导语
哈喽大家好!我是木子吖~
上一期给大家已经介绍了爬虫的一些功能步骤等等,这一期想着还是给大家更新一些爬虫的案
例吧!这里有我给大家准备的精心准备的爬虫案例代码,当然如果基础有点儿差的小伙伴儿也
不用担心哈,附带了详细的 视频讲解的,可以直接跟着视频慢慢敲代码听思路也可以的啦!
你的贴心木已上线,爱了爱了!
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

——小Tips
很多案例都是不能过啦。所以只能竟可能的不描述的太详细。(不能出现一些详细的爬虫的地
址、案例名字等等)
又到了毕业生找工作的季节了,秋风起兮雨萧瑟,校招不知几人回啊。就算找到了工作被前辈
骂成狗也是家常便饭。正值“毕业”求职季,大三大四实习期,年关也快到了,大家都找到心仪
的工作了吗?面对海量信息,哪些招聘网站可以放心使用?找工作的小伙伴快来跟着小编一起
看看吧!招聘网站三部曲,你想要的招聘网站都在这这儿啦~
(如果没有你心仪的,你说 我下次接着努力趴一趴)

正文
找工作太难?职场套路太深?来来来,今天木子来教你怎么找工作了哈。
一、基础讲解
模块安装统一讲解:
win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内
镜像源)
相对应的安装包/安装教程/激活码/使用教程/学习资料/工具插件可以来找我拿免费分享的哈模块安装问题:
- 如果安装python第三方模块:
1. win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
2. 在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:https://pypi.hustunique.com/
山东理工大学:https://pypi.sdutlinux.org/
豆瓣:https://pypi.douban.com/simple/
例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好
或者你pycharm里面python解释器没有设置好如何配置pycharm里面的python解释器?
1. 选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
2. 点击齿轮, 选择add
3. 添加python安装路径pycharm如何安装插件?
1. 选择file(文件) >>> setting(设置) >>> Plugins(插件)
2. 点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
3. 选择相应的插件点击 install(安装) 即可
4. 安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效二、案例实战
1)Python采集招聘网站数据内容——猎聘

(1)前期准备
运行环境——
Python3、Pycharm。
第三方库:requests >>> pip install requests 数据请求
selenium >>> pip install selenium==3.141.0 自动化测试 操作浏览器
parsel >>> pip install parsel 数据解析 提取数据
faker >>> pip install faker 随机生成UA
csv 保存数据 保存csv文件
time 时间模块
random 随机模块(2)代码展示
代码实现步骤——
1. 发送请求, 模拟浏览器对 url地址 发送请求
url地址: https://www.liepin.com/job/1948917627.shtml?d_sfrom=search_prime&d_ckId=null&d_curPage=2&d_pageSize=40&d_headId=null&d_posi=1&skId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&fkId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&ckId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&sfrom=search_job_pc&curPage=2&pageSize=40&index=1
2. 获取数据, 获取服务器返回响应数据
开发者工具: response
3. 解析数据, 提取我们想要的数据内容
岗位基本数据信息:
4. 保存数据, 把数据保存本地文件
- 基本数据 保存csv表格里面
- 岗位职责 保存文本里面主程序——
# 导入数据请求模块 --> 第三方模块 需要安装 pip install requests
import requests
# 导入faker --> 第三方模块 需要安装 pip install 导入faker
from faker import Factory
# 导入数据解析模块 --> 第三方模块 需要安装 pip install parsel
import parsel
# 导入csv模块 内置模块 不需要安装
import csv
# 导入自动化测试模块
from selenium import webdriver
# 导入时间模块
import time
# 导入随机模块
import random
"""
selenium: 模拟人的行为去操作浏览器
"""
# 1. 打开浏览器
driver = webdriver.Chrome()
# 2. 访问网站
driver.get(
'https://www.liepin.com/zhaopin/?city=410&dq=410&pubTime=¤tPage=2&pageSize=40&key=python%E7%88%AC%E8%99%AB&suggestTag=&workYearCode=0&compId=&compName=&compTag=&industry=&salary=&jobKind=&compScale=&compKind=&compStage=&eduLevel=&otherCity=&scene=input&suggestId=')
# 隐式等待 ---> 让网页数据加载完成
driver.implicitly_wait(10)
time.sleep(3)
# 创建文件
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位名',
'薪资',
'城市',
'经验',
'学历',
'福利',
'岗位标签',
'公司名',
'详情页',
])
# 写入表头
csv_writer.writeheader()
# 3. 获取岗位详情页url地址
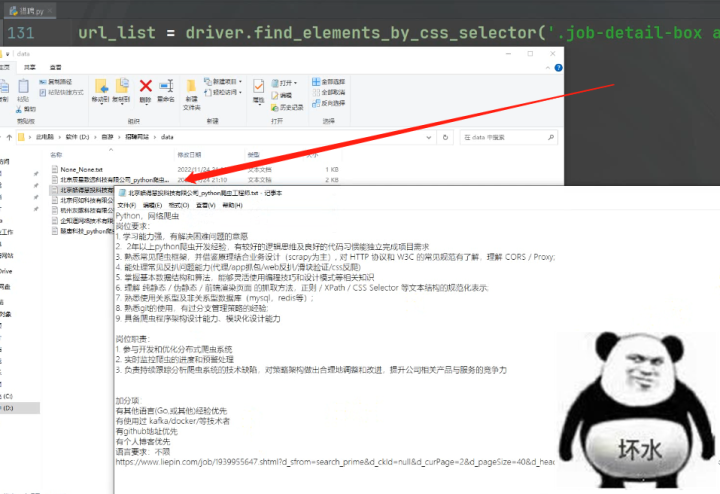
url_list = driver.find_elements_by_css_selector('.job-detail-box a')
for index in url_list:
url = index.get_attribute('href')
print(url)
time.sleep(random.randint(1, 2))
"""
1. 发送请求, 模拟浏览器对 url地址 发送请求
- 把python代码伪装成浏览器发送请求
目的: 为了防止被反爬
"""
# 请求url地址
# url = 'https://www.liepin.com/job/1948917627.shtml?d_sfrom=search_prime&d_ckId=null&d_curPage=2&d_pageSize=40&d_headId=null&d_posi=1&skId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&fkId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&ckId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&sfrom=search_job_pc&curPage=2&pageSize=40&index=1'
# 模拟伪装 ---> 开发者工具里面进行复制粘贴
Fact = Factory.create()
# 随机生成UA
ua = Fact.user_agent()
headers = {
# User-Agent 用户代理 表示浏览器基本身份信息
'User-Agent': ua
}
# 发送请求 -> <Response [200]> 表示请求成功
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具: response
response.text 获取响应文本数据, 返回字符串数据类型 html字符串数据内容
3. 解析数据, 提取我们想要的数据内容
css选择器 根据标签属性提取数据内容:
"""
# 把获取下来 html字符串数据内容 <response.text> 转成可解析对象
selector = parsel.Selector(response.text)
"""
.job-apply-content .name-box .name 定位标签
- get() 获取第一个标签 就获取一个内容 返回字符串
- getall 获取所有标签内容, 返回列表
css选择器, 在系统课程 都是从头到尾讲2.5个小时才能讲完知识点内容
a::text 表示 提取a标签里面文本呀
"""
title = selector.css('.job-apply-content .name-box .name::text').get() # 职位名
salary = selector.css('.job-apply-content .name-box .salary::text').get() # 薪资
city = selector.css('.job-apply-content .job-properties span:nth-child(1)::text').get() # 城市
exp = selector.css('.job-apply-content .job-properties span:nth-child(3)::text').get() # 经验
edu = selector.css('.job-apply-content .job-properties span:nth-child(5)::text').get() # 学历
# 把列表合并成字符串
labels = ','.join(selector.css('.job-apply-container-desc .labels span::text').getall()) # 福利
job_labels = ','.join(selector.css('.tag-box ul li::text').getall()) # 职位标签
company = selector.css('.company-info-container .company-card .content .name::text').get() # 公司名
job_info = '\n'.join(selector.css('.job-intro-container .paragraph dd::text').getall()) # 岗位职业
"""
4. 保存数据, 把数据保存本地文件
- 基本数据 保存csv表格里面
- 岗位职责 保存文本里面
"""
# 把数据写入到字典里面
dit = {
'职位名': title,
'薪资': salary,
'城市': city,
'经验': exp,
'学历': edu,
'福利': labels,
'岗位标签': job_labels,
'公司名': company,
'详情页': url,
}
# 写入数据
csv_writer.writerow(dit)
print(title, salary, city, exp, edu, labels, job_labels, company, job_info)
file = f'data\\{company}_{title}.txt'
with open(file, mode='a', encoding='utf-8') as w:
w.write(job_info)
w.write('\n')
w.write(url)![]() (3)效果展示
(3)效果展示

2)Python采集招聘网站数据内容——前程无忧

(1)前期准备
运行环境——
环境: Python 3 、Pycharm、requests 。 其他内置模块(不需要安装 re json csv),安装
好 python环境就可以了。
(win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安 装速度比较慢, 你可以切
换国内镜像源))
第三方库的安装:
pip install + 模块名 或者 带镜像源 pip install -i https://pypi.douban.com/simple/ +模块名 ![]() (2)代码展示
(2)代码展示
代码实现步骤——
1. 发送请求, 模拟浏览器对于url地址发送请求
2. 获取数据, 获取服务器返回响应数据 开发者工具里面所看到 response 显示内容
3. 解析数据, 提取我们想要的数据内容 招聘岗位基本信息
4. 保存数据, 把数据信息保存表格里面主程序——
# 数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
# 创建文件
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位',
'公司',
'城市',
'经验',
'学历',
'薪资',
'福利',
'公司领域',
'公司规模',
'公司性质',
'发布日期',
'公司详情页',
'职位详情页',
])
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 需要模块
- 模拟浏览器, 是用什么伪装模拟的
请求头
- 批量替换方法:
1. 选择替换内容, ctrl + R
2. 点击 .*
3. 输入正则命令 进行替换
(.*?): (.*)
'$1': '$2',
"""
# 确定请求url地址
url = 'https://search.51job.com/list/010000%252C020000%252C030200%252C040000%252C090200,000000,0000,00,9,99,python,2,1.html?u_atoken=0ebd3b84-8a7e-4598-8442-28333687bb0e&u_asession=01LE1DKlBRig-pCserJvEKtcD8FRdkDmxSC9vHIlu9RgicRu619dwho-tcQMpJEh-ZX0KNBwm7Lovlpxjd_P_q4JsKWYrT3W_NKPr8w6oU7K8losFOpWBCXw72NVjjGbeyUe3R9QHfzEvknA4dzJmVTGBkFo3NEHBv0PZUm6pbxQU&u_asig=0509LTGV1DvXMS_d8cXU0jv3xyAuxRHtUv_3iTMcaock6sXe4lMoRzoeNU0-4WRPy8d9VLjYwSYoqZRfrHRzYjSRtEXt_gJnMbngMyKwkcQvy_U3ZscBbWiqZINhCZ6eYI4iBYZ8_0uvXSgelx2P_AmiQIPqS5RvD76Ykjv1qCZTv9JS7q8ZD7Xtz2Ly-b0kmuyAKRFSVJkkdwVUnyHAIJzQlgrzuxIWQIo0fiMVZCpCacmYM5qL-ed1eR5R0F9DTnH_8T8uYGNepqxdb-gLe1IO3h9VXwMyh6PgyDIVSG1W_B5D3kdbrqcgu5uUHKicA6yeddtsgrM7GqljNTK8OvHqzgiKs0HrpHBlhQgs6dylHgSSI0vZrxvglZJr9CZiMwmWspDxyAEEo4kbsryBKb9Q&u_aref=T%2BGBzeflb1FpnfpkX4KDw6w05pw%3D'
# 伪装模拟 headers 字典数据类型
headers = {
# User-Agent 用户代理 浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
}
# 发送请求
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名response接收返回数据
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具里面所看到 response 显示内容
3. 解析数据, 提取我们想要的数据内容
招聘岗位基本信息
response.text 获取响应文本数据 获取html数据
re 会 1 不会 0
- 调用re模块里面findall方法 找到所有我们想要数据
- re.findall('匹配什么数据<匹配规则>', '什么地方')
- 从什么地方去匹配找寻什么样的数据内容
- 从 response.text 去找寻 window.__SEARCH_RESULT__ = (.*?)</script> 其中 (.*?) 这段是我们要的数据
- 正则表达式提取出来数据返回 ---> 列表数据类型
print(json_data) 打印字典数据, 显示一行
pprint(json_data) 打印字典数据, 显示多行, 展开效果
type() 内置函数, 查看数据类型
"""
html_data = re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', response.text)[0]
# 转一下数据类型 转成字典数据类型
# 通过字典键值对取值, 提取我们想要的内容 根据冒号左边的内容[键], 提取冒号右边的内容[值]
json_data = json.loads(html_data)
# for循环遍历, 把列表里面的元素一个一个提取出来
for index in json_data['engine_jds']:
dit = {
'职位': index['job_name'],
'公司': index['company_name'],
'城市': index['workarea_text'],
'经验': index['attribute_text'][1],
'学历': index['attribute_text'][-1],
'薪资': index['providesalary_text'],
'福利': index['jobwelf'],
'公司领域': index['companyind_text'],
'公司规模': index['companysize_text'],
'公司性质': index['companytype_text'],
'发布日期': index['issuedate'],
'公司详情页': index['company_href'],
'职位详情页': index['job_href'],
}
csv_writer.writerow(dit)
print(dit)![]()
![]() (3)效果展示
(3)效果展示

3)Python采集招聘网站数据内容——拉勾网

(1)前期准备
运行环境——
环境: Python 3 、Pycharm、requests 。 其他内置模块(不需要安装 re json csv),安装
好 python环境就可以了。
(win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安 装速度比较慢, 你可以切
换国内镜像源))
第三方库的安装:
pip install + 模块名 或者 带镜像源 pip install -i https://pypi.douban.com/simple/ +模块名 ![]() (2)代码展示
(2)代码展示
主程序——
"""
# 导入数据请求模块
import requests
# 导入正则
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
# 导入时间模块
import time
# 创建文件
f = open('python多页.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位名',
'公司名',
'城市',
'区域',
'薪资',
'经验',
'学历',
'公司规模',
'公司领域',
'详情页',
])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 需要请求工具 ---> requests
- 老师, 我英语不好, 可以学习编程吗? 可以学习python吗?
单词不需要死记硬背, python常用关键单词词汇 135+左右
python常用单词词汇文本
pycharm 翻译插件 ---> 自己去安装
- 模拟浏览器
爬虫模拟浏览器, 都是用请求头... headers
- 如果你是VIP学员, 远程安装 解答辅导 都是可以
"""
for page in range(1, 11):
try:
# 确定url地址
time.sleep(1)
url = f'https://www.lagou.com/wn/jobs?pn={page}&fromSearch=true&kd=python'
# 模拟浏览器
headers = {
# cookie 用户信息, 常用于检测是否登陆账号
# User-Agent 用户代理, 表示浏览器基本身份标识
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 ---> <Response [200]> 响应对象 200 状态码 表示请求成功
response = requests.get(url=url, headers=headers)
# 2. 获取数据 print(response.text)
"""
3. 解析数据 ---> re正则表达式 会用 1 不会用 0
简单的使用re ----> 详细re教学 在系统课程教授2.5个小时左右...
re.findall('什据么数', 什么地方) re模块findall方法
从 什么地方 去找什么数据
说字典的同学, 说明你自学, 基础学的不怎么扎实...
"""
html_data = re.findall('<script id="__NEXT_DATA__" type="application/json">(.*?)</script', response.text)[0]
# 转成字典数据类型 自定变量命名规则, 蛇形命名 驼峰命名 Sad jsonData
json_data = json.loads(html_data)
# 字典取值---> 键值对取值 根据冒号左边的内容[键], 提取冒号右边的内容[值]
result = json_data['props']['pageProps']['initData']['content']['positionResult']['result']
# for遍历
for index in result:
# 详情页
link = f'https://www.lagou.com/wn/jobs/{index["positionId"]}.html'
dit = {
'职位名': index['positionName'],
'公司名': index['companyFullName'],
'城市': index['city'],
'区域': index['district'],
'薪资': index['salary'],
'经验': index['workYear'],
'学历': index['education'],
'公司规模': index['companySize'],
'公司领域': index['industryField'],
'详情页': link,
}
job_info = index['positionDetail']
job_info = re.sub('<.*?>', '', job_info)
name = index['positionName'] + index['companyFullName']
name = re.sub(r'[/\:"?*<>\n|]', '', name)
with open('data\\' + name + '.txt', mode='a', encoding='utf-8') as f:
f.write(job_info)
f.write('\n')
f.write(link)
# 写入数据
csv_writer.writerow(dit)
print(dit)
except Exception as e:
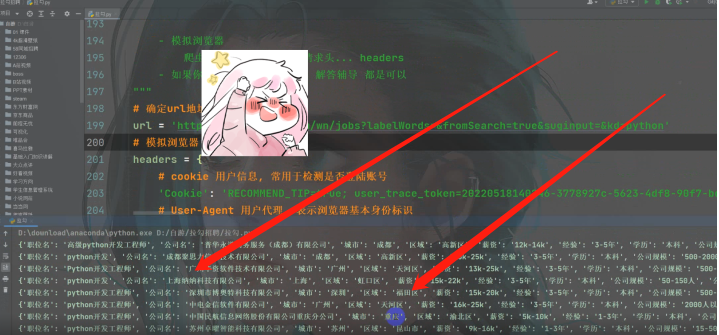
print(e)![]() (3)效果展示
(3)效果展示
总结
现在在网上找工作的人越来越多了,但是招聘网站众多,各个企业鱼龙混杂,所以我们在找工
作的时候要提高警惕,选择一些比较靠谱的招聘网站。那么,今天就先写三个网站爬虫哈,下
一期我们接着再来!大家想我写什么网站的招聘爬虫可以评论区评论哦~
🎯完整的免费源码领取处:找我吖!文末公众hao可自行领取,滴滴我也可!
🔨推荐往期文章——
项目1.0 实战案例:淘宝爬虫、秒杀、疫情数据等
【Python合集系列】爬虫有什么用,网友纷纷给出自己的答案,王老师,我..我想学那个..爬虫。可以嘛?“(淘宝爬虫、秒杀脚本、vip解析视频、疫情可视化等)
项目1.1 WIFI暴力破解代码
Python编程零基础如何逆袭成为爬虫实战高手之《WIFI破解》(甩万能钥匙十条街)爆赞爆赞~
项目1.2 圣诞树代码合集系列
【Turtle合集】提前祝大家圣诞快乐,我为大家献歌一首,叮叮当,叮叮当,穷的响叮当——快开门,我送礼物来了哟~(圣诞树代码)
🎄文章汇总——
汇总合集 Python—2022 |已有文章汇总 | 持续更新,直接看这篇就够了
(更多内容+源码都在✨文章汇总哦!!欢迎阅读喜欢的文章🎉~)












![[附源码]Python计算机毕业设计高校贫困生信息管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/7deff0260c7f4e2d9f9324e5507e050a.png)