网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach[1]

第5章 回避算法(Avoidance-Based Algorithms)
对TCP拥塞控制学术文献的回顾可以发现,最初在1988年和1990年分别引入的TCP Tahoe和Reno机制与1994年开始的研究活动之间存在着明显不同,主要标志是引入了一种被称为TCP Vegas的替代方案,从而引发了大量比较研究和替代设计,并持续了25年以上的时间。
延伸阅读:
L. Brakmo, S. O’Malley and L. Peterson TCP Vegas: New Technique for Congestion Detection and Avoidance. ACM SIGCOMM ‘94 Symposium. August 1994. (Reprinted in IEEE/ACM Transactions on Networking, October 1995).
尽管截止目前所介绍的方法都将丢包视为拥塞信号,并试图在拥塞发生后对控制拥塞做出反应,但TCP Vegas采取了一种基于回避(avoidance-based) 的方法应对拥塞: 它试图检测吞吐率的变化来发现拥塞,并在拥塞严重到足以导致丢包之前调整发送速率。本章将介绍一般的"Vegas策略",以及随着时间的推移引入的三个不同的例子。这类研究的高潮是谷歌如今所倡导的BBR算法。
5.1 TCP Vegas
TCP Vegas背后的基本思想是根据测量的吞吐率和预期吞吐率的比较来调整发送速率。可以从图29中给出的TCP Reno图示中直观看到,最上面的图显示了连接的拥塞窗口,给出的信息与前一章相同。中间和底部的图描述了新的信息: 中间的图显示了在发送端处测量的平均发送速率,而底部的图显示了在瓶颈路由器处测量的平均队列长度,三个图在时间上是同步的。在4.5秒到6.0秒之间(阴影区域),拥塞窗口增加(上图),我们预计观察到的吞吐量也会增加,但实际上却保持不变(中图),这是因为吞吐量的增加不能超过可用带宽,超过可用带宽之后,任何窗口大小的增加只会导致占用更多的瓶颈路由器缓冲区空间(下图)。
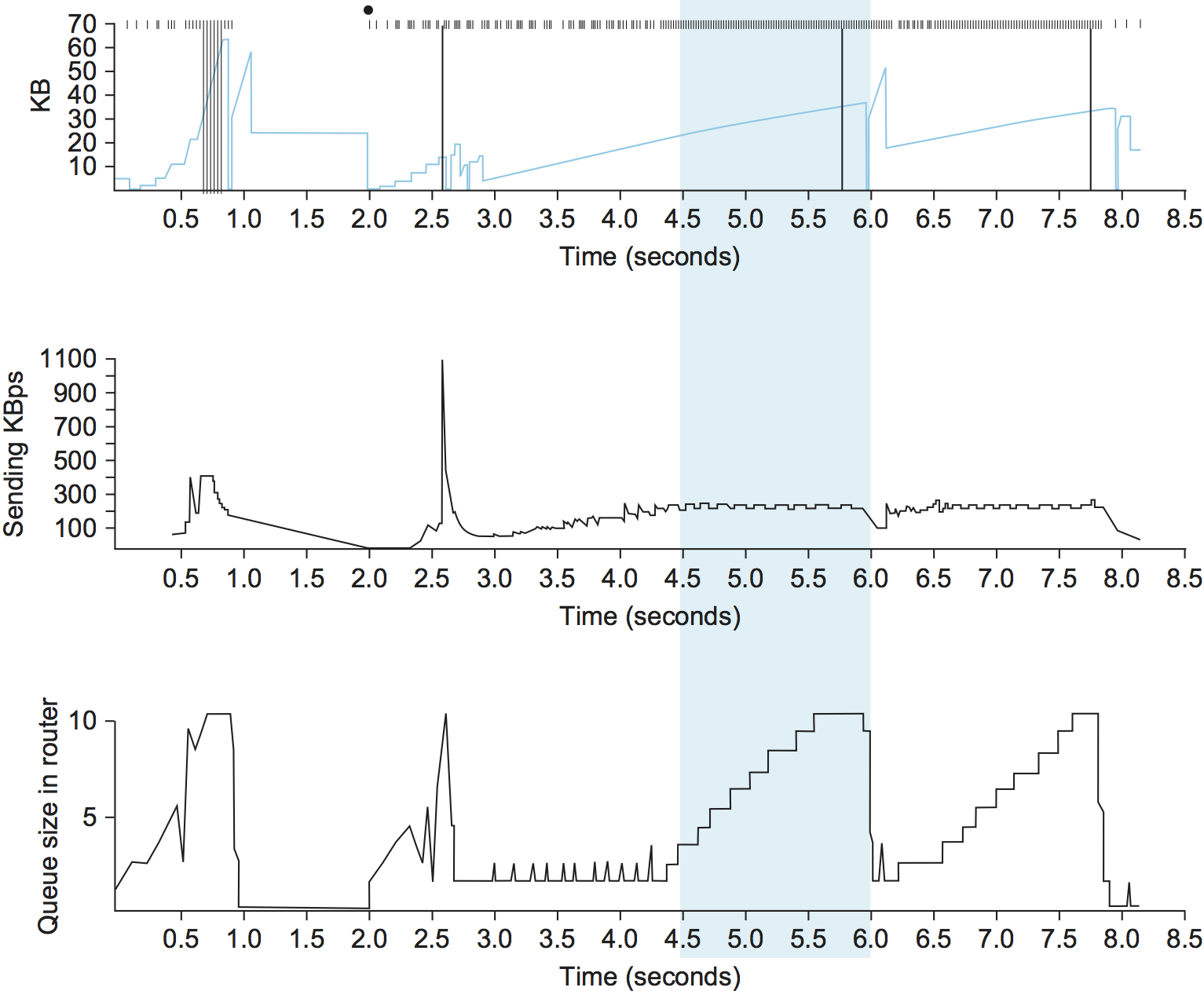
一个有趣的比喻可以用来描述图29中所示现象,即冰上驾驶。速度计(拥堵窗口)可能会显示速度是每小时30英里,但通过看车窗外面,看到步行经过你的人们(测量的吞吐率),你知道自己的速度不超过每小时5英里。在这种类比中,发动机无意义的空转就像发送的额外数据包一样,只是无用的停留在路由器缓冲区中。
TCP Vegas用这种思想来测量和控制连接传输中的额外数据量,这里的"额外数据"指的是如果发送端能够完全匹配网络可用带宽,就不会传输的数据。TCP Vegas的目标是在网络中维护"正确的"额外数据量。显然,如果一个发送端发送了太多额外数据,将导致长时间的延迟,并可能导致拥塞。不太明显的是,如果一个连接发送的额外数据太少,就无法对可用网络带宽的短暂增加做出足够快的响应。TCP Vegas基于估算网络中额外数据量的变化做出回避拥塞动作,而不仅仅基于丢包,接下来我们详细介绍这个算法。
首先,将给定流的BaseRTT定义为当流没有拥塞时数据包的RTT。在实践中,TCP Vegas将BaseRTT设置为测量到的所有往返时间的最小值,通常是在路由器由于该流造成队列增加之前,连接发送的第一个包的RTT。如果假设没有溢出连接,那么预期吞吐量为
其中CongestionWindow是TCP拥塞窗口,假设(为了这个讨论的目的)等于传输中的字节数。
其次,TCP Vegas计算当前发送速率ActualRate。计算方法是记录一个区分数据包(distinguished packet)的发送时间,记录从数据包发送到接收到它的ACK之间传输了多少字节,并当ACK信息到达时计算区分数据包的样本RTT,最后传输字节数除以样本RTT,此计算在每次往返时间中执行一次。
第三,TCP Vegas比较ActualRate和ExpectedRate并相应调整窗口。Diff = ExpectedRate - ActualRate,注意,根据定义,Diff为正或0。只有当测量样本RTT小于BaseRTT时,才会出现ActualRate > ExpectedRate的情况,如果发生这种情况,将BaseRTT改为最新采样的RTT。我们还定义了两个阈值,α < β,分别对应于网络中额外数据太少和太多的情况。当Diff < α时,TCP Vegas在下一个RTT期间线性增加拥塞窗口;当Diff > β时,TCP Vegas在下一个RTT期间线性减少拥塞窗口。当α < Diff < β时,TCP Vegas保持拥塞窗口不变。
直观来看,实际吞吐量与预期吞吐量之间的差距越远,网络中的拥塞就越大,意味着发送速率应该降低,β阈值就会触发发送率下降。另一方面,当实际吞吐率太接近预期吞吐率时,连接就会面临无法利用可用带宽的境地,α阈值就会触发发送率的增加。总的目标是在网络中保留的额外字节数介于α和β之间。
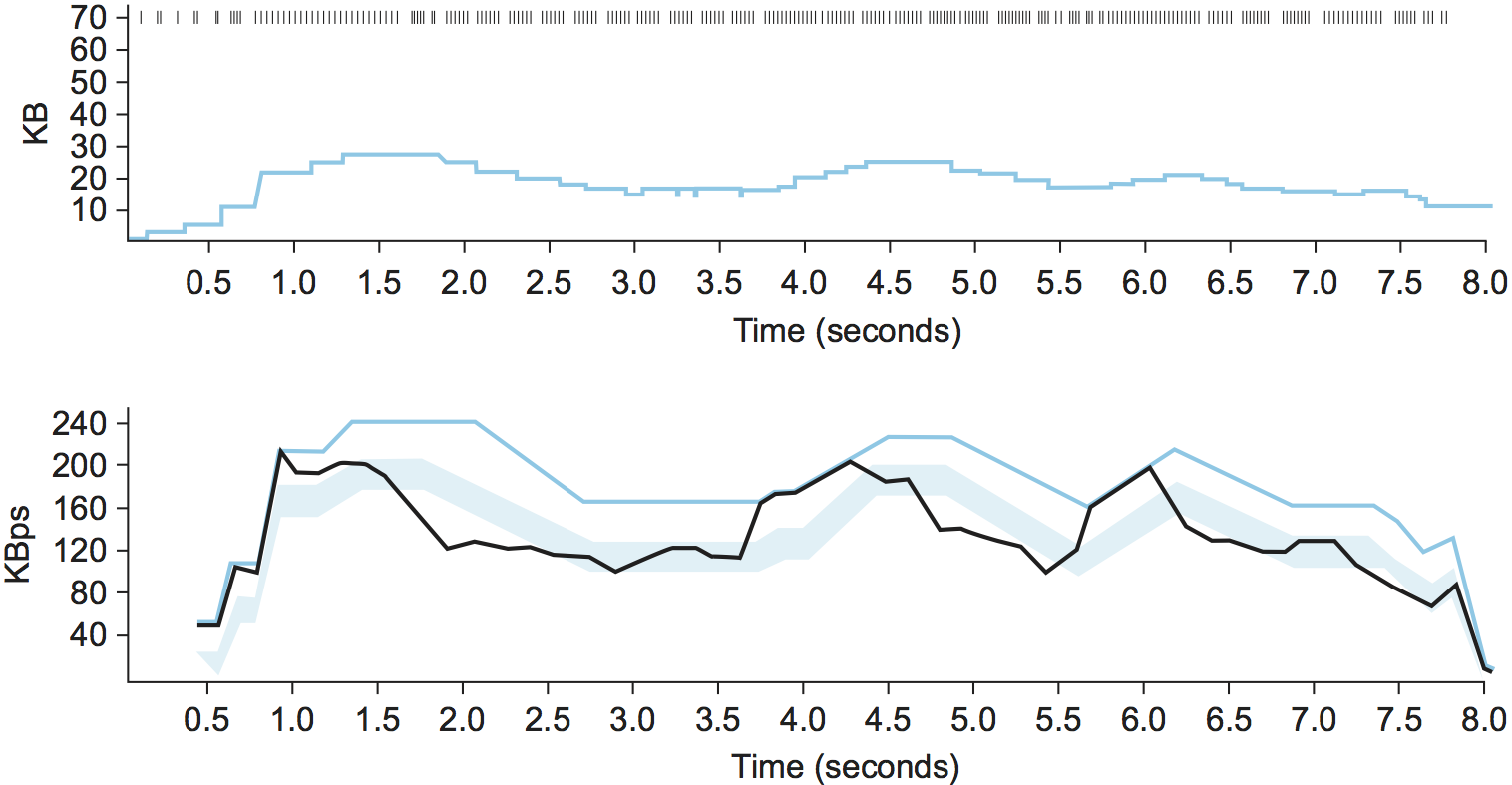
图30显示了TCP Vegas拥塞避免算法。上图显示了拥塞窗口,与本章给出的其他图示相同。下图显示了预期和实际的吞吐量,这决定了如何设置拥塞窗口。下图最能说明算法是如何工作的。彩色线显示了ExpectedRate,而黑线显示了ActualRate。阴影部分给出了α和β阈值区间,阴影带的顶部距离ExpectedRate有α KBps的距离,底部距离ExpectedRate有β KBps的距离,目标是将ActualRate保持在阴影区域内的这两个阈值之间。每当ActualRate低于阴影区域(即离ExpectedRate太远),TCP Vegas就会担心网络中有太多的包被缓冲,从而减少拥塞窗口。同样,每当ActualRate超过阴影区域(即太接近ExpectedRate),TCP Vegas就会担心网络没有被充分利用,因此会增加拥塞窗口。
由于刚才介绍的算法比较实际和期望吞吐量率与α和β阈值之间的差异,所以这两个阈值是按照KBps定义的。但是,考虑连接在网络中占用了多少额外的包缓冲区可能更准确。例如,在BaseRTT为100ms,数据包大小为1 KB的连接上,如果α = 30 KBps以及β = 60 KBps,那么可以认为α指定该连接需要在网络中占用至少3个额外的缓冲区,并且β指定该连接在网络中占用不超过6个额外的缓冲区。α和β的设置在Vegas第一次部署的实际环境中工作得很好,但正如下一节将会介绍的,这些参数将持续根据不断变化的环境进行调整。
最后,注意TCP Vegas以线性方式减少拥塞窗口,似乎与需要指数减少来确保稳定性的规则相冲突。这是因为TCP Vegas在超时发生时确实使用指数减少,刚才介绍的线性下降是拥塞窗口的早期下降,发生在拥塞发生以及数据包开始被丢弃之前。
5.2 不同的假设
为了响应不同网络的假设,TCP Vegas以及类似Vegas的拥塞回避方法已经随着时间的推移进行了调整。Vegas从未像Reno那样被广泛使用,所以这些修改通常更多的是由实验室研究而不是广泛的现实经验驱动的,但对算法的完善有助于我们对基于回避的算法的理解。我们在这里总结了其中一些见解,但在第7章中我们将继续介绍为特定用例定制拥塞控制算法的一般性主题。
5.2.1 FAST TCP
第一种受到Vegas启发的机制是FAST TCP,它对Vegas进行了改进,使其在具有大带宽时延积的高速网络上更加高效。其主要想法是在算法试图找到可用的"传输中"带宽(数据包在网络中被缓冲之前)的阶段更积极的增加拥塞窗口,然后在算法开始与其他流在瓶颈路由器上争夺缓冲区时表现的保守。FAST还建议将α值调整为大约30个包。
除了在具有大带宽时延积的网络中管理拥塞之外,保持流水线满也是一个实质性的挑战,关于FAST还有两个值得注意的事项。首先,TCP Reno和TCP Vegas都是基于直觉和大量试错的结果,而FAST是基于优化理论(后来这被用来解释为什么Vegas行得通)。其次,与我们所知的所有其他拥塞控制算法不同,FAST的实现只能作为专有的解决方案。
延伸阅读:
S. Low, L. Peterson, and L. Wang. Understanding TCP Vegas: A Duality Model. Journal of the ACM, Volume 49, Issue 2, March 2002.
5.2.2 TCP Westwood
虽然Vegas的动机是在发生丢包之前检测并避免拥塞,但TCP Westwood (TCPW)的动机主要是意识到数据包丢失并不总是拥塞的可靠指标。这在无线连接方面尤其明显,在Vegas被提出时这还是新鲜事物,但在TCPW出现时已经变得很普遍了。无线链路经常会因为无线信道上未纠正的错误而丢包,而这与拥塞无关,因此,需要用另一种方法检测拥塞。有趣的是,其最终结果与Vegas有些相似,TCPW还试图通过查看ACK返回成功交付的数据包的速率来确定瓶颈带宽。
当发生丢包时,因为还不知道丢包是由于拥塞还是由于链路相关,TCPW不会立即将拥塞窗口缩短一半,取而代之的是会估计在丢包发生之前流量的流动速度,这是一种比TCP Reno更温和的退让形式。如果丢包与拥塞相关,则TCPW应该以丢包前可接受的速率发送。如果丢包是由无线错误造成的,则TCPW不会降低发送率,并且还会开始再次提高发送率,以充分利用网络。其结果是一个在固定链接上类似于Reno,但在有损链接上性能获得了实质性提升的协议。
无线链路上拥塞控制算法的优化仍然是一个具有挑战性的问题,更复杂的是,WiFi和移动蜂窝网络具有不同的特性。我们将在第7章重新讨论这个问题。
5.2.3 New Vegas
最后一个例子是New Vegas (NV),它是对Vegas基于延迟的方法的一种适应,适用于链路带宽为10Gbps或更高的数据中心网络,其RTT通常在几十微秒内。这是我们在第7章将介绍的一个重要用例,当前的目标是建立一些直观感受。
为了理解NV的基本思想,假设我们为每个收到ACK的包绘制Rate与CongestionWindow的关系图。出于简化目的,Rate仅仅是CongestionWindow(以字节为单位)与被ACK(以秒为单位)的数据包RTT的比率。注意,为了简单起见,讨论中使用了CongestionWindow,而实际上NV使用的是传输中(未收到ACK)的字节。如图31所示,我们用竖条(而不是点)表示由于测量中的瞬时拥塞或噪声而导致的CongestionWindow值。
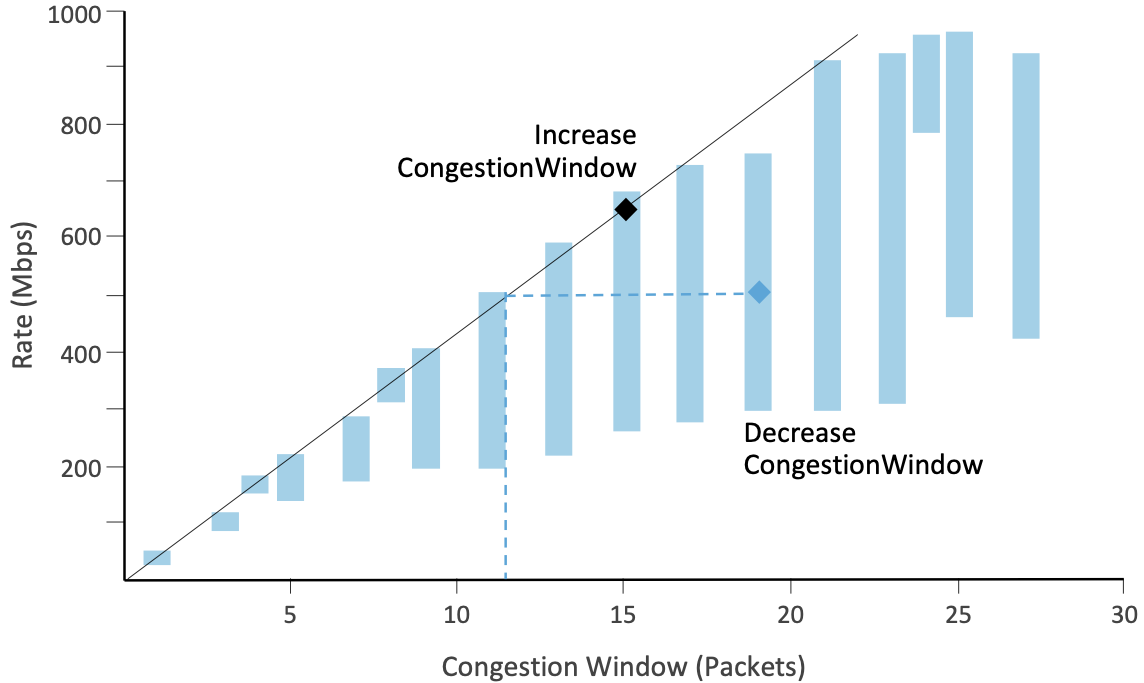
条形图顶部的最大斜率表示过去所能达到的最佳水平。在一个经过良好调整的系统中,条形图的顶端由一条穿过原点的直线作为边界。这个想法是,只要网络没有拥塞,每RTT发送的数据量增加一倍,速率就会增加一倍。
Rate和CongestionWindow的新测量值可以落在边界线附近(图中的黑色菱形)或下面(图中的蓝色菱形)。在该直线上方的测量会导致NV通过增加其斜率来自动更新该直线,因此测量结果将落在新直线上。如果新的度量值接近这条线,那么NV会增加CongestionWindow。如果测量值低于这条线,那就意味着和之前较低的拥塞窗口类似的性能。图31所示示例中,我们看到了与CongestionWindow=12类似的性能,所以减少了CongestionWindow。在新的测量有噪声的情况下,这种降低是指数级的,而不是瞬间的。为了过滤掉不好的度量值,NV收集了许多度量值,然后在做出拥塞判断之前使用最好的度量值。
5.3 TCP BBR
BBR(Bottleneck Bandwidth and RTT)是谷歌研究人员开发的一种新的TCP拥塞控制算法。像Vegas一样,BBR是基于延迟的,意味着它试图检测缓冲区的增长,以避免拥塞和丢包。BBR和Vegas都使用最小RTT和观察到的瓶颈带宽(根据一段时间间隔计算)作为主要控制信号。
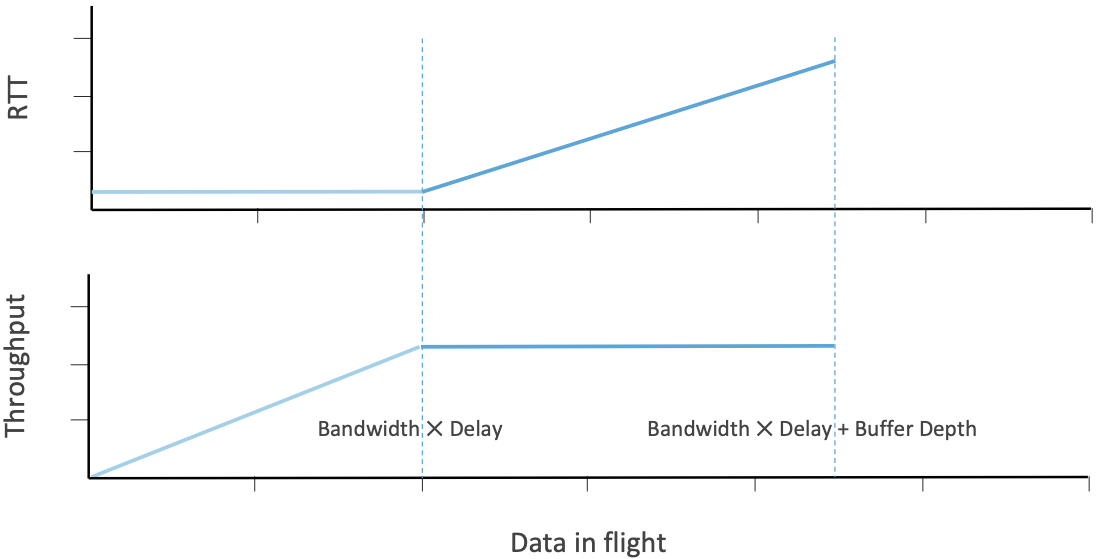
图32显示了BBR的基本思想。假设某个网络的瓶颈链路还有一些可用带宽和队列容量,随着拥塞窗口打开,更多的数据被发送,最初由于瓶颈未满,延迟没有增加,吞吐量会增加(下图)。然后,一旦速率达到瓶颈带宽,就开始填充队列。此时,RTT上升,但没有观察到吞吐量上升,这是拥塞阶段的开始。这个图表实际上是我们在图29中4.5到6.0秒时间框架中看到的简化版本。
像Vegas一样,BBR的目标是准确确定队列刚刚开始填充的那个点,而不是像Reno那样一直持续到填满缓冲区并导致丢包。BBR的很多工作都是围绕着提高定位最佳点的机制的灵敏度,其中有许多挑战: 测量带宽和延迟是有噪声的;网络条件是动态的;以及在与BBR和非BBR流竞争带宽时对公平的长期追求。
与其他方法相比,BBR的一个显著特点是不完全依赖于CongestionWindow来决定有多少数据被传输。值得注意的是,BBR还试图平滑发送者将数据送入网络的速率,以避免会导致过度排队的突发峰值流量。理想条件下,我们希望以完全符合瓶颈的速度发送数据,从而在不造成队列堆积的情况下实现尽可能高的吞吐量。虽然大多数TCP变体使用ACK到达来触发数据的发送,从而确保传输中未确认数据的数量保持不变,但BBR创建了瓶颈带宽的估算,并使用本地调度算法以该速率发送数据。ACK在更新有关网络的状态方面仍然发挥着重要作用,但并不直接用于调整传输速度,这意味着延迟的ACK不会导致传输量的突然爆发。当然,CongestionWindow仍然用于确保可以发送足够的数据以保持流水线满,并确保传输中的数据量不会比带宽延迟积大太多,从而避免队列溢出。
为了维护当前RTT和瓶颈带宽的最新视图,有必要在当前估计的瓶颈带宽上下持续探测。由于竞争流流量的减少、链路属性(如无线链路)的变化或路由的变化,也许可以获得更多带宽。如果路径变化了,RTT也有可能会变。为了检测RTT的变化,需要发送更少的流量,从而清空队列。为了检测可用带宽的变化,需要发送更多的流量。因此,BBR在其当前估计的瓶颈带宽的上下同时探测,如果有必要,会更新估算,并相应更新发送速率和CongestionWindow。
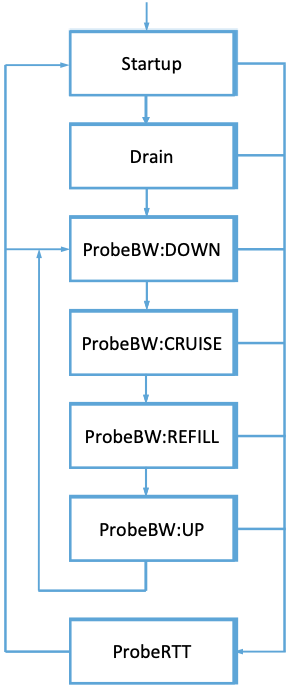
图33的状态图显示了顺序探测可用带宽和最小RTT的过程。在尝试建立路径上的可用带宽的激进启动阶段之后,降低发送速率以清空队列,然后算法进入图的内环,在内环中,定期检查在较低发送速率下是否有更低的延迟,或者在较高发送速率下是否有更高的吞吐量。在一个相对较长的时间范围内(几秒),算法进入ProbeRTT状态,将其发送速率降低两倍,以完全清空队列并测试是否有更低的RTT。
该方法有趣的地方在于,当一个大流在ProbeRTT状态下显著降低发送速率时,该流对队列延迟的贡献将下降,这将导致其他流同时看到一个新的、更低的RTT,并更新它们的估算。因此,当队列实际上是空的或接近空的时候,流表现出同步RTT估算的趋势,从而提高了估算的准确性。
BBR正在积极开发并在快速发展中,撰写本文时最新版本是2。其主要焦点是公平,例如,一些早期实验表明,CUBIC流在与BBR流竞争时获得的带宽减少了100倍,而其他实验表明,BBR流之间可能存在不公平性。BBR版本1对丢包不敏感,特别是当路径上的缓冲量相对较低时,可能会导致较高的丢包率。由于BBR的几种实现现在正在不同环境中进行试验,包括在谷歌的内部主干网以及更广泛的互联网中,人们正在收集经验来进一步完善设计。IETF的拥塞控制工作组正在主持关于正在进行的设计和实验的讨论。
延伸阅读:
N. Cardwell, Y. Cheng, C. S. Gunn, S. Yeganeh, V. Jacobson. BBR: Congestion-based Congestion Control. Communications of the ACM, Volume 60, Issue 2, February 2017.
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
TCP Congestion Control: A Systems Approach: https://tcpcc.systemsapproach.org/index.html
本文由 mdnice 多平台发布