-
我国自改革开放以来,大力发展工业和经济,对电能同样有着巨大的需求,所需求的电能不仅需要保证其数量,还要保障其质量,因此对整个电力系统安全稳定的运行也提出了更高的要求,电力系统发生故障要实时检测并及时排除,避免造成严重的安全事故和经济损失.
-
我国输电线路巡检基本以人工巡检方式为主,但传统的人工巡检方式效率低,限制多,还往往会消耗大量的人力物力,后来引入直升机沿线巡检的方法,但该方法飞行作业十分危险且培训及维护费用极其昂贵,无法在很大程度上缓解人工巡检带来的问题。
-
最近几年,GPU 计算能力不断提升,越来越多研究者选择将机器视觉技术与深度学习算法相结合进行目标检测算法技术的研究及应用,因此机器视觉技术的应用场景也越来越丰富。比如人脸识别、自动驾驶、医学图像分析,甚至在各种工业机器人中也搭载了目标检测算法,电气领域也不例外,在变电站和输电线路巡检的工作中,也有不少得益于目标检测算法。
-
YOLOX 是由旷视科技的研究人员在 2021 年提出的最新的深度学习目标检测算法。该算法进行了如下改进措施:在输入端加入了 Mosaic 数据增强的基础上,加入了 Mixup 数据增强效果;在 Backbone 和 Neck 结构层,将激活函数换成了 SiLU 函数;在网络结构的输出端,将检测头改为 Decoupled Head、采用anchor free、multi positives、SimOTA 的方式,提升网络模型的计算精度。所研究的输电线路异物检测问题,在对上述模型进行一定的比较分析之后,选择了最新的单阶段深度学习目标检测框架 YOLOX 作为异物目标信息的检测算法。
-
为了缓解传统人工巡检带来的压力,直升机巡检的方式应运而生,其时间可以追溯到 20 世纪 50 年代,国外开始引入直升机巡检的方式对输电线路进行巡检,到了 20 世纪 90 年代,直升机巡检的方式已在西方各发达国家中广泛使用。由于直升机巡检本身也存在许多弊端,后来各国陆续开展巡线机器人以及无人机的研究。
-
无人机巡检的技术,起始于 20 世纪末。1995 年,英国威尔士大学和 EA电力咨询公司联合研发了一种小型旋翼无人机,在输电线路巡检工作中具有一定的可行性。美国电科院则设计了相关的无人机平台,通过其搭载的摄像机在输电线路巡检中完成了识别大尺寸设备的试验
-
在输电线路智能巡检技术方面,国外的起步要比国内早,且硬件方面的研究工作也比国内要领先。我国虽然还有许多不足之处,但在该领域具备长足的潜力,以后的输电线路巡检也定会朝更加智能、更加实用的方向发展。
-
输电线路异物分布范围广,种类多,在杆塔上可能存在鸟巢、风筝、绳索等杂物,在架空线上也可能搭挂风筝、气球、塑料薄膜等杂物,因此检测存在一定的难度。在异物检测算法方面,电力研究者也进行了许多相关研究。
-
文献[Detection of Bird Nests on Power Line Patrol Using Single Shot Detector]利用 SSD 对输电线路鸟巢进行识别,将检测结果裁剪为子图像,再结合 HSV 颜色空间模型过滤掉不包含鸟巢的子图像,使识别准确率增加到98.23%,大幅提升了检测精度。文献[Detection of bird species related to transmission line faults basedon lightweight convolutional neural network]提出一种使用 YOLO 轻量化网络YOLOv4-tiny 网络模型的输电线路鸟类检测算法,结合分段训练、数据增强等策略,将文献中构建的 20 中鸟类图像数据集检测精度提升到 92.04%,为预防鸟害造 成 的 电 网 停 电 提 供 了 依 据 。 文 献 [RCNN-based foreign object detection for securing power transmission lines (RCNN4SPTL)] 提 出 了 一 种 新 的 深 度 学 习 网 络RCNN4SPTL,用于输电线路上的固定异物检测,其使用了 RPN 生成候选框匹配异物的尺寸,同时使用了端到端的训练方式提高性能,相比原始的 Faster RCNN检测速度和识别精度均有所提升。文献[Foreign object detection of transmission lines based on Faster R-CNN]采用了 Fast-RCNN 网络模型,对传输线内的风筝、气球等异物进行检测,相比传统的目标检测方法,其克服了人工特征提取的不稳定性,还提升了传输线中异物检测准确性。文献[一种新的输电线路异物检测网络结构——TLFOD Net]设计了 TLFODNet 输电线路异物检测网络,并且使用了端对端的训练方式提高网络性能,在识别速度和精度方面均取得了突破。文献[Neural detection of foreign objects for transmission lines in power systems]在传输线异物检测领域应用了YOLOv3 网络,并融入迁移学习和数据增强的方法用来缓解数据集容量太小的问题,验证了使用迁移学习策略和数据增强方法的有效性。文献[Study on the method of transmission line foreign body detection based on deep learning]使用了 SSD 进行异物检测算法研究,与 DPM、Faster R-CNN 进行了对比评估,较高的 mAP 和FPS 也反映了其进行异物检测任务的准确性和实时性。文献[Feature GANs: a model for data enhancement and sample balance of foreign object detection in high voltage transmission lines]提出一种基于对抗神经网络 GANs 的数据增强方法,改善了输电线路异物检测中样本不足或不平衡的情况,显著提高了几种经典 CNN 模型的分类性能。文献[Deep Learning-Based Bird’s Nest Detection on Transmission Lines Using UAV Imagery]提出一种增加感兴趣区域挖掘的区域卷积神经网络(RCNN)对鸟巢进行自动检测,解决了分类阶段类别不平衡问题,其平均精度值(mAP)与 F1 分数均高于 RCNN 和级联RCNN。基于YOLOX的输电线路异物检测算法研究及软件设计 - 中国知网 (cnki.net)
-
图像分为模拟图像和数字图像两类:模拟图像是人们眼睛所感受认识到的,其值域是连续的;而数字图像是计算机等电子设备所认识到的事物,其值域是离散不连续、有限的。
-
图像的噪声是指图像中各种阻碍人们获取图像信息的因素。在图像的收集和传输过程中,由于各种噪声的不确定影响会导致图像品质的降低,会对后续目标检测模型训练过程中图像特征信息的提取造成严重的影响。CCD 相机拍摄的数字图像中的噪声的主要种类有暗电流噪声、读出噪声、模式噪声、光子噪声、热噪声以及量化噪声。暗电流噪声是指在入射光照缺乏的条件下,通道中输出的反向电流,会形成背景的白噪声;读出噪声是指读出电路里面的电子器件带有的固定噪声和电路设计带来的噪声;模式噪声是指数字图像的形成过程中,相机传感器对于光子强度和数量的捕捉,会受到感光元件性能的影响,有一定的损失,就会形成图像的噪声;光子噪声是指在一定的光照条件下,达到传感器的光子数量也是随机的,不确定的光子数量也会造成图像形成过程的噪声;热噪声是在电子元件和传输介质工作的时候发热形成的,任何的放大电路都会存在热噪声,形成图像噪声;量化噪声是图像在模数电话量化转化的过程中,由于采样过程中的信息损失和近似误差形成的一种噪声。影像的通讯信号如果在使用过程中受到了严重的干扰,则在图像中经常出现椒盐噪声,在图像中随机位置出现白点或黑点,具体表现为也就是在亮的区域内存在黑色像素,抑或是在暗的图像区域内存在白色像素。
-
图像的噪声一般具有以下特点:噪声在图像中的分布具有随机性,无论是噪声的分布还是噪声大小都是不规则的;噪声具有叠加性,在图像的串联传输系统中,同类噪声可以进行功率的相加,噪声效果得以加强,更加严重的降低图像的质量;图像和噪声之间还具有相关性,摄像机的信号会对噪声的大小有影响,比如图像中的黑暗区域的噪声大,图像中明亮区域的噪声会偏小,还有数字图像中的量化噪声还与图像的相位有关,当图像里的内容较为平坦时,量化噪声呈现伪轮廓,但如果图像中存在有随机噪声,会因为颤噪效应使得图像中的量化噪声变得不明显。
-
图像的特征提取会受到噪声的影响,限制了后面图像处理算法的效果,因此图像的去噪已经成为图像预处理过程中不可少的一步。图像的去噪也可以称为图像的平滑处理,主要是对图像采用各种滤波算法以减少噪声,常用的方法有均值滤波、高斯滤波、中值滤波和双边滤波等。
-
均值滤波为典型的线性滤波算法,主要方法为邻域平均法,即通过模板求像素邻域的均值代替原像素值。在进行均值滤波时,需要先给出一个滤波卷积核模板,对当前待处理的像素点(x,y),选择由该点和其周围的若干像素组成一个模板,求该模板中所有像素值的均值,然后把该均值赋予给像素点(x,y),作为处理后在该点上的像素值。均值滤波的抑制噪声效果好,但在去噪过程中不能很好保护图像的细节,会造成图像模糊。
-
高斯滤波是一种线性平滑滤波,对图像中的高斯噪声有一个很好的去除作用,在图像的去噪过程里得到了广泛的使用。高斯滤波就是对整幅图像的像素点进行加权平均的过程。高斯滤波后的图像中每一个像素点的值,都是用本身和邻域内其它像素的加权平均值替代原像素值,用于噪声的平滑消除。
-
中值滤波是一种典型的非线性滤波技术,采用邻域内像素的中值代替原像素值来去除噪声。其需要通过基本排序统计理论对所求像素点以及其领域内的像素值进行排序处理,然后选取排序后的中值代替当前的像素值,让周围的像素值接近真实值,从而消除孤立的噪声点。中值滤波由于不依赖领域内那些与典型值差别很大的值,所以椒盐噪声和斑点噪声的去除有显著效果,且能保护信号边缘不被模糊,但需要进行像素排序,计算量大。
-
双边滤波是一种非线性的滤波方法,考虑到空间信息和灰度的相似性,结合图像的空间邻近度和像素相似度进行一定处理,以达到去噪音的目的。双边滤波器可以很好的做到边缘保护,对图像中的高频细节有很好的保护效果,但是也导致了双边滤波器不能够将图像中的高频噪音干净的滤掉,只能对低频的噪音有一个很好的去除效果。
-
图像去噪处理通过滤波降低嗓声点干扰,实现图像平滑,但滤波会对特征信息削弱从而造成图像细节丢失。在实际进行图像处理时,应当综合考虑嗓声消除与细节保留这两方面因素,选择合适的图像去嗓方法。均值滤波不能很好的保存图像的细节,在去噪的同时也对图像的细节部分也造成了一定程度的破坏,会造成边缘模糊;高斯滤波在有利于去除高斯噪声,能较柔和的保留边界,但依然较难完全去除椒盐噪声;中值滤波在去除嗓声的效果较好,能够在去除图像噪声的同时,对图像的边缘特性进行保存,但由于需要进行排序操作,花费的时间是均值滤波的五倍以上;双边滤波方式能够有效的去除图像中的低频噪音,对做到图像的较好边缘保存效果,但是对高频噪音不能很好的去除。因此根据具体情况选择合适的滤波方法对后续的工作会有很大的帮助。
-
由于卷积操作属于线性变换,得到的输出也是线性的,如果不加入激活函数,那么不论有多少个设计网络层,输入与输出都是线性的,与没有隐藏层的效果是一样的,因此还需要引入激活层对其进行非线性处理。常用的激活函数有 Sigmoid、Tanh、Relu,Softplus 和 Dropout 函数等。各激活函数的对比如下表示。
-
在卷积神经网络网络层次比较浅时,通常会使用激活函数 Sigmoid 函数和Tanh 双曲正切函数。但是大部分数值在经过 Sigmoid 函数和 Tanh 函数之后,由于两者的导数都比较小,多个值很小的导数相乘,导致得到的运算结果很小,当卷积神经网络结构越来越深,梯度后向传播到前层网络的时候,就无法引起参数的扰动,也就是说没有将 loss 的信息传递到前层网络,便会导致网络结构无法进行学习,从而形成梯度消失现象。
-
为了规避了饱和激活函数 Sigmoid 函数和 Tanh 函数的梯度消失问题,研究人员提出了 Relu 激活函数。Relu 函数的梯度只有两个值 0 和 1,输入大于 0 时,梯度为 1;输入小于 0 时,梯度为 0。Relu 函数的梯度连乘不会收敛到 0,只有两个值 0 和 1。当值为 1 时,会继续前向传播;若值为 0,则会从此处停止前向传播,从而解决了 Sigmoid 函数和 Tanh 函数的梯度消失问题。同时相对于 sigmoid函数,由于 Relu 函数的梯度只有 0 和 1,并且函数的负值部分被截断为 0,避免了无用信息的干扰,进一步提高了网络结构的计算速度.
-
Relu 函数虽然能够提高网络计算的速度,但会面临着神经元死亡的问题。对于输入数据总是负值的情况,在反向传播的过程中,由于 Relu 函数的倒数在输入为负值时候总是为 0,对应的权重和偏置参数就无法得到更新,神经元就无法得到学习。针对神经元死亡的情况,提出了 LeakyRelu 激活函数,在输入小于 0时,给激活函数赋予一个很小的梯度值,使得在反向传播时(不会像Relu 函数一样梯度为 0),这样就避免了神经元得不到学习的情况。
-
相对于 LeakyRelu 激活函数,Mish 激活函数是一个非单调函数,在保持小的负值的同时,能够稳定网络的梯度流,让更多的神经元得到更新。Mish 函数还是一个光滑函数,具有很好的泛化能力以及结果的优化能力,可以让结果的质量得到进一步的提升。
-
激活函数的选择也是卷积神经网络搭建的一个重要工作,Tanh 函数适用于输入数据特征相差比较明显的情况,因为在循环过程中特征会被其不断放大并显现出来。反之,则可选用 Sigmoid 函数,同时 Sigmoid 函数也相当适用于二分类问题。另外,当激活函数选用 Sigmoid 和 Tanh 时,输入需规范化,否则激活后的值全部都进入平坦区,导致隐层的输出会全部趋同,甚至丧失原有的特征表达。而 Relu 相比二者优势明显,其计算量较少,且未必要对输入规范化,但其只能应用于隐藏层。目前大部分的卷积神经网络都采用 Relu 作为激活函数。
-
池化层进行下采样,压缩了图像数据和参数,可以减少训练参数的数量,可以有效加快网络运行速度。同时,其还可以有效保留图像的信息并减少噪声传递。池化层输入即为卷积层输出的原数据与卷积核进行卷积操作后的特征图像。常见的池化方式有两种,一是最大池化,选取指定区域内的最大特征数字来代表整个区域,注重图像的纹理信息;一是均值池化,选取指定区域内所有特征数字的均值来代表整个区域,注重图像的背景信息。
-
在经过多个卷积层和池化层的处理以后,将得到的特征向量传输到全连接层中,全连接层中每个神经元都与前一层所有的神经元全部连接。比如经过多层卷积池化以后得到的特征图的大小 5*5*256,则在全连接层中,会将这些神经元整合成一维向量,也就是 6000 个神经元结构,全连接层再与分类器连接完成图像的分类任务。并且为了防止卷积神经网络过拟合现象的产生,可以加入 Dropout随机失活,让模型更具有鲁棒性,提高模型的泛化能力。
-
将进入输出层的一维特征向量,经过 Softmax 函数完成图像的分类操作。同时需采用不同的目标函数评估模型对数据的拟合程度,常用的损失函数有均方、交叉熵和指数损失函数等。几种常用的损失函数比较如下:
-
均方误差(Mean Squared Error):均方误差是指参数估计值与参数真值之差平方的期望值;MSE 可以评价数据的变化程度,MSE 的值越小,说明预测模型描述实验数据具有更好的精确度。
-
M S E = 1 N ∑ i = 1 N ( y ( i ) − f ( x ( i ) ) ) 2 MSE=\frac1N\sum^N_{i=1}(y^{(i)}-f(x^{(i)}))^2 MSE=N1i=1∑N(y(i)−f(x(i)))2
-
均方根误差:均方根误差是均方误差的算术平方根,能够直观观测预测值与实际值的离散程度。通常用来作为回归算法的性能指标。
-
R M S E = 1 N ∑ i = 1 N ( y ( i ) − f ( x ( i ) ) ) 2 RMSE=\sqrt{\frac1N\sum_{i=1}^N(y^{(i)}-f(x^{(i)}))^2} RMSE=N1i=1∑N(y(i)−f(x(i)))2
-
平均绝对误差(Mean Absolute Error):平均绝对误差是绝对误差的平均值,平均绝对误差能更好地反映预测值误差的实际情况。通常用来作为回归算法的性能指标。
-
M S E = 1 N ∑ i = 1 N ∣ y ( i ) − f ( x ( i ) ) ∣ MSE=\frac1N\sum^N_{i=1}|y^{(i)}-f(x^{(i)})| MSE=N1i=1∑N∣y(i)−f(x(i))∣
-
交叉熵代价函数(Cross Entry):交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况,减少交叉熵损失就是在提高模型的预测准确率。
-
H ( p , q ) = − ∑ i = 1 N p ( x ( i ) ) l o g q ( x ( − i ) ) H(p,q)=-\sum_{i=1}^Np(x^{(i)})logq(x^{(-i)}) H(p,q)=−i=1∑Np(x(i))logq(x(−i))
-
其中 p(x)是指真实分布的概率,q(x)是模型通过数据计算出来的概率估计。比如对于二分类模型的交叉熵代价函数:
-
L ( w , b ) = − 1 N ∑ i = 1 N ( y ( i ) l o g f ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − f ( x ( i ) ) ) L(w,b)=-\frac1N\sum^N_{i=1}(y^{(i)}logf(x^{(i)})+(1-y^{(i)})log(1-f(x^{(i)})) L(w,b)=−N1i=1∑N(y(i)logf(x(i))+(1−y(i))log(1−f(x(i)))
-
其中 f(x)可以是 sigmoid 函数,或深度学习中的其它激活函数。而 y(i)∈0,1,通常用做分类问题的代价函数。
-
-
Torch7 的发展趋势在 2017 年得到了改变,来自 Facebook FAIR 和其他多家实验室的研究人员决定要重新改造 Torch7,在保留 Torch7 简洁方便的程序编写风格和强大的后端运算能力的同时,使用 Python 语言代替了原来使用的 Lua 语言,借助 python 语言完善的开源基础设施,让 Torch7 深度学习框架的重造得以实现,一个全新的 PyTorch 可微分编程深度学习框架出现在人们眼前。
-
PyTorch 的语言简洁,代码层次清晰,模块划分合理。PyTorch 的设计使得开发者可以从张量、变量和神经网络三个层次进行修改。PyTorch 主要分为基础矩阵运算部分,实现自动微分的计算图和神经网络的计算层和单元,这种更直观的设计,使得 PyTorch 的源代码十分易读,并且源代码的量只有 TensorFlow 的十分之一左右。
-
PyTorch 具有简单的数据处理方式,快捷的模型保存与加载,方便的分布式计算方式。PyTorch 支持常见计算机领域内的数据增广方法,torchvision 模块更是包含了许多数据增广操作;模型的保存与加载可以直接通过 save,load-state-dict 方法进行操作,并且 torchvision 模块还包含了很多常见的 CNN 模块以及其预训练权重那个,为神经网络的迁移学习提供了助力;分布式计算方式则无需考虑多个计算图之间交互问题,直接利用 torch.nn.DataParallel 实现单机多卡运算。
-
PyTorch 深度学习框架的安装简单,性能更优。PyTorch 的安装十分简单,可以通过 Anaconda 的包管理系统直接安装,并且可以继续安装 PyTorch 所需要的一些必要组件;针对于同样的算法,使用 PyTorch 实现更有可能快过其他的深度学习框架,PyTorch 框架的易用性和可读性的优点更加的突出。
-
-
使用 LabelImg 标注工具对上节获取的异物检测数据集进行标注,将标签名称分别命名为 nest、balloon、kite 以及 trash,并存储为 VOC2007 标准数据集。标注界面与存储内容分别如下图所示,其中 VOC 数据集中 JPEGImages 文件夹下存储“.jpg”格式的异物数据集图片,Annotations 文件夹下存储通过LabelImg 标注生成的“.xml”格式的标签文件,标签文件内容包含了异物的标签名称及标注框坐标等信息,ImageSets 存储后续划分数据集的相关设置文件,在训练前进行划分
-
颜色变换通过调节 RGB 图像三通道的像素值大小实现,主要采用亮度调节的方式进行亮度方面的数据增强,调节亮度只需在三个通道对其像素值按照一定规律增减即可改变图像的亮度。RGB 图像的亮度为:
-
L = 0.299 R + 0.587 G + 0.114 B L=0.299R+0.587G+0.114B L=0.299R+0.587G+0.114B
-
对图像进行加噪和加雾可以分别对图像采集过程中的噪声和恶劣天气下的环境进行模拟,其中图像加噪声主要加高斯噪声。
-
-
实际应用中还会用到图像混叠的方式进行数据增强,通过拼接、混叠等方式将若干张图片合成为一张新的图片。常用的图像混叠类的数据增强方式有 CutMix、Mosaic 和 Mixup 等。CutMix 是将两张图片进行裁剪后拼接而成的图片,设𝑥𝑖与𝑦𝑖分别为训练样本 i 及其标签值,𝑥𝑗与𝑦𝑗分别为训练样本 j 及其标签值,𝑥̃和𝑦̃为经过 CutMix 生成的新样本和及对应的标签值.
-
x ^ = M ⊙ x i + ( 1 − M ) x j y ^ = λ y i + ( 1 − λ ) y j \hat x=M\odot x_i+(1-M)x_j\\ \hat y=\lambda y_i+(1-\lambda)y_j x^=M⊙xi+(1−M)xjy^=λyi+(1−λ)yj
-
M 为裁剪部分及填充部分的二进制掩码,是一个元素为 0、1 的矩阵;☉为逐像素相乘的运算;λ服从 Beta 分布:λ~Beta(α, α),当α = 1时,为(0, 1)的均匀分布。CutMix 通过二进制掩码矩阵 M 对两张图片进行互补裁剪,再将两者拼接到一起,扩大了数据集容量,可以在有限的图片中获得更多的异物信息,对后续模型训练的分类效率有一定的提升作用。
-
-
Mosaic 数据增强方法与 CutMix 类似,但是 Mosaic 使用了四张图片进行拼接生成新的训练图片。丰富了异物检测时的背景,并且在后续 BN 计算时会计算四张图片的数据。Mosaic 数据增强方法的实现思路可以分为如下三步:
-
随机读取 JPEGImages 文件夹中四张图片;
-
将读取到的四张图片进行简单的空间、颜色变换,并将四者按左上、左下、右上、右下的位置进行摆放;
-
进行四张图片的组合和其目标框的对应组合,并保留有效的目标框。
-

-
-
Mixup 是一种基于混叠的数据增强方式,是将两张图片进行混合生成的。设𝑥𝑖与𝑦𝑖分别为训练样本i 及其标签值,𝑥𝑗与𝑦𝑗分别为训练样本j 及其标签值,𝑥̃和𝑦̃为经过Mixup 生成的新样本和及对应的标签值:
-
x ^ = λ x i + ( 1 − λ ) x j y ^ = λ y i + ( 1 − λ ) y j \hat x=\lambda x_i+(1-\lambda)x_j\\ \hat y=\lambda y_i+(1-\lambda)y_j x^=λxi+(1−λ)xjy^=λyi+(1−λ)yj
-
与 CutMix 数据增强公式不同的是,Mixup 没有二进制掩码矩阵,λ服从 Beta分布:λ~Beta(α, α),当α = 1时,为(0, 1)的均匀分布。Mixup 对异物识别的背景也起到了丰富的作用,对模型训练效果有一定的提升。
-

-
-
传统的目标检测算法如 SIFT、HOG 等以特征提取、目标识别及目标定位的依次顺序对图像进行目标检测,其特征工具往往都为人工设计,这样的检测方法十分复杂且耗时,且难以满足实时性要求,检测效果也不大理想。
-
R-CNN 目标检测算法主要分为以下 4 步进行:
-
候选区域生成。利用不同尺寸的窗口对输入图像进行滑动检索,并通过 selective search 方法生成共 1000 至 2000 个候选区域(region proposal);
-
特征提取。对不同大小的候选区域进行缩放,统一为 227*227 的尺寸后输入到 CNN 进行特征提取;
-
类别判定。通过将提取到的特征输入到每一类的分类器中,判别其是否属于某一类别,分类器多选用 SVM、Adaboost 等。
-
位置校正。利用回归器校正候选框的位置,对分类器已完成分类的候选区域进行边框回归,利用 Bounding Box 回归值校正原来的候选区域,生成更加准确的预测窗口目标。
-
-
其中,第一步中提取到的候选框数据较大,还要进行后续几步的特征提取与分类器分类,计算量巨大,一张图甚至需要四十几秒的时间完成检测,检测速度堪忧。
-
为了改进这一问题,2015 年时 R-CNN 原作者采纳了 SPPNet 的思想,对原R-CNN 进行改进,于是更快更准的 Fast-R-CNN 诞生了,相比于原 R-CNN 算法,其主要有以下三种改进:
-
卷积计算直接针对整张图像,而非对每个候选区域进行计算,避免了重叠候选区域的重复计算过程,大大提升了在特征提取过程中的计算速度;
-
采用感兴趣区域池化层(ROI pooling layer)进行特征的尺寸变换,便于对之后全连接层的输入,此处借鉴了 SPPNet 的空间金字塔结构;
-
损失函数采用了多任务损失函数(multi-task loss),去掉了基础网络VGG16 后边的结构,使用 Softmax 函数代替 SVM 分类器,可以将多分类任务同时进行,在速度和精度上可以获得比 SVM 更好的效果。而且将边框回归也直接加入到 CNN 网络中进行训练。
-
-
深度学习网络模型训练将消耗大量的时间,如果从零开始训练,将会大大延长训练时间。模型的特征提取能力在随机化参数的情况下极差,严重情况下甚至无法使网络正常收敛。因此需要使用迁移学习的方法进行模型优化,迁移学习(Transfer Learning)是指将一个任务的网络结构和权值迁移到另一个任务中,使其可以在该任务中产生较好的效果。适合这种样本不足的情况,将通用特征的学习从已训练好的网络模型中迁移到输电线路异物检测网络中,既可以节省训练时间,又可以得到较好的识别效果。
-
除此之外,为了缓解硬件对训练的限制,对训练样本进行分批处理,批(batch)是每次进行迭代模型要处理的图片数量。batch 的大小在一定程度上会对网络的梯度下降速度有影响,选用较大的 batch 将会提升网络的梯度下降速度,然而由于硬件限制,batch 的值不能无限制地大,太大的 batch 将会使显存爆满,中断训练过程。
-
学习率(learning rate)是训练期间权重更新的量,是网络训练中使用的可配置超参数,取值范围为 0.0 至 1.0.过大的学习率在网络模型训练的前期加速学习,使得模型容易接近局部或全局最优解,但后期可能会导致损失函数的值一直振荡,难以达到真实的最优解。而学习率太小,会导致网络损失的收敛速度下降,甚至可能不会收敛,陷入次优解的范围。因此在训练前期设置学习率为 0.001,后期采用学习率余弦退火(cosine annealing)衰减的方法对学习率进行适度下降。学习率余弦退火衰减是指通过余弦函数的形式对学习率进行调整,先缓慢下降,然后加速下降,再缓慢下降,学习率的更新机制如下式所示:
-

-
其中,learning_rate 表示初始学习率,global_step 表示用于衰减计算的全局步数,decay_steps 表示衰减步数,α表示最小学习率。
-
-
优化器(Optimizer)是在深度学习网络反向传播过程中使损失函数不断逼近全局最小的一种权值参数更新算法。作为最原始的优化器随机梯度下降法(SGD,Stochastic Gradient Descent),其计算量太大,且较容易收敛到局部最小值,因此可以选用收敛能力更强且计算效率更高的 Adam 梯度下降法。其权重更新方式如公式所示:
-
θ t + 1 = θ t − η v ^ t + ϕ m ^ t m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat v_t+\phi}}\hat m_t\\ \hat m_t=\frac{m_t}{1-\beta^t_1}\\ \hat v_t=\frac{v_t}{1-\beta^t_2} θt+1=θt−v^t+ϕηm^tm^t=1−β1tmtv^t=1−β2tvt
-
其中,𝜃𝑡、𝜃𝑡+1表示 t、t+1 时刻的梯度,η表示学习率,𝑚̂𝑡,𝑣̂𝑡分别表示梯度的一阶、二阶矩估计修正值,𝛽1、𝛽2分别表示一阶、二阶矩的指数衰减率,𝑚𝑡、𝑣𝑡分别表示梯度的一阶、二阶矩,其中,𝑔𝑡表示 t 时刻的梯度值。其公式如下:
-
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m_t=\beta_1m_{t-1}+(1-\beta_1)g_t\\ v_t=\beta_2v_{t-1}+(1-\beta_2)g^2_t mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2
-
基于YOLOX的输电线路异物检测算法研究及软件设计_有系统有文献,整体认知蛮好的
news2026/2/12 3:49:10


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/896219.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

从零做软件开发项目系列之一综论软件项目开发
1 引言
有一个三个泥瓦匠的故事。 三个泥瓦匠在砌墙,一个人走过来,问他们在干什么。 第一个泥瓦匠没好气地说,你没看见吗?我在辛苦地砌墙呢。 第二个回答,我们正在建一座高楼。 第三个则洋溢着喜悦说&…
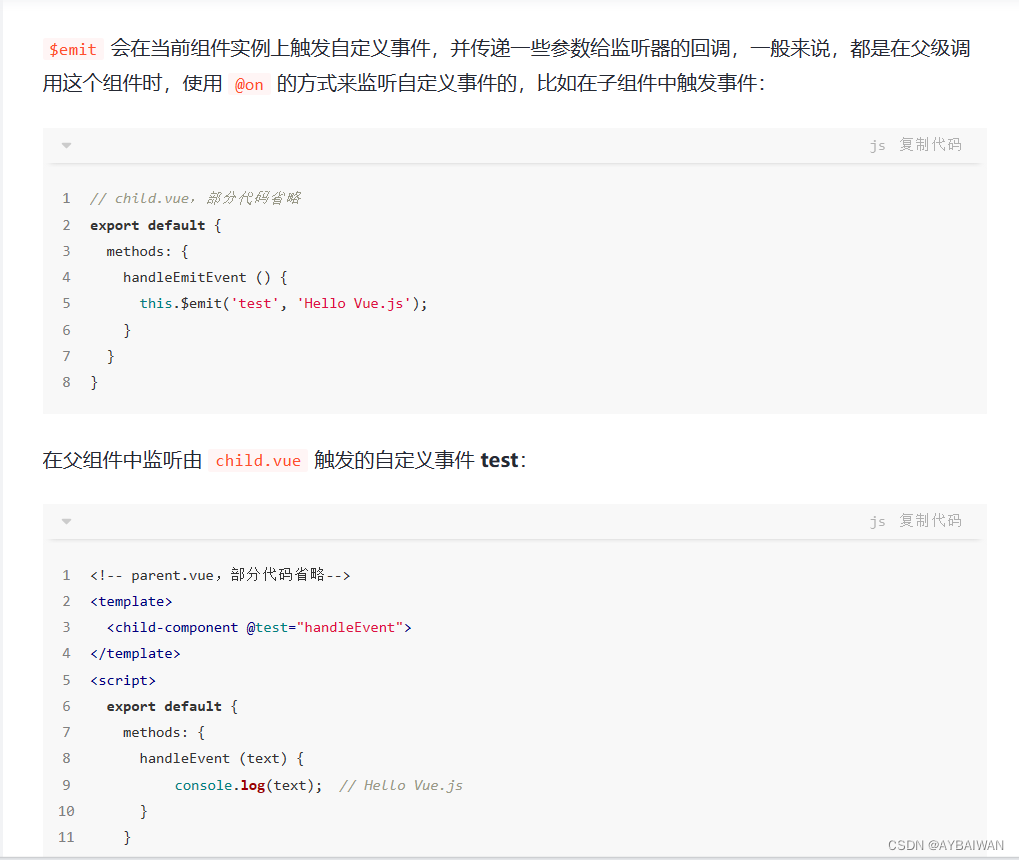
Vue2子组件修改父组件的方法
Vuex
Vuex 是状态管理器,集中式存储管理所有组件的状态。 Vuex速成整理_AYBAIWAN的博客-CSDN博客https://blog.csdn.net/aybaiwan/article/details/131442547?spm1001.2014.3001.5501vuex中this.$store.commit和this.$store.dispatch的用法_老电影故事的博客-CSD…

第八届XCTF联赛首场国际外卡赛——WACON2023即将开启!
由国际战队SuperGuesser操刀命题 第八届XCTF首场国际外卡赛 WACON2023即将开启
线上资格赛前6名队伍 将晋级WACON2023总决赛 飞往韩国首尔 与全球顶尖白帽黑客一决高下
总决赛冠军队伍将获得: 3千万韩元(折合人民币16万)高额奖金 &第八…
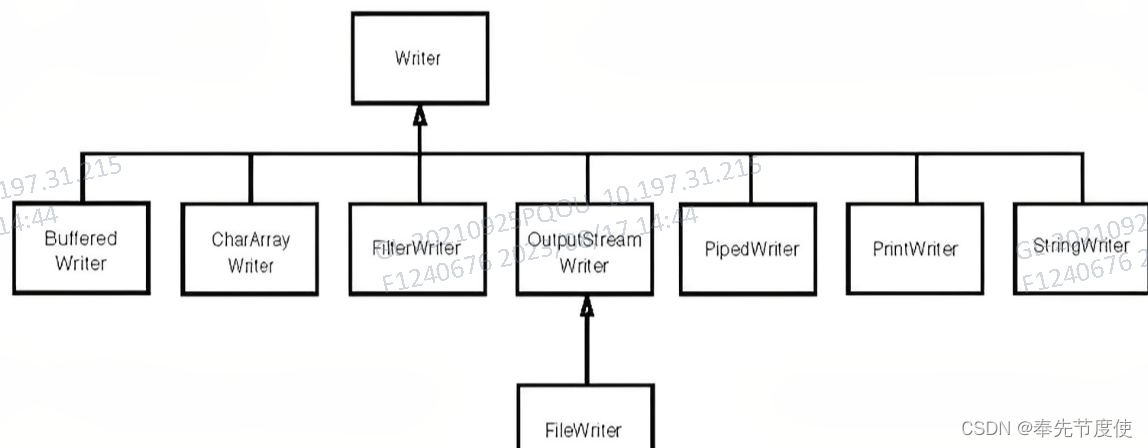
Java IO流(一)IO基础
概述 IO流本质 I/O表示Input/Output,即数据传输过程中的输入/输出,并且输入和输出都是相对于内存来讲Java IO(输入/输出)流是Java用于处理数据读取和写入的关键组件常见的I|O介质包括 文件(输入|输出)网络(输入|输出)键盘(输出)显示器(输出)使用场景 文件拷贝(File&…

基于Java的深圳坂田附近闲置物品交易群管理系统
开发技术:java 开发框架:springmvc、spring、mybatis 数据库:mysql
备注:方便大家将手中的二手闲置物品转让给需要的人,例如大家搬家的时候,有不要的(冰箱、洗衣机、桌子、椅子)等物…
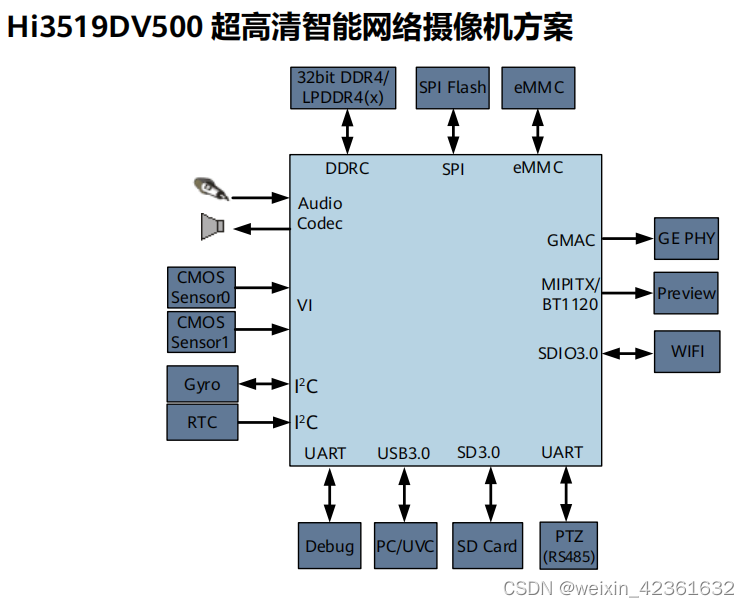
【3519DV500】AI算法承载硬件平台_2.5T算力+AI ISP图像处理_超感光视频硬件方案开发
Hi3519DV500 内置双核 A55 ,提供高效、丰富和灵活的CPU 资源,以满足客户计算和控制需求。 Hi3519DV500集成了高效的神经网络推理引擎,最高2.5Tops NN算力,支持业界主流的神经 网络框架。神经网络支持完整的 API 和工具链…

Qt使用qml(QtLocation)显示地图
一、qt版本和QtLocation模块版本确认
如果qt版本过低的话是没有QtLocation模块的,我的版本如下 构建工具版本如下
二、qml代码编写
1、工程中添加模块
首先在工程中添加模块quickwidgets positioning location
2、添加资源文件 3、在资源文件中添加qml文件 …


【001】ts学习笔记-准备工作和【基本类型】
typescript安装的包
npm i typescript #安装ts
npm i types/node --save-dev # TypeScript 项目中使用类型检查和自动补全。
npm i ts-node -g #可直接在nodejs环境中使用ts, 如:ts-node example.tstsc 常用命令
tsc -init #生成tsc目录下的配置文件:tsconfig.jso…

ADAS-干货|自动驾驶汽车E/E拓扑架构与软件功能框架
引言 之前在公众号中我们对自动驾驶常见传感器的原理进行了讲解,如《可见光相机》《IMU惯导传感器》《GPS传感器原理》《毫米波雷达原理》以及《激光雷达原理》。今天我们将结合TI自动驾驶部门专家发表的相关的论文,讲解现代自动驾驶汽车车身电气架构以及…
dockerfile的概念
目录
一、Dockerfile 概念
1.1 docker镜像的分层
二、Docker镜像的创建
2.1 基于已有的镜像创建
2.2 基于本地模板创建
2.3 基于dockerfile创建
2.3.1 dockerfile 结构(四部分)
三、Dockerfile操作指令
3.1 ENTRYPOINT指令
3.2 CMD 与entrypoint
3.3 小结
四、ADD和…
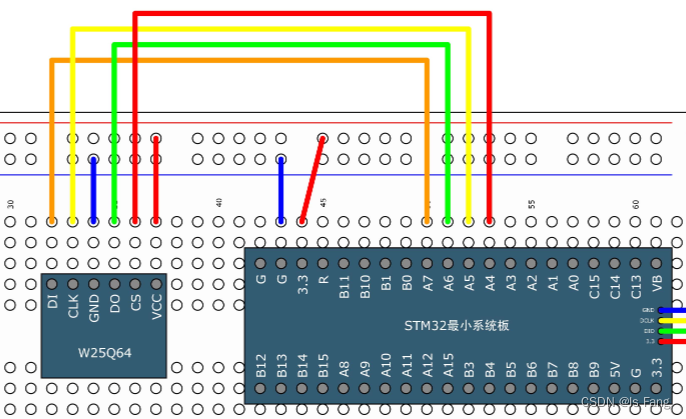
STM32——SPI外设总线
SPI外设简介 STM32内部集成了硬件SPI收发电路,可以由硬件自动执行时钟生成、数据收发等功能,减轻CPU的负担 可配置8位/16位数据帧、高位先行/低位先行 时钟频率: fPCLK / (2, 4, 8, 16, 32, 64, 128, 256) 支持多主机模型、主或从操作 可…

Pandas+Pyecharts | 成都大运会奖牌数据分析可视化
文章目录 🏳️🌈 1. 导入模块🏳️🌈 2. Pandas数据处理2.1 读取数据2.2 数据信息2.3 数据处理 🏳️🌈 3. Pyecharts数据可视化3.1 每日奖牌数量分布3.2 奖牌榜单TOP20金银铜牌分布3.3 各比赛项目金牌…
Java“牵手“拼多多商品详情页面数据获取方法,拼多多API实现批量商品数据抓取示例
拼多多商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取拼多多商品详情数据,您可以通过开放平台的接口或者直接访问拼多多商城的网页来获取商品详情信息。以下是两种常用方法的介绍:…
使用el-tree实现自定义树结构样式
实现结果: 直接上代码:
<template><div><div class"tops"><el-tree :default-expanded-keys"[1]" ref"myTree" :data"data" :props"defaultProps" node-click"handleNod…

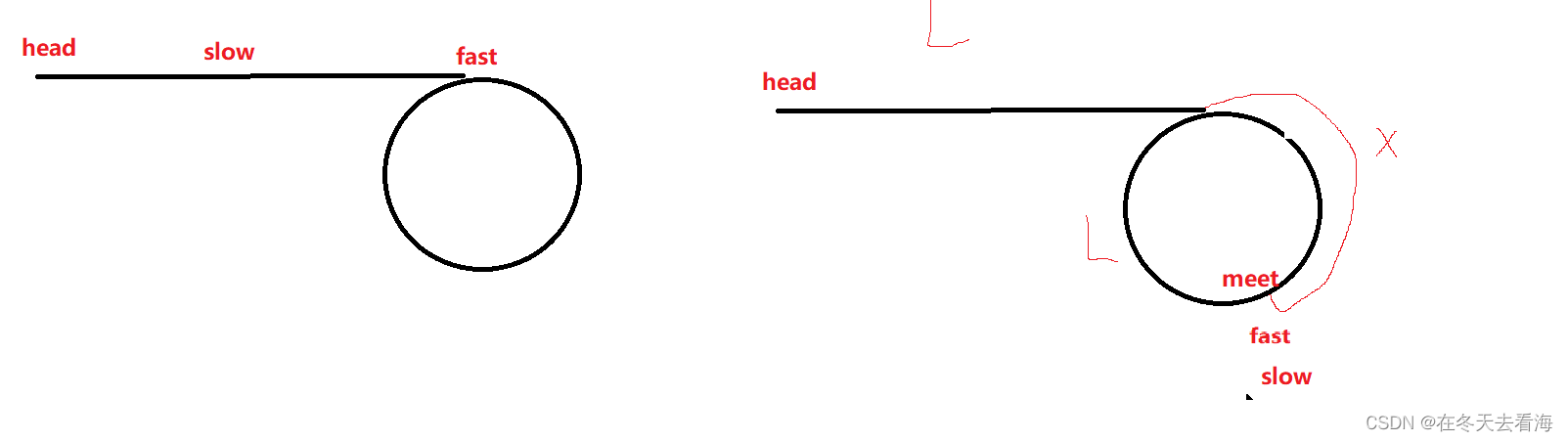
环形链表笔记(自用)
环形链表 不管怎么样slow最多走半圈了, 快慢指针slow走一步,fast走两步最合适,因为假设fast和slow相差n每一次他们前进,就会相差n-1步,这样他们一定会相遇,如果是环形链表的话。 代码
/*** Definition for…
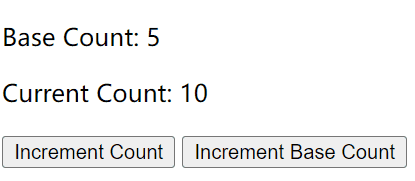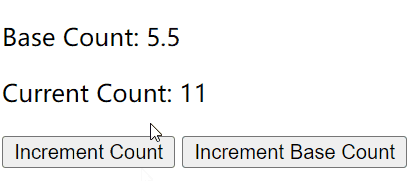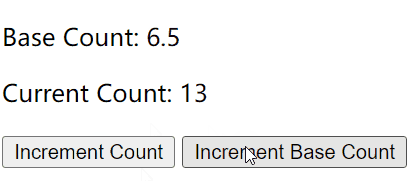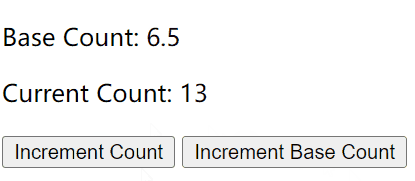
Vue 2的计算属性与侦听器
计算属性 vs 方法 vs 侦听器
计算属性的出现是为了解决模板内表达式太过复杂而变得难以维护。
假设我们知道长和宽,要计算一个矩形的面积,如果没有计算属性,我们可能像下面这样处理:
<div id"app"><input t…
基于Java+SpringBoot+Vue的乌鲁木齐南山冰雪旅游服务网站【源码+论文+演示视频+包运行成功】
博主介绍:✌csdn特邀作者、博客专家、java领域优质创作者、博客之星,擅长Java、微信小程序、Python、Android等技术,专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推…

北京“三阳”凶猛,真会说来就到吗?
综合媒体最新报道,据北京疾控中心发布的第32周《传染病周报》称,8月7日-8月13日,呼吸道传染总报告数为6205例(新冠为主),比上周猛增了71.6%!
从30周到32周,北京呼吸道传染病分别增长了5.3%、20.6%、71.6%。…