【Redis】什么是缓存穿透,如何预防缓存穿透?
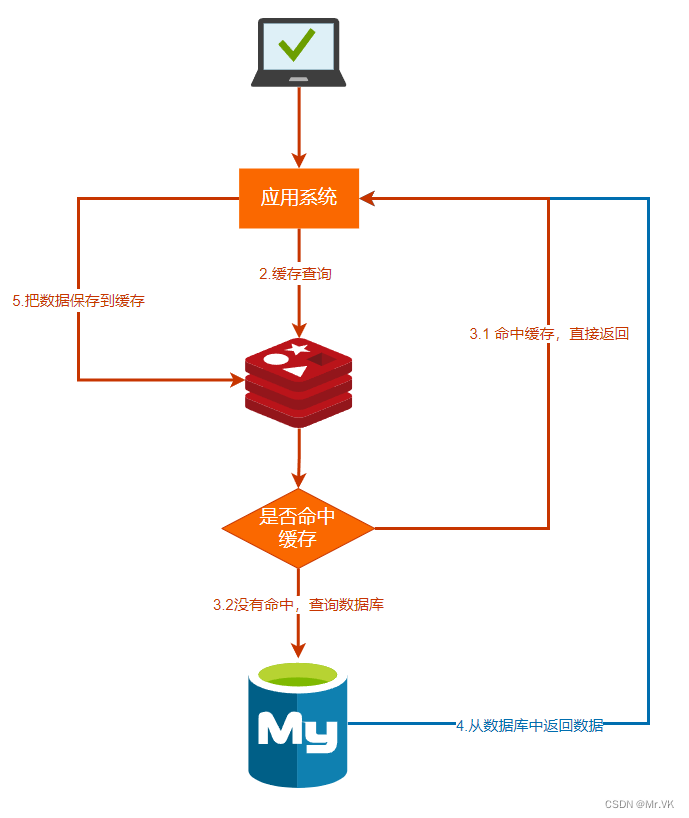
缓存穿透是指查询一个一定不存在的数据,由于缓存中不存在,这时会去数据库查询查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,这就造成缓存穿透。简单来说,就是访问业务系统不存在的数据,就可能会造成缓存穿透。
缓存穿透会产生什么危害呢?危害就是如果存在海量请求查询系统根本不存在的数据,那么这些海量请求都要查询数据库中,数据库压力剧增,就可能会导致系统崩溃。
防止缓存穿透有两个解决办法。
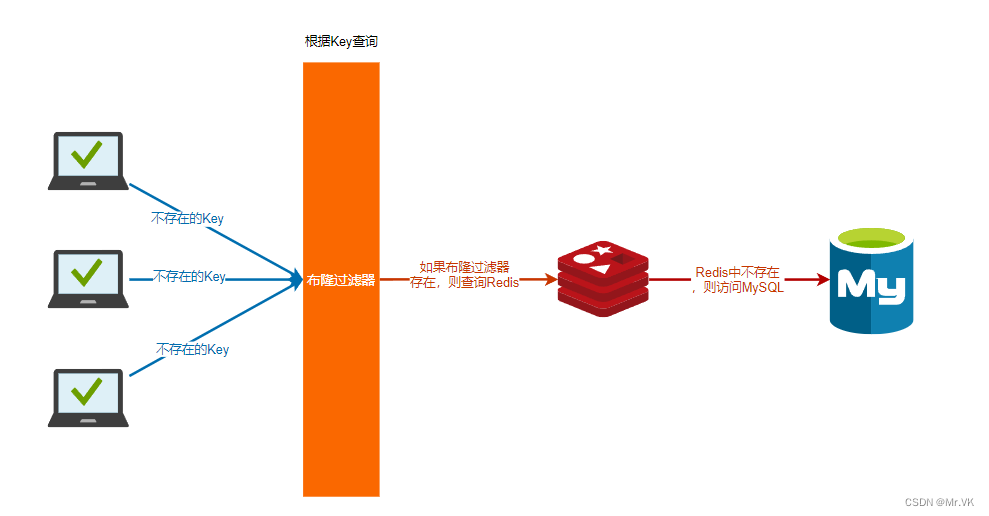
第一个办法是在缓存之前再加一道屏障,在控制层先进行校验,符合规则才进行查询,最常见的是采用 BloomFilter(即布隆过滤器)。BloomFilter 中存储目前数据库中存在的所有 Key。当业务系统有查询请求时,首先去 BloomFilter 中查询该 Key 是否存在。若不存在,则说明数据库中也不存在该数据,直接返回空值。若存在,则继续执行后续的流程,先从缓存中查询,缓存中没有再访问数据库进行查询。
使用 BloomFilter 判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合,但不会把属于这个集合的元素误认为不属于这个集合。在增加了错误率这个因素之后,BloomFilter 通过允许少量的错误来节省大量的存储空间。
BloomFilter的缺点:只适用于数据命中不高,数据相对固定实时性低(通常是数据集较大)的应用场景,代码维护也较为复杂。
当然,它也有优点,就是缓存空间占用少
另外一个办法就是空值缓存。也就是如果一个查询返回的数据为空 (不管是数据不存在,还是系统故障),仍然把这个空结果进行缓存。但这样做有一定的弊端,就是当这个查询有数据时,在一定时间内得到的结果仍然是空,所以这个空结果的数据它的过期时间应该要设置得短一些,让它能得到自动剔除;空值缓存,也就保存了更多的键值,消耗了更多的内存空间,如果是外部攻击大量的空值缓存,会消耗掉所有的内存空间,导致系统崩溃。所以空值缓存的利与弊需要在使用过程中综合考虑。