文章目录
- 版权声明
- 零 引·缘起
- 一 存储原理
- 二 fsck命令
- 2.1 副本块数量的配置
- 2.1.1 全局设置方式
- 2.1.2 临时设置方式
- 2.2 检查文件的副本数
- 2.3 block大小和复制策略配置
- 三 NameNode元数据
- 3.1 edits文件
- 3.2 fsimage文件
- 3.3 NameNode元数据管理维护
- 3.4 元数据合并控制参数
- 3.5 Checkpoint
- 3.6 恢复和元数据操作
- 3.7 SecondaryNameNode的作用
- 四 HDFS数据的学读写流程
- 4.1 数据写入流程
- 4.2 数据读取流程
- 4.3 读写流程总结
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
零 引·缘起
-
在广袤的二次元世界中,一个神奇的存储魔法正在悄然运行,它就是 Hadoop Distributed File System(HDFS)。就像是一个巨大的魔法书库,HDFS 将大文件切成小块,然后将它们分散存放在不同的魔法书架上。每一本小块书都有多个魔法使在不同的书架上保留备份,确保即使魔法书架之一出现了问题,也能从其他书架上找回同样的知识宝藏。
-
这个神奇的存储魔法是如何实现的呢?
第一步:魔法切割
- 在魔法图书馆的中央,有一个超级大法师,称之为 NameNode。他是整个魔法图书馆的管理者,他会将每本大书切成相同大小的小块,让它们更容易管理。这些小块被称为魔法书页,每一页的大小是固定的,通常是128MB。这样一来,大书可以被分成许多小块,便于存储和传输。
第二步:魔法复制
- 为了保证魔法书不会因为某个书架的崩溃而丢失,每一本魔法书页都会被复制到其他不同的书架上。这些复制品被称为魔法镜像。HDFS 默认会将每本书页的魔法镜像复制到三个不同的书架上,这样即使有一个书架受到了邪恶力量的袭击,还有两个书架保持着它的魔法知识。
第三步:魔法映射
- NameNode 还会创建一个魔法地图,将每本魔法书页与它们的魔法镜像的位置关联起来。这样,无论你从哪里进入魔法图书馆,NameNode 都可以帮助你快速找到需要的魔法知识。
第四步:魔法管理
- 每本魔法书页都有自己的守护精灵,称为数据节点。它们负责在书架上保管魔法书页和镜像,并定期向 NameNode 报告它们的状态。如果有一本魔法书页丢失了,数据节点会通过其他镜像或者新的魔法书页来恢复它,保证魔法知识不会被损坏。
就这样,在这个充满魔法与冒险的二次元世界里,HDFS 用它的存储魔法保护着宝贵的数据宝藏。无论是大魔法书还是小魔法页,它们都在这个神奇的存储系统中得到了安全而稳定的保护。一起加入我们的数据冒险队伍,探索这个充满奇迹和挑战的魔法世界吧!
一 存储原理
- 分布式存储:数据存入HDFS是分布式存储,即每一个服务器节点,负责数据的一部分。
- Hadoop Distributed File System (HDFS) 是 Hadoop 生态系统中的分布式文件系统,它将大文件切分成多个块,并在集群中的不同节点上进行存储。每个块都被复制到多个节点以提供容错性。

- 数据在HDFS上是划分为一个个Block块进行存储。
- 为解决文件大小不一的问题,文件的最小存储单元设置为block块,大小为256MB

- 在HDFS上,数据Block块可以有多个副本,提高数据安全性
- 为解决文件丢失问题,提高安全性。将每个Block块备份放入不同的服务器,默认备份数为2

二 fsck命令
2.1 副本块数量的配置
2.1.1 全局设置方式
- HDFS文件系统的数据安全,是依靠多个副本来确保的,设置文件上传到HDFS中拥有的副本数量,可以在
hdfs-site.xml中配置如下属性:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
- 这个属性默认是3,一般情况下,无需主动配置(除非需要设置非3的数值)
- 如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性
2.1.2 临时设置方式
- 除了配置文件外,还可以在上传文件的时候,临时决定被上传文件以多少个副本存储
# 临时设置其副本数为2
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
- 对于已经存在HDFS的文件,修改
dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
# 指定path的内容将会被修改为2个副本存储
# -R选项可选,使用-R表示对子目录也生效
hadoop fs -setrep [-R] 2 path
2.2 检查文件的副本数
- 使用hdfs提供的fsck(file system check)命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
fsck:可以检查指定路径是否正常-files:可以列出路径内的文件状态-files -blocks: 输出文件块报告(有几个块,多少副本)-files -blocks -locations: 输出每一个block的详情
2.3 block大小和复制策略配置
- 块大小(Block Size): HDFS 将大文件切分为固定大小的块,通常情况下默认块大小为 256MB(可以通过配置进行修改)。块大小的选择会影响到文件存储的效率和性能。较小的块大小可能会导致存储开销增加,而较大的块大小可能会导致数据的粒度不够细,影响并行处理能力。
- 配置项:
dfs.blocksize,默认值为 256MB - 示例配置,设置为512MB:
<property> <name>dfs.blocksize</name> <value>536870912</value> </property> - 配置项:
- 块复制策略(Replication Placement Policy): HDFS 支持多种块复制策略,用于确定块的复制位置。默认策略是随机选择不同的机架上的节点进行复制,以增加容错性和性能。
- 可以选择使用不同的策略,如
org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault或自定义的策略。 - 配置项:
dfs.block.replicator.classname,默认值为org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault - 示例配置:
- 可以选择使用不同的策略,如
<property>
<name>dfs.block.replicator.classname</name>
<value>org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault</value>
</property>
三 NameNode元数据
- 在hdfs中,文件是被划分了一堆的block块,Hadoop使用namenode记录和整理文件和block块的关系
- NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
3.1 edits文件
- Edit Logs(编辑日志): 编辑日志记录了所有文件系统的变更操作,比如文件的创建、删除、重命名等。编辑日志保留了文件系统的完整修改历史,是文件系统的操作日志。
- edits文件是流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block

- edits文件的合并

3.2 fsimage文件
- File System Image(文件系统镜像): 文件系统镜像是一个快照,它表示文件系统的当前状态,包括所有文件、目录、权限、属性等信息。
- 文件系统镜像在某个时间点捕获了文件系统的元数据信息,它是静态的。
- 将全部的edits文件,合并为最终结果,即可得到一个FSImage文件
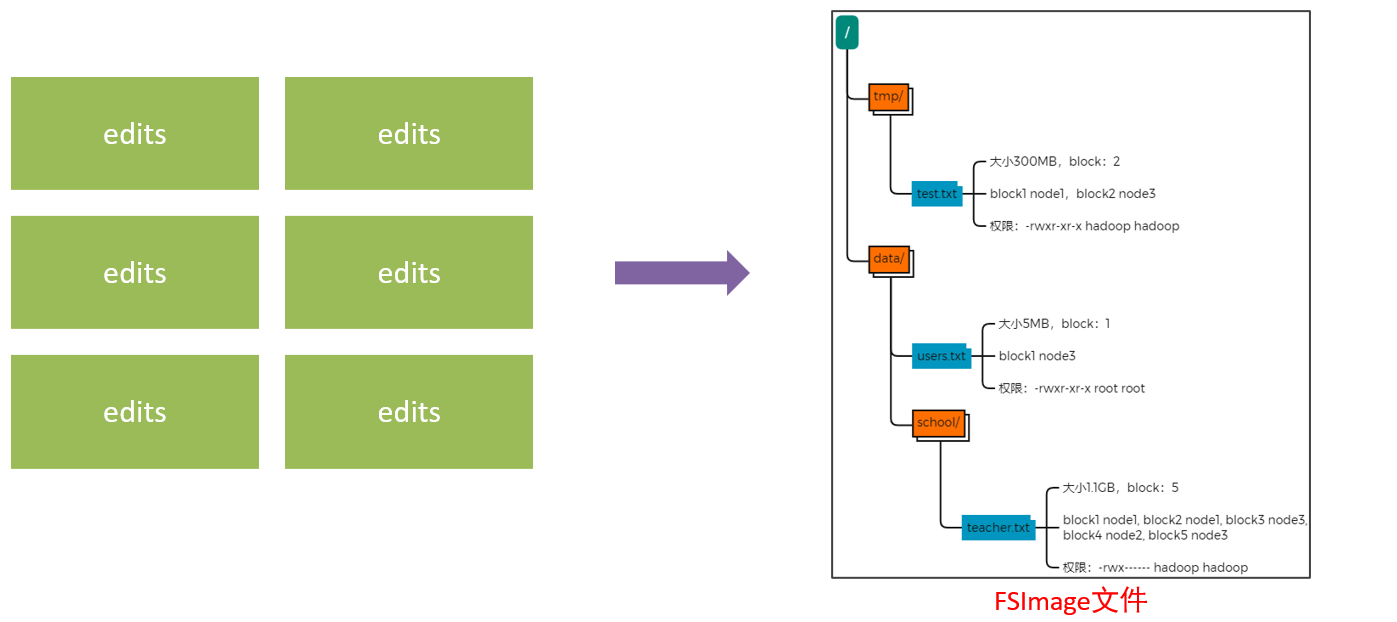
3.3 NameNode元数据管理维护
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
- 每次对HDFS的操作,均被edits文件记录
- edits达到大小上线后,开启新的edits记录
- 定期进行edits的合并操作
- 如当前没有fsimage文件, 将全部edits合并为第一个fsimage
- 如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
- 重复123流程
3.4 元数据合并控制参数
- 对于元数据的合并,是一个定时过程,基于:
dfs.namenode.checkpoint.period,默认3600(秒)即1小时dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个达到条件就执行。
- 检查是否达到条件,默认60秒检查一次,基于:
dfs.namenode.checkpoint.check.period,默认60(秒),来决定
3.5 Checkpoint
- Checkpoint(检查点): 为了防止编辑日志无限增长并提高元数据的恢复效率,NameNode 会定期将当前的编辑日志与文件系统镜像合并,生成一个新的文件系统镜像。这个过程被称为检查点。
- 检查点包含了前一个文件系统镜像和从上一个检查点之后的所有编辑日志记录。
3.6 恢复和元数据操作
- 恢复和元数据操作: 当 NameNode 启动时,它会加载最近的检查点和相关的编辑日志。
- 首先,它加载检查点,使其成为内存中的文件系统状态。然后,它会逐一应用之后的编辑记录,将文件系统状态还原到最新状态。这样,NameNode 可以确保文件系统的元数据在启动后是一致的。
3.7 SecondaryNameNode的作用
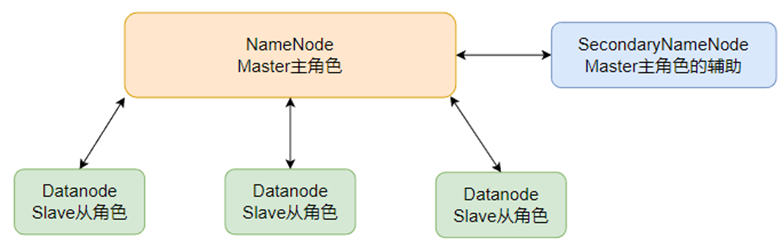
- Secondary NameNode(次要名称节点)是 Hadoop Distributed File System(HDFS)中的一个辅助组件,它的主要作用是帮助 NameNode 进行部分元数据的维护和检查点(Checkpoint)的生成,以减轻 NameNode 的负载并提高系统的可用性。尽管名字中带有 “Secondary”,但 Secondary NameNode 并不是 NameNode 的备用副本。
Secondary NameNode 的作用包括以下几个方面:
-
检查点生成: HDFS 中的 NameNode 在运行过程中会不断地记录文件系统的编辑操作(edits)到编辑日志中。为了避免编辑日志过大并提高元数据的恢复效率,Secondary NameNode 定期从 NameNode 复制文件系统的编辑日志(edits)和文件系统镜像(fsimage),然后将这些信息合并,生成一个新的文件系统镜像。这个合并的过程就是检查点生成。
- 生成的检查点包括了最近的文件系统镜像和之后的编辑操作,而不包括之前的编辑操作。检查点的生成减少了启动时恢复编辑日志的工作量,提高了系统的性能。
-
减轻 NameNode 负载: 在检查点生成的过程中,Secondary NameNode 会执行一些元数据操作,比如合并文件系统镜像和编辑日志。这些操作可以减轻 NameNode 的负载,因为原本这些操作需要由 NameNode 自己执行。通过将这些操作委托给 Secondary NameNode,可以使 NameNode 更专注于处理实际的文件系统请求,提高了系统的响应能力。
-
辅助故障恢复: 在某些情况下,如果 NameNode 发生了故障并需要从备份恢复,Secondary NameNode 可以作为辅助工具。虽然 Secondary NameNode 本身不能替代 NameNode 运行,但它可以提供一个合并后的文件系统镜像,使恢复过程更加高效。
- 注意,尽管 Secondary NameNode 在检查点生成过程中能够减轻 NameNode 的负载,但它并不是 NameNode 的备用副本。在 Hadoop 2.x 版本之后,引入了 High Availability(高可用性)功能,允许使用两个或多个真正的活动 NameNode 实例,以提供更高的可用性和容错性。
四 HDFS数据的学读写流程
4.1 数据写入流程
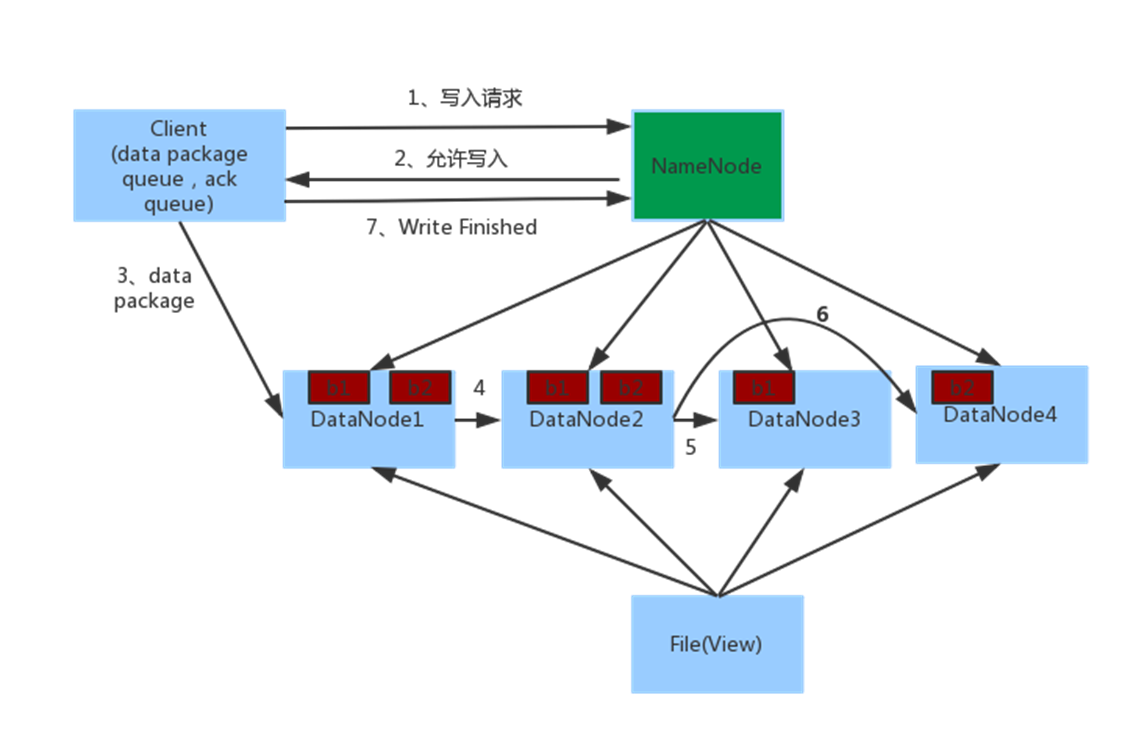
- 客户端向NameNode发起请求
- NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
- 客户端向指定的DataNode发送数据包
- 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
- 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
- 写入完成客户端通知NameNode,NameNode做元数据记录工作
关键信息点:
- NameNode不负责数据写入,只负责元数据记录和权限审批
- 客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个
- 数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)
4.2 数据读取流程
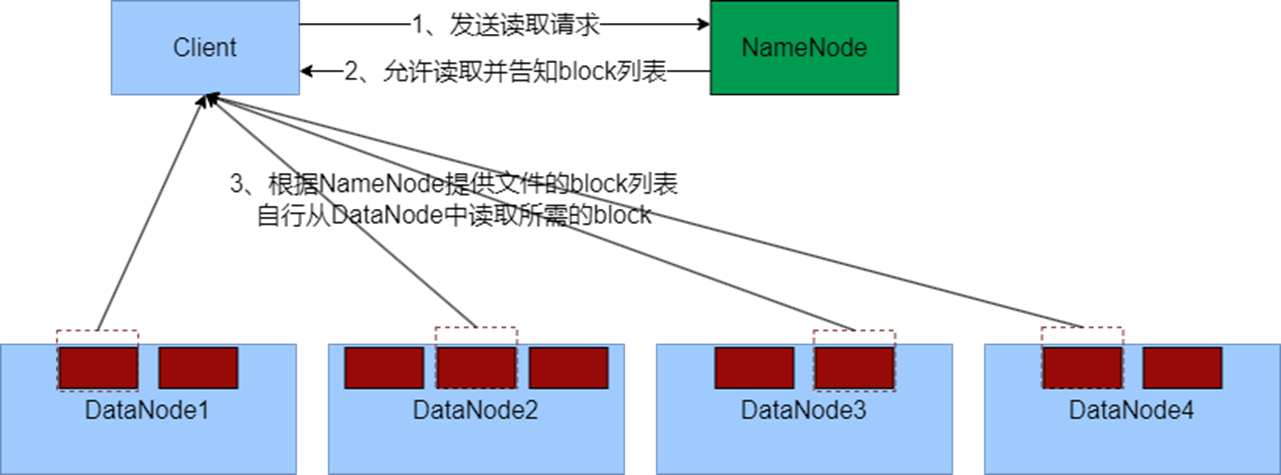
- 客户端向NameNode申请读取某文件
- NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
- 客户端拿到block列表后自行寻找DataNode读取即可
- 关键点:
- 数据同样不通过NameNode提供
- NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的。这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取
4.3 读写流程总结
- 对于客户端读取HDFS数据的流程中
- 不论读、还是写,NameNode都不经手数据,均是客户端和DataNode直接通讯
- 不然对NameNode压力太大
- 写入和读取的流程,简单来说就是:
- NameNode做授权判断(是否能写、是否能读)
- 客户端直连DataNode进行写入(由DataNode自己完成副本复制)、客户端直连DataNode进行block读取
- 写入,客户端会被分配找离自己最近的DataNode写数据
- 读取,客户端拿到的block列表,会是网络距离最近的一份
- 网络距离
- 最近的距离就是在同一台机器
- 其次就是同一个局域网(交换机)
- 再其次就是跨越交换机
- 再其次就是跨越数据中心
- HDFS内置网络距离计算算法,可以通过IP地址、路由表来推断网络距离