摘要:本文整理自 Apache Flink PMC&Committer 伍翀(云邪)在 9 月 24 日 Apache Flink Meetup 的演讲。主要内容包括:
Hive SQL 迁移的动机
Hive SQL 迁移的挑战
Hive SQL 迁移的实践
Hive SQL 迁移的演示
未来规划
Tips:点击「阅读原文」获取 PPT~
01
Hive SQL 迁移的动机

Flink 已经是流计算的事实标准,当前国内外做实时计算或流计算一般都会选择 Flink 和 Flink SQL。另外,Flink 也是是家喻户晓的流批一体大数据计算引擎。
然而,目前 Flink 也面临着挑战。比如虽然现在大规模应用都以流计算为主,但 Flink 批计算的应用并不广泛,想要进一步推动真正意义上的流批一体落地,需要推动业界更多地落地 Flink 批计算,需要更积极地拥抱现有的离线生态。当前业界离线生态主要以 Hive 为主,因此我们在过去版本中做了很多与 Hive 相关的集成,包括 Hive Catalog、Hive 语法兼容、Hive UDF 兼容、流式写入 Hive 等。在 Flink 1.16 版本中,我们进一步提升了 HiveSQL 的兼容度,还支持了 HiveServer2 的协议兼容。
所以,为什么 Flink 要去支持 Hive SQL 的迁移?一方面,我们希望吸引更多的 Hive 离线数仓用户,通过用户来不断打磨批计算引擎,对齐主流批计算引擎。另一方面,通过兼容 Hive SQL,来降低现有离线用户使用 Flink 开发离线业务的门槛。除此之外,另外,生态是开源产品的最大门槛。Flink 已经拥有非常丰富的实时生态工具,但离线生态依然较为欠缺。通过兼容 Hive 生态可以快速融入 Hive 离线生态工具和平台,降低用户接入的成本。最后,这也是实现流批一体的重要一环,我们希望推动业界尝试统一的流计算和批计算引擎,再统一流计算和批计算 SQL。

从用户角度来看,Hive SQL 为什么要迁移到 Flink SQL 上?
对于平台方而言,统一流批计算引擎,只需维护一套 Flink 引擎,可以降低维护成本,提升团队研发效率。另外,可以利用 Flink + Gateway+ HiveSQL 兼容,快速建设一套 OLAP 系统。Flink 的另一优势是拥有丰富的 connector 生态,可以借助 Flink 丰富的数据源实现强大的联邦查询。比如不仅可以在 Hive 数仓里做 ad-hoc 查询,也可以将 Hive 表数据与 MySQL、HBase、Iceberg、Hudi 等数据源做联邦查询等。
对于离线数仓用户而言,可以用 Hive SQL 写流计算作业,极大降低实时化改造成本。使用的依然是以前的 HiveSQL 语法,但是可以运行在 streaming 模式下。在此基础之上也可以进一步探索流批一体 SQL 层以及流批一体数仓层的建设。
02
Hive SQL 迁移的挑战

但是 Flink 支持 HiveSQL 的迁移面临着很多挑战,主要有以下三个方面:
兼容:包括离线数仓作业和Hive平台工具的兼容。主要对应用户层的兼容和平台方的兼容。
稳定性:迁移后的作业首先要保证生产的稳定性。我们在1.16中也做了很多这方面的工作,包括FLIP-168 预测执行和Adaptive Hash Join。后续我们会发表更多的文章来介绍这方面的工作。
性能:最后性能也是很重要的,在1.16中我们也做了很多这方面的工作,包括Dynamic Partition Pruning(DPP)、元数据访问加速等,后续也会发表更多文章来介绍这方面的工作。
接下来我们重点讲解下 Hive 兼容相关的工作。
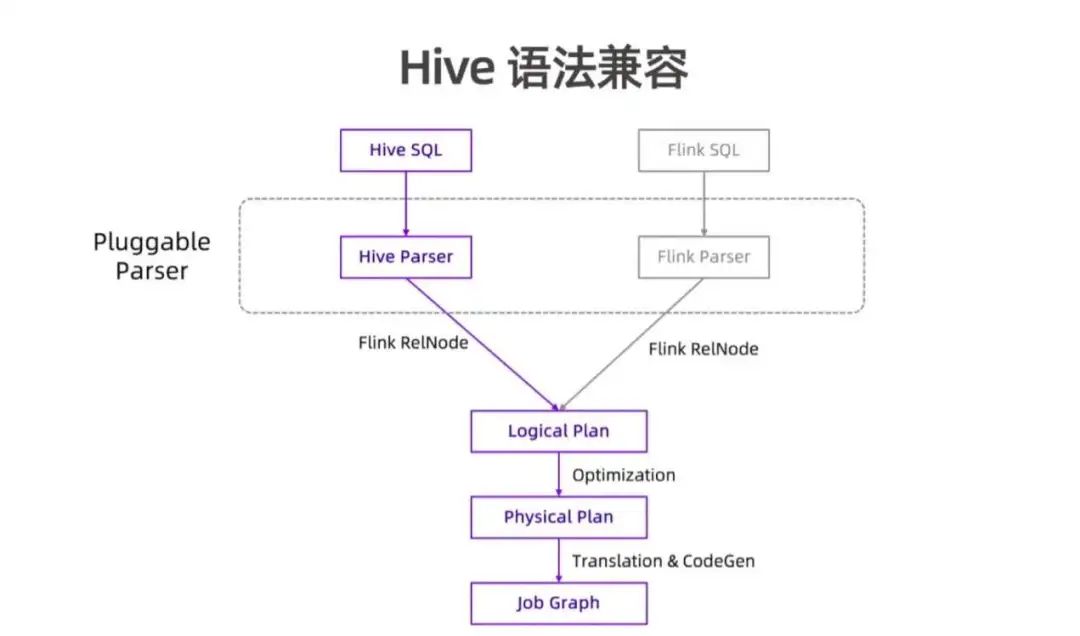
Hive 语法的兼容并没有完全造出一套新的 SQL 引擎,而是复用了 Flink SQL 的很多核心流程和代码。我们抽象出了可插拔的 parser 层来支持和扩展不同的语法。Flink SQL 会经过 Flink Parser 转换成 Flink RelNode,再经过 Logical Plan 优化为 Physical Plan,最后转换为 Job Graph 提交执行。为了支持 Hive 语法兼容,我们引入了 Hive Parser 组件,来将 Hive SQL 转化成 Flink RelNode。这个过程中,复用了大部分 Hive 现有的 SQL 解析逻辑,保证语法层的兼容(均基于 Calcite)。之后 RelNode 复用同样的流程和代码转化成 LogicalPlan、Physical Plan、JobGraph,最后提交执行。

从架构上看,Hive 语法兼容并不复杂,但这是一个“魔鬼在细节”的工作。上图为部分 Flink1.16 版本里 Flink Hive 兼容相关的 issue,涉及 query 兼容、类型系统、语义、行为、DDL、DML、辅助查询命令等非常多语法功能。累计完成的 issue 数达近百个。
Flink1.16 版本将 Hive 兼容度从 85% 提升至 94.1%。兼容度测试主要依靠 Hive qtest 测试集,其中包含 12,000 多个测试 case,覆盖了 Hive 目前所有主流语法功能。没有兼容的一部分包括 ACID 功能(业界使用较少),如果除去 ACID 功能,兼容度已达 97%以上。
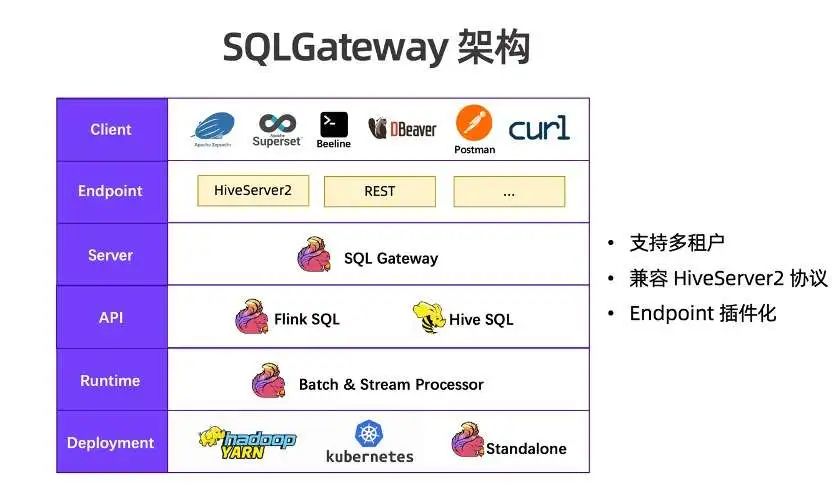
SQLGateway 是 Flink SQL 的 server 层组件,是单独的进程,对标 HiveServer2 组件。从 Flink 整体架构上看,SQLGateway 处于中间位置。
向下,封装了用户 API 的 Flink SQL 和 Hive SQL。不管是 Flink SQL 还是 Hive SQL,都使用 Flink 流批一体的 Runtime 来执行,可以运行在批模式,也可以运行在流模式。Flink 的资源也可以部署运行在 YARN、K8S、Flink standalone 集群上。
向上,SQLGateway 提供了可插拔协议层 Endpoint,目前提供了 HiveServer2 和 REST 两种协议实现。通过 HiveServer2 Endpoint,用户可以将 Hive 生态的很多工具和组件(Zeppelin、Superset、Beeline、DBeaver 等)连接到 SQL Gateway,提供流批统一的 SQL 服务并兼容 Hive SQL。通过 REST 协议可以使用 Postman、curl 命令或自己通过 Python、Java 编程来访问,提供完善和灵活的流计算服务。将来,Endpoint 能力也会继续扩展,比如可以提供更高性能的 gRPC 协议或兼容 PG 协议。
03
Hive SQL 迁移的实践
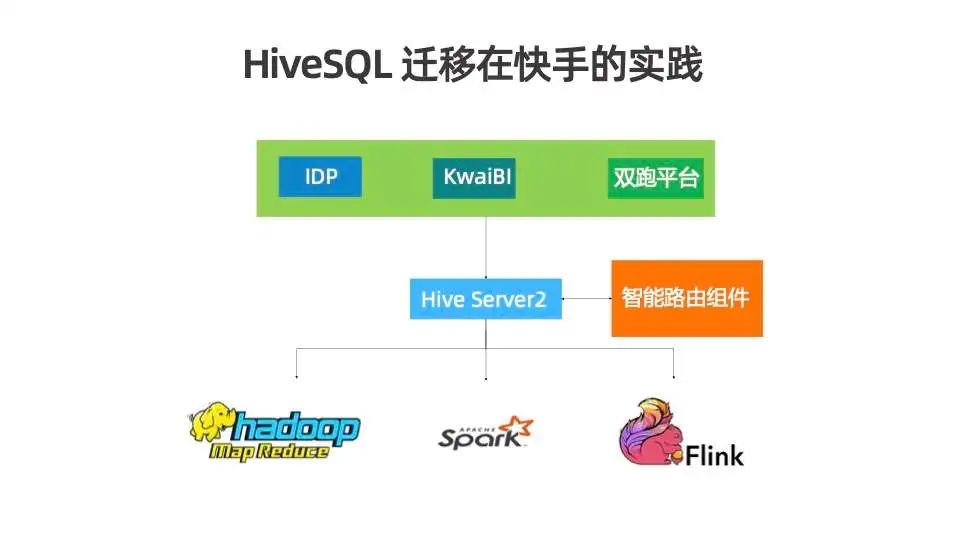
目前快手正在与 Flink 社区紧密合作,推进流批一体的落地。目前快手迁移 Hive SQL 作业到 Flink SQL 作业已经取得了初步的进展,已有上千个作业完成了迁移。快手的迁移主要策略为双跑平台,已有业务继续运行,双跑平台有智能路由组件,可以通过指定规则或 pattern 识别出作业,投递到 MapReduce、Spark 或 Flink 上运行。初期的运行较为谨慎,会通过白名单机制指定某些作业先运行在 Flink,观察其稳定性与性能,对比其结果一致性,后续逐步通过规则来放量。更多的实践经验与细节可以关注 Flink Forward Asia 2022 上分享的《Hive SQL 迁移到 Flink SQL 在快手的实践》。
04
Hive SQL 迁移的演示
Demo1:Hive SQL 如何迁移到 Flink SQL
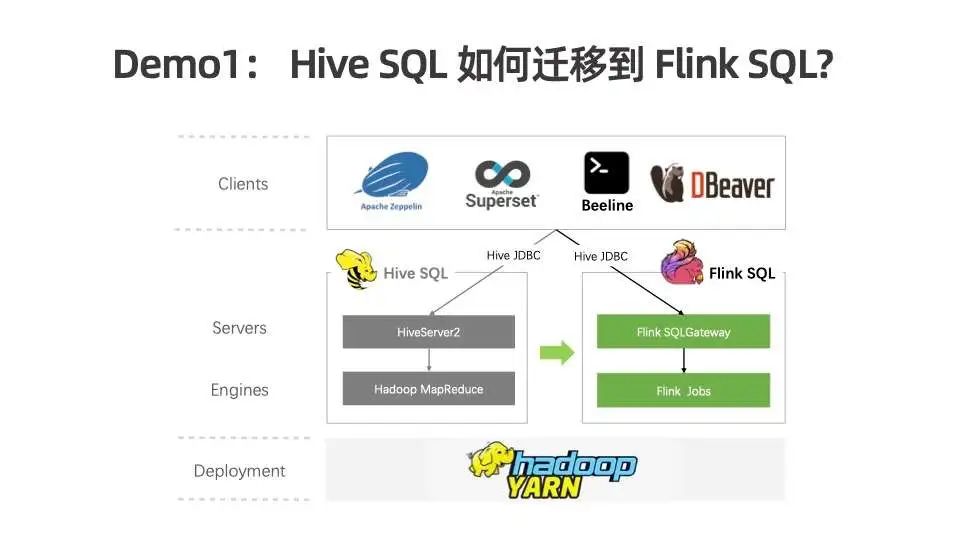
接下来演示一下 Hive SQL 如何迁移到 Flink SQL。我们已经搭建好一个 YARN 集群,以及 Hive 相关组件,包括 HiveServer2 的服务。我们使用 Zeppelin 做数据可视化和 SQL 查询。我们将演示 Hive SQL 迁移到 Flink SQL 只需改一行地址,Zeppelin 体验并无二致,SQL 也无需修改。完整的 Demo 视频请观看完整的演讲视频:https://www.bilibili.com/video/BV1BV4y1T7d4
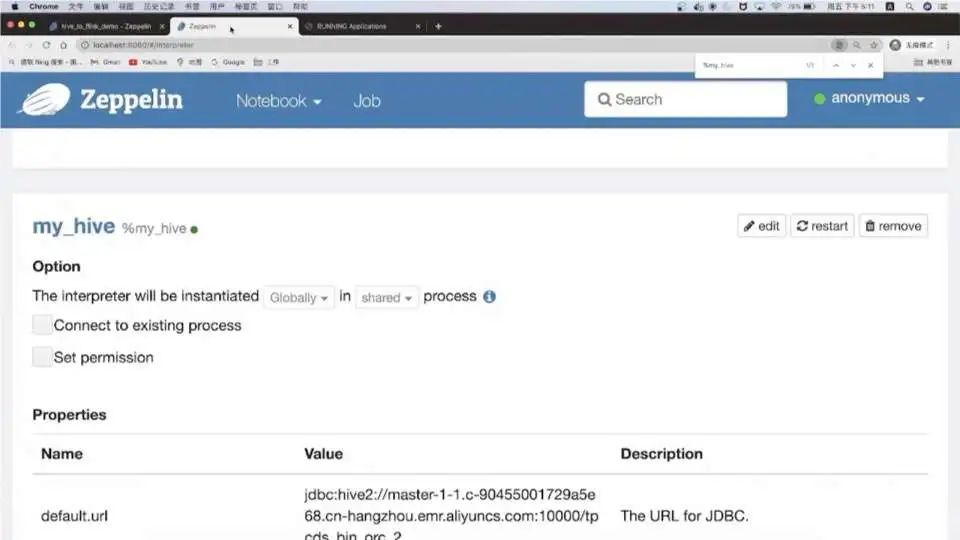
首先在 Zeppelin 中配置 Hive Interpreter,填入 HiveServer2 的 JDBC 地址和端口、用户名密码、Driver 等信息。
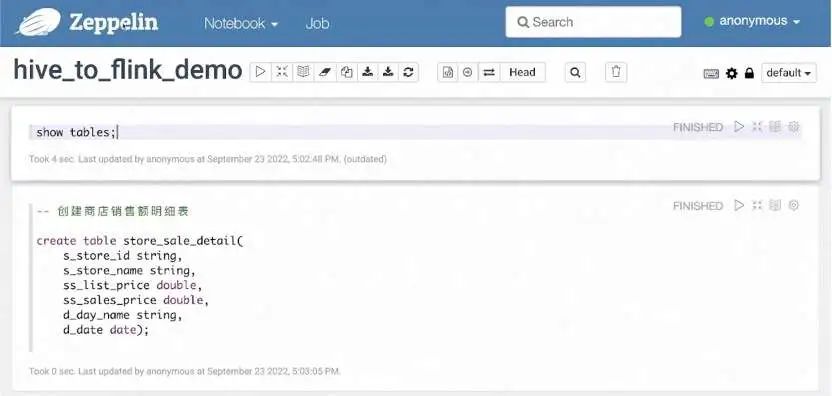
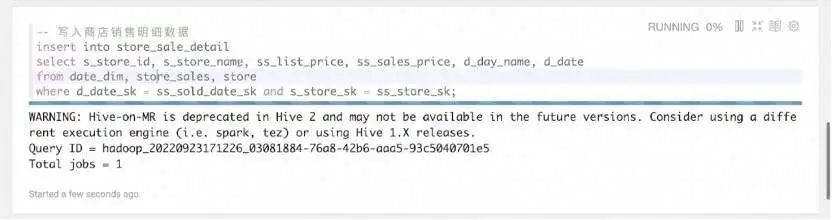
使用当前的 Hive Interpreter,我们可以通过 Hive DDL 命令创建一张打宽的 store_sale_detail 表。使用 Hive SQL 语法关联 store_sales、date_dim、store 三张表,打成一张宽表写到 store_sale_detail。执行该 INSERT INTO 语句后,便能在 Hadoop 平台上看到运行起来的 MapReduce 任务。
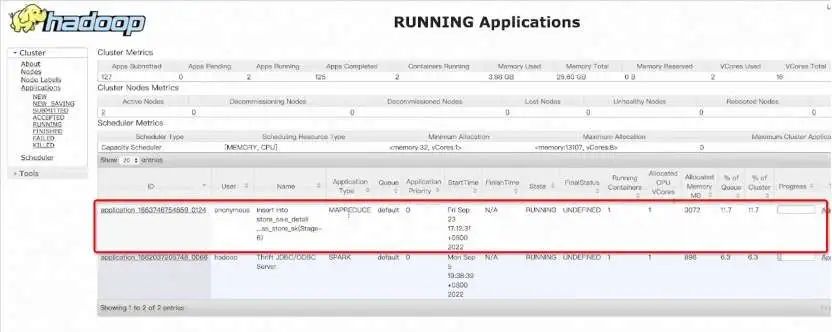
store_sale_detail 明细宽表生产完后,我们就可以进行查询分析,比如查看星期天每个店铺的销量。运行完后可通过饼图等多种形式展示结果。
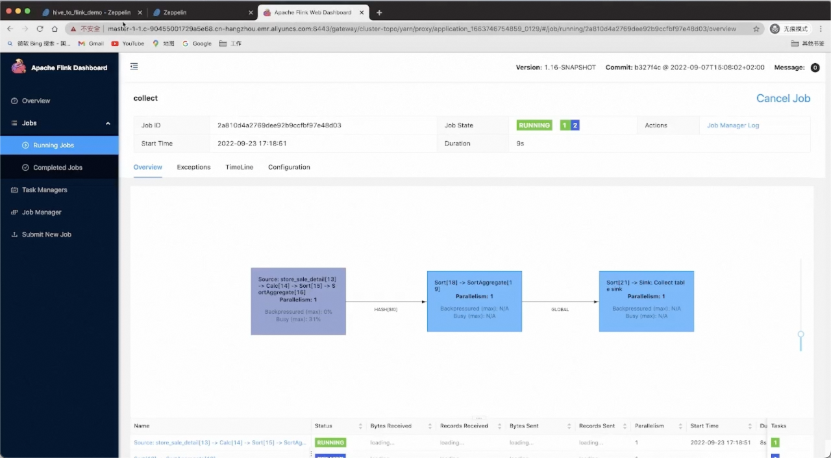
上面简单演示了使用 Hive 进行数据生产和数据分析,其中计算引擎使用的是 Hive 原生的 Hadoop MapReduce 作业,作业运行在 YARN 集群上。接下来我们开始迁移到 Flink SQL,作业仍然运行在 YARN 集群上。
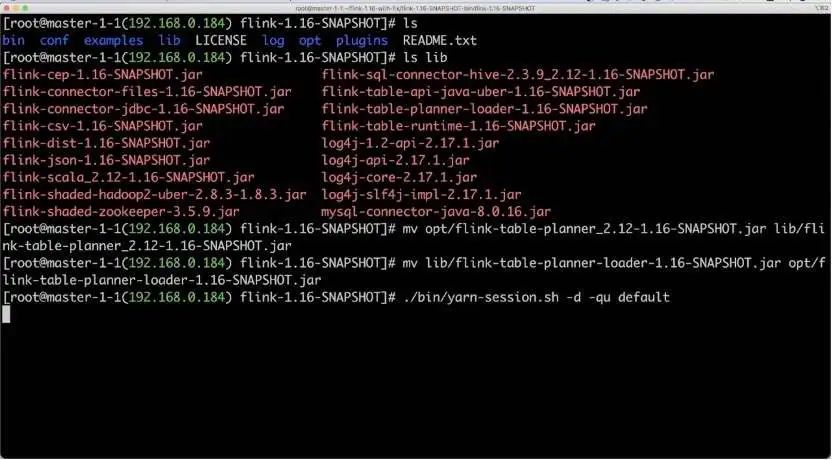
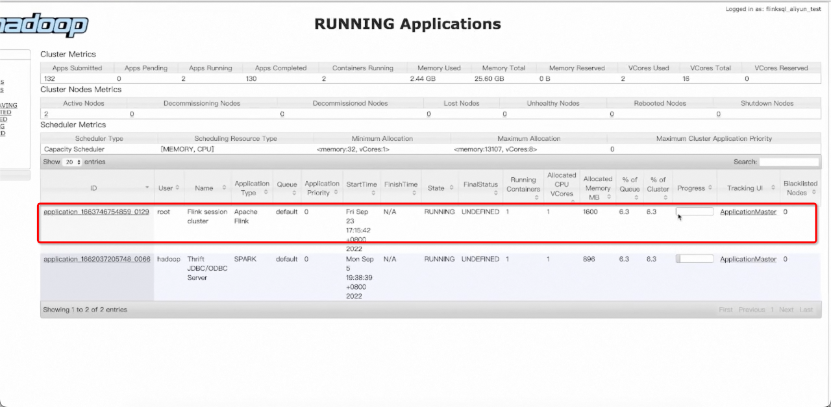
首先搭建 Flink SQL 集群以及启动 SQLGateway。我们已经下载并解压了 Flink 1.16 版本。其中 lib 文件夹下也已经提前准备 Hive connector、JDBC connector 和 MySQL Driver。另外,还需要将 flink-table-planner-loader 与 opt/ 目录下的 flink-table-planner JAR 包做个替换,然后启动 YARN session 集群。Session 集群启动后,可在 yarn 上看到 Flink 的 session application。
在启动 SQLGateway 之前,需要先修改配置,主要配置 HiveServer2 Endpoint 相关的信息。
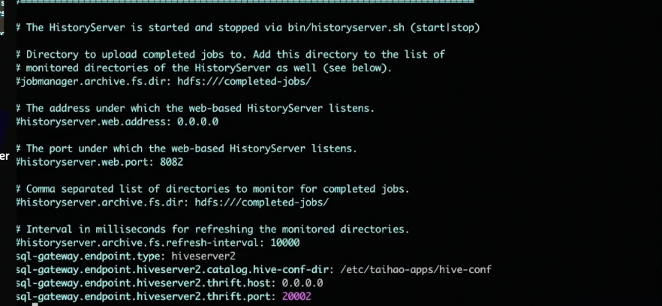

此处 SQLGateway 的 endpoint type 是 HiveServer2,以及需要额外设置三个配置:HiveServer2 的 hive-conf-dir、thrift.host 以及 thrift.port。这里注意我们启动的端口号是 20002。然后通过 sql-gateway.sh start 命令启动 SQL Gateway 服务。
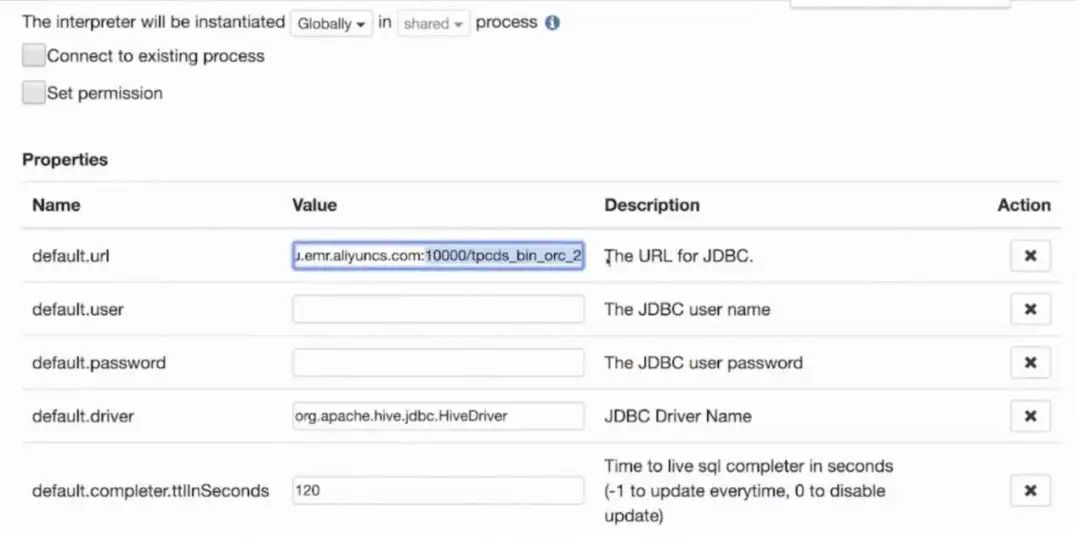
启动后便可以进行迁移。因为 HiveServer2 运行在同一台机器上,因此只需修改端口号即可。将此处 10000 端口号改为刚刚启动的 20002 端口号,即 Flink SQLGateway 的端口,无需进行任何其他改动。重启 interpreter,迁移完成!
接着我们可以在 Zeppelin 中重新执行一遍刚刚的 Hive SQL 语句,可以发现结果都是一致的。
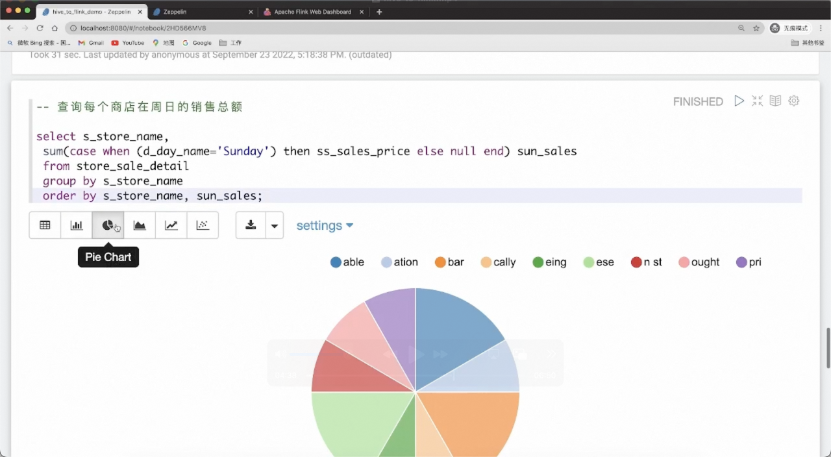
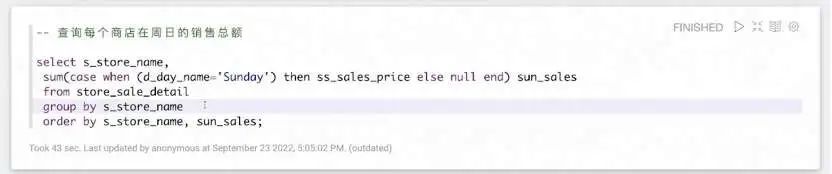
如上图所示,是查询每个商店在周日的销售总额的结果,其饼图结果与使用 Hive 引擎查询的结果完全一致,不同的是这次的查询是运行在 Flink 引擎之上。
Hive SQL 迁移到 Flink SQL 后不仅能获得更好的性能,还能获得 Flink SQL 提供的额外能力,包括更丰富的联邦查询和流批一体能力。
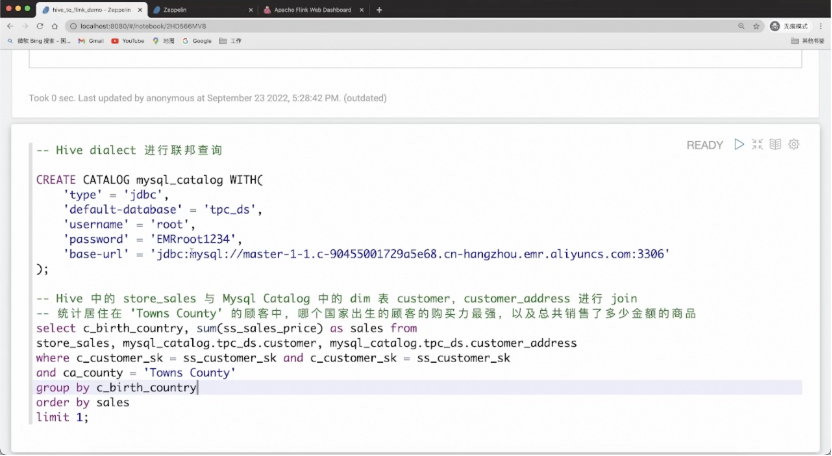
我们可以用 Flink DDL 创建新的 catalog,比如 MySQL 表里还有新的额外的维度信息,不在 Hive 中,希望关联它做新数据的探查。只需使用 Flink 的 CREATE CATALOG 语句创建 MySQL catalog,即可实现联邦查询。同时,Flink 会将能下推的 projection、filter 等都下推到 MySQL 进行裁剪。
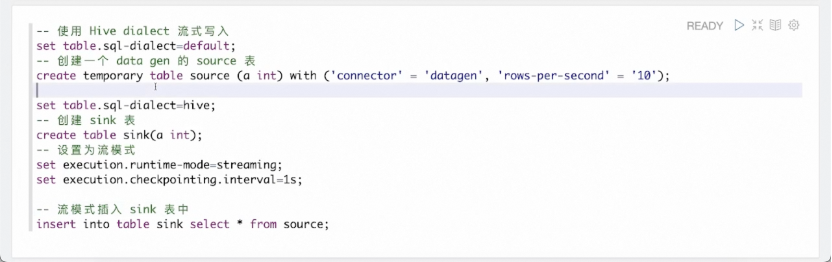
除此之外,也可以使用 Hive SQL 体验流计算的能力。使用 Flink 语法创建一张 datagen 表,该表会源源不断产生随机数据。再切回 Hive 语法创建一张 Hive 结果表 sink。将运行模式改为 streaming,执行 insert into 语句,便提交了一个流作业,该作业会源源不断地将 datagen 中生成的数据流式地写入 Hive。
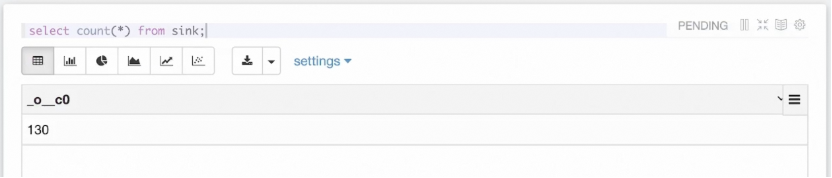
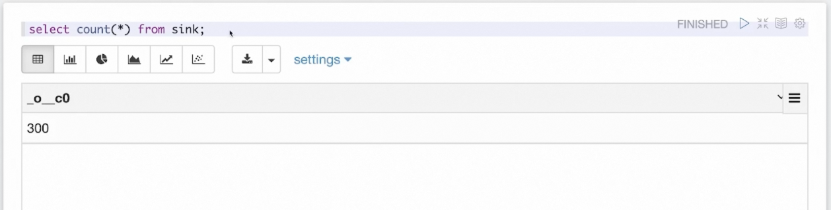
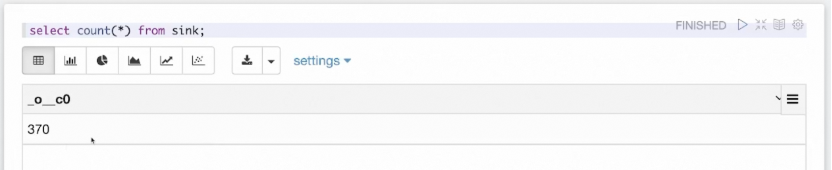
为了验证 Hive 结果表一直在被流作业写入数据,我们也可以用 Hive 语法查询写入的表。如上图所示,通过不断执行 count(*) 语句,可以看到该表一直在写入数据,因此查询结果会不断变化。
05
未来规划

未来,Flink 将在以下三个方面持续演进:
第一,持续在 batch 上做更多尝试和投入,提升 batch 的稳定性和性能,目标是短期内能够追齐主流的批计算引擎。
第二,完善数据湖的分析,比如更高效的批式数据湖读写、查询优化下推、列存上的读写优化,Iceberg、Hudi 以及 Flink Table Store 的支持等。另外,也会提供丰富的湖上数据查询和管理功能,比如查询快照版本的能力、查询元数据、更丰富的 DML 语法(UPDATE、DELETE、MERGE INTO)以及管理湖上数据 CALL 命令等。
第三,Flink Batch 生态建设,包括进一步完善 Remote Shuffle Service、血缘管理等。
Q&A
Q:Hive 写通过 Flink 执行,如果 Hive 数据量特别大,是否会出现内存不足、OOM 等报错?
A:目前 Flink 执行 batch 模式下,基本所有算子里都有内存管理机制。数据不是以 Java 对象的方式存在 Flink,而是在 Java 内存里面开辟了单独的内存空间供其使用。如果内存满,则会做落盘、spill,速度可能会略微下降,但一般不会发生内存 OOM。
Q:Flink 是否支持 Hive 自定义 UDF 函数?迁移成本如何?
A:支持,可直接迁移。
Q:现有的离线数仓从 Hive 迁到 Flink 是否存在风险?平滑迁移的注意点有哪些?
A:平滑迁移目前大多使用双跑平台,通过机制挑选出部分作业先进行迁移,迁移的作业在两个平台同时运行,因此需要验证行为、结果是否一致,然后逐渐将老平台的作业下线,变为单跑。整个过程需要循序渐进,通常需要半年至一年的时间。
Q:Demo 中有一个 SQL 查询使用了 Hive on MR 引擎,迁移之后是走 Flink SQLGateway 还是 Hive on MR 模式?
A:迁移后,因为配置的端口是 Flink SQL Gateway 的端口,所以 SQL 请求走的是 Flink SQL Gateway,Gateway 会将 Hive SQL 编译成 Flink 作业提交到 YARN 集群上运行。
Q:Flink 运行批量任务时,TaskManager 个数是我们指定还是自动生成?
A:对于 standalone 模式,包括运行在 k8s 上的 standalone 模式,TM 数量由用户指定。其他模式下,TM 数量都由 Flink 自己决定和拉起,包括 yarn/k8s application 模式,yarn session 模式, yarn per-job 模式,native k8s session 模式。拉起的 TM 数量和作业请求的 slot 数相关,taskmanager.numberOfTaskSlots 参数决定了 slot 与 TM 个数的映射关系,slot 数量则和被调度的作业节点的并发度相关。
Q:Flink 运行在 K8S 上时,如果启用了动态资源分配,shuffle 数据会一直保存在 POD 磁盘上吗?
A:可以选择,可以 on TM 也可以 on RemoteShuffleService。
Q:离线作业迁移后,是否还支持 with as 语法以及 partition by 语法?
A:WITH AS 语法依然支持,CREATE TABLE 中的 PARTITIONED BY 语法也仍然支持。
Flink 1.16.0 已如期发布,欢迎大家体验和使用 Hive SQL 迁移的能力,也欢迎加入【Flink Batch 交流群】交流和反馈相关的问题和想法。

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,获取演讲 PPT
点击「阅读原文」,获取演讲 PPT