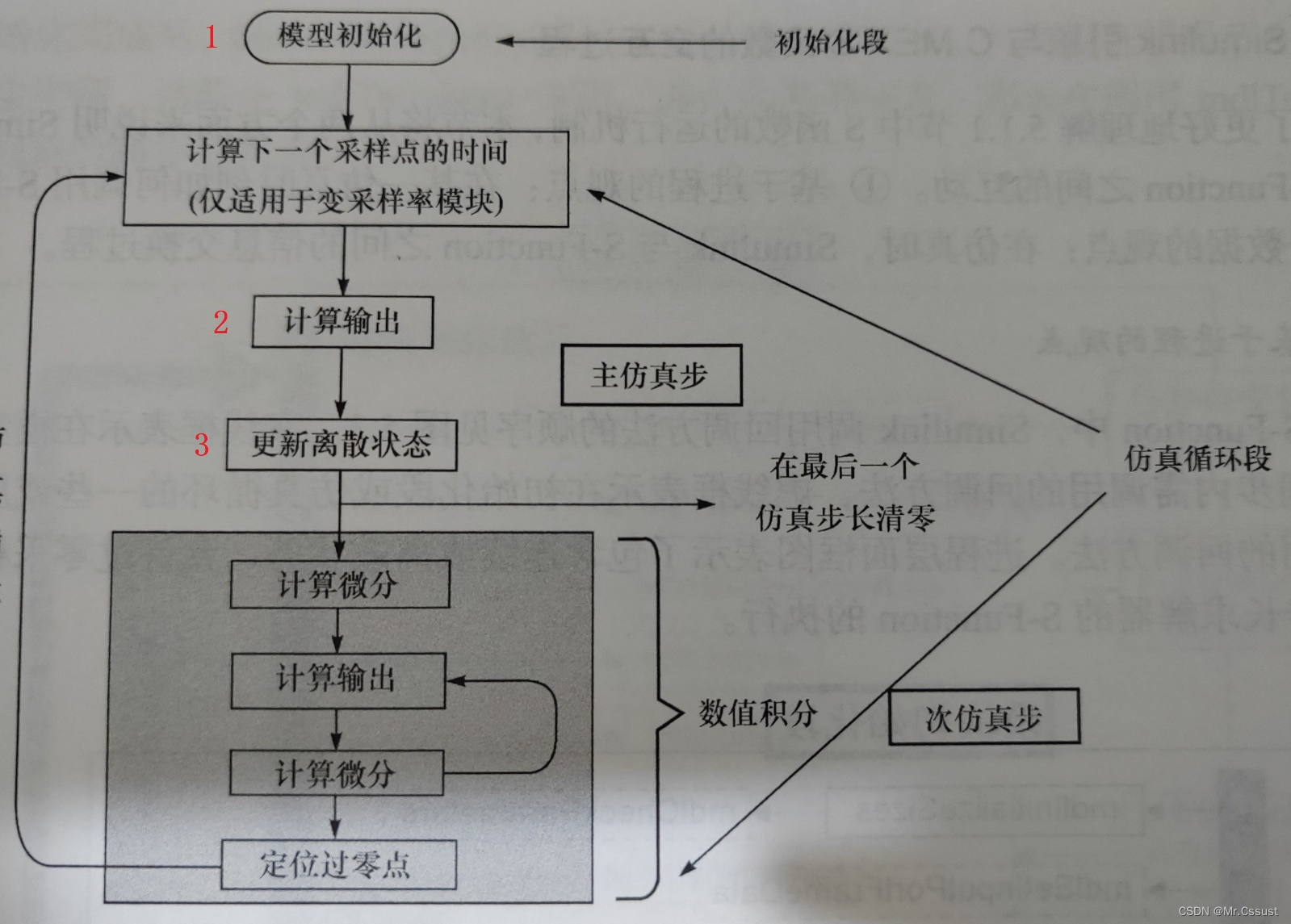
LLM日益流行,已经渗透到各个领域,比如生物医学,但是模型的规模导致微调LLM对普通用户不够友好,因此,我们需要借助一些低成本方法,通过更新少量参数也达到与LLM全参数更新一样的效果。这里介绍三种主流方法:冻结,P-tuning,QLoRA。
冻结
Freeze是冻结的意思,Freeze方法指的是参数冻结,对原始模型的大部分参数进行冻结,仅训练少部分的参数,这样就可以大大减少显存的占用,从而完成对大模型的微调。这是一种比较简单微调方法,由于冻结的参数是大部分,微调的参数是少部分,因此在代码中只需要设置需要微调的层的参数即可,比如:
for name, param in model.named_parameters():
if not any(pn in name for pn in ["layers.26", "layers.25", "layers.24", "layers.23"]):
param.requires_grad = False
P-tuning
P-tuning分为P-tuning v1和P-tuning v2。首先了解prefix-tuning(prefix-tuning:Optimizing Continuous Prompts for Generation),指的是在微调模型的过程中只优化加入的一小段可学习的向量(virtual tokens,即Prefix),而不需要优化整个模型的参数(训练的时候只更新Prefix部分的参数,而LLM中的其他部分参数固定)。prefix-tuning可以理解为在输入信息中添加额外的prompt,这个prompt是通过学习获得的。
可以了解soft prompt和hard prompt:
- hard prompt等同于discrete prompt,离散prompt是一个实际的文本字符串(自然语言,人工可读),通常由中文或英文词汇组成;
- soft prompt等同于continuous prompt,连续prompt通常是在向量空间优化出来的提示,通过梯度搜索之类的方式进行优化。
在离散的prompts中,提示语的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。成本比较高,并且效果不太好,连续的prompts将具有更好的鲁棒性,显然Prefix Tuning属于Soft prompt。

- Model Tuning对每个任务都进行全参数微调。Prompt tuning给每个任务都定义了自己的Prompt(可学习的向量),拼接到数据上作为输入,上图只在输入层加入prompt tokens。混合任务的训练可以提高prompt的鲁棒性。
在P-tuning v1中,使用virtual tokens替换hard prompt中的离散tokens,使用BiLSTM+MLP对virtual tokens编码得到连续prompts。P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:1.更多可学习的参数可以提高表现,2.加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
QLoRA
LoRA需要回顾 LLaMA-7B微调记录-Alpaca-LoRA,LoRA 的最大优势是速度更快,使用的内存更少:
- 计算效率:由于LoRA只需要计算和优化低秩矩阵,因此它的计算效率比完全微调更高。
- 通信效率:在多卡训练中,通信效率通常是一个瓶颈。由于LoRA只需要通信低秩矩阵的参数,因此它的通信效率比完全微调更高。通常,LoRA可以将硬件门槛降低3倍。
QLoRA的核心如下:
- 4bit NormalFloat(NF4):对于正态分布权重而言,这是一种信息理论上最优的数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的结果。
- 双量化(Double Quantization):对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 分页优化器(Paged Optimizers):使用NVIDIA统一内存特性,该特性可以在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
- 增加Adapter:4-bit的NormalFloat与Double Quantization,节省了很多空间,但带来了性能损失,因此通过插入更多adapter来弥补这种性能损失。在LoRA中,一般会选择在query和value的全连接层处插入adapter。而QLoRA则在所有全连接层处都插入了adapter,增加了训练参数,弥补精度带来的性能损失。
微调经验
对于模型大小的选择:
- 一般情况下,参数越大效果越好,资源允许推荐选择30B以上模型;
- 参数多量化低的模型要优于参数低量化高的模型,举例 :33B-fb4 模型要优于 13b-fb16 模型。
数据处理:
- 在数据处理过程中,可能面临各种类型的数据,PDF,Word,HTML,code文件等等,对于这种不同类型的数据需要都处理成文本,同时还过滤掉一些干扰项或乱码的数据。
- 对于空的文档或文档长度低于100进行过滤,进一步减少噪音。
- LLaMA模型的词表大小是32K,其主要针对英语进行训练,对多语种支持不是特别理想,如果要考虑其他语种,还需要扩展词汇表,并进行预训练。
灾难性遗忘问题:
- 如果采用LoRA训练出现遗忘时,可以将 lora_rank调大,如从8调到64 ( 原因是与原模型数据领域相差较大的话,需要更大的秩)。
- 复习:跟人一样,在预训练或微调时,回看之前训练的数据。还可以专门把特征图存起来,量化以后放在一个类似于记忆库的地方,之后在新任务上训练的时候从这个记忆库里重构出记忆和新数据一起训练。
- 尝试调小学习率,如chatglm学习率改到2e-4,但训练速度会慢很多。
来自:https://blog.csdn.net/dzysunshine/article/details/131590701