原文链接:https://arxiv.org/abs/2304.09801
1. 引言
目前,多模态融合感知中的一大问题在于忽视了传感器失效带来的影响。之前工作的主要问题包括:
- 特征不对齐:通常使用CNN处理拼接后的特征图,存在几何噪声时可能导致特征不对齐;这可归因于CNN在长距离感知和对输入自适应关注的局限性。
- 高度依赖完整模态:基于查询的方法或按通道融合的方法,均高度依赖完整的模态输入,性能会在某一模态失效时严重下降。
本文提出MetaBEV,在统一的BEV表达下解决上述问题,而与使用的模态或者具体的任务无关。由于现有方法的瓶颈在于融合模块缺乏独立融合的能力,本文提出任意模态BEV进化解码器,使用跨模态注意力关联单一模态或多模态特征。
本文在6种传感器失效(包括视野受限(LF),光束减少(BR),物体丢失(MO),视图丢失(VD),视图噪声(VN),障碍遮挡(OO))和2种传感器丢失(包括激光雷达丢失(ML),相机丢失(MC))的情况下对MetaBEV进行了评估。实验表明MetaBEV具有强鲁棒性。
此外,本文使用共享框架处理多任务。但是多任务之间的冲突会导致性能下降,而很少有工作去分析和进行相应的方案设计。本文将MetaBEV与多任务混合专家(M
2
^2
2oE)模块整合,为多任务学习提供可能的解决方案。
3. MetaBEV方法
本文通过参数化的meta-BEV连接各个模态,并使用跨模态注意力整合来自各模态的几何和语义信息。网络如下图所示,由特征编码器、(带跨模态可变形注意力的)BEV进化解码器和任务头组成。
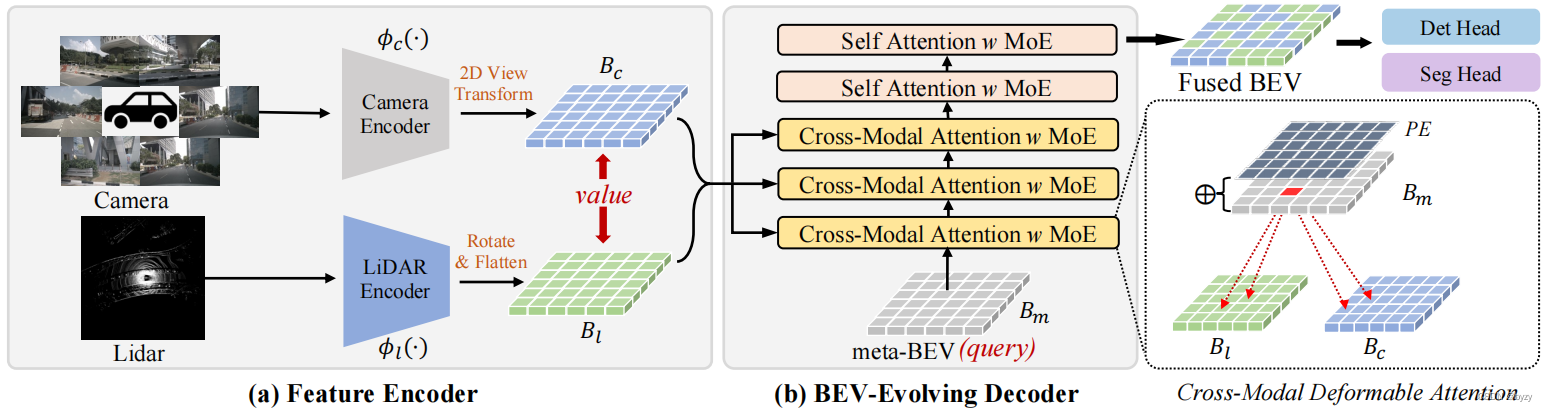
3.1 BEV特征编码器概述
MetaBEV在BEV下生成融合特征,以组合多模态特征并适应不同的任务。
相机/激光雷达到BEV:使用BEVFusion的方式,使用图像主干提取多视图图像特征,并按照LSS将图像特征提升到3D空间,并压缩得到BEV特征图
B
c
B_c
Bc。激光雷达进行体素化后,使用3D稀疏卷积编码为BEV表达
B
l
B_l
Bl。
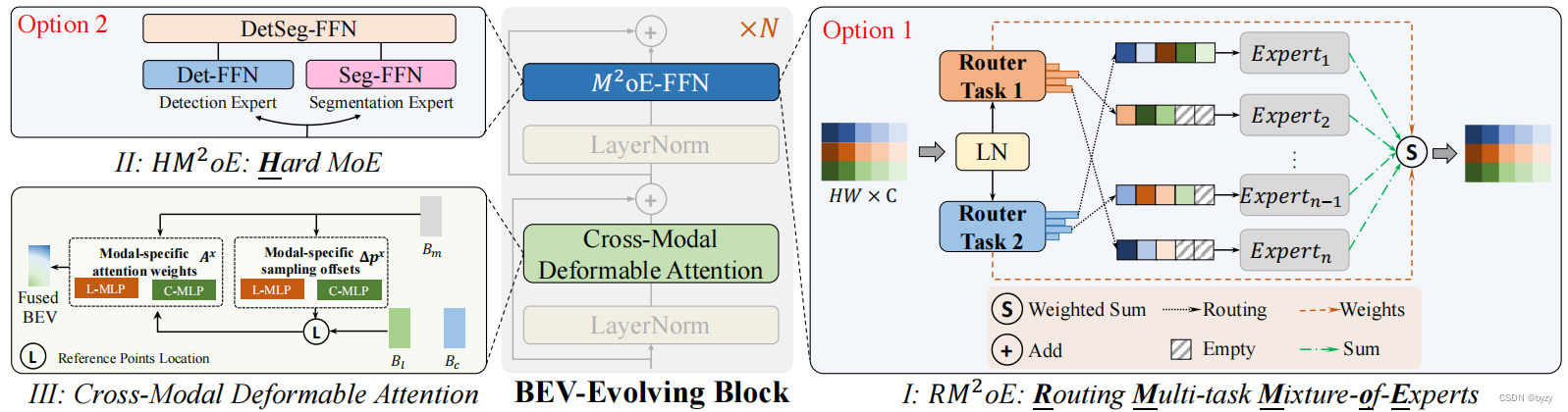
3.2 BEV进化解码器
该部分由三个组件构成:跨模态注意力层,自注意力层和即插即用的M
2
^2
2oE块。结构如下图所示。
跨模态注意力层:首先初始化密集BEV查询,称为meta-BEV
B
m
B_m
Bm。与位置编码相加后,和各模态交互。为加快效率,本文使用可变形注意力
DAttn
(
⋅
)
\text{DAttn}(\cdot)
DAttn(⋅)。但原始的可变形注意力不适合处理任意模态输入。本文使用模态相关的MLP(上图中的C-MLP和L-MLP)预测采样点和注意力权重
A
A
A。给定BEV表达
x
∈
{
B
c
,
B
l
}
x\in\{B_c,B_l\}
x∈{Bc,Bl},首先生成模态相关的采样偏移量
Δ
p
x
\Delta p^x
Δpx和注意力权重
A
x
A^x
Ax,前者用于定位采样特征,后者用于缩放采样特征。之后利用缩放的采样特征更新meta-BEV。整个过程可表示如下:
DAttn
(
B
m
,
p
,
x
)
=
∑
m
=
1
M
W
m
[
∑
x
∈
{
B
c
,
B
l
}
∑
k
=
1
K
A
m
k
x
⋅
W
m
′
x
(
p
+
Δ
p
m
k
x
)
]
\text{DAttn}(B_m,p,x)=\sum_{m=1}^MW_m[\sum_{x\in\{B_c,B_l\}}\sum_{k=1}^KA_{mk}^x\cdot W'_{m}x(p+\Delta p_{mk}^x)]
DAttn(Bm,p,x)=m=1∑MWm[x∈{Bc,Bl}∑k=1∑KAmkx⋅Wm′x(p+Δpmkx)]其中
m
m
m表示注意力头,
K
K
K表示采样点数,
p
p
p表示参考点。
W
m
W_m
Wm和
W
m
′
W'_m
Wm′表示可学习投影矩阵。
交叉注意力机制一层一层地融合特征,使meta-BEV迭代地“进化”为融合特征。
自注意力层:上述过程未进行查询之间的交互。本文使用自注意力。使用
B
m
B_m
Bm替换前面式子中的
x
x
x,得到自注意力的表达式
DAttn
(
B
m
,
p
,
B
m
)
\text{DAttn}(B_m,p,B_m)
DAttn(Bm,p,Bm)。
M
2
^\textbf{2}
2oE块:按照之前通过混合专家层(MoE)为大型语言建模的方式,本文将MLP引入BEV进化块,提出M
2
^2
2oE块用于多任务学习,如上一张图中的I、II所示。
首先介绍RM
2
^2
2oE:
M
2
oE
(
x
)
=
∑
i
=
1
t
R
(
x
)
i
E
i
(
x
)
,
t
≪
E
\text{M}^2\text{oE}(x)=\sum_{i=1}^t\mathcal{R}(x)_i\mathcal{E}_i(x),t\ll E
M2oE(x)=i=1∑tR(x)iEi(x),t≪E其中
x
x
x是输入RM
2
^2
2oE-FFN的token,
R
:
R
D
→
R
E
\mathcal{R}:\mathbb{R}^D\rightarrow\mathbb{R}^E
R:RD→RE是将token分配给所属专家的寻径函数,
E
i
:
R
D
→
R
D
\mathcal{E}_i:\mathbb{R}^D\rightarrow\mathbb{R}^D
Ei:RD→RD是专家
i
i
i处理的token。
R
\mathcal{R}
R和
E
i
\mathcal{E}_i
Ei均为MLP,
E
E
E是确定专家数量的超参数。对于每个token,
R
\mathcal{R}
R会选择概率最高的
t
t
t个专家进行分配,导致大量的专家处于未激活状态。
HM
2
^2
2oE属于RM
2
^2
2oE的退化版本(
E
E
E等于任务数且
t
=
1
t=1
t=1)。token会绕过路径分配过程通过相应任务的FFN网络,然后在任务融合网络融合。这个过程能通过不同的专家分离多任务相互冲突的梯度,从而减轻任务冲突。
3.3 传感器失效
本文定义了6种传感器失效方式:
- 激光雷达视野受限(LF):由于不正确收集或部分硬件损坏,激光雷达只能从视野的一个部分获取数据;
- 物体丢失(MO):某些材料阻止激光雷达点反射;
- 光束减少(BR):由于能源或传感器处理能力受限导致;
- 视图丢失(VD):来自相机故障;
- 视图噪声(VN):来自相机故障;
- 障碍遮挡(OO):物体在相机视图中被遮挡。
此外,本文还考虑了两种严重的传感器缺失场景:相机丢失和激光雷达丢失。
3.4 切换模态训练
本文提出切换模态训练方法,在训练时按预定义的概率随机接收来自某一模态的输入,保证使用任意模态时均有较高精度。
4. 实验
4.2 在完整模态下的性能
实验表明,对于目标检测任务,在图像单一模态下,MetaBEV能大幅超过现有模型的性能;激光雷达单一模态和相机激光雷达多模态均能达到SotA相当的性能。对于BEV语义分割任务,MetaBEV在激光雷达单一模态和相机激光雷达多模态下均能大幅超越之前的方法。
4.3 传感器失效时的性能
传感器丢失时,过去的方法不能处理缺失的特征,本文将缺失的特征替换为全0值以保证网络能够输出预测结果。实验表明MetaBEV对模态丢失有更好的鲁棒性,特别是在缺失激光雷达的情况下,检测性能能大幅超越BEVFusion;在缺失相机的情况下,BEV分割性能能大幅超越BEVFusion。即使在相机丢失的情况下,MetaBEV也能超过激光雷达单一模态SotA模型的性能。
在传感器部分失效时,本文进行了两种评估方式:零样本测试和域内测试。对于前者,直接把训练模型在传感器部分失效的情况下进行测试;对于后者,则先在传感器部分失效的情况下进行训练,再进行测试。实验表明,MetaBEV能在两种测试方法上超过BEVFusion。
4.4 多任务学习的性能
在不加入MoE的情况下,MetaBEV的性能已经能达到SotA。加入两种MoE,性能均有提升,且RMoE比HMoE的提升更大。
4.5 消融研究
网络配置:首先寻找BEV进化解码器的最优结构,包括层的组合、采样点的数量和专家的数量。实验表明使用少量的交叉注意力层、少量的采样点就能达到足够的性能。此外,加入自注意力层也能提高性能,因为其捕捉了查询之间的相关性。在RMoE中,使用和分配更多的专家能达到更好的性能。
切换模态训练:与全模态训练相比,切换模态训练能大幅提高缺失模态时的性能,也能少量提高完全模态时的性能。
补充材料
7. 实施细节
7.2 传感器失效
- 视野受限(LF):只输入某一角度范围内的激光雷达点云。
- 物体丢失(MO):按概率丢弃来自物体的点。
- 光束减少(BR):选择来自激光雷达部分光束的点。
- 视图噪声(VN):为部分或全部视图图像添加随机噪声。
- 视图丢失(VD):随机丢弃部分视图并替换为全零输入。
- 障碍遮挡(OO):生成预定义掩膜并与图像视图进行alpha混合。
7.3 训练细节
为图像和激光雷达使用MMDetection3D中的标准数据增广;使用CBGS以平衡各类别。
在多任务训练时,在预训练的3D检测网络中插入分割头,并对整个网络进行微调。
使用切换模态训练方法训练时,平均设置各种模态组合的输入概率。