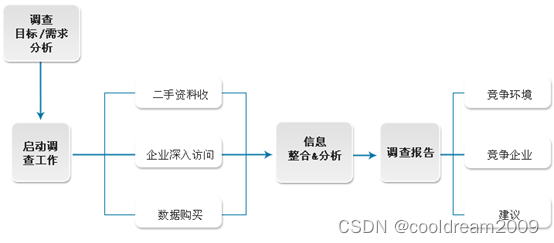
线程池
进程已经能做到并发编程了 , 为什么还需要线程 ?
进程实在是太重量了 , 创建和销毁成本都比较高 , 需要申请释放资源
线程就是针对上述问题的优化 , 因为他是共用同一组系统资源的 , 一旦资源申请好了 , 后续就不需要再继续申请了
虽然线程已经很好了 , 不过在更高频率下的创建释放的情况下 , 线程也就扛不住了
所以还需要进一步优化 :
1. 线程池
2. 协程 (也叫做纤程) , 更加轻量级的线程
我们主要研究一下线程池 :
线程池解决的思路就是把线程创建好之后 , 放到池子中 , 而不是通过系统来销毁
当线程用完了 , 还是还回到池子中 , 而不是通过系统来进行销毁
上述操作 , 就又进一步的提高效率了
那为什么把线程放到池子里 , 然后从池子中取出线程就要比从系统中创建线程来得快呢 ?
如果是从系统这里创建线程, 需要调用系统api, 进一步的由操作系统内核完成线程创建(内核态, 内核是给所有的进程提供服务的, 不可控的)
如果是从线程池这里获取线程, 上述的内核中进行的操作, 都提前做好了, 直接靠用户代码完成线程获取(用户态, 可控)
标准库中的线程池

线程池对象创建好后, 使用submit 方法, 就可以把任务添加到线程池中
public class Demo24 {
public static void main(String[] args) {
// ExecutorService 叫做执行器服务
// Executors.newFixedThreadPool() 创建固定线程个数的线程池
// Executors 是静态方法
// Executors 通过.的方式调用静态方法
// 固定个数的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
// 线程数量动态增加的线程池
// Executors.newCachedThreadPool();
// 把任务加入到线程池中
// 与定时器类似,线程池内部也有线程阻止退出,我们需要手动关闭
threadPool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello 线程池");
}
});
}
}
经典面试题
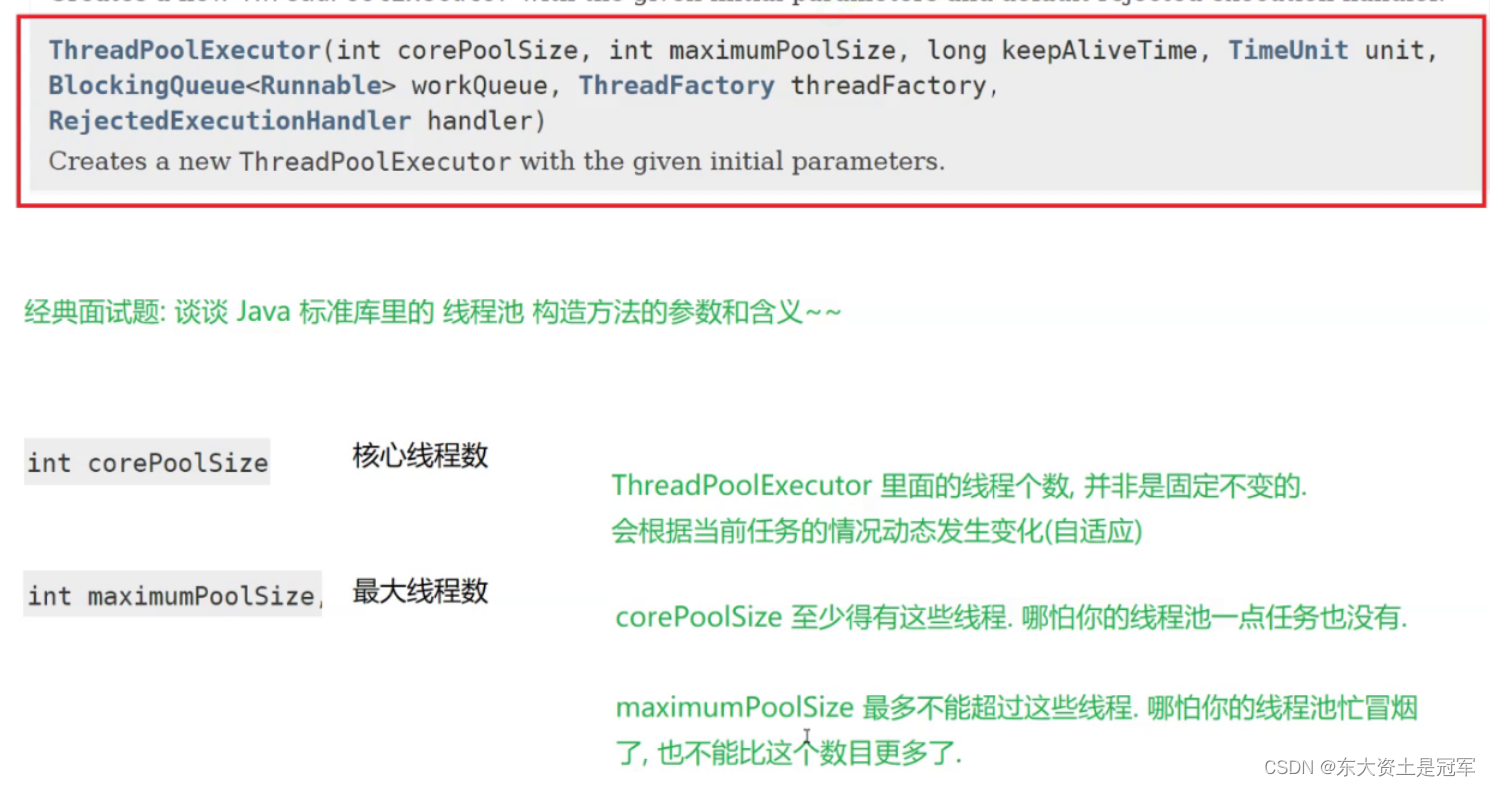
如果把线程池比喻成公司, 核心线程数就是正式员工数量. 最大线程数就是正式员工 + 实习生 的数量
当公司业务不忙的时候, 就不需要实习生; 当公司业务繁忙的时候, 就找些实习生来分配任务.
不忙的时候再裁掉.
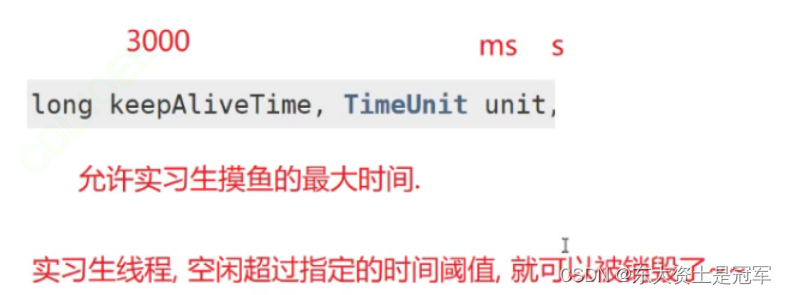


官方提供一下拒绝策略(重点):
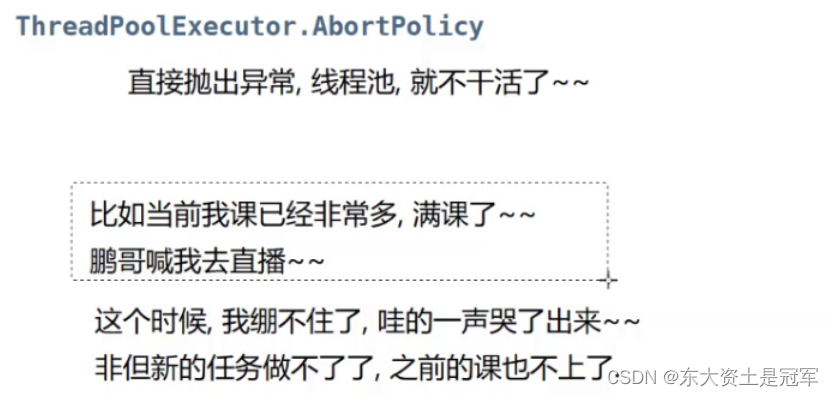


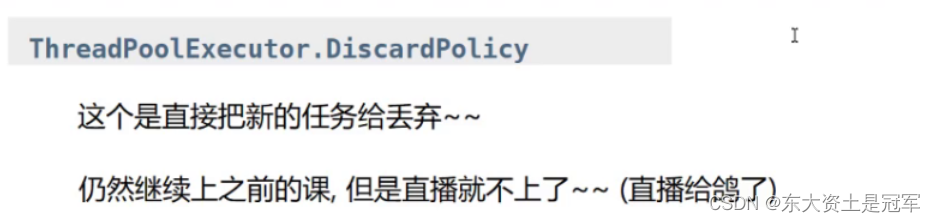
第二个和第四个的区别在于第四个策略中新任务完全不会执行, 第二个中还会执行新任务
自己实现线程池
阻塞队列来保存一些任务 , submit 方法给线程池添加任务 , 线程池内部再持有一些线程来消费执行这里的任务
线程池就相当于一个简单的生产者-消费者模型
class MyThreadPool {
// 由于插入任务可以一次性插入很多.需要能够把当前尚未执行的任务都保存起来 -> 队列
// 这个队列就是一个任务队列,把当前线程池中要完成的内容都放到这个队列里
// 再由线程池内部的工作线程负责完成他们
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
// 通过这个方法, 来把任务添加到线程池中.
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
// 构造方法中,就需要创建一些线程,让这些线程负责完成上述执行任务的工作
// n 表示线程池里有几个线程.
// 创建了一个固定数量的线程池.
public MyThreadPool(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
// 取出任务, 并执行~~
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
}
// 线程池
public class Demo24 {
public static void main(String[] args) throws InterruptedException {
MyThreadPool pool = new MyThreadPool(4);
for (int i = 0; i < 1000; i++) {
pool.submit(new Runnable() {
@Override
public void run() {
// 要执行的工作
System.out.println(Thread.currentThread().getName() + " hello");
}
});
}
}
}此时线程的调度是随机的
当前给这个线程池插入的任务, 在执行的时候, 也不一定是N个线程的工作量完全相等
但是从统计意义上说, 任务栏均等~
创建线程池的时候, 线程个数是咋确定的?
MyThreadPool pool = new MyThreadPool(4);线程池的线程数目网上查资料, 你能看到很多种说法
比如, 假设cpu核数为N , 线程池线程个数: N N + 1 , 1.2 * N , 1.5 * N , 2 * N 这个说法不准确
不同项目中, 线程要做的工作是不一样的:
有的线程的工作, 是"CPU密集型", 线程的工作全是运算
大部分工作都要在CPU上完成, CPU得给工作安排核心后工作才有进展
如果CPU是N个核心, 当你线程数量也是N的时候, 理想情况就是每个核心上有一个线程
如果搞很多线程, 线程也就是在排队等待, 不会有新的进展
有的线程的工作, 是" IO密集型" , 读写文件, 等待用户输入, 网络通信
涉及大量的等待时间(等用户) 等的过程中, 没有使用CPU
这样就算线程更多一些, 也不会给CPU造成太大的负担
比如CPU是16个核心, 写32 个线程 由于是IO密集的
这里大部分线程都在等, 都不消耗CPU, 反而CPU的占用情况还很低
实际开发中, 一个线程往往是一部分工作是CPU密集的, 一部分工作是IO密集的
此时一个线程几成是在CPU上, 几成是在等待IO说不好
更好的做法是通过实验的方式, 来找到合适的线程数,
性能测试尝试不同的线程数目 找到性能和系统资源开销比较均衡的线程数