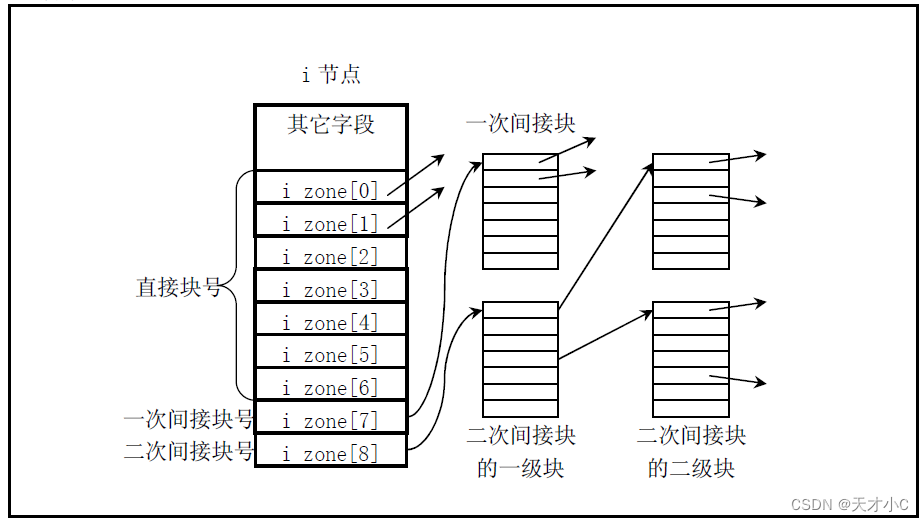
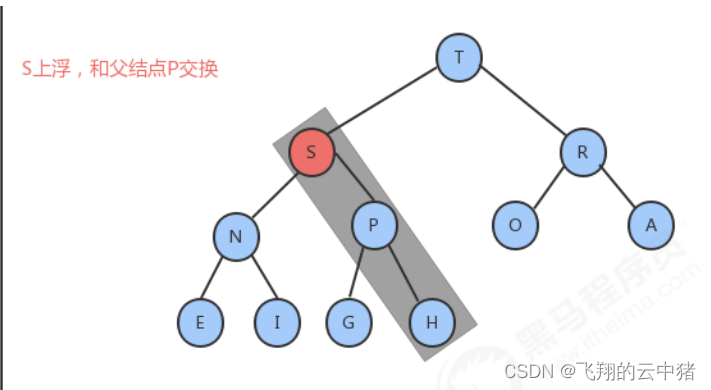
近年来,人工智能在自然语言处理(NLP)领域经历了更大的发展或突破——而“变形金刚”是这场革命背后的不那么秘密的新技术。转换器与传统方法(如递归神经网络或卷积神经网络)之间的主要区别在于,转换器可以同时处理输入文本的每个单词。变形金刚在各种NLP任务中令人印象深刻的表现得益于一种新颖的注意力机制,该机制通过计算位置和基于内容的注意力分数来捕获序列中单词之间有意义的相互依赖关系。
受到NLP中注意力机制表现的启发,研究人员探索了将它们应用于视觉任务的可能性。谷歌大脑团队研究员Prajit Ramachandran提出,自我注意层可以完全取代视觉任务中的卷积层,并实现最先进的性能。为了证实这一理论,洛桑联邦理工学院(EPFL)的研究人员提出了理论和经验证据,表明自我注意层确实可以实现与卷积层相同的性能。
从理论角度来看,研究人员使用建设性证明表明,多头自我注意层可以模拟任何卷积层。
研究人员设置了多头自注意层的参数,使其可以像卷积层一样工作,并进行了一系列实验来验证所提出的理论结构的适用性,将包含六个多头自注意力层的全注意力模型与CIFAR-18数据集上的标准ResNet10进行比较。
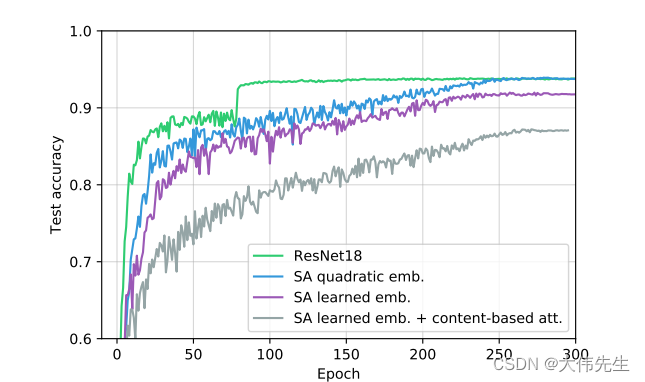
在测试中,自我注意模型表现相当不错,除了基于内容的注意力的学习嵌入 - 这主要是由于参数数量的增加。然而,研究人员证实,在理论和经验的支持下,任何卷积层都可以用自我注意层来表达,并且完全注意模型可以学习根据输入内容将局部行为和全局注意力结合起来。
论文《关于自我注意和卷积层之间的关系》发表在arXiv上。