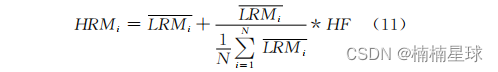文章目录
- 引言
- 论文翻译
- Abstract
- 问题
- Introduction
- 第一部分
- 问题
- 第二部分
- 问题
- Model Architecture网络结构
- 第一部分
- 问题
- 第二部分
- 问题
- Experiments实验
- 问题
- Conclusion结论
- 问题
- 总结
- 参考
引言
- 这篇文章,是《PixelSNAIL:An Improved Autoregressive Geenrative Model》主要应用到的三个技术之一,我正在复现这篇文章,需要了解一下PixelSNAIL这个序列预测生成的模型。
- 这篇文章是2017年的,属于近五年的文章,并且来自于Proceedings of Machine Learning Research, PMLR,是一篇顶会,是CCF-A类文章。
- 出于学习的目的,这里还是翻译一下这篇文章。
- 自注意力机制:可以获得任何时间信息,但是只能获取少量的信息
- 因果卷积:可以获得任意数量的信息,但是只能获取的附近上下文的信息,范围有限。
- 两者完美结合,实现互补。
论文翻译
Abstract
- 自回归模型在密度估计任务中效果一直都很棒,尤其是针对图片或者音频等高维度数据的生成。自回归模型是将密度估计看作是序列建模任务,也就是使用递归神经网络(RNN)对下一个元素的条件分布进行建模,这个条件分布是基于之前所有的元素的。这类问题中,难点是如何设定RNN,使之能够有效地对长路径依赖进行建模。最常见的方法是使用因果卷积,因果卷积能够更好地访问序列中靠前的数据。受到最近兴起的元强化学习在处理长范围依赖方法的启发,我们引入因果卷积和自我注意力机制相结合的新的生成模型架构。在这篇文章中,我们展示了最终的训练模型,并且展示了最新的对数似然结果,分别是在CIFAR-10和ImageNet两个数据集上进行展示的。
问题
-
元强化学习?
- 含义:元强化学习(Meta Reinforcement Learning)是通过在多个任务上的经验,使得智能体能够在新任务上迅速学习和适应。
- 特点:
- 学习如何学习:该学习方法不仅仅是学习一个特定任务的策略,是学习如何在新任务上快速学习策略
- 快速适应:智能体能够在看到新任务的少量数据后,能够快速适应
- 常见算法:MAML(Model-Agnostic Meta-Learning)、Reptile和PEARL(Probabilistic Embeddings for Actor-Critic Reinforcement Learning)
-
因果卷积网络?
- 含义:任何时间点的输出仅仅以来于该时间点之前的输入,不依赖于未来的输入,确保了输出和过去输入的因果函数。
- 常规卷积: 如下图,timeA的这一列的最后的节点,是可以获取的timeB和timeC两列节点的信息,正常的时间顺序应该是timeA > timeB > timeC的顺序,后两者的顺序对于timeA而言,是未来的事件,不应该获得来自未来的信息,所以并不适合序列推列。
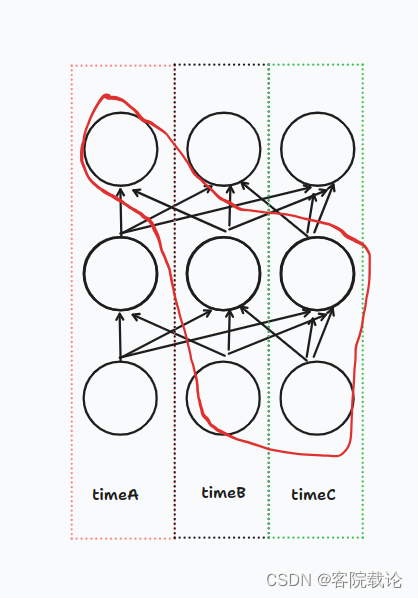
- 因果卷积:不同于因果卷积,这里的每一层神经元并不是全连接的,当前节点的数据来源,只能是发生在当前时间点之前的数据。过去可以影响现在,但是未来并不能影响现在。
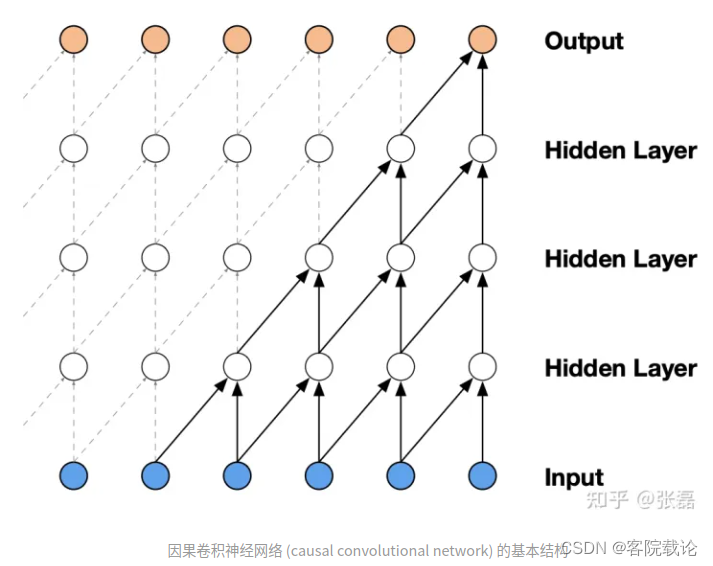
- 具体实现:因果卷积 可以通过适当的填充来实现,对于一维卷积,通过输入序列左侧添加适当数量的零;对于二维卷积,可以使用掩码卷积,根据中心元素进行分割。具体可以看这篇链接
- 扩展:在我所找到的博客中,他还使用了孔洞卷积,也就是膨胀卷积,来增加卷积的感受野,卷积层能够获得尽可能多的未来数据。
-
自注意力机制?
- 含义:自注意力机制允许模型在处理一个序列的时候,对序列中每一个元素分配不同的注意力权重,可以根据每一个元素的上下文来决定他应该给予多少关注。
- 目前这个有点难懂,找机会花时间,找视频好好看看
Introduction
第一部分
-
在高维度数据上的自回归生成模型能够将联合分布拆解成条件分布的乘积。
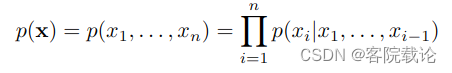
-
然后使用一个循环神经网络对特定的某一个条件分布 p ( x i ∣ x 1 : i − 1 ) p(x_i|x_{1:i-1}) p(xi∣x1:i−1)进行模拟。这个模拟可以给予额外的全局信息 h h h,如果是生成图片,这个 h h h就是类别标签,然后条件分布 p ( x i ∣ x 1 : i − 1 ) p(x_i|x_{1:i-1}) p(xi∣x1:i−1)可以表示为 p ( x i ∣ x 1 : i − 1 , h ) p(x_i|x_{1:i-1},h) p(xi∣x1:i−1,h)。这种方法效果不错,能够对复杂的依赖关系进行建模。比起GAN,神经自回归模型能够有效地计算似然值,并且训练起来相对容易一些,在某些任务或者是数据集上,神经自回归模型的效果是超过了潜变量模型。
-
我们设计的核心考虑点就是用来实现循环神经网络(RNN)的网络模型,要能有效调用序列中早期的数据。常见的解决办法如下
- 传统的RNN,,比如说GRU或者LSTM:这些算法将信息保存在隐藏状态中,然后在训练的过程中,将之传播到下一个状态。他们这种基于时间的线性依赖性,严重限制了他们对于数据中长依赖的获取。
- 因果卷积:直接对序列数据使用卷积,通过掩码或者转换,使得对于当前数据的预测仅仅会被之前的数据影响。同时,他们能一次性处理更多的数据,也就是说能够接触更多的过去的数据,考虑的更加全面。但是他们的感受野尺寸有限,并且感受野周围的信息衰弱的会更加明显。
- 自我注意力机制:这种方法是将序列转成无序键值对进行保存,同时又可以基于内容进行查询检索。他们的感受野是没有边界的,并且可以实现无衰减的访问时间比较久远的信息。这个刚好弥补了因果卷积的缺点。但是,他们仅仅只能精确访问少量信息,而且需要通过额外的机制,将具体信息和位置信息进行结合。
问题
-
联合分布如何拆解成条件概率分布
- 下文是使用条件概率公式进行拆解的,最终的联合分布是若干个条件分布的累乘

- 下文是使用条件概率公式进行拆解的,最终的联合分布是若干个条件分布的累乘
-
为什么自回归模型比起GAN之类的模型能够更好地计算似然值
- 对于自回归模型而言,他的似然函数就是分解之后的条件概率,他的目标就是让最终的条件概率的累乘结果最大。对于每一个数据,我们只需要计算其在给定前面数据点的条件下的概率即可。
- 对于GAN模型而言, 他并不是直接优化和计算似然函数,而是通过对看过程训练生成器和判别器。
-
为什么传统RNN无法处理长序列数据
- 因为传统RNN在处理非常长的序列时,会出现梯度消失和梯度爆炸的问题,影响模型的训练。
- RNN的特点是在时间步骤上是顺序的,每一个时间步骤必须在前一个时间步骤完成后进行,并行十分困难,并不是擅长处理长序列的数据。
第二部分
- 因果卷积和自注意力机制彼此的优势和劣势是互补的:因果卷积一次能处理很多的数据,但是仅限于局部时间内的上下文数据。但是自注意力机制能够访问任意时间范围内的上下文,但是只能访问少量的数据。将两者结合,效果最好,同时利用因果卷积的高带宽访问和自注意力机制的长范围访问。整个模型能够访问任何有效的数据,并且没有数量和范围的限制。
- 具体的合并过程是这样的:卷积是将数据进行聚合,来创建一个上下文,然后在进行注意力查找。这种方法被称为SNAIL,最开始是用在元学习上的,而且效果还不错。主要是因为在元学习中,获取长期时间依赖十分重要,因为智能体的很多决策都是建立在过去的经验上的,SNAIL又刚好解决了这个问题。
- 在这个文章中,我们也是将相同的想法应用在自回归生成模型上,因为对于自回归生成模型而言,关难点也是获取过去的数据。基于当前生成模型的最先进的技术——PixelCNN,我们提出了新的网络架构,也就是PixelSNAIL,他就是结合SNAIL技术,并应用在CIFAR-10和ImageNet数据集上,取得了最好的生成效果。
问题
- 元学习是干什么的?
- 含义:学会学习,目标是设计模型能够快速适应新任务,即使只有少量的数据。元学习是关于如何更好地训练模型,是其能够更快地学习新任务。
- 特点
- 快速适应新任务:传统的机器学习模型需要大量的数据训练,才能完成任务。但是元学习只需要少量样本就能快速适应新的数据
- 训练和测试阶段:不同于传统的机器学习,仅仅只需要学习单个任务。元学习在训练阶段会同时接触多个任务,主要是学习如何快速从一个任务迅速转移到另外一个任务。测试阶段会接触一个新的任务,快速适应对应的知识。
- 模型结构:有两个部分,一个是学习如何学习的部分,另外一个是针对特定任务进行学习的部分
Model Architecture网络结构
第一部分
- 在这部分,我们主要是介绍PixelSNAIL的网络结构。主要由两个模块构成,具体见图一,描述如下。
- 每一个残差模块由若干个卷积层构成,并且都有残差链接。为了实现因果性,对卷积层进行掩码操作,使得当前的像素只能处理左边以及上边的像素。我们使用门激活函数(gate activation function)。在整个模型中,我们每一个残差模块是4个卷积层,每一个卷积层是256个卷积核。
- 一个注意力模块执行的是单键值对查找。这个模块会将数据映射到较低的维度中,然后在使用低维度的数据生成键值对,借此来减少计算复杂性,并获取输入的重要特征,然后使用soft-max函数来计算 注意力(注意,在这个模块还使用了掩码机制,使得当前的像素仅仅只会关注之前生成的像素)。我们使用的key的维度是16位,value的维度是128位。
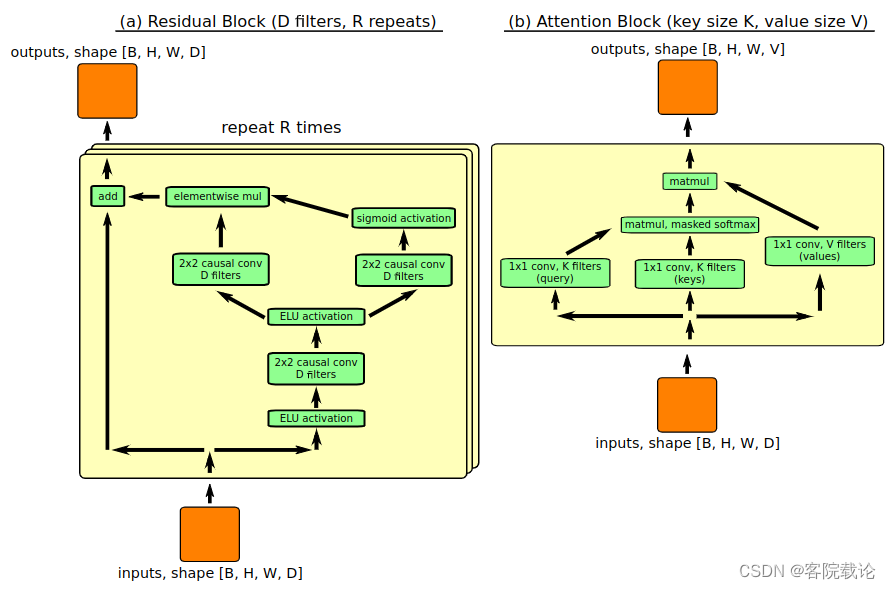
- 上图的两个模块构成了PixelSNAIL,左边是残差模块,总共是256个滤波器,然后有4个模块了;右边是注意力模块,键的维度是16,然后值的维度是128
问题
-
门激活函数(gate activation function)
- 含义:并不是特定的激活函数,在深度学习和神经网络中,用来控制信息流的机制
- 作用:在处理序列数据时,不是所有的信息都是 同等重要的。门激活函数允许模型有选择性的控制信息的流动,对于捕捉和记忆长期依赖关系十分有用
-
自注意力机制中的键值对如何生成?如何作用的?
- 将输入进行线性投影:分别将输入序列应用到三个不同的线性变换中,生成三个矩阵分别是查询Q、键K和值V,计算这三个矩阵分别有对应的权重矩阵
- Q = X ∗ W Q Q = X * W_Q Q=X∗WQ
- K = X ∗ W K K = X * W_K K=X∗WK
- V = X ∗ W V V = X * W_V V=X∗WV
- 计算注意力分数:这里计算 Q Q Q和 K K K的权重矩阵点乘来计算注意力分数
- 应用激活函数:对注意力分数使用softmax函数来计算权重矩阵 W e i g h t Weight Weight
- 加权求和:使用上面的权重矩阵 W e i g h t Weight Weight和价值矩阵 V V V的点乘,作为最红的输出
- 效果:使得模型在每一个位置都考虑到整个序列的信息,从而捕捉长距离的依赖关系
- 将输入进行线性投影:分别将输入序列应用到三个不同的线性变换中,生成三个矩阵分别是查询Q、键K和值V,计算这三个矩阵分别有对应的权重矩阵
第二部分
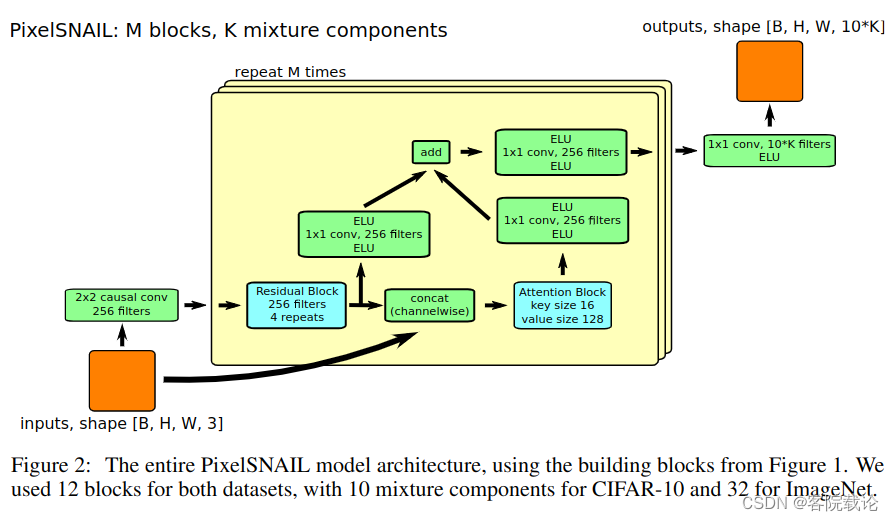
- 图2展示了完整的PixelSNAIL的网络结构,他是整合了残差模块和注意力模块。在CIFAR-10的数据集中,每一个残差模块后的第一个卷积层都有一个dropout层,会将一半的数据进行失活,主要是防止模型过拟合,因为数据太少了。在ImageNet中,就没有使用任何的dropout,因为数据集很大,不用担心过拟合。
- 在两个数据集上,我们使用了Polyak平均法对训练参数进行平均。对于CIFAR-10,使用了0.99995的指数移动平均权重,对于ImageNet,我们使用了0.9997的权重。作为输出分布,我们使用了离散化logistics混合,其中CIFAR-10用了10个混合组件,ImageNet用了32个组件,为了预测子像素的值,我们使用了线性自回归参数化方法。
问题
-
为什么要对训练参数进行平均?
- 参数平均的原因
- 提升模型的稳定性,参数初始化时,参数的波动会比较大,对参数进行平均,可以减少波动。
- 平滑损失曲线 ,平均过后的参数,损失值变化会更小,曲线更加平滑
- 提高泛化性能,这部分是通过实验发现的
- 减少噪声的影响,通过平均的参数,对于噪声的抑制能力会更强
- 参数平均的原因
-
指数移动平均权重是为了什么?
- 含义:这个简称为EMA,是前一个epoch的指数平均值和当前参数的值的加权和。

- 含义:这个简称为EMA,是前一个epoch的指数平均值和当前参数的值的加权和。
-
离散化的logitics混合组件是干什么的?
- 什么是混合模型:通过组合多个简单的分布来逼近复杂的数据分布
- logitics混合组件:通过多个简单的logistics分布(逻辑分布)来逼近复杂的分布。
- 作用:
- 表示多模态分布、逼近复杂分布、更好的似然估计
-
线性自回归参数化方法是干啥的?
- 含义:使用线性模型来预测像素值,基于其邻近像素或在某个结构中的其他的像素。
Experiments实验
- 在表格3中,我们提供了PixelSNAIL在CIFAR-10和ImageNet上的负对数似然结果,我们将PixelSNAIL和其他一些自回归模型进行比较。其他模型包括,PixelRNN(基于LSTM),PixelCNN和PixelCNN++(仅仅使用因果卷积)还有ImageTransformer(仅仅使用了自注意力机制)。PixelSNAIL的效果最好,这表明将这两个结构进行组合,效果确实不错。

- 表格1,展示了在CIFAR-10和ImageNet两个数据集上的几种不同方法的负对数似然结果,PixelSNIAL的效果是比其他仅仅使用因果卷积或者是自注意力机制的要好。
问题
- 负对数似然结果(negative log-likehood results)有什么用
- 含义:评估生成模型性能的常用指标,尤其是针对图像生成模型,越小越好。
- 计算过程
- 模型预测:模型对于给定的输入,会预测下一个像素或者下一部分的分布。每一个像素一般都是一个概率值。
- 获取真实值的概率:概率分布中,真实值的概率
- 计算对数似然:计算当前像素的对数似然,并且取负数。
- 计算整个图像的NLL:计算每一个像素的NLL,并进行求和。
- 平均NLL:对于一个数据集而言,就是计算每一个图片的NLL,然后累加求和,在求平均。
Conclusion结论
- 我们引入了PixelSNAIL,这是一种自回归生成模型,他将因果卷积和自注意力机制进行结合。我们验证了模型在CIFAR-10和ImageNet上性能,并且将项目公开在github上,链接。
- 虽然自回归神经网络的似然度很好计算,并且在很多场景下都很有效,但是他有一个明显的缺陷就是生成很慢,主要是每一个像素必须顺序生成。PixelSNAIL的生成速率和其他的采样速率都很慢。所以设计一个模型能够快速采样并且性能有很好的,始终是一个问题。
问题
-
注意力机制、空间注意力、通道注意力、混合注意力四者有什么区别?
- 传统注意力机制:通常用于序列数据、例如文本或者时间序列。
- 空间注意力机制:专门用于图像或者其他的空间数据,允许关注图西那个的某些特征区域。
- 通道注意力机制:在处理多通道数据时,允许模型关注特定通道的数据
- 混合注意力机制:通道和空间注意力机制的混合,同时关注通道和空间。
-
注意力机制的核心
- 允许模型动态地为其输入分配不同的权重,关注更加重要的部分。
总结
- 较之于以往常见的PixelCNN,PixelSNAIL就是在PixelCNN的基础上,增加了一个自注意力机制,来弥补因果卷积的只能感知有限上下文的缺点。将这两者进行结合,就可以实现感受野不受影响,并且获取数据量很大的两个特点。使得模型的预测结果更加准确。
- 通过这个模型,可以学一下具体的自注意力机制是如何实现,不同于之前实现过的空间注意力机制、通道注意力机制以及混合注意力机制。
参考
- chatGPT -WebBrowser模式,链接
- 因果卷积神经网络 —— 专为时间序列预测而设计的深度学习网络结构