简介
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device=‘’)
详细:DataLoader
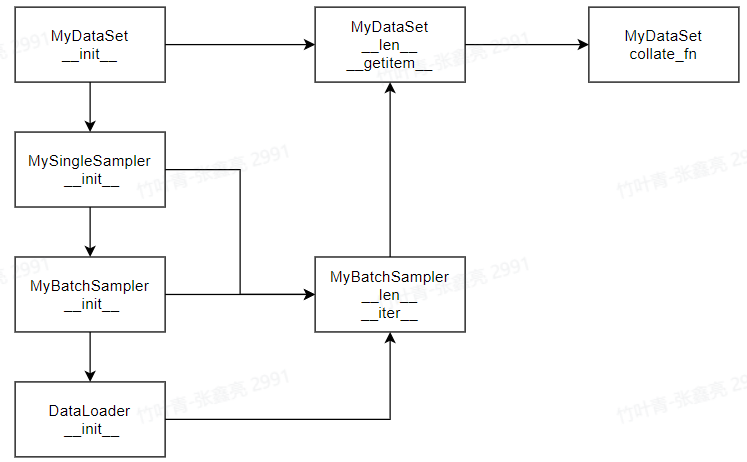
自己基于DataLoader实现各个模块
代码实现
MyDataset基于torch中的Data实现对个人数据集的载入,例如图像和标签载入
SingleSampler基于torch中的Sampler实现对于数据的batch个数图像的载入,例如,Batch_Size=4,实现对所有数据中选取4个索引作为一组,然后在MyDataset中基于__getitem__根据图像索引去进行图像操作
MyBathcSampler基于torch的BatchSampler实现自己对于batch_size数据的处理。需要基于SingleSampler实现Sampler的处理,更为灵活。MyBatchSampler的存在会自动覆盖DataLoader中的batch_size参数
注:Sampler的实现,将会与shuffer冲突,shuffer是在没有实现sampler前提下去自动判断选择的sampler类型
collate_fn是实现将batch_size的图像数据进行打包,遍历过程中就可以实现batch_size的images和labels对应
sampler
from typing import Iterator, List
import torch
from torch.utils.data import BatchSampler
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.data import Sampler
class MyDataset(Dataset):
def __init__(self) -> None:
self.data = torch.arange(20)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
@staticmethod
def collate_fn(batch):
return torch.stack(batch, 0)
class MyBatchSampler(BatchSampler):
def __init__(self, sampler: Sampler[int], batch_size: int) -> None:
self._sampler = sampler
self._batch_size = batch_size
def __iter__(self) -> Iterator[List[int]]:
batch = []
for idx in self._sampler:
batch.append(idx)
if len(batch) == self._batch_size:
yield batch
batch = []
yield batch
def __len__(self):
return len(self._sampler) // self._batch_size
class SingleSampler(Sampler):
def __init__(self, data_source) -> None:
self._data = data_source
self.num_samples = len(self._data)
def __iter__(self):
# 顺序采样
# indices = range(len(self._data))
# 随机采样
indices = torch.randperm(self.num_samples).tolist()
return iter(indices)
def __len__(self):
return self.num_samples
train_set = MyDataset()
single_sampler = SingleSampler(train_set)
batch_sampler = MyBatchSampler(single_sampler, 8)
train_loader = DataLoader(train_set, batch_size=4, sampler=single_sampler, pin_memory=True, collate_fn=MyDataset.collate_fn)
for data in train_loader:
print(data)
batch_sampler
from typing import Iterator, List
import torch
from torch.utils.data import BatchSampler
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.data import Sampler
class MyDataset(Dataset):
def __init__(self) -> None:
self.data = torch.arange(20)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
@staticmethod
def collate_fn(batch):
return torch.stack(batch, 0)
class MyBatchSampler(BatchSampler):
def __init__(self, sampler: Sampler[int], batch_size: int) -> None:
self._sampler = sampler
self._batch_size = batch_size
def __iter__(self) -> Iterator[List[int]]:
batch = []
for idx in self._sampler:
batch.append(idx)
if len(batch) == self._batch_size:
yield batch
batch = []
yield batch
def __len__(self):
return len(self._sampler) // self._batch_size
class SingleSampler(Sampler):
def __init__(self, data_source) -> None:
self._data = data_source
self.num_samples = len(self._data)
def __iter__(self):
# 顺序采样
# indices = range(len(self._data))
# 随机采样
indices = torch.randperm(self.num_samples).tolist()
return iter(indices)
def __len__(self):
return self.num_samples
train_set = MyDataset()
single_sampler = SingleSampler(train_set)
batch_sampler = MyBatchSampler(single_sampler, 8)
train_loader = DataLoader(train_set, batch_sampler=batch_sampler, pin_memory=True, collate_fn=MyDataset.collate_fn)
for data in train_loader:
print(data)
参考
Sampler:https://blog.csdn.net/lidc1004/article/details/115005612








![[ MySQL ] — 复合查询和内外连接的使用](https://img-blog.csdnimg.cn/29953cbebbd3470792b866423b05ea1a.png)
