if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
在offer方法中,我们会先判断数组是否需要扩容,然后判断当前队列是否是空队列,如果是空,插入的元素直接作为数组的第一个元素,也就是完全二叉树的根节点存在。如果不是就执行siftUp(i, e);方法,下面我们来看看siftUp方法的实现:
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
如果我们传入了一个构造器,我们就调用siftUpUsingComparator(k, x),否则调用 siftUpComparable(k, x)方法,这两个方法其实大同小异(只是比较的方式不一样),我们这里就选siftUpComparable来看看:
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
当我们的k(作为第几个元素插入)大于0,我们拿当前插入的元素和数组中的第(k-1)/2个元素进行比较,如果大于,直接跳出循环,直接将数组第k个元素复制为x,即我们的插入元素。如果小于,我们将数组上原来(n-1)/2位置上的元素存放在k位置上,然后继续第(k-1)/2个数,做比较,直到我们的k等于0或者我们插入的元素大于(k-1)/2位置上的元素时,跳出循环。
为什么要和我们的(k-1)/2个元素去比较呢?
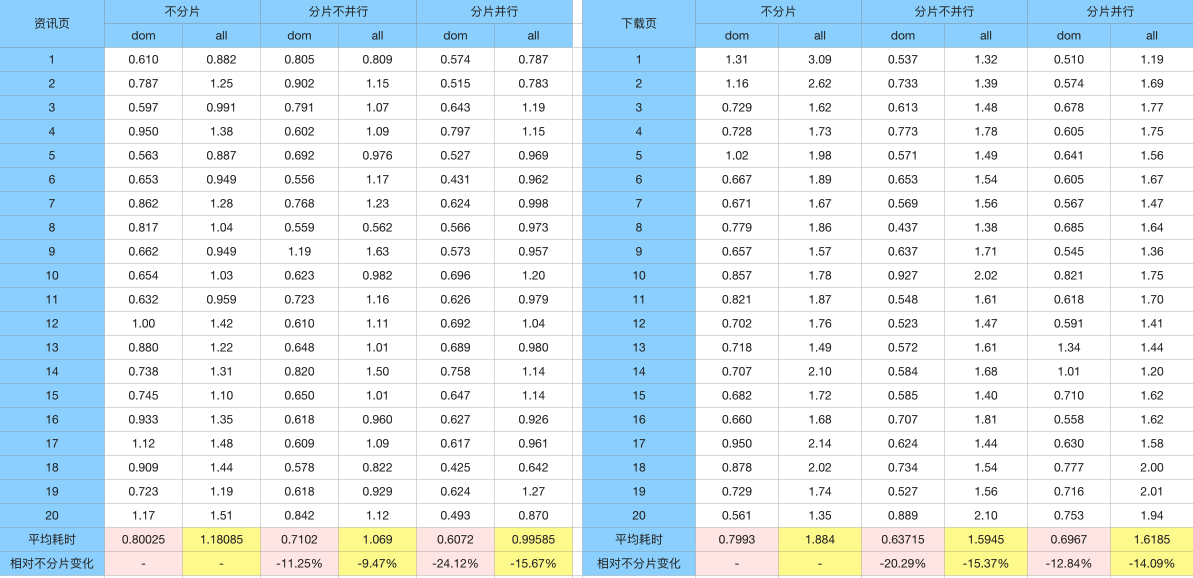
上面我们说过,我们的优先队列其实是个堆(一个棵完全的二叉树)。下面我们看张图大家就懂了:

如上图所示,我们要在原有的小根堆中插入一个数为11,我们最原始的大根堆转为数组表示为:[9,17,65,23,45,78,87,53]。(数组中的元素个数从0开始)
现在我们要插入一个数11,是数组中的第8个元素。因为我们的堆是个完全二叉树,所以我们从最后一层开始找到最近的空的叶子节点(即23的右子节点),在插入一个数后,我们现有的堆,不满足我们小根堆的性质了,所以我们需要重新调整,怎么调整呢,我们和它的父节点23开始比较,23大于11,交换两个数的位置,还是不满足,我们继续往上比较,拿17和11比较还是大,我们继续往上找到9,9大于我们的小于,所以我们的11放在原来17的位置。细心的朋友肯定已经发现了,第(k-1)/2个元素其实就是我们的11在插入和移动过程中的父节点。(8-1)/2等于3,数组中的第3个元素就是23即我们一开始的插入位置的父节点,(3-1)/2等于1,即数组中的第1个元素17。
我们的offer方法其实就是上述代码的实现,每次offer方法执行结束,我们的数组还是满足堆的性质,优先级最大的始终在数组的第一个元素,保证我们优先每次取出的元素,都是优先级最大的(即数值最小的)。
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
出队,取出数组中的第0个元素。用变量x记录数组中的最后一个数,再将最后一个数置为null(移除最后一个元素)。然后执行siftDown方法,下面我们看看siftDown方法的实现:
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
我们直接分析siftDownComparable方法,和siftUpComparable相反,我们siftDownComparable是从上到下进行的,每次都和数组中第2k+1和2k+2的中较小的数比较,如果比较小的数大,我们就和较小的数交换位置否则我们的数就放在k位置上,k从0开始。
我们来用个小根堆分析下:
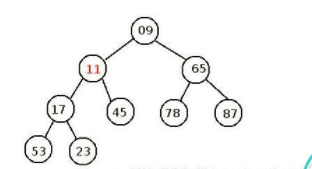
如图所示:我们现在要删除第一个元素9,然后我们取出最后一个数23,拿他和11和65中较小的数11比较,发现23比11大,将11放置在数组的第一个位置,即树的根节点,然后拿23跟17,45中较小的数字17比较,23>17,17 上移,然后拿23和53比较,小于.,所以23占据原来17的位置。
最后结果即:

最小值11跑到了根节点(即优先级最高),整个完全二叉树,还满足堆的性质。
下面我们来看看PriorityQueue的remove方法。
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
private int indexOf(Object o) {
if (o != null) {
for (int i = 0; i < size; i++)
if (o.equals(queue[i]))
return i;
}
return -1;
}
E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);
if (queue[i] == moved) {
siftUp(

i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
首先我们通过遍历当前数组找到要删除元素的索引,然后调用removeAt方法。如果删除的元素,是堆的根节点,则队列为置为空,否则我们找到当前堆的最后一个叶子节点,即数组的最后一个数组,从i(删除的位置开始)执行siftDown操作。如果执行完siftDown操作,删除的位置上的值等于原本数组的最后一位的值在执行从i位置开始shiftUp操作。
还拿上面堆来说明:
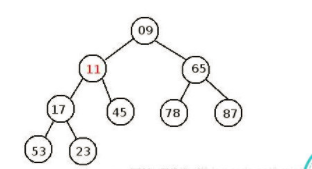
如果我们现在要移除元素11,我们取出最后一个节点元素23从11位置开始从下比较,左后结果就是23取代了17的位置,17取代了11的位置结果如下:

五.优点
相比普通数组,删除和插入的复杂度O(n),PriorityQueue插入和删除元素的复杂度都是O(logn),不需要频繁的移动数组元素,效率比较高。每次删除和插入元素,都会自动调整位置,保证优先级最高的始终在当前数组的第一个。
g?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2JyYWludHQ=,size_16,color_FFFFFF,t_70)
五.优点
相比普通数组,删除和插入的复杂度O(n),PriorityQueue插入和删除元素的复杂度都是O(logn),不需要频繁的移动数组元素,效率比较高。每次删除和插入元素,都会自动调整位置,保证优先级最高的始终在当前数组的第一个。