1、摘要
1.1 第一段
作者说深度神经网络是非常难以训练的,我们使用了一个残差学习框架的网络来使得训练非常深的网络比之前容易得很多。
把层作为一个残差学习函数相对于层输入的一个方法,而不是说跟之前一样的学习unreferenced functions
作者提供了非常多的实验证据证明残差网络非常容易训练,并且能够获得非常好的精度,特别是当把层增加了之后,在ImageNet数据集上使用了152层(在当时GoogleNet也很快出来了,不过不是用了152层深,而是用了很多并行的层)。152层的深度是非常厉害的。
比VGG的网络深了8倍,但是有更低的复杂度(这个是非常有趣的,网络深度是8倍,但是计算复杂度却更低)。用了这些残差网络做了一个ensemble之后得到了3.57的测试精度,这个结果让他们赢下了ImageNet 2015的竞赛。
在CIFAR-10上演示了怎么训练10到1000层的网络。
任何一个得到冠军亚军的文章都应该也会被大家关注,特别是提出了一个框架和一个方法的文章。
CIFAR-10在计算机视觉上是一个很常见也非常小的数据集,训练1000层的网络是非常夸张的,在这之前可能没有见过1000层的网络长什么样子。
1.2第二段
对于很多视觉的任务来说,深度是很重要的。我仅仅是把我的网络换成了之前学习到的残差网络,在COCO目标检测数据集上得到了28%的相对改进。通过ILSVRC&COCO 2015的竞赛上拿下了第一名。
主要的工作就是把CNN的主干网络替换成了作者所提出来的残差网络,在一系列的任务上都取得了比较好的结果还赢下了竞赛第一名。 如果大家做物体检测的话,COCO应该是这一领域最大的数据集了。
按照正常情况,接下来我们应该去看一下结论,比较有意思这篇文章竟然没有结论。
这篇文章是发表在CVPR上的,CVPR要求正文不能超过8页,这篇文章需要放上的结果比较多,包括ImageNet和COCO,导致结果没有空间去放结论部分。
2 重要公式、表格、图片
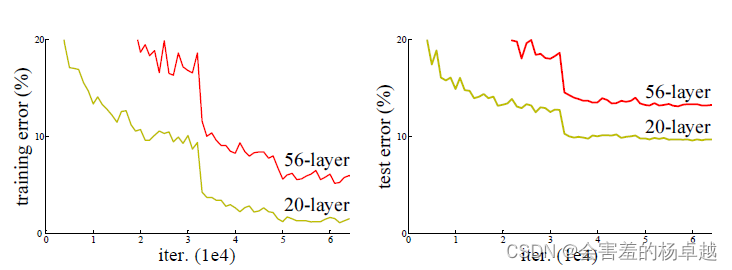
左图是训练误差,右图是测试误差,在CIFA-10上,用了20层和56层的plain networks。结果表明,56层的网络误差反而更高,训练误差更高、测试误差也更高。在训练更深的网络上,其实不仅仅是过拟合,而且是训练不动的。
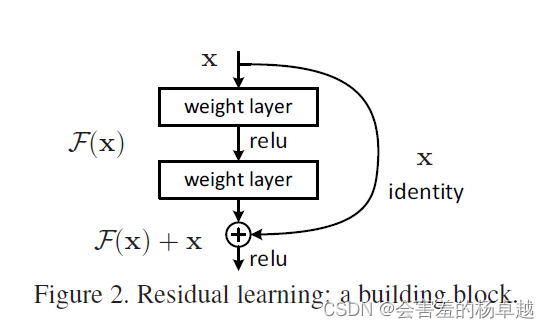
这张图主要讲整个架构的实现,原始输入经过一层可学习权重的层,再经过一层 relu,再经过一层可学习权重的层,再与之前的原始数据加在一起的结果经过relu。就是这样的一个结构,构成了网络的主体。
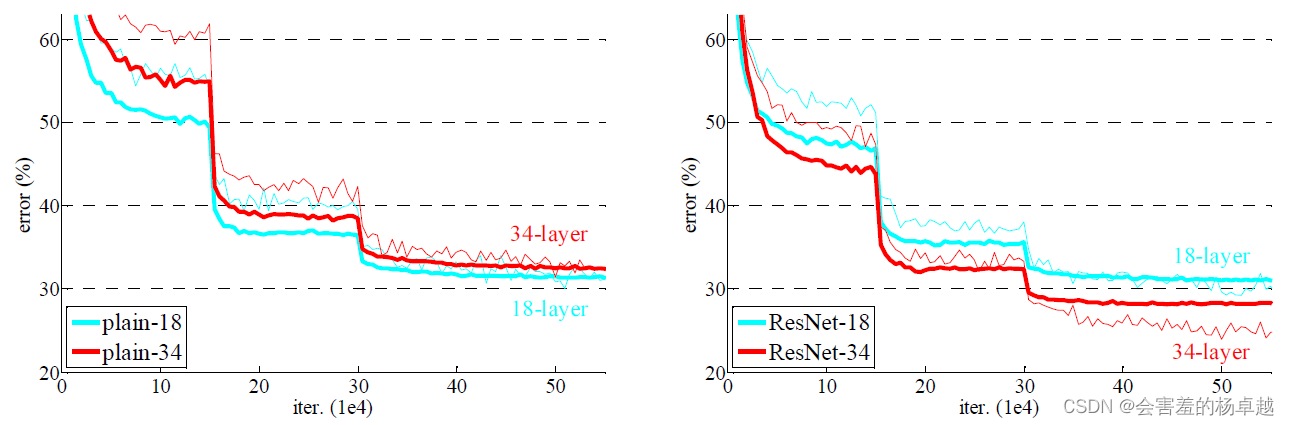
这是在ImageNet数据集上,左图是没有加残差的时候用的是18层和34层的结果,右图是加了残差之后的结果。
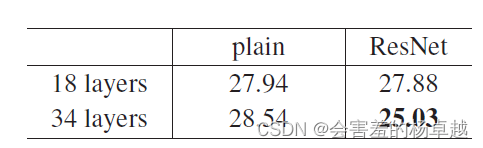
34层的28.54%的错误率在加上残差后可以降低到25.3%
这是赢下15年比赛的最后结果
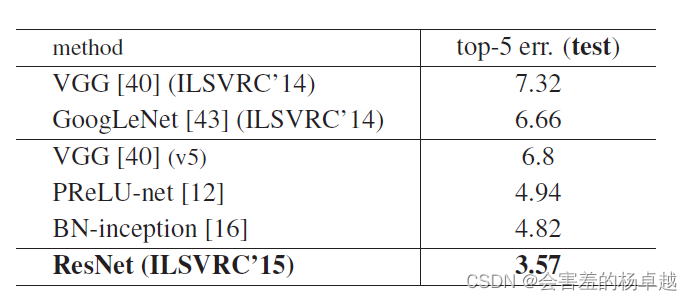
这张图是赢下15年比赛的最后结果
(到这里是第一遍的阅读)




![[保研/考研机试] KY11 二叉树遍历 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/7caeb35fef9748e088f020f524d4b9f4.png)