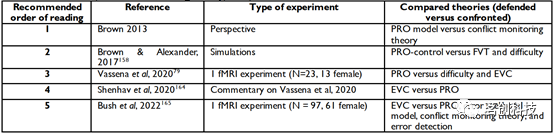
代码:
import torch.nn as nn
import numpy as np
from matplotlib import pyplot as plt
import time
#from utils import get_accur,load_data,train
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
import torch
import torch.optim as optim
import numpy as np
def load_data(path, batch_size):
datasets = torchvision.datasets.ImageFolder(
root = path,
transform = transforms.Compose([
transforms.ToTensor()
])
)
dataloder = DataLoader(datasets, batch_size=batch_size, shuffle=True)
return datasets,dataloder
def get_accur(preds, labels):
preds = preds.argmax(dim=1)
return torch.sum(preds == labels).item()
def train(model, epochs, learning_rate, dataloader, criterion, testdataloader):
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
train_loss_list = []
test_loss_list = []
train_accur_list = []
test_accur_list = []
train_len = len(dataloader.dataset)
test_len = len(testdataloader.dataset)
for i in range(epochs):
train_loss = 0.0
train_accur = 0
test_loss = 0.0
test_accur = 0
for batch in dataloader:
imgs, labels = batch
preds = model(imgs)
optimizer.zero_grad()
loss = criterion(preds, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_accur += get_accur(preds,labels)
train_loss_list.append(train_loss)
train_accur_list.append(train_accur / train_len)
for batch in testdataloader:
imgs, labels = batch
preds = model(imgs)
loss = criterion(preds, labels)
test_loss += loss.item()
test_accur += get_accur(preds,labels)
test_loss_list.append(test_loss)
test_accur_list.append(test_accur / test_len)
print("epoch {} : train_loss : {}; train_accur : {}".format(i + 1, train_loss, train_accur / train_len))
return np.array(train_accur_list), np.array(train_loss_list), np.array(test_accur_list), np.array(test_loss_list)
class ConvNetwork(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=0, dilation=1),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=0, dilation=2),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5, stride=1, padding=0, dilation=5),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.fc = nn.Linear(128 * 3 * 3, 3)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1, 128 * 3 * 3)
out = self.fc(x)
return out
if __name__ == "__main__":
train_path = "./cnn/train/"
test_path = "./cnn/test/"
train_datasets, train_dataloader = load_data(train_path, 64)
test_datasets, test_dataloader = load_data(test_path, 64)
model = ConvNetwork()
critic = nn.CrossEntropyLoss()
epoch = 15
lr = 0.01
start = time.clock()
train_accur_list, train_loss_list, test_accur_list, test_loss_list = train(model, epoch, lr, train_dataloader,
critic, test_dataloader)
end = time.clock()
test_accur = 0
for batch in test_dataloader:
imgs, labels = batch
preds = model(imgs)
test_accur += get_accur(preds, labels)
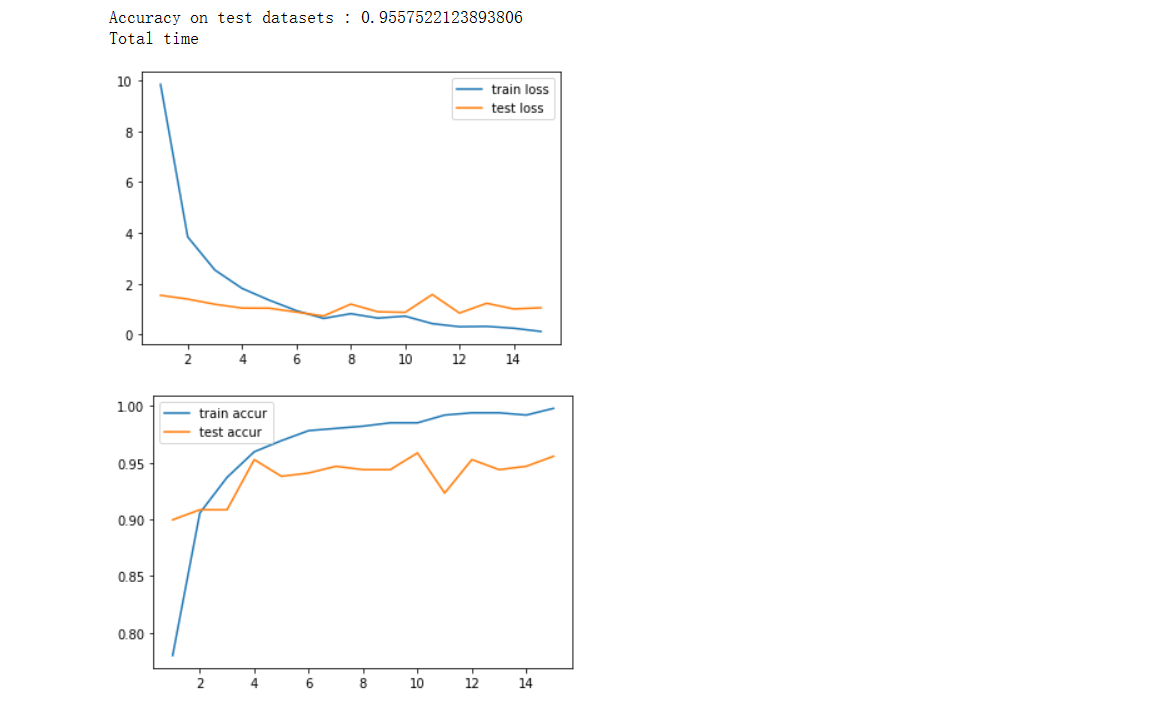
print("Accuracy on test datasets : {}".format(test_accur / len(test_datasets)))
print("Total time".format(end - start))
x_axis = np.arange(1, epoch + 1)
plt.plot(x_axis, train_loss_list, label="train loss")
plt.plot(x_axis, test_loss_list, label="test loss")
plt.legend()
plt.show()
plt.plot(x_axis, train_accur_list, label="train accur")
plt.plot(x_axis, test_accur_list, label="test accur")
plt.legend()
plt.show()
执行结果: