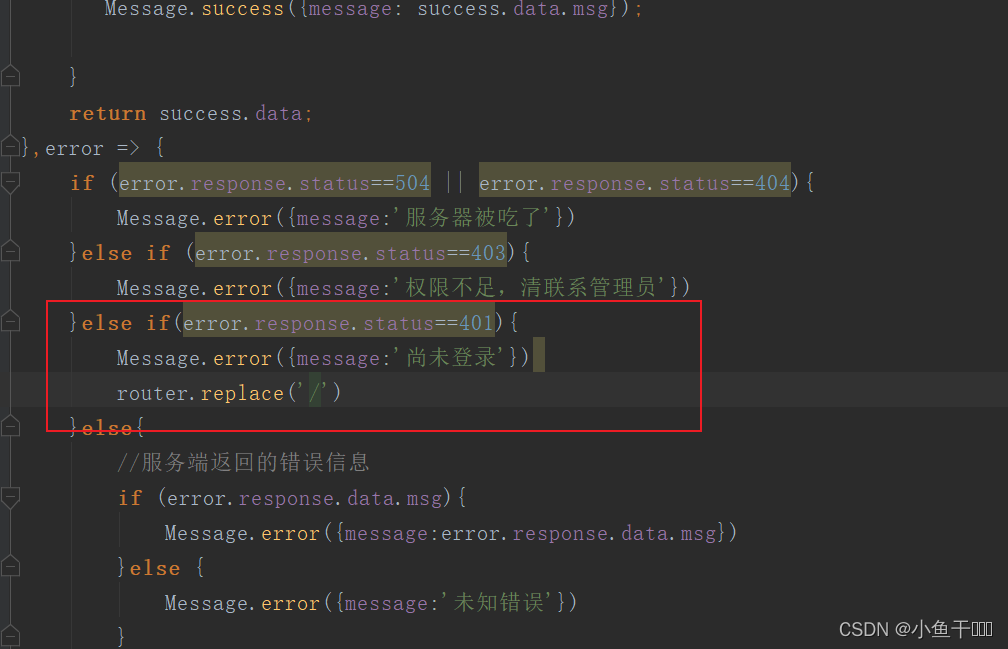
classification
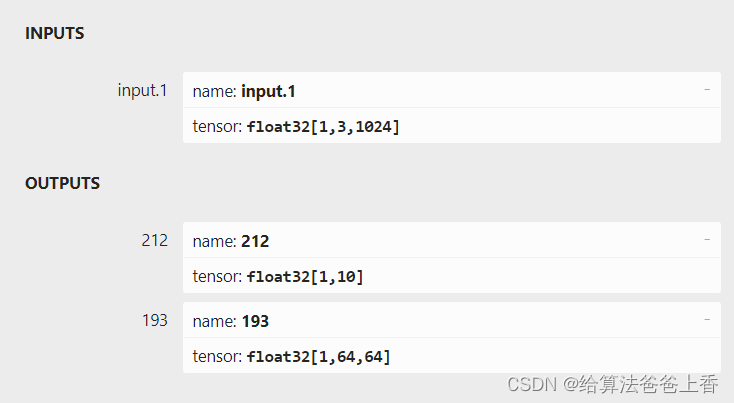
如上图所示,由于直接export出的onnx文件有两个输出节点,不方便处理,所以编写脚本删除不需要的输出节点193:
import onnx
onnx_model = onnx.load("cls.onnx")
graph = onnx_model.graph
inputs = graph.input
for input in inputs:
print('input',input.name)
outputs = graph.output
for output in outputs:
print('output',output.name)
graph.output.remove(outputs[1])
onnx.save(onnx_model, 'cls_modified.onnx')
C++推理代码:
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include <cuda_runtime.h>
#include <NvInfer.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h>
const int point_num = 1024;
void pc_normalize(std::vector<float>& points)
{
float mean_x = 0, mean_y = 0, mean_z = 0;
for (size_t i = 0; i < point_num; ++i)
{
mean_x += points[3 * i];
mean_y += points[3 * i + 1];
mean_z += points[3 * i + 2];
}
mean_x /= point_num;
mean_y /= point_num;
mean_z /= point_num;
for (size_t i = 0; i < point_num; ++i)
{
points[3 * i] -= mean_x;
points[3 * i + 1] -= mean_y;
points[3 * i + 2] -= mean_z;
}
float m = 0;
for (size_t i = 0; i < point_num; ++i)
{
if (sqrt(pow(points[3 * i], 2) + pow(points[3 * i + 1], 2) + pow(points[3 * i + 2], 2)) > m)
m = sqrt(pow(points[3 * i], 2) + pow(points[3 * i + 1], 2) + pow(points[3 * i + 2], 2));
}
for (size_t i = 0; i < point_num; ++i)
{
points[3 * i] /= m;
points[3 * i + 1] /= m;
points[3 * i + 2] /= m;
}
}
class TRTLogger : public nvinfer1::ILogger
{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override
{
if (severity <= Severity::kINFO)
printf(msg);
}
} logger;
std::vector<unsigned char> load_file(const std::string& file)
{
std::ifstream in(file, std::ios::in | std::ios::binary);
if (!in.is_open())
return {};
in.seekg(0, std::ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0)
{
in.seekg(0, std::ios::beg);
data.resize(length);
in.read((char*)& data[0], length);
}
in.close();
return data;
}
void classfier(std::vector<float> & points)
{
TRTLogger logger;
nvinfer1::ICudaEngine* engine;
//#define BUILD_ENGINE
#ifdef BUILD_ENGINE
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);
if (!parser->parseFromFile("cls_modified.onnx", 1))
{
printf("Failed to parser onnx\n");
return;
}
int maxBatchSize = 1;
config->setMaxWorkspaceSize(1 << 32);
engine = builder->buildEngineWithConfig(*network, *config);
if (engine == nullptr) {
printf("Build engine failed.\n");
return;
}
nvinfer1::IHostMemory* model_data = engine->serialize();
FILE* f = fopen("cls.engine", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
model_data->destroy();
parser->destroy();
engine->destroy();
network->destroy();
config->destroy();
builder->destroy();
#endif
auto engine_data = load_file("cls.engine");
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());
if (engine == nullptr)
{
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
float* input_data_host = nullptr;
const size_t input_numel = 1 * 3 * point_num;
cudaMallocHost(&input_data_host, input_numel * sizeof(float));
for (size_t i = 0; i < 3; i++)
{
for (size_t j = 0; j < point_num; j++)
{
input_data_host[point_num * i + j] = points[3 * j + i];
}
}
float* input_data_device = nullptr;
float output_data_host[10];
float* output_data_device = nullptr;
cudaMalloc(&input_data_device, input_numel * sizeof(float));
cudaMalloc(&output_data_device, sizeof(output_data_host));
cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream);
float* bindings[] = { input_data_device, output_data_device };
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
int predict_label = std::max_element(output_data_host, output_data_host + 10) - output_data_host;
std::cout << "\npredict_label: " << predict_label << std::endl;
cudaStreamDestroy(stream);
execution_context->destroy();
engine->destroy();
runtime->destroy();
}
int main()
{
std::vector<float> points;
std::ifstream infile;
float x, y, z, nx, ny, nz;
char ch;
infile.open("bed_0610.txt");
for (size_t i = 0; i < point_num; i++)
{
infile >> x >> ch >> y >> ch >> z >> ch >> nx >> ch >> ny >> ch >> nz;
points.push_back(x);
points.push_back(y);
points.push_back(z);
}
infile.close();
pc_normalize(points);
classfier(points);
return 0;
}
其中推理引擎的构建也可以直接使用tensorrt的bin目录下的trtexec.exe。
LZ也实现了cuda版本的前处理代码,但似乎效率比cpu前处理还低。可能是数据量不够大吧(才10^3数量级),而且目前LZ的cuda水平也只是入门阶段…
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#include <NvInfer.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h>
const int point_num = 1024;
const int thread_num = 1024;
const int block_num = 1;
__global__ void array_sum(float* data, float* val, int N)
{
__shared__ double share_dTemp[thread_num];
const int nStep = gridDim.x * blockDim.x;
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
double dTempSum = 0.0;
for (int i = tid; i < N; i += nStep)
{
dTempSum += data[i];
}
share_dTemp[threadIdx.x] = dTempSum;
__syncthreads();
for (int i = blockDim.x / 2; i != 0; i /= 2)
{
if (threadIdx.x < i)
{
share_dTemp[threadIdx.x] += share_dTemp[threadIdx.x + i];
}
__syncthreads();
}
if (0 == threadIdx.x)
{
atomicAdd(val, share_dTemp[0]);
}
}
__global__ void array_sub(float* data, float val, int N)
{
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
const int nStep = blockDim.x * gridDim.x;
for (int i = tid; i < N; i += nStep)
{
data[i] = data[i] - val;
}
}
__global__ void array_L2(float* in, float* out, int N)
{
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
const int nStep = blockDim.x * gridDim.x;
for (int i = tid; i < N; i += nStep)
{
out[i] = sqrt(pow(in[i], 2) + pow(in[i + N], 2) + pow(in[i + 2 * N], 2));
}
}
__global__ void array_max(float* mem, int numbers)
{
int tid = threadIdx.x;
int idof = blockIdx.x * blockDim.x;
int idx = tid + idof;
extern __shared__ float tep[];
if (idx >= numbers) return;
tep[tid] = mem[idx];
unsigned int bi = 0;
for (int s = 1; s < blockDim.x; s = (s << 1))
{
unsigned int kid = tid << (bi + 1);
if ((kid + s) >= blockDim.x || (idof + kid + s) >= numbers) break;
tep[kid] = tep[kid] > tep[kid + s] ? tep[kid] : tep[kid + s];
++bi;
__syncthreads();
}
if (tid == 0)
{
mem[blockIdx.x] = tep[0];
}
}
__global__ void array_div(float* data, float val, int N)
{
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
const int nStep = blockDim.x * gridDim.x;
for (int i = tid; i < N; i += nStep)
{
data[i] = data[i] / val;
}
}
void pc_normalize_gpu(float* points)
{
float *mean_x = NULL, *mean_y = NULL, *mean_z = NULL;
cudaMalloc((void**)& mean_x, sizeof(float));
cudaMalloc((void**)& mean_y, sizeof(float));
cudaMalloc((void**)& mean_z, sizeof(float));
array_sum << <thread_num, block_num >> > (points + 0 * point_num, mean_x, point_num);
array_sum << <thread_num, block_num >> > (points + 1 * point_num, mean_y, point_num);
array_sum << <thread_num, block_num >> > (points + 2 * point_num, mean_z, point_num);
float mx, my, mz;
cudaMemcpy(&mx, mean_x, sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(&my, mean_y, sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(&mz, mean_z, sizeof(float), cudaMemcpyDeviceToHost);
array_sub << <thread_num, block_num >> > (points + 0 * point_num, mx / point_num, point_num);
array_sub << <thread_num, block_num >> > (points + 1 * point_num, my / point_num, point_num);
array_sub << <thread_num, block_num >> > (points + 2 * point_num, mz / point_num, point_num);
//float* pts = (float*)malloc(sizeof(float) * point_num);
//cudaMemcpy(pts, points, sizeof(float) * point_num, cudaMemcpyDeviceToHost);
//for (size_t i = 0; i < point_num; i++)
//{
// std::cout << pts[i] << std::endl;
//}
float* L2 = NULL;
cudaMalloc((void**)& L2, sizeof(float) * point_num);
array_L2 << <thread_num, block_num >> > (points, L2, point_num);
//float* l2 = (float*)malloc(sizeof(float) * point_num);
//cudaMemcpy(l2, L2, sizeof(float) * point_num, cudaMemcpyDeviceToHost);
//for (size_t i = 0; i < point_num; i++)
//{
// std::cout << l2[i] << std::endl;
//}
int tmp_num = point_num;
int share_size = sizeof(float) * thread_num;
int block_num = (tmp_num + thread_num - 1) / thread_num;
do {
array_max << <block_num, thread_num, share_size >> > (L2, thread_num);
tmp_num = block_num;
block_num = (tmp_num + thread_num - 1) / thread_num;
} while (tmp_num > 1);
float max;
cudaMemcpy(&max, L2, sizeof(float), cudaMemcpyDeviceToHost);
//std::cout << max << std::endl;
array_div << <thread_num, block_num >> > (points + 0 * point_num, max, point_num);
array_div << <thread_num, block_num >> > (points + 1 * point_num, max, point_num);
array_div << <thread_num, block_num >> > (points + 2 * point_num, max, point_num);
}
class TRTLogger : public nvinfer1::ILogger
{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override
{
if (severity <= Severity::kINFO)
printf(msg);
}
} logger;
std::vector<unsigned char> load_file(const std::string& file)
{
std::ifstream in(file, std::ios::in | std::ios::binary);
if (!in.is_open())
return {};
in.seekg(0, std::ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0)
{
in.seekg(0, std::ios::beg);
data.resize(length);
in.read((char*)& data[0], length);
}
in.close();
return data;
}
void classfier(std::vector<float> & points)
{
TRTLogger logger;
nvinfer1::ICudaEngine* engine;
//#define BUILD_ENGINE
#ifdef BUILD_ENGINE
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);
if (!parser->parseFromFile("cls_modified.onnx", 1))
{
printf("Failed to parser onnx\n");
return;
}
int maxBatchSize = 1;
config->setMaxWorkspaceSize(1 << 32);
engine = builder->buildEngineWithConfig(*network, *config);
if (engine == nullptr) {
printf("Build engine failed.\n");
return;
}
nvinfer1::IHostMemory* model_data = engine->serialize();
FILE* f = fopen("cls.engine", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
model_data->destroy();
parser->destroy();
engine->destroy();
network->destroy();
config->destroy();
builder->destroy();
#endif
auto engine_data = load_file("cls.engine");
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());
if (engine == nullptr)
{
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
float* input_data_host = nullptr;
const size_t input_numel = 1 * 3 * point_num;
cudaMallocHost(&input_data_host, input_numel * sizeof(float));
for (size_t i = 0; i < 3; i++)
{
for (size_t j = 0; j < point_num; j++)
{
input_data_host[point_num * i + j] = points[3 * j + i];
}
}
float* input_data_device = nullptr;
float output_data_host[10];
float* output_data_device = nullptr;
cudaMalloc(&input_data_device, input_numel * sizeof(float));
cudaMalloc(&output_data_device, sizeof(output_data_host));
cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream);
pc_normalize_gpu(input_data_device);
float* bindings[] = { input_data_device, output_data_device };
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
int predict_label = std::max_element(output_data_host, output_data_host + 10) - output_data_host;
std::cout << "\npredict_label: " << predict_label << std::endl;
cudaStreamDestroy(stream);
execution_context->destroy();
engine->destroy();
runtime->destroy();
}
int main()
{
std::vector<float> points;
std::ifstream infile;
float x, y, z, nx, ny, nz;
char ch;
infile.open("sofa_0020.txt");
for (size_t i = 0; i < point_num; i++)
{
infile >> x >> ch >> y >> ch >> z >> ch >> nx >> ch >> ny >> ch >> nz;
points.push_back(x);
points.push_back(y);
points.push_back(z);
}
infile.close();
classfier(points);
return 0;
}