over(partition by subject order by score desc) as max聚合order_by
-- ,avg(score) over(partition by subject) as avg聚合no_order_by
-- ,avg(score) over(partition by subject order by score desc) as avg聚合order_by
from score;
2.1、sum
2.1.1 不带order by
,sum(score) over(partition by subject) as sum聚合no_order_by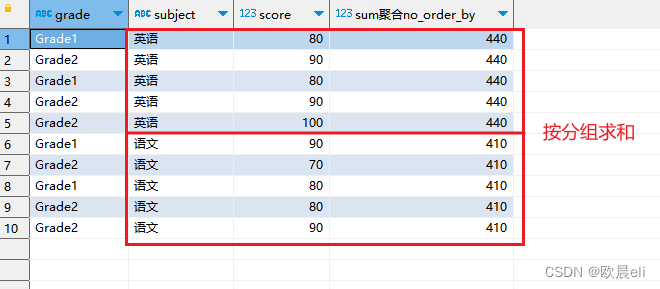
2.1.2 带有order by
,sum(score) over(partition by subject order by score desc) as sum聚合order_by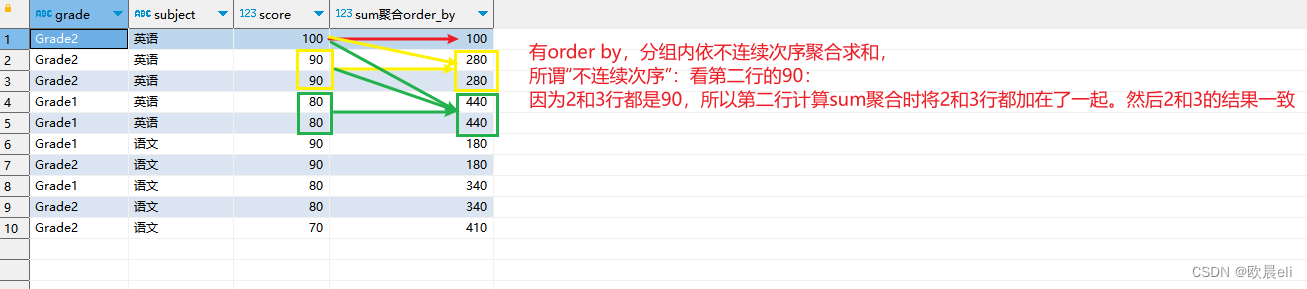
三、其他开窗函数
-- 三、其他开窗函数
-- ① lag(字段名,n,0) -- 落后移位开窗函数,表示返回向后第n行指定字段对应数据。其中n代表向后偏移n行,0代表若偏移行数超出表范围则返回0也可以改成其他值,若不写则默认null
-- ② lead(字段名,n,0) -- 超前移位开窗函数,与lag()相反,表示返回向前第n行指定字段对应数据
-- ③ first_value() -- 取分组后截止到当前行,排序后第一个值
-- ④ last_value() -- 取分组后截止到当前行,排序后最后一个值
-- 【oracle独有函数】⑤ ratio_to_report(字段名) over(partition by 字段名) -- 百分比分析函数,ratio_to_report(字段名) 为分子,over(partition by 字段名) 为分母,若分母中partition by 字段名 省略则表示占数据集整体百分比。为Oracle数据库函数,mysql不能使用
select grade
,subject
,score
-- ,lag(score,1,0) over(partition by subject order by score desc) as lag移位order_by
-- ,lag(score,1,0) over(partition by subject) as lag移位no_order_by
-- ,lead(score,1,0) over(partition by subject order by score desc) as lead移位order_by
-- ,lead(score,1,0) over(partition by subject) as lead移位no_order_by
-- ,first_value(score) over(partition by subject order by score asc) as first_value排序1
,last_value(score) over(partition by subject order by score asc) as last_value排序1
from score;四、开窗函数的定位框架
-- 四、开窗函数的定位框架
-- 在order by 后存在可省略的窗口框架 range/rows between x and y ,主要用于对partition by的分组排序后结果做进一步限制,并定位出限制后的运算范围。
-- range表示按照值的排序范围进行范围的定义,而rows表示按照行的范围进行范围的定义。
-- 若order by 后未指定框架,那么默认框架将采用 range unbounded preceding and current row,表示按照值的排序范围进行范围的定义,从开窗后的第一行到当前行。
-- 若窗口函数没有order by,也就不存在框架range/rows between x and y。
-- 框架range/rows between x and y 具体x、y可取值见下表:
-- 可取值 含义
-- unbounded preceding partition by 分组order by后 第一行
-- unbounded following partition by 分组order by后 最后一行
-- current row partition by 分组order by后 当前行
-- n preceding partition by 分组order by后 前n行
-- n following partition by 分组order by后 后n行
-- 其中:range 只支持使用 unbounded preceding、 unbounded following、current row
select grade
,subject
,score
-- ,sum(score) over(partition by subject order by score desc) as sum聚合默认
-- ,sum(score) over(partition by subject order by score desc rows between unbounded preceding and current row) as sum聚合rows_preceding
-- ,sum(score) over(partition by subject order by score desc rows between current row and unbounded following) as sum聚合rows_preceding
-- ,sum(score) over(partition by subject order by score desc range between unbounded preceding and current row) as sum聚合range
-- ,sum(score) over(partition by subject order by score desc range between current row and unbounded following) as sum聚合range_following
-- ,sum(score) over(partition by subject order by score desc rows between 2 preceding and 1 following) as sum聚合2_1
,sum(score) over(partition by subject order by score desc range between 1 preceding and 1 following) as sum聚合range
from score;参考:SQL函数 - 开窗(窗口)函数 - 知乎