题库链接:https://leetcode.cn/problem-list/e8X3pBZi/
| 类型 | 题目 | 解决方案 |
|---|---|---|
| 双指针 | 剑指 Offer II 021. 删除链表的倒数第 N 个结点 | 双指针 + 哨兵 ⭐ |
| 剑指 Offer II 022. 链表中环的入口节点(环形链表) | 双指针:二次相遇 ⭐ | |
| 剑指 Offer II 023. 两个链表的第1个重合节点(相交链表) | 双指针:链表拼接 ⭐ | |
| 反转链表 | 剑指 Offer II 024. 反转链表 | 迭代:模拟双向链表 ⭐ |
| 剑指 Offer II 025. 链表中的数字相加(2022.01.07 字节二面) | 模拟:辅助栈(ArrayDeque)⭐ | |
| 剑指 Offer II 026. 重排链表(2021.09.13 美团一面) | 找中点 + 反转链表 + 合并链表 ⭐ | |
| 剑指 Offer II 027. 回文链表 | 双指针 + 线性表 ⭐ | |
| 双向和循环链表 | 剑指 Offer II 028. 扁平化多级双向链表 | 深搜:递归 ⭐ |
| 剑指 Offer II 029. 排序的循环链表 | 模拟:一次遍历(分类讨论)⭐ |
本章题目包含知识点有:哨兵节点、双指针、反转链表、双向链表、循环链表
- 哨兵节点:如果一个操作可能产生新的头节点,则可以尝试在链表的最前面添加一个哨兵节点来简化代码逻辑,降低代码出现问题的可能性;
- 双指针: 前后双指针的思路是让一个指针提前走若干步,然后将第2个指针指向头节点,两个指针以相同的速度一起走;快慢双指针则是让快的指针每次走两步,而慢的指针每次只走一步;
- 反向链表:用于需要从后往前遍历链表的情况;
- 双向链表:要注意每个指针都指向了正确的位置;
- 循环链表:循环链表中的所有节点都在一个环中,因此要特别注意死循环问题,当遍历完链表中的所有节点就要及时停止,避免在环中绕圈子。
1. 剑指 Offer II 021. 删除链表的倒数第 N 个结点 – P50
给定一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
1.1 双指针 + 哨兵 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode sentinel = new ListNode(0,head); // 避免单独处理头节点
ListNode fast = head;
ListNode slow = sentinel;
while (n -- > 0) { // fast 指针先走 n 步
fast = fast.next;
}
while (fast != null) { // 然后 fast 与 slow 一起走
fast = fast.next;
slow = slow.next;
}
slow.next = slow.next.next;
return sentinel.next;
}
}

2. 剑指 Offer II 022. 链表中环的入口节点(环形链表) – P52
给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环,则返回 null。
可参考图解:LCR 022. 环形链表 II - 力扣(LeetCode)
2.1 双指针 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (true) {
if (fast == null || fast.next == null) return null;
fast = fast.next.next;
slow = slow.next;
if (fast == slow) break; // 第一次相遇
}
fast = head;
while (fast != slow) { // 第二次相遇,即找到了入口节点
fast = fast.next;
slow = slow.next;
}
return fast;
}
}

2.2 哈希表 – O(n)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode pos = head;
Set<ListNode> visited = new HashSet<>();
while (pos != null) {
if (visited.contains(pos)) return pos;
visited.add(pos);
pos = pos.next;
}
return null;
}
}
3. 剑指 Offer II 023. 两个链表的第1个重合节点(相交链表) – P55
给定两个单链表的头节点 headA 和 headB ,请找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
3.1 双指针:链表拼接 – O(m+n)(⭐)
时间复杂度 O ( m + n ) O(m+n) O(m+n),空间复杂度 O ( 1 ) O(1) O(1)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
ListNode pA = headA;
ListNode pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next; // A 走完了接到 B
pB = pB == null ? headA : pB.next; // B 走完了接到 A
}
return pA;
}
}
4. 剑指 Offer II 024. 反转链表 – P59
给定单链表的头节点 head ,请反转链表,并返回反转后的链表的头节点。
4.1 迭代:模拟双向链表 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode prev = null; // 记录当前节点的前一节点
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next; // 记录当前节点的后一节点
curr.next = prev; // 反转指向:让当前节点的后一节点指向前一节点
prev = curr;
curr = next;
}
return prev;
}
}
4.2 递归:head.next.next = head – O(n)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode curr = reverseList(head.next);
head.next.next = head; // 反向:当前节点的下下指向是它本身
head.next = null; // 切断原来的指向
return curr;
}
}
5. 剑指 Offer II 025. 链表中的数字相加 – P60
给定两个 非空链表 l1和 l2 来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
5.1 模拟:辅助栈(ArrayDeque)-- O(max(m,n))(⭐)
时间复杂度 O ( m a x ( m , n ) ) O(max(m,n)) O(max(m,n)),空间复杂度 O ( m + n ) O(m+n) O(m+n)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
Deque<Integer> q1 = new ArrayDeque<>(); // ArrayDeque实现栈的功能
Deque<Integer> q2 = new ArrayDeque<>();
while (l1 != null) { // 将链表1存入栈q1中
q1.addFirst(l1.val);
l1 = l1.next;
}
while (l2 != null) { // 将链表2存入栈q2中
q2.addFirst(l2.val);
l2 = l2.next;
}
int carry = 0;
ListNode res = null;
while (!q1.isEmpty() || !q2.isEmpty() || carry != 0) {
int a = q1.isEmpty() ? 0 : q1.poll(); // 后进先出
int b = q2.isEmpty() ? 0 : q2.poll();
int cur = a + b + carry;
carry = cur / 10; // 计算进位
cur = cur % 10;
ListNode node = new ListNode(cur, res); // 构造新链表
res = node;
}
return res;
}
}
5.2 模拟:反转链表再相加 – O(max(m,n))
时间复杂度 O ( m a x ( m , n ) ) O(max(m,n)) O(max(m,n)),空间复杂度 O ( 1 ) O(1) O(1)
手写的一般是要比使用库函数来得快一些,但是使用库函数书写会更简洁,各有利弊。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode h1 = reverseLinked(l1);
ListNode h2 = reverseLinked(l2);
ListNode res = addTwoLinked(h1, h2);
return res;
}
public ListNode addTwoLinked(ListNode h1, ListNode h2) { // 链表按位相加
int carry = 0;
ListNode res = null;
while (h1 != null || h2 != null || carry != 0) {
int a = h1 == null ? 0 : h1.val;
int b = h2 == null ? 0 : h2.val;
int cur = a + b + carry;
carry = cur / 10;
cur = cur % 10;
res = new ListNode(cur, res);
h1 = h1 == null ? null : h1.next; // 防止空指针异常
h2 = h2 == null ? null : h2.next;
}
return res;
}
public ListNode reverseLinked(ListNode head) { // 反转链表
if (head == null || head.next == null) return head;
ListNode cur = reverseLinked(head.next);
head.next.next = head;
head.next = null;
return cur;
}
}
PS:补充知识1 - 【ArrayDeque】
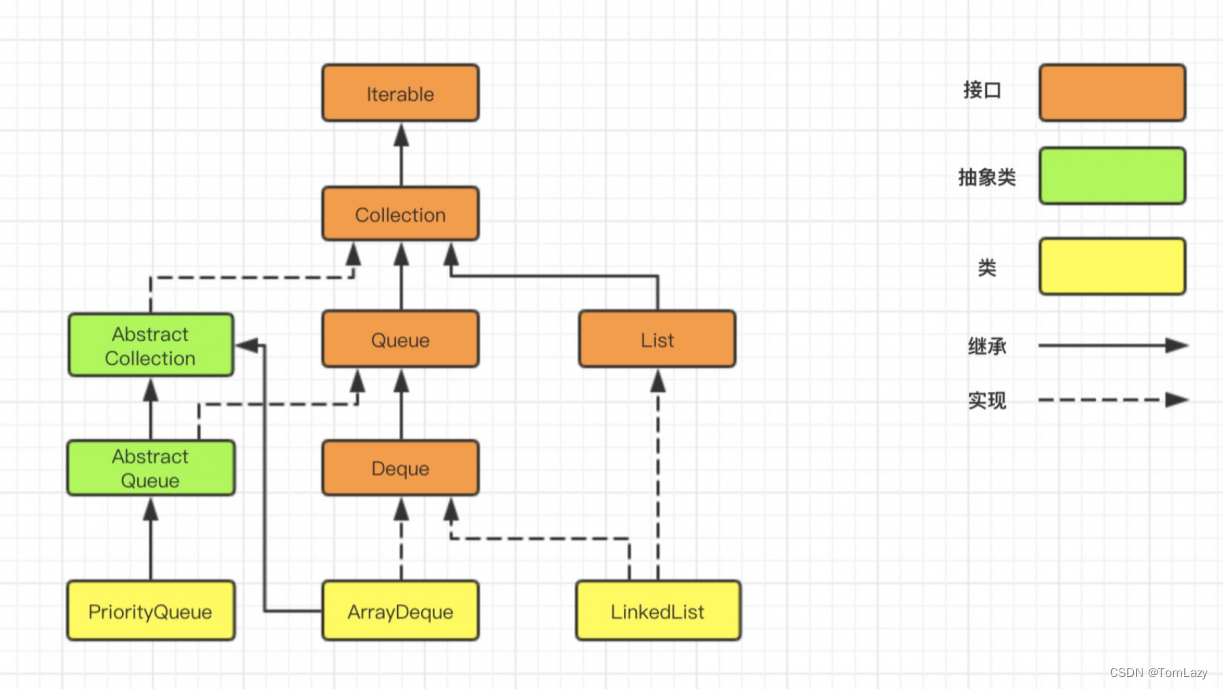
ArrayDeque 类继承 AbstractCollection 抽象类,并且实现了 Deque 接口
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
具体可参考:
[1] 一文详解 ArrayDeque 双端队列使用及实现原理 - 知乎
[2] 你真的了解环形队列吗?- yuyulovespicy的博客
[3] 集合框架之ArrayDeque类详解 - 妙乌的博客
① ArrayDeque的基本方法
具体内容可参考:Leetcode 工具箱 - MarcyTheLibrarian的博客

ArrayDeque 是 Java 中对双端队列的线性实现(数组)
……
特性:
- 来自JDK1.6,底层采用可变容量的环形数组实现一个双端队列,有序存放;
- 无容量大小限制,容量按需增长,默认大小为16;可指定大小,最小为8;容量不足时会进行扩容,每次扩容容量增加一倍;
- 非线程安全队列,无同步策略,不支持多线程安全访问;
- 当用作栈时,性能优于Stack,当用于队列时,性能优于LinkedList;
- 两端都可以操作,且同时支持栈和队列操作;
- 具有fail-fast特性,不能存储null值,支持双向迭代器遍历;
- 出队入队是通过头尾指针循环,利用数组实现的;没有实现list接口,不能通过索引操作元素。
……
方法列表:
类型 方法 说明 添加元素 public void addFirst(E e) 在数组前面添加元素 public void addLast(E e) 在数组后面添加元素 public boolean offerFirst(E e) 在数组前面添加元素,并返回是否添加成功 public boolean offerLast() 在数组后面添加元素,并返回是否添加成功 删除元素 public E pollFirst() 删除第一个元素,并返回删除元素的值,如果元素为null,将返回null public E pollLast() 删除最后一个元素,并返回删除元素的值,如果为null,将返回null public E removeFirst() 删除第一个元素,并返回删除元素的值,如果元素为null,将抛出异常 public E removeLast() 删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常 public boolean removeFirstOccurrence(Object o) 删除第一次出现的指定元素 public boolean removeLastOccurrence(Object o) 删除最后一次出现的指定元素 获取元素 public E getFirst() 获取第一个元素,如果没有将抛出异常 public E getLast() 获取最后一个元素,如果没有将抛出异常 队列操作 public boolean add(E e) 在队列尾部添加一个元素 public boolean offer(E e) 在队列尾部添加一个元素,并返回是否成功 public E remove() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将抛出异常(其实底层调用的是removeFirst() public E peek() 获取第一个元素,没有返回null 栈操作 public void push(E e) 栈顶添加一个元素 public E pop() 移除栈顶元素,如果栈顶没有元素将抛出异常 其他 public int size() 获取队列中元素个数 public boolean isEmpty() 判断队列是否为空 public Iterator iterator() 迭代器,从前向后迭代 public Iterator descendingIterator() 迭代器,从后向前迭代 public boolean contains(Object o) 判断队列中是否存在该元素 public Object[] toArray() 转成数组 public T[] toArray(T[] a) 转成a数组 public void clear() 清空队列 public ArrayDeque clone() 克隆(复制)
当作队列使用时:先进先出
Deque<E> queue = new ArrayDeque<>();
queue.size()
queue.addLast(E e)
queue.removeFirst()
当作栈使用时:后进先出
Deque<E> stack = new ArrayDeque<>();
stack.size()
stack.addLast(E e)
stack.removeLast()
② ArrayDeque的成员变量

// 用数组存放队列元素,长度为2的幂,默认长度为16
transient Object[] elements;
// 头指针,为当前头部的index
transient int head;
// 尾指针,下一个要添加到尾步的index (除tail=0时,当前的尾部为tail-1)
transient int tail;
// 用于新创建的双端队列的最小容量,必须是 2 的幂
private static final int MIN_INITIAL_CAPACITY = 8;
🎈 补充:transient 关键字一般在实现了 Serializable 接口的类中使用,被 transient 修饰的变量不参与序列化和反序列化。
……
更多内容可参考:
[1] Java中的关键字transient,这篇文章你再也不发愁了
[2] Java 关键字 transient 竟然还能这么用 - 知乎
💡 总结:ArrayDeque 中的数组本质上是一个环形数组,其通过数组+双指针的方式,实现双端队列,最小容量为8且必须为2的幂次方。
③ ArrayDeque的迭代器接口
在Java编程中,迭代器接口是一种用于遍历集合类对象的工具。ArrayDeque 通过 iterator() 和 descendingIterator() 方法实现了双向迭代器遍历。
🎈 注意:Iterator 迭代器遍历一般都是单向的,只能从前往后遍历,不支持逆向遍历。descendingIterator() 方法是 Deque 接口中定义的方法,仅适用于双端队列,可用于在双端队列的尾部向头部进行逆向迭代。而一般要想在 List 类型的集合中实现逆向迭代则需要使用 ListIterator 接口。
迭代器接口方法
迭代器接口包含以下几个核心方法:
- hasNext():判断集合中是否还有下一个元素;
- next():返回集合中的下一个元素;
- remove():从集合中移除上一次返回的元素(可选操作).
ArrayDeque的迭代器遍历
正向迭代器(iterator()):从前往后遍历
import java.util.ArrayDeque;
import java.util.Iterator;
public class ArrayDequeIteratorExample {
public static void main(String[] args) {
// 创建一个ArrayDeque并添加元素
ArrayDeque<String> arrayDeque = new ArrayDeque<>();
arrayDeque.add("A");
arrayDeque.add("B");
arrayDeque.add("C");
// 获取迭代器并遍历元素
Iterator<String> iterator = arrayDeque.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
}
}
逆向迭代器(descendingIterator()):从后往前遍历
import java.util.ArrayDeque;
import java.util.Iterator;
public class ArrayDequeDescendingIteratorExample {
public static void main(String[] args) {
// 创建一个ArrayDeque并添加元素
ArrayDeque<String> arrayDeque = new ArrayDeque<>();
arrayDeque.add("A");
arrayDeque.add("B");
arrayDeque.add("C");
// 获取逆向迭代器并逆向遍历元素
Iterator<String> descendingIterator = arrayDeque.descendingIterator();
while (descendingIterator.hasNext()) {
String element = descendingIterator.next();
System.out.println(element);
}
}
}
④ ListIterator接口与descendingIterator()方法的区别
💡 总结:
……
- ListIterator是一个专门用于列表(List)类型集合的迭代器接口,它是Iterator 接口的子接口,提供了更多的功能和灵活性。ListIterator 除了支持正向迭代(从前往后),还通过 hasPrevious()、previous() 等方法实现了逆向迭代(从后往前);此外,ListIterator 还支持在迭代过程中插入、替换和删除元素。
- descendingIterator() 方法是 Deque 接口中定义的方法,用于获取逆向迭代器。Deque 是双端队列的接口,包括 ArrayDeque 在内。
……
简言之:ListIterator 是 Iterator 的子接口,适用于对列表进行正向和逆向迭代,同时支持元素的插入、替换和删除操作;而 descendingIterator() 是独属于双端队列(Deque 以及 ArrayDeque)的方法,用于在双端队列中以逆向的方式访问元素。
ListIterator 实现迭代
正向迭代:与 Iterator 基本一致
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ListIteratorExample {
public static void main(String[] args) {
// 创建一个列表并添加元素
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 获取ListIterator并正向遍历元素
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasNext()) {
String element = listIterator.next();
System.out.println(element);
}
}
}
逆向迭代:使用 hasPrevious()方法判断是否存在前一个元素,然后通过 previous() 方法从当前位置向前移一个位置
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ListIteratorExample {
public static void main(String[] args) {
// 创建一个列表并添加元素
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 获取ListIterator并逆向遍历元素
ListIterator<String> listIterator = list.listIterator(list.size()); // 从最后一个元素开始
while (listIterator.hasPrevious()) {
String element = listIterator.previous();
System.out.println(element);
}
}
}
⑤ Iterator与ListIterator的区别
🚩 迭代器相关内容可参考:
[1] Java 核心面试题全解析 - 油腻的程序猿啊的博客中的 31 ~ 34 问
💡 总结:
- Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。
- Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。
- ListIterator 从 Iterator 接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
⑥ toArray()与toArray(T[] a)的区别
🚩 更多内容可参考:
[1] 深入理解ArrayList中 toArray(),toArray(T[])方法 - XRYMIBZ的博客
[2] Collection中 Object[] toArray()和 T[] toArray(T[])方法 - DimplesDimples.的博客
toArray()方法
public Object[] toArray() {
return Arrays.copyOf(this.elementData, this.size);
}
toArray(T[] a)方法
public <T> T[] toArray(T[] var1) {
if(var1.length < this.size) {
return (Object[])Arrays.copyOf(this.elementData, this.size, var1.getClass());
} else {
System.arraycopy(this.elementData, 0, var1, 0, this.size);
if(var1.length > this.size) {
var1[this.size] = null;
}
return var1;
}
}
💡 总结:
- toArray() 方法,底层实质上是调用了 Arrays.copyof() 方法,将ArrayList类型的对象转换为数组(copyof()方法生成的新数组);
- toArray(T[] a) 方法,其内部实现,则是先将 ArrayList 列表的长度和我们提供的数组 a 的长度进行比较:
- 如果是 ArrayList 列表长度更长,那么就调用 Arrays.copyOf() 方法,和 toArray() 方法一样,生成新的数组,然后依次将元素复制过去;
- 如果是 a 数组的长度更长,那么将直接使用 a 数组进行元素复制的操作,并将 ArrayList 对象长度的末尾置为null(
a[this.size] = null;).
PS:补充知识2 - 【集合的遍历方式 4 & 7】
Java中遍历集合的方式总共有7种,但一般最常用的仅有4种;常用遍历方法将以 ⭐ 号标记。
🚩 具体内容可参考:
[1] Java - 集合遍历的7种方式详解(for、foreach、iterator、并行流等)
[2] Java遍历集合的三种方法 - RainbowCoder的博客
[3] 3种遍历集合的方法(原理,复杂度,适用场合)- 出处不详,经久不息的博客
① 基本的 for 循环 ⭐【性能要求不高的情况】
最简单,最基础的遍历方式。但该方式需要知道集合的长度,不适合所有集合。
List<String> list = Arrays.asList("hangge", "google", "baidu");
for (int i = 0; i < list.size(); i++){
System.out.println(list.get(i));
}
② 使用迭代器遍历 ⭐【在遍历集合的同时对其进行修改】
(1)大多数的集合类(例如 java.util.List、java.util.Set 和 java.util.Map)都提供了 iterator() 方法来返回一个 java.util.Iterator 对象,用于遍历集合中的元素。下面是一个简单的样例:
🎈 注意:虽然 java.util.Enumeration 也可以用来遍历集合中的元素。不过,java.util.Enumeration 接口在 Java 的新版本中已经被认为是过时的,应该使用 java.util.Iterator 接口代替。
List<String> list = Arrays.asList("hangge", "google", "baidu");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
(2)与下面的 for-each 循环相比,使用 Iterator 的方式更加灵活,因为它允许手动控制迭代过程,例如在迭代过程中修改集合、跳过元素或在多个集合之间进行迭代。比如下面样例在迭代过程中修改集合:
🎈 注意:使用 for-each 循环时不能在循环内修改集合,否则会抛出 java.lang.UnsupportedOperationException 异常。
List<String> list = Arrays.asList("hangge", "google", "baidu");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
if (s.equals("google")) {
iterator.remove(); // 移除元素
}
}
③ 使用 for-each 循环(也称为增强型 for 循环)⭐
(1)for-each 循环遍历使用 Iterator 的方式在语法上略有不同,但基本上是等价的。下面是一个使用样例:
List<String> list = Arrays.asList("hangge", "google", "baidu");
for (String s : list) {
System.out.println(s);
}
(2)for-each 循环本质上是使用了迭代器模式,它将迭代器的实现细节隐藏在了语法层面。当使用 for-each 循环遍历集合时,编译器会将其转换为使用迭代器的方式。比如上面代码会被编译器转换为类似于以下代码,在底层实现上,for-each 循环和使用 Iterator 的方式是等价的:
List<String> list = Arrays.asList("hangge", "google", "baidu");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.println(s);
}
④ 使用 Java 8 的 forEach 方法遍历 ⭐【使用 Lambda 表达式】
(1)从 Java 8 开始,我们可以使用 forEach() 方法来迭代列表的元素,这个方法在 Iterable 接口中定义。下面是一个简单样例:
🎈 注意:虽然 forEach 方法可以很方便地遍历任何实现了 Iterable 接口的集合(它本身就是基于 Iterator 实现的),但是它并不能用来遍历数组。
List<String> list = Arrays.asList("hangge", "google", "baidu");
list.forEach(element -> {
System.out.println(element);
});
(2)该方式还可以配合方法引用来使用,下面代码效果通上面一样:
List<String> list = Arrays.asList("hangge", "google", "baidu");
list.forEach(System.out::println);
⑤ 使用 Stream API 的 forEach 方法遍历
(1)使用 Stream API 可以很方便地对集合进行各种操作,下面是一个简单的样例:
List<String> list = Arrays.asList("hangge", "google", "baidu");
list.stream().forEach(element -> {
System.out.println(element);
});
(2)该方式同样可以配合方法引用来使用,下面代码效果通上面一样:
List<String> list = Arrays.asList("hangge", "google", "baidu");
list.stream().forEach(System.out::println);
(3)Stream API 的 forEach 方法出了可以遍历集合的,还可以用来遍历任何支持流的对象,包括集合、数组、文件、函数生成器等。
String[] array = {"hangge", "google", "baidu"};
Arrays.stream(array).forEach(element -> {
System.out.println(element);
});
⑥ 使用 ListIterator 接口遍历集合【遍历 List 集合的同时进行修改】
(1)ListIterator 是 Iterator 接口的子接口。ListIterator 可以向前或向后遍历列表中的元素,并允许在列表中插入和替换元素。下面是一个简单的样例,可以看到向后遍历和 Iterator 用法是一样的:
List<String> list = Arrays.asList("hangge", "google", "baidu");
ListIterator<String> iterator = list.listIterator();
while (iterator.hasNext()) {
String name = iterator.next();
System.out.println(name);
}
(2)我们还可以使用 ListIterator 向前遍历 List 中的元素:
🎈 注意:要向前遍历的话需要创建了一个从列表末尾开始的 ListIterator。
List<String> list = Arrays.asList("hangge", "google", "baidu");
//创建了一个从列表末尾开始的ListIterator
ListIterator<String> iterator = list.listIterator(list.size());
while (iterator.hasPrevious()) {
String name = iterator.previous();
System.out.println(name);
}
(3)我们还可以使用 ListIterator 来修改、添加或删除集合中的元素,比如下面样例我们将 hangge 修改为 hangge.com,在 baidu 之后添加了一个新元素 apple,并删除了所有其他元素。
//创建一个可变列表类型
List<String> list = new ArrayList<>(Arrays.asList("hangge", "google", "baidu"));
ListIterator<String> iterator = list.listIterator();
while (iterator.hasNext()) {
String name = iterator.next();
if (name.equals("hangge")) {
iterator.set("hangge.com"); // 修改元素
} else if (name.equals("baidu")) {
iterator.add("apple"); // 在 baidu 之后添加元素
} else {
iterator.remove(); // 删除元素
}
}
System.out.println(list);
⑦ 使用并行流遍历【对大型集合进行并行处理】
(1)并行流使用多个线程来并行处理集合中的元素,可以提高处理速度。上面的代码使用了并行流来遍历集合 list 中的元素,并将它们打印出来。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 创建一个并行流(将parallel标志指定为true表示创建并行流)
Stream<Integer> parallelStream = list.parallelStream();
// 查看流是否支持并行遍历
System.out.println("流是否支持并行遍历: " + parallelStream.isParallel());
// 使用 forEach() 方法遍历并行流
parallelStream.forEach(element -> {
System.out.println(element);
});
PS:补充知识3 - 【集合类图】
🚩 更多内容可参考:
[1] Java Collection Cheat Sheet
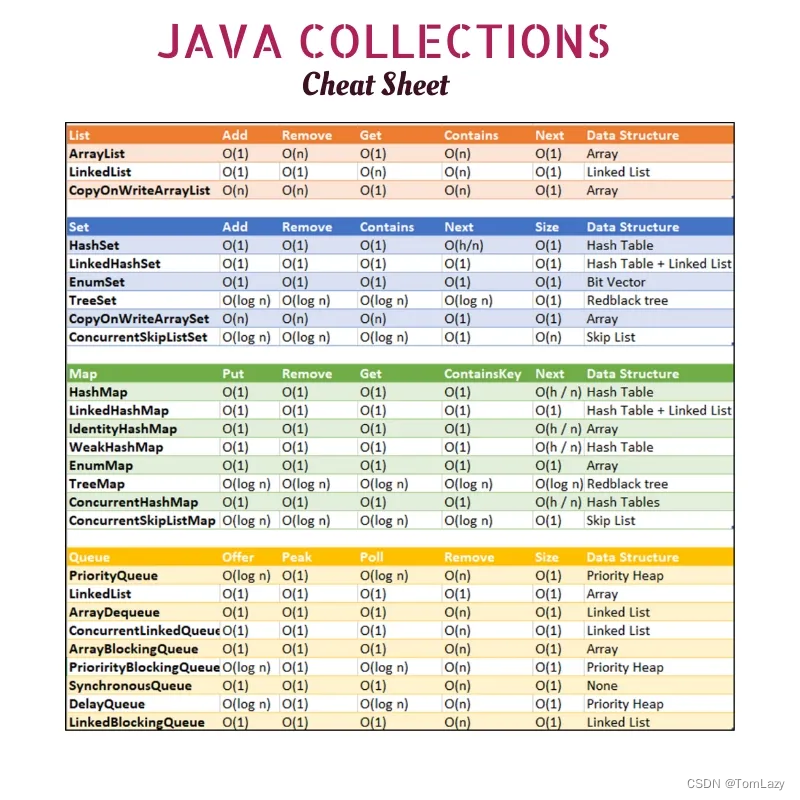
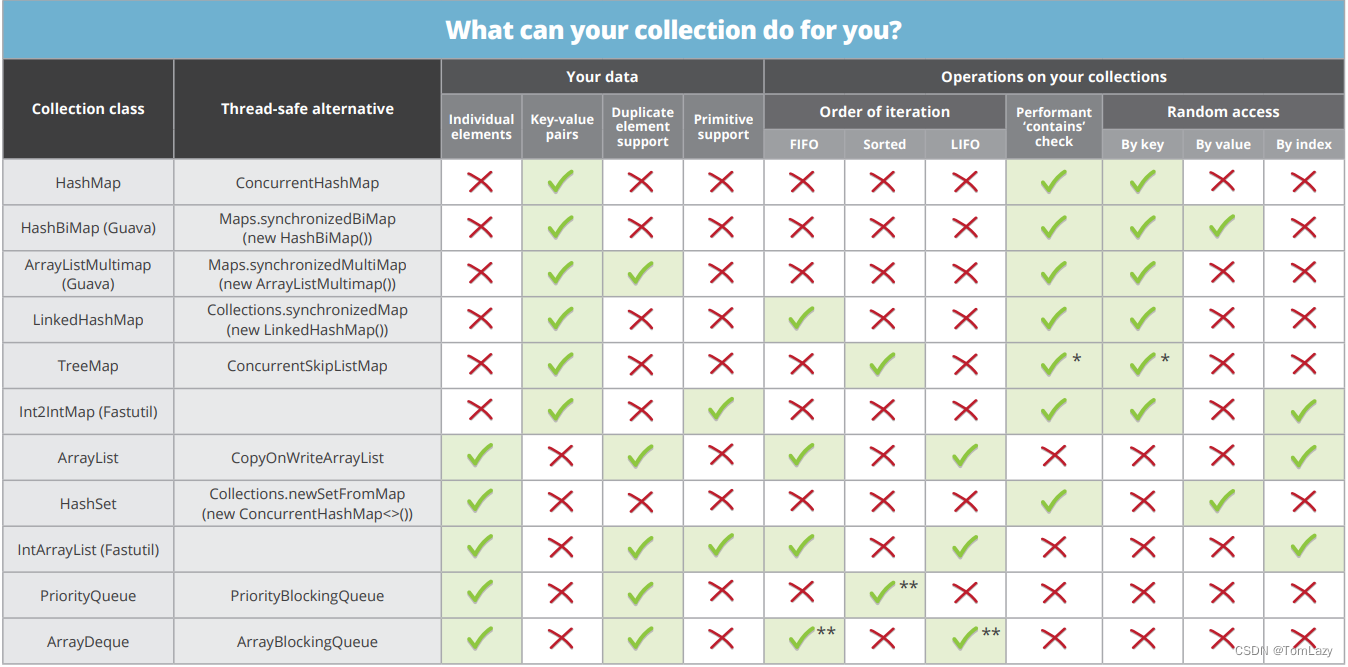
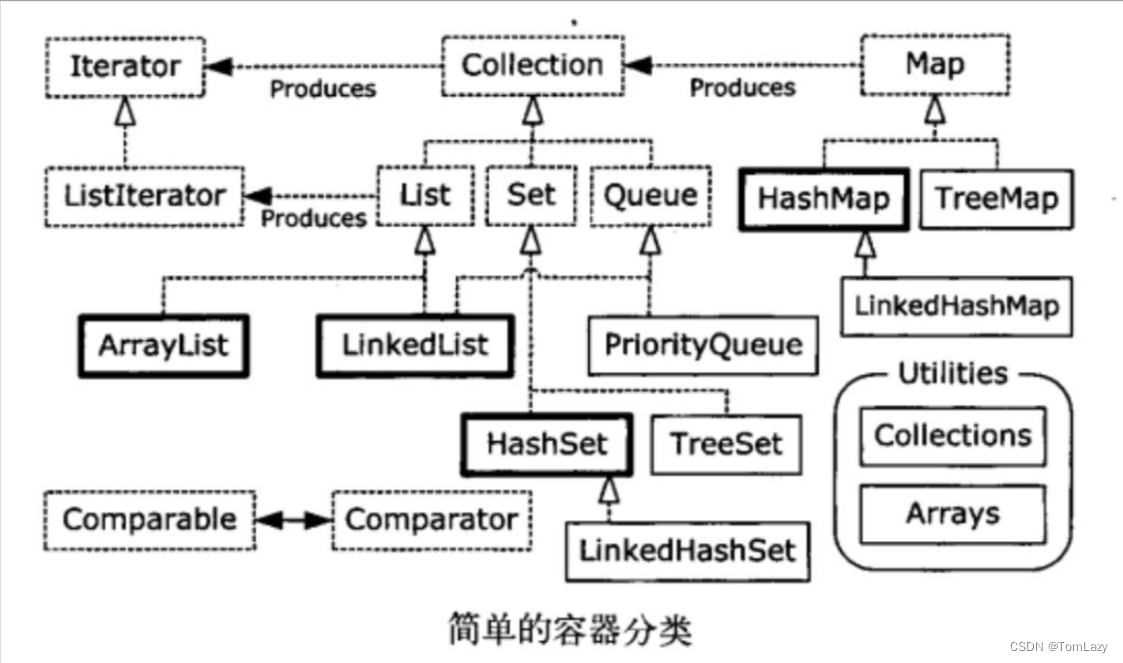

PS:补充知识4 - 【fail-fast 和 fail-safe】
🚩 更多内容可参考:
[1] 谈谈fail-fast与fail-safe是什么以及工作机制 - 知乎 (讲的比较透彻)
[2] fail-fast 和 fail-safe 快速学习 - 杨戬的博客(有代码调试示例)
[3] Java 中的 Fail-Fast 与 Fail-Safe - 码农汉子的博客
① fail-fast与fail-safe的区别
💡 总结:
- fail-fast,即快速失败机制,它是 Java 对 java.util 包下的所有集合类的是一种错误检测机制,当多个(或单个)线程在结构上对集合进行改变时(插入和删除,修改不算),就有可能会产生fail-fast机制,从而抛出 ConcurrentModificationException 异常(通常发生在迭代器元素遍历中);
- 实现原理:迭代器每当执行一次 next() / hasNext() 等方法时,都会调用一次 checkForComodification() 这个方法,查看modCount 与 expectedModCount是否保持一致,如果不一致,则说明集合元素的个数发生了改变,从而抛出异常;
- 处理方案:如果我们不希望在迭代器遍历的时候因为并发等原因,导致集合的结构被改变,进而可能抛出异常的话,我们可以在涉及到会影响到 modCount 值改变的地方,加上同步锁 (synchronized),或者直接使用 Collections.synchronizedList 来解决。
- fail-safe,安全失败机制,它是 Java 对 java.util.concurrent 包下的所有集合类的是一种错误检测机制,其在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历(不会抛出异常)。
- 实现原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
- 缺点:1. 复制集合时需要额外的空间和时间上的开销;2. 不能保证遍历的是最新内容(迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的)。
② java.util 与 java.util.concurrent 下的集合
🚩 更多内容可参考:
[1] Java集合框架总述(java.util包) | 羊驼之野望(java.util包中集合的简单介绍)
[2] Java并发——JUC包下的并发集合类 - 社会你鑫哥的博客(JUC集合相关介绍)
[3] 理清Java集合类(Util包和Concurrent包) - 灰信网(介绍的比较清晰)
[4] 集合类存放于java.util包下,主要的接口说明 - Zsiyuan的博客(图解)
[5] Java.util.concurrent包下集合类的特点与适用场景 - 梦幻朵颜 - 博客园(表格形式总结)
- java.util 包下的集合【fail-fast】
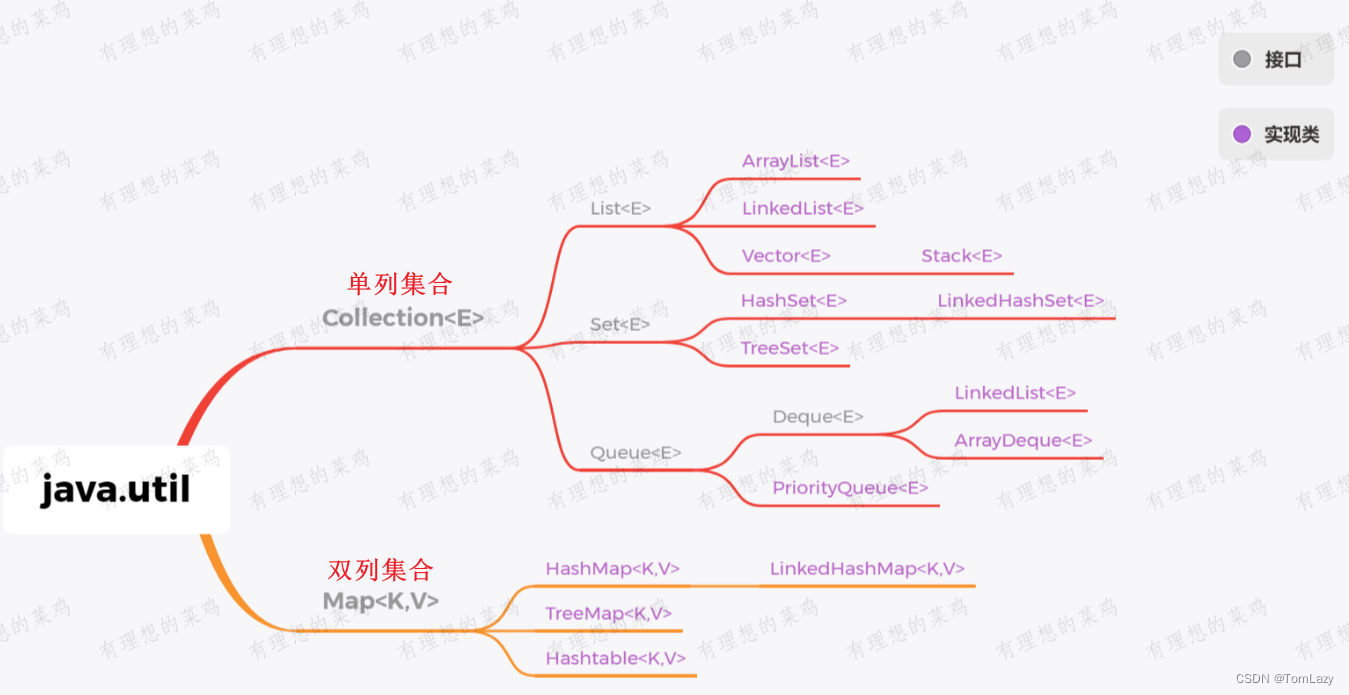
- java.util.concurrent(JUC)包下的集合

JUC 包中 Map 实现类
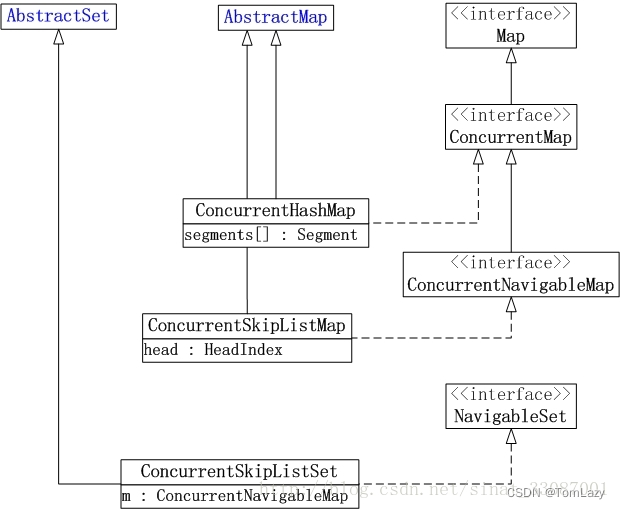
PS:补充知识5 - 【对象持久化】
Java的对象持久化是指将内存中的Java对象保存到持久存储介质(如磁盘、数据库等)中,以便在程序重新启动或数据传输时能够恢复这些对象的状态。
……
对象持久化是在应用程序中保留数据的重要方法之一,它允许数据在不同的执行环境中保持一致性,从而实现数据的长期存储和共享。
🚩 更多内容可参考:
[1] Java持久化详解(简单介绍)
[2] Java对象持久化保存的方法(表格形式)
[3] Java中的ORM框架有哪些,Hibernate使用讲解 - 计算机徐师兄的博客(Hibernate)
① 常见的对象持久化方法
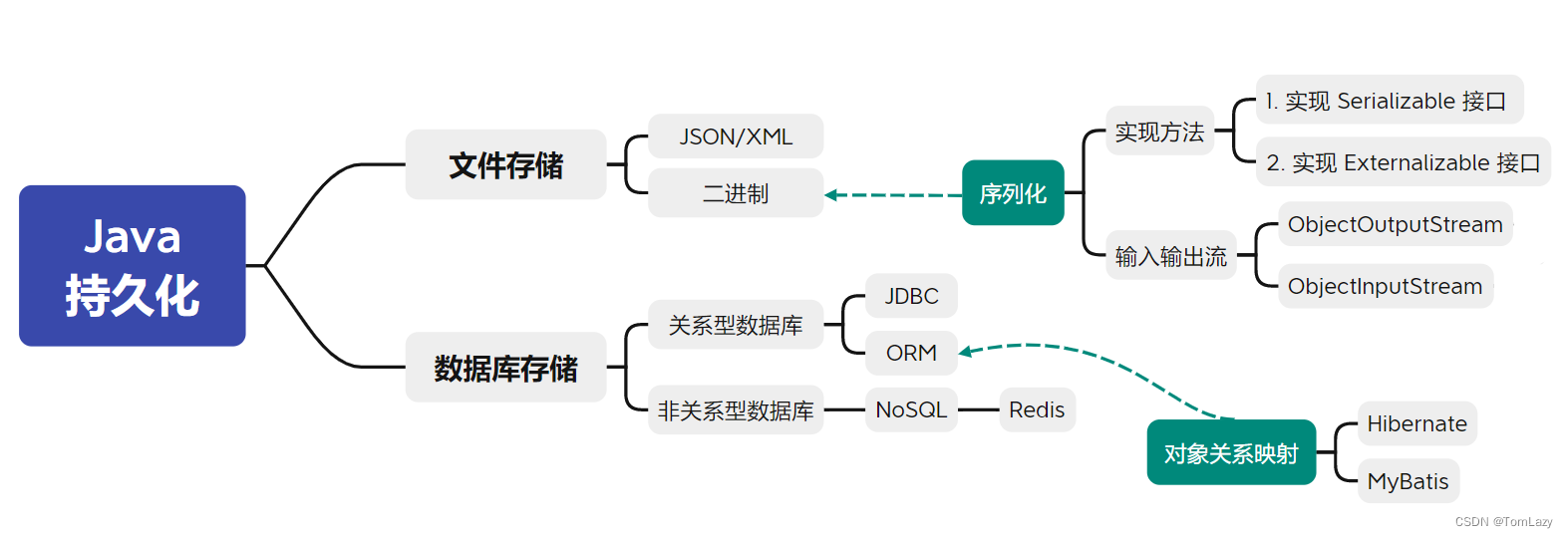
💡 总结:在Java中,实现对象持久化的方法有多种,但根据存储方式的不同大致可以分为两类:文件存储 和 数据库存储。
- 文件存储:文件存储是最简单和最常见的持久化方式之一。通过将数据以文件的形式存储在磁盘上,可以实现数据的持久保存和读取。Java提供了多种文件操作API,如FileInputStream和FileOutputStream,可用于读写文件。由此,我们就可以通过 序列化\反序列化 或者 XML或JSON 来将对象存入文件。
……
- 序列化 (Serialization):Java提供了一个Serializable接口,让类可以将其对象序列化为字节流,然后在需要时反序列化回对象。
// 序列化对象 try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("object.dat"))) { outputStream.writeObject(myObject); } // 反序列化对象 try (ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("object.dat"))) { MyObject restoredObject = (MyObject) inputStream.readObject(); }……
- XML或JSON格式:
// 使用Jackson库将对象保存为JSON ObjectMapper objectMapper = new ObjectMapper(); objectMapper.writeValue(new File("object.json"), myObject); // 从JSON中还原对象 MyObject restoredObject = objectMapper.readValue(new File("object.json"), MyObject.class);……
2. 数据库存储:通过将数据存储在关系型数据库或非关系型数据库中,可以实现数据的持久保存、查询和更新。
- 传统的JDBC或ORM框架是关系型数据库的标准访问和映射工具,非关系型数据库(NoSQL数据库)通常采用不同的数据模型和访问方法。
- NoSQL数据库可以用于缓存存储(Redis),但不限于缓存存储;NoSQL数据库通常更适合用于长期数据存储和分析(MongoDB)。非关系型数据库可用于:文档型(Web应用)、key-value型(内容缓存)、列式数据库(分布式文件系统)、图形数据库(社交网络、推荐系统)。
② 关系型数据库和非关系型的区别
🚩 更多内容可参考:
[1] 关系型数据库和非关系型数据及其区别 - 乌梅子酱~的博客
[2] 关系型数据库和非关系型区别 - 一只IT攻城狮的博客
💡 总结:
- 数据存储方式不同:关系型数据天然就是表格式的,因此存储在数据表的行和列中,结构化存储;非关系型数据通常存储在数据集中,就像文档、键值对、列存储、图结构。
- 扩展方式不同:关系型数据库难以横向拓展,为支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力;而NoSQL数据库是横向扩展的,非关系型数据存储天然就是分布式的,可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
- 对事务性的支持不同:SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务;而NoSQL数据库是最终一致性,一般不保证ACID的数据存储系统,但其具有极高的并发读写性能,真正闪亮的价值是在操作的扩展性和大数据量处理方面。
6. 剑指 Offer II 026. 重排链表 – P63
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln-1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
6.1 双指针 + 线性表(List)-- O(n)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public void reorderList(ListNode head) {
if (head == null || head.next == null) return;
List<ListNode> list = new ArrayList<>();
while (head != null) { // 将链表存入线性表
list.add(head);
head = head.next;
}
int l = 0, r = list.size()-1;
while (l < r) {
list.get(l).next = list.get(r);
l++;
//if (l == r) break; // 偶数提前跳出,加不加都可
list.get(r).next = list.get(l);
r--;
}
list.get(l).next = null;
}
}

6.2 找中点 + 反转链表 + 合并链表 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
// 2. 找中点,反转中点后链表,重排链表
public void reorderList(ListNode head) {
if (head == null) {
return;
}
ListNode mid = findMid(head); // 找中点
ListNode l1 = head;
ListNode l2 = mid.next;
mid.next = null;
l2 = reverseList(l2);
mergeList(l1, l2);
}
// 合并重排链表
public void mergeList(ListNode l1, ListNode l2) {
ListNode l1_tmp;
ListNode l2_tmp;
while (l1 != null && l2 != null) {
l1_tmp = l1.next;
l2_tmp = l2.next;
l1.next = l2;
l1 = l1_tmp;
l2.next = l1;
l2 = l2_tmp;
}
}
// 反转链表
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode cur = reverseList(head.next);
head.next.next = head;
head.next = null;
return cur;
}
// 找出链表中点
public ListNode findMid(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
}
PS:补充知识1 - 【线性表 List】
💡 说明:线性表(List)划分为顺序表(ArrayList)和链表(LinkList),需要强调的是,在数据结构中,线性表被设计成一个接口,顺序表和链表都继承实现了该接口内的方法
……
更多内容可参考:
[1] JAVA版数据结构-----线性表 - 一入猿门深似海的博客
7. 剑指 Offer II 027. 回文链表 – P65
给定一个链表的 头节点 head ,请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
7.1 辅助栈(ArrayDeque)-- O(n)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null) return false;
Deque<ListNode> stack = new ArrayDeque<>();
ListNode cur = head;
while(cur != null) { // 将链表元素入栈
stack.push(cur);
cur = cur.next;
}
while(head != null){ // 依次比较
if(head.val != stack.pop().val){
return false;
}
head = head.next;
}
return true;
}
}
7.2 双指针 + 线性表 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null) return false;
List<Integer> vals = new ArrayList<>();
while (head != null) { // 将链表元素的值存入线性表
vals.add(head.val);
head = head.next;
}
int l = 0, r = vals.size()-1;
while (l < r) { // 双指针折半判断是否回文
if (vals.get(l) != vals.get(r)) return false;
l++;
r--;
}
return true;
}
}

7.3 找中点 + 反转链表 + 判断回文 – O(n)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
该方法属于该题的最优解,但实际效果不佳,因此在实际情况下更推荐 7.2 双指针 + 线性表 的解题方法。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null) return false;
ListNode mid = findMid(head);
ListNode l1 = head;
ListNode l2 = reverseList(mid.next);
mid.next = null;
while (l1 != null && l2 != null) { // 折半判断回文
if (l1.val != l2.val) return false;
l1 = l1.next;
l2 = l2.next;
}
return true;
}
public ListNode findMid(ListNode head) { // 找中点
ListNode fast = head;
ListNode slow = head;
while (fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
public ListNode reverseList(ListNode head) { // 反转链表
if (head == null || head.next == null) return head;
ListNode cur = reverseList(head.next);
head.next.next = head;
head.next = null;
return cur;
}
}
8. 剑指 Offer II 028. 扁平化多级双向链表 – P67
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构。
给定位于列表第一级的头节点,请扁平化列表,即将这样的多级双向链表展平成普通的双向链表,使所有结点出现在单级双链表中。

💡 提示:展平的规则是一个节点的子链展平之后将插入该节点和它的下一个节点之间。
8.1 深搜:递归 – O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
dfs(head);
return head;
}
public Node dfs(Node head) { // 找到每一级的尾节点,并完成平展
Node cur = head;
Node tail = null;
while (cur != null) {
Node next = cur.next;
if (cur.child != null) {
Node child = cur.child;
Node childTail = dfs(child); // 找到了平展的尾节点
cur.child = null; // 平展该级子列表
cur.next = child;
child.prev = cur;
childTail.next = next;
if (next != null) {
next.prev = childTail;
}
tail = childTail; // 不能忘记
} else {
tail = cur;
}
cur = next;
}
return tail;
}
}
9. 剑指 Offer II 029. 排序的循环链表 – P69
给定循环单调非递减列表中的一个点,写一个函数向这个列表中插入一个新元素 insertVal ,使这个列表仍然是循环升序的。
9.1 模拟:一次遍历(分类讨论)-- O(n)(⭐)
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1)
/*
// Definition for a Node.
class Node {
public int val;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _next) {
val = _val;
next = _next;
}
};
*/
class Solution {
public Node insert(Node head, int insertVal) {
Node node = new Node(insertVal);
if (head == null) { // 1. 空链表
node.next = node;
return node;
}
if (head.next == head) { // 2. 链表中只有一个节点
head.next = node;
node.next = head;
return head;
}
Node curr = head, next = head.next; // 3. 多节点
while (next != head) {
if (insertVal >= curr.val && insertVal <= next.val) { // 3.1 插入值在链表范围内
break;
}
if (curr.val > next.val) { // 此时curr是最大元素
if (insertVal > curr.val || insertVal < next.val) { // 3.2 插入值不在链表范围内
break;
}
}
curr = curr.next;
next = next.next;
}
curr.next = node;
node.next = next;
return head;
}
}
10. 继续提升:加练题目
🎈 可参考:
- 链表 · SharingSource/LogicStack-LeetCode Wiki · GitHub
- DFS · SharingSource/LogicStack-LeetCode Wiki · GitHub