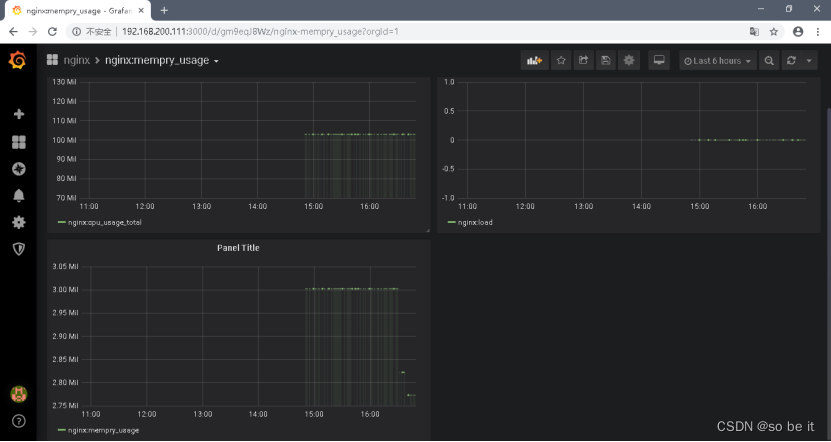
SparkSQL主要通过Antlr4定义SQL的语法规则,完成SQL词法,语法解析,最后将SQL转化为抽象语法树。所以有必要先了解下Antlr4的工作流程。
ANTLR4是什么?
ANTLR 是 ANother Tool for Language Recognition 的缩写,官网:https://www.antlr.org/
它是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件。
包括:自动生成词法分析器 (Lexer)、语法分析器 (Parser) 和树分析器 (Tree Parser)。
词法分析器(Lexer):词法分析器的工作是分析量化那些本来毫无意义的字符流,将他们翻译成离散的字符组(也就是一个一个的Token),供语法分析器使用。
语法分析器(Parser):语法分析器将把收到的Tokens组织起来,并转换成语法规则定义的所允许的结构。
树分析器 (tree parser):树分析器可以用于对语法分析生成的抽象语法树进行遍历,并能执行一些相关的操作。
解析流程图:

-
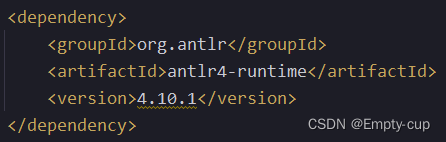
IDEA新建maven工程,导入如下依赖,注意antlr版本和安装的antlr插件版本保持一致。
-
使用 ANTLR 的专门语法写一个简单的词法语法解析文件,并根据此文件自动生成相关词法语法解析的java文件。
将编写的文件放到resources文件夹下,实现一个简答的数字加法功能:AddExpr.g4grammar AddExpr; // parser stat : expr; //定义表达式 :expr 表达式可以是数字(INT),也可以是加法运算表达式 expr : expr op='+' expr # AddSub | INT # int ; //lexer INT : [0-9]+ ; // 运算数为整数的任意组合 ADD : '+' ; //加法在编写的AddExpr.g4文件上右键,选择 Configure ANTLR

填写代码生成的位置和包名
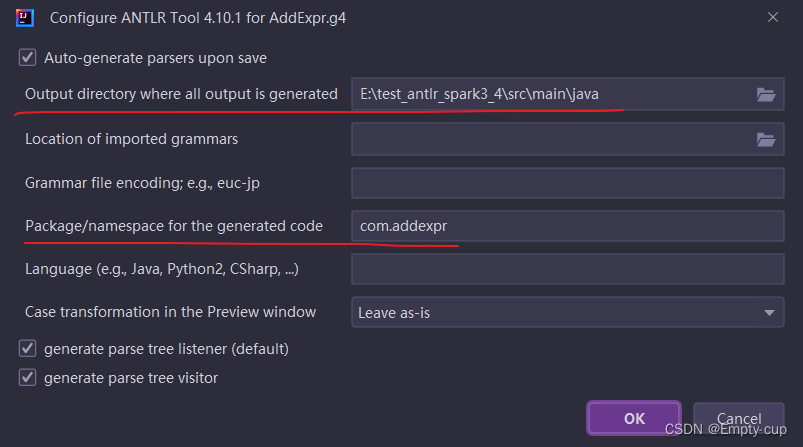
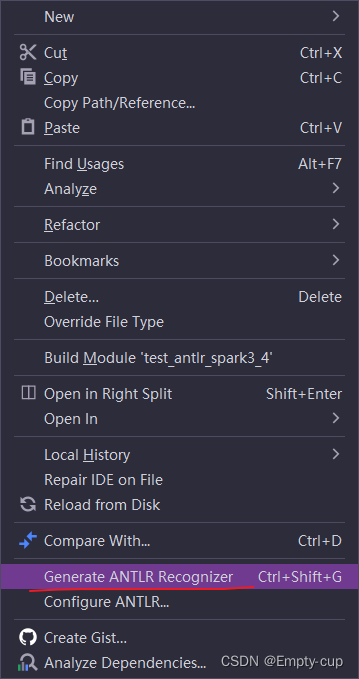
在编写的AddExpr.g4文件上右键,选择 Configure ANTLR Recognizer,就会在配置好的目录下生成代码了。
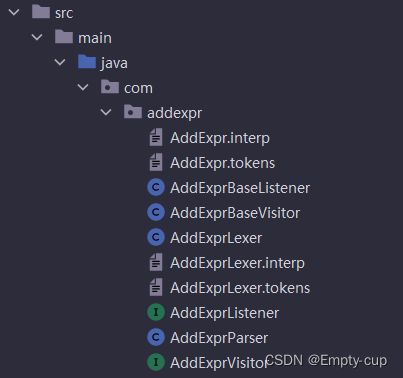
-
在test文件夹下建一个测试文件,以测试刚才生成的java代码
AddExprTestimport com.addexpr.AddExprBaseVisitor; import com.addexpr.AddExprLexer; import com.addexpr.AddExprParser; import org.antlr.v4.runtime.ANTLRInputStream; import org.antlr.v4.runtime.CommonTokenStream; import org.antlr.v4.runtime.tree.ParseTree; public class AddExprTest { public static void run(String expr) { //对每一个输入的字符串,构造一个 ANTLRStringStream 流 in ANTLRInputStream in = new ANTLRInputStream(expr); //用 in 构造词法分析器 lexer,词法分析的作用是产生记号 AddExprLexer lexer = new AddExprLexer(in); //用词法分析器 lexer 构造一个记号流 tokens CommonTokenStream tokens = new CommonTokenStream(lexer); //再使用 tokens 构造语法分析器 parser,至此已经完成词法分析和语法分析的准备工作 AddExprParser parser = new AddExprParser(tokens); //最终调用语法分析器的规则 stat,完成对表达式的验证 ParseTree tree = parser.stat(); System.out.println("------------------AstTree-------------------"); System.out.println(tree.toStringTree(parser)); //遍历语法树--返回null AddExprBaseVisitor<Integer> visitor = new AddExprBaseVisitor<>(); visitor.visit(tree); System.out.println(visitor.visit(tree)); //原生的visitor遍历树结果返回null,并不是想要的结果,需要自定义重新实现 //MyAddVisitor类就对应SparkSQL中的ASTBuild类 MyAddVisitor myAddVsitor = new MyAddVisitor(); System.out.println(myAddVsitor.visit(tree)); } public static void main(String[] args) { String s = "1+2"; run(s); } } -
从代码运行结果中可以看出,原生的visitor遍历树结果返回null,并不是想要的结果,实际使用过程中,需要自定义重新实现visitor遍历方法,实际上,Spark源码中也是做的重新实现。代码中的 MyAddVisitor 类就对应SparkSQL中的 ASTBuild 类,就是自定义的实现类。代码如下:
MyAddVisitor
import com.addexpr.AddExprBaseVisitor; import com.addexpr.AddExprParser; /** * 自定义的Visitor实现类 */ public class MyAddVisitor extends AddExprBaseVisitor<Integer> { @Override public Integer visitStat(AddExprParser.StatContext ctx) { return visitChildren(ctx); } @Override public Integer visitAddSub(AddExprParser.AddSubContext ctx) { Integer left = visit(ctx.expr(0)); //获取左边表达式最终值 Integer right = visit(ctx.expr(1)); //获取右边表达式最终值 return left + right; } @Override public Integer visitInt(AddExprParser.IntContext ctx) { return Integer.parseInt(ctx.INT().getText()); } }