【菜鸡读论文】MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection
大家好哇!是谁美滋滋地准备开始放暑假了!没错!你没有听错!放暑假!
谁能想到都已经立秋了,竟然有人还在实验室,还没有放暑假!咱就是说,真的还有人比我更晚放暑假吗!
哈哈,不过不管怎么说,总算是可以回家啦!这次要好好回家休息一下。因为是周五了,今年的最后一个工作日,一起来读一篇论文吧!最近好久没有读论文了,之前读了一些论文,但因为各种事情(最重要的原因是我真的太懒了),就没有记录下来,现在还是要好好记录一下。

这是2022年CVPR的一篇文章做Action Detection,它提出使用一个多尺度的时域ConvTransformer:MS-TCT。首先我们来看一下提出的背景。
背景

- 动作检测数据包括复杂的时间关系,包括复合或共同发生的行动。为了在这些复杂的设置中检测行动,**有效地捕捉短期和长期的事件信息是至关重要的。**例如,如上图所示,“taking food”这个行为可以从“打开冰箱”和“制作三明治”中获得上下文信息,这对应于短期和长期的术语行动依赖关系。
- 为了对未修剪视频中的时间关系进行建模,之前的多种方法使用了一维时间卷积。然而,由于核大小的限制,基于卷积的方法只能直接访问局部信息。注意机制可以在视频的每个时间段(即时间标记)之间建议一对一的全局关系,以检测高度相关和复合动作。
- 为此,我们提出一种MS-TCT。该网络由三个主要组件组成:(1)时间编码器模块探索全局和局部时间关系在多个时间分辨率,(2)时间尺度混合器模块有效地融合多尺度特性,创建一个统一的特征表示,(3)分类模块学习每个动作实例在时间的中心相对位置,并预测帧级分类分数。
Multi-Scale Temporal ConvTransformer
如下图所示,MS-TCT包括(1)一个视觉编码器,它编码了一个初步的视频表示,(2)一个时间编码器,在不同时间尺度上的时间关系,(3)一个时间尺度混合器,被称为TS混合器,它结合了多尺度的时间表示,以及(4)一个预测类别概率的分类模块。

Visual Encoder
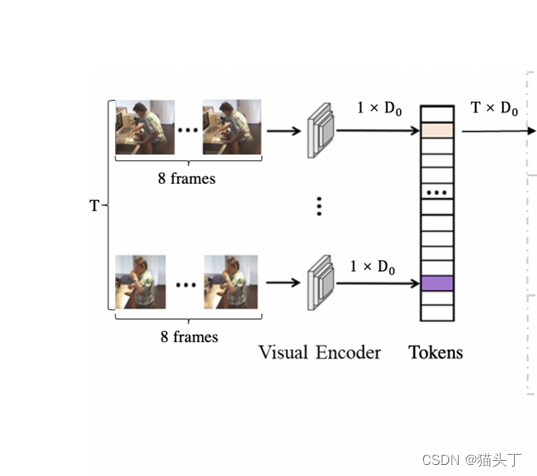
我们使用I3D backbone对视频进行编码。每个视频被分成T个不重叠的片段,每个片段包含8帧。这样的RGB帧作为一个输入段被输入到I3D网络中。每个段级特性(I3D的输出)都可以被视为一个时间步长的token。我们沿时间轴堆叠标记,形成一个T*D视频标记表示,并输入时间编码器。
Temporal Encoder
(1)使用1d时间卷积层,关注邻近的信息但忽略了直接长期时间依赖视频,或(2)transformer层全局编码一对一的交互,而忽略了局部语义;我们的时间编码器通过探索局部和全局上下文信息以交替的方法受益于两个方法的好处。
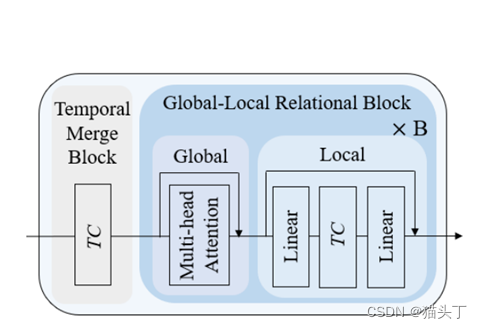
时间编码器遵循具有N个阶段的层次结构:早期阶段学习具有更多时间标记的细粒度动作表示,而后期阶段学习具有更少标记的粗表示。每个阶段对应于一个语义级别(即时间分辨率),并包括一个时间合并块和B个全局-局部关系块:

其中:
Temporal Merging Block 它在增加特征维度的同时减少了token的数量(即时间分辨率)。这一步可以看作是相邻token之间的一个加权池化操作。在实践中,我们使用一个时间卷积层(核大小为k,步幅一般为2)来将token的数量减半,并扩展通道大小。
Global-Local Relational Block 在全局关系块中,我们使用标准的多头自注意层来建模长期的动作依赖关系,即全局上下文关系。在局部关系块中,我们使用一个时间卷积层(核大小为k),通过注入来自邻近token的上下文信息,即局部归纳偏差,来增强token表示。这增强了每个token在建模与一个动作实例对应的短期时间信息时的时间一致性。
Temporal Scale Mixer
为了预测动作的概率,我们的分类模块需要在原始的时间长度上进行预测,作为网络的输入。因此,我们需要在时间维度上插值标记,这是通过执行上采样和线性投影步骤来实现的。



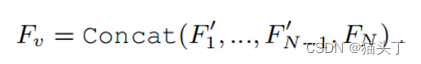
Classification Module
MS-TCT是通过联合学习两个分类任务来实现的。在这项工作中,我们引入了一个新的分类分支来学习动作实例的热图。这个热图不同于地面真是标签,因为它根据动作中心和持续时间而变化。使用这种热图表示的目的是在MS-TCT的学习标记中编码时间相对定位。



与之前的工作类似,我们使用另一个分支来执行通常的多标签分类。热图分支鼓励模型学习实例中心在视频token相对位置。因此,分类分支也可以从这些位置信息中获益,从而做出更好的预测。

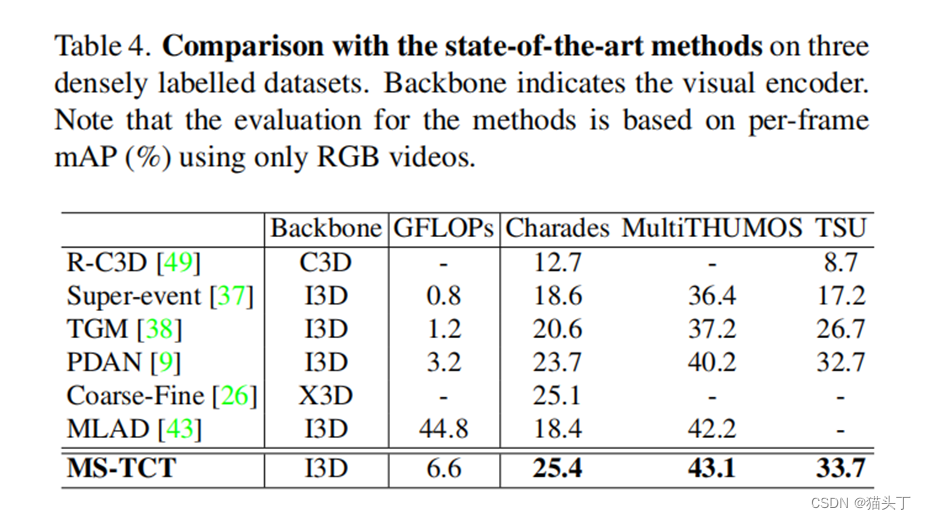
结果









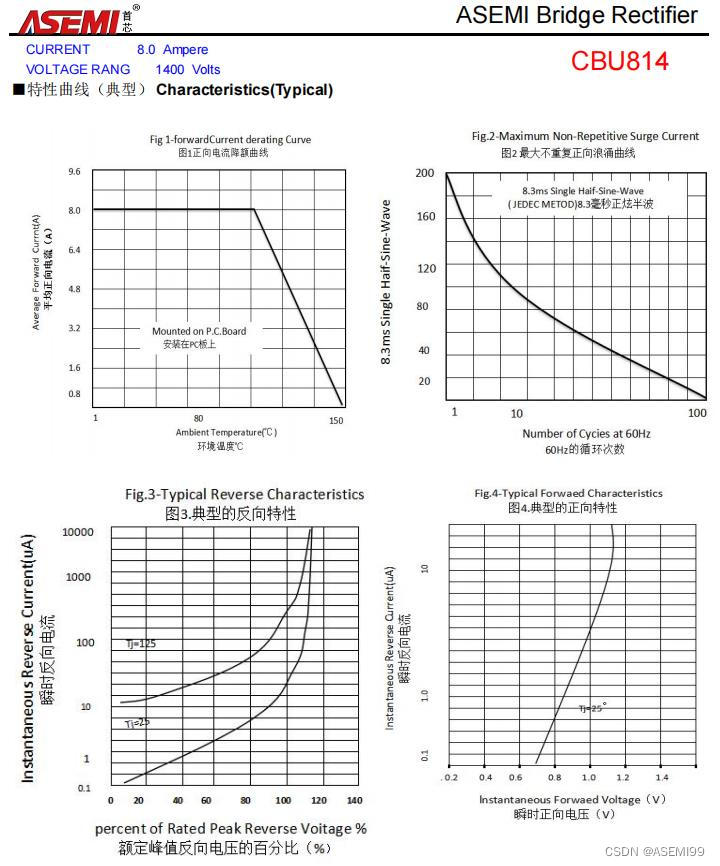
![[USACO1.5] 八皇后 Checker Challenge](https://img-blog.csdnimg.cn/img_convert/f27867727fa38f27102dd1bf40962aea.png)