目录
一、简单说一说什么是微服务?
二、微服务有哪些优缺点?
三、微服务、分布式、集群的区别?
四、什么是Eureka?
五、Eureka有那两大组件?
六、actuator是什么?
七、Discovery是什么?
八、什么是Eureka的自我保护机制?
九、微服务有很多注册中心组件,说说你知道的有哪些?并说出他们的区别?
十、什么是Ribbon?
十一、刚才你提到了RestTemplate,那么RestTemplate有什么常用的方法吗?
十二、Ribbon有哪些负载规则?
十三、Ribbon默认的轮询规则的原理是什么?
十四、什么是OpenFeign?它能干什么?
十五、Feign和OpenFeign两者区别?
十六、Ribbon与Feign的区别?
十七、简单讲一讲OpenFeign的超时控制?
十八、什么是OpenFeign日志增强?
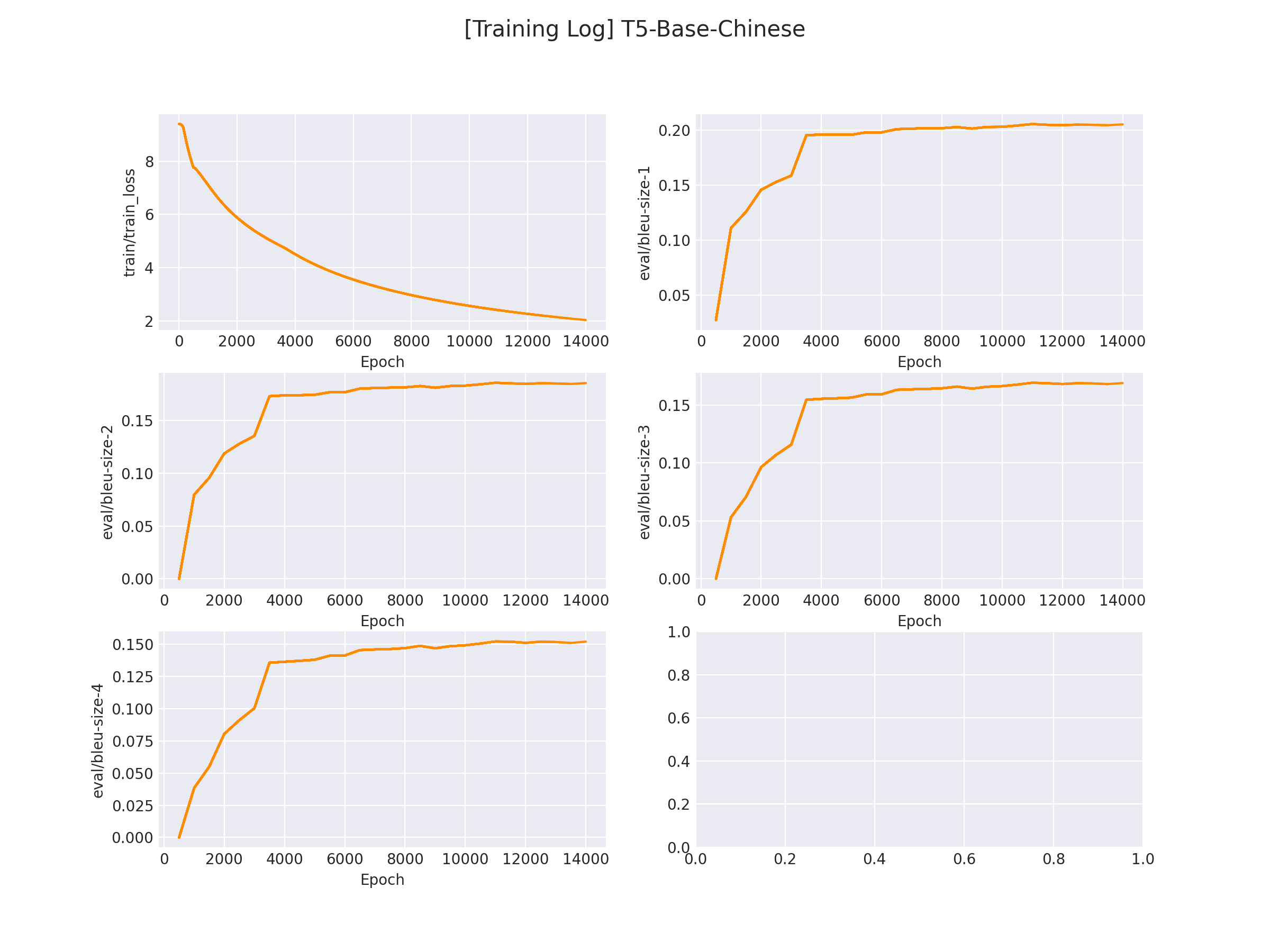
十九、讲一讲Hystrix是什么?有什么作用?
二十、请你分别说一说服务降级和服务熔断的概念
二十一、服务熔断重要的三个参数是什么?
二十二、Hystrix有哪些常用注解?
二十三、Hystrix组件有个Dashboard,你了解过吗?
二十四、GateWay是什么?
二十五、SpringCloud Gateway与Zuul的区别?
二十六、能简单讲一讲GateWay的非阻塞异步模型吗?
二十七、GateWay有三个核心概念,你知道是什么吗?
二十八、GateWay常用的Predicate断言有哪些?
二十九、GateWay中自定义全局过滤器如何实现?
三十、SpringCloud Config是什么?有什么用处?
三十一、SpringCloud中,使用过全局事件总线bus吗?如果使用过请简单的谈一谈
三十二、SpringCloud中,使用过Stream消息驱动吗?如果使用过请简单的谈一谈
三十三、假如说我们的分布式项目链路很多,有很多节点,那么如何跟踪这些链路呢?
三十四、除了Eureka、Zookeeper、Consul,你还知道什么服务注册中心的组件吗?
三十五、你刚刚提到Nacos,那与其它几种注册中心组件有什么区别吗?
三十六、Hystrix与Sentinel有什么区别吗?
三十七、简单说一说Sentinel都有哪些流控规则?
一、简单说一说什么是微服务?
微服务架构是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API)。
举个简单例子来说,我们以前都是单一的Web项目,包含着比如订单功能、支付功能、物流功能、日志功能等。但微服务是要你将这些功能按业务进行拆分,每个功能是一个SpringBoot项目,每个项目互相通信。
二、微服务有哪些优缺点?
优点:
- 每个服务足够内聚,足够小,代码容易理解这样能聚焦一个指定的业务功能或业务需求。
- 开发简单、开发效率提高,一个服务可能就是专一的只干一件事。
- 微服务能够被小团队单独开发,这个小团队是2到5人的开发人员组成。
- 微服务是松稠合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。
- 微服务能使用不同的语言开发。
- 易于和第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,如Jenkins,Hudson,bamboo。
- 微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作才能体现价值。
- 微服务允许你利用融合最新技术。
- 微服务只是业务逻辑的代码,不会和HTML、CSS或其他界面组件混合。
- 每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一数据库。
缺点:
- 开发人员要处理分布式系统的复杂性。
- 多服务运维难度,随着服务的增加,运维的压力也在增大。
- 系统部署依赖。
- 服务间通信成本。
- 数据一致性。
- 系统集成测试。
- 性能监控......
三、微服务、分布式、集群的区别?
分布式:一个业务分拆多个子业务,部署在不同的服务器上。
集群:同一个业务,部署在多个服务器上。
去饭店吃饭就是一个完整的业务,饭店的厨师、配菜师、传菜员、服务员就是分布式;厨师、配菜师、传菜员和服务员都不止一个人,这就是集群;分布式就是微服务的一种表现形式,分布式是部署层面,微服务是设计层面。
四、什么是Eureka?
在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息比如服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者服务提供者),以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何RPC远程框架中,都会有一个注册中心存放服务地址相关信息(接口地址)。
Eureka说白了就是服务注册中心,我们都知道微服务架构会有很多Module项目,众多的项目需要一个管家去管理,每个项目都要去Eureka中注册,由Eureka去统筹管理众多的项目。
我们发现哪怕不加服务注册中心,我们的消费端也能调用数据提供端完成功能,但怕就怕在量变引起质变。比如一个病人去私人医院一对一的找大夫咨询,这时倒不用中间隔这一个门诊,直接去就行了。但如果病人多了,我想知道今天还有没有剩号和余号,我们需要监控流量的管控,那么这些东西我们是不是需要一个门诊来咨询。我们得知道今天有什么专家坐诊,这个专家现在有没有余号了,这都需要门诊来咨询。
五、Eureka有那两大组件?
Eureka Server和EurekaClient。
六、actuator是什么?
如图,在Eureka中暴露了IP地址。
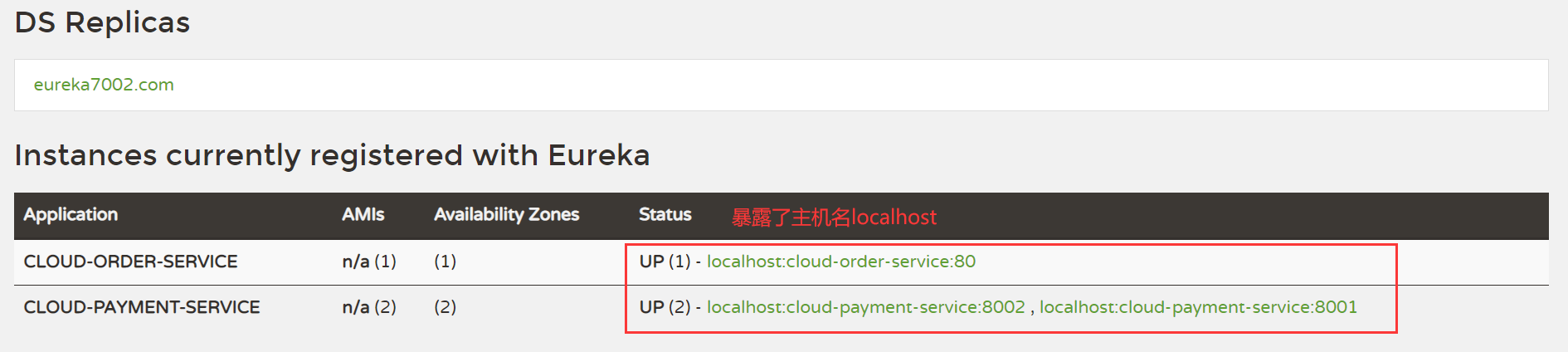
actuator的作用就是把Eureka页面中暴露的IP地址换成你指定的名字,具有信息保护的作用。
七、Discovery是什么?
消费端可以通过Discovery来获取生产者端的一些信息,比如IP、端口、服务ID等。
八、什么是Eureka的自我保护机制?
一句话总结:某时刻某一个微服务不可用 ,Eureka不会立刻清理,依旧会对该微服务的信息进行保存。
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题——当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。
自我保护机制:默认情况下EurekaClient定时向EurekaServer端发送心跳包
如果Eureka在server端在一定时间内(默认90秒)没有收到EurekaClient发送心跳包,便会直接从服务注册列表中剔除该服务,但是在短时间( 90秒中)内丢失了大量的服务实例心跳,这时候Eurekaserver会开启自我保护机制,不会剔除该服务(该现象可能出现在如果网络不通但是EurekaClient为出现宕机,此时如果换做别的注册中心如果一定时间内没有收到心跳会将剔除该服务,这样就出现了严重失误,因为客户端还能正常发送心跳,只是网络延迟问题,而保护机制是为了解决此问题而产生的)。
它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例。一句话讲解:好死不如赖活着。
九、微服务有很多注册中心组件,说说你知道的有哪些?并说出他们的区别?
注册中心组件有Eureka、Zookeeper、Consul等。
区别是:
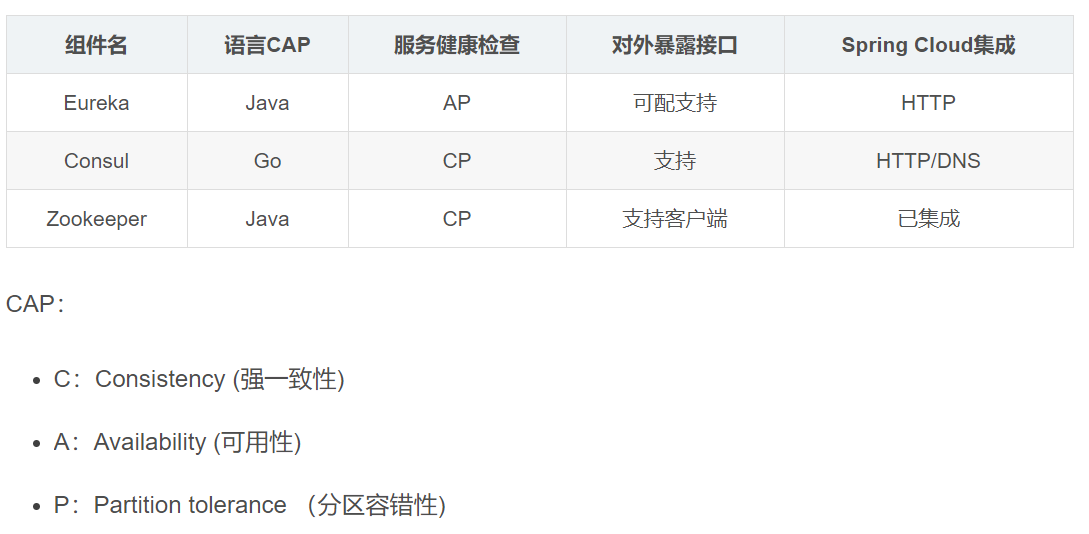
Eureka具有自我保护机制,当你某个服务宕机时,我不会立即把你干掉,会保留一段时间,保证了高可用性AP。
而Zk和Consul都是只要服务一宕机,立马把你干掉,头也不回,所以保证了CP。
十、什么是Ribbon?
Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。
一句话解释Ribbon,就是 负载均衡 + RestTemplate调用。
十一、刚才你提到了RestTemplate,那么RestTemplate有什么常用的方法吗?
(1)getForObject方法/getForEntity方法(GET请求方法)。
getForObject():返回对象为响应体中数据转化成的对象,基本上可以理解为Json。
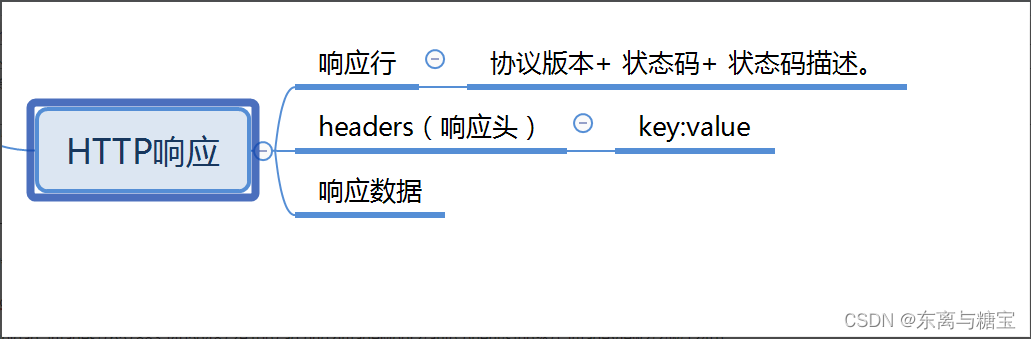
getForEntity():返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等。
(2)postForObject方法/postForEntity方法(POST请求方法)。
十二、Ribbon有哪些负载规则?
1、RoundRobinRule 轮询。
2、RandomRule 随机。
3、RetryRule 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务。
4、WeightedResponseTimeRule 对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择。
5、BestAvailableRule 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务。
6、AvailabilityFilteringRule 先过滤掉故障实例,再选择并发较小的实例。
7、ZoneAvoidanceRule 默认规则,复合判断server所在区域的性能和server的可用性选择服务器。
十三、Ribbon默认的轮询规则的原理是什么?
默认负载轮训算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标,每次服务重启动后rest接口计数从1开始。
我们的客户端现有2台机器,我们是第一次请求,那么按公式算就是1%2=1。
十四、什么是OpenFeign?它能干什么?
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了SpringMVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡。
前面在使用Ribbon+RestTemplate时,利用RestTemplate对http请求的封装处理,形成了一套模版化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring cloud Ribbon时,自动封装服务调用客户端的开发量。而OpenFeign在Feign的基础上又增加了对springmvc注解的支持。
十五、Feign和OpenFeign两者区别?
| Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端。Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。 | OpenFeign是Spring Cloud在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@Feignclient可以解析SpringMvc的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
| <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-feign</artifactId> </dependency> | <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> |
十六、Ribbon与Feign的区别?
1、Ribbon和Feign都是调用其他服务的,但方式不同。
2、启动类注解不同,Ribbon是@RibbonClient feign的是@EnableFeignClients。
3、服务指定的位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
4、调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。Feign需要将调用的方法定义成抽象方法即可。
十七、简单讲一讲OpenFeign的超时控制?
我们在使用OpenFeign进行调用接口时,如果因为某些原因,调用时间过长,会导致报错。
OpenFeign默认等待1秒钟,超过后报错。也就是说如果你调用接口总共花了3秒时间,超过1秒不返回直接就报错了。为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
十八、什么是OpenFeign日志增强?
说白了就是对Feign接口的调用情况进行监控和输出。
有以下四种日志级别:
NONE:默认的,不显示任何日志。
BASIC:仅记录请求方法、URL、响应状态码及执行时间。
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息。
FULL:除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据。
十九、讲一讲Hystrix是什么?有什么作用?
在复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
而Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
二十、请你分别说一说服务降级和服务熔断的概念
服务降级:服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,调用备选fallback方法。比如程序运行导常(数组下标越界、除数分母为0)、超时等会触发降级。
服务熔断:类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示。服务熔断也是一种服务降级方式。
1、调用失败会触发降级,而降级会调用fallback方法。
2、但无论如何降级的流程一定会先调用正常方法再调用fallback方法。
3、假如单位时间内调用失败次数过多,也就是降级次数过多,则触发熔断。
4、熔断以后就会跳过正常方法直接调用fallback方法。
5、所谓“熔断后服务不可用”就是因为跳过了正常方法直接执行fallback。
二十一、服务熔断重要的三个参数是什么?
1、快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
2、请求总数阀值:在快照时间窗内,必须满足请求总数阀值才有资格熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
3、错误百分比阀值:当请求总数在快照时间窗内超过了阀值,比如发生了30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阀值情况下,这时候就会将断路器打开。
二十二、Hystrix有哪些常用注解?
@HystrixCommand、@EnableHystrix、@DefaultProperties
二十三、Hystrix组件有个Dashboard,你了解过吗?
Dashboard是Dashboard组件的图形化页面,Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少请求多少成功,多少失败等。
二十四、GateWay是什么?
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5,Spring Boot 2和Project Reactor等技术。
Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能,例如:熔断、限流、重试等。
SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
二十五、SpringCloud Gateway与Zuul的区别?
(1)Zuul 1.x使用的是传统的Serviet IO处理模型。而Gateway使用的是异步非阻塞模型,效率很高。在性能方面,根据官方提供的基准测试,Spring Cloud Gateway的RPS(每秒请求数)是Zuul的1.6倍。
(2)Gateway还支持WebSocket,并且与Spring紧密集成拥有更好的开发体验。
二十六、能简单讲一讲GateWay的非阻塞异步模型吗?
Zuul1.x模型
Springcloud中所集成的Zuul版本,采用的是Tomcat容器,使用的是传统的Serviet IO处理模型。
该模型的缺点是:
Servlet是一个简单的网络IO模型,当请求进入Servlet container时,Servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的。但是一旦高并发(如抽风用Jmeter压),线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势。
所以Zuul 1.X是基于servlet之上的一个阻塞式处理模型,即Spring实现了处理所有request请求的一个servlet (DispatcherServlet)并由该servlet阻塞式处理处理。所以SpringCloud Zuul无法摆脱servlet模型的弊端。
Gateway模型
传统的Web框架,比如说: Struts2,SpringMVC等都是基于Servlet APl与Servlet容器基础之上运行的。
但是在Servlet3.1之后有了异步非阻塞的支持。而WebFlux是一个典型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。相对于传统的web框架来说,它可以运行在诸如Netty,Undertow及支持Servlet3.1的容器上。非阻塞式+函数式编程(Spring 5必须让你使用Java 8)。
Spring WebFlux是Spring 5.0 引入的新的响应式框架,区别于Spring MVC,它不需要依赖Servlet APl,它是完全异步非阻塞的,并且基于Reactor来实现响应式流规范。
二十七、GateWay有三个核心概念,你知道是什么吗?
1、Route(路由) - 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如断言为true则匹配该路由。
2、Predicate(断言) - 参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由。
3、Filter(过滤) - 指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
举例:我去医院看牙科(请求),门卫大爷(Filter过滤)说不管你要看什么,必须先做核酸。当我做完核酸后门卫大爷让我进去了。这时我拿着手机上的挂号信息与医院的挂号信息相匹配(Predicate断言),匹配上了我可以找大夫看病了(路由)。
二十八、GateWay常用的Predicate断言有哪些?
After:比如在某段时间后才可以执行路由。这个After大多用在维护开服时间,比如游戏准备22年10月1日开服,那用After可以设置此时间之后的路由才好使。
Before:与After异曲同工。
Between:在两个时间段内才可执行路由。
Cookie:通过Cookie值去匹配。
Header:根据请求头信息来进行匹配。
二十九、GateWay中自定义全局过滤器如何实现?
主要实现两个接口:
- GlobalFilter
- Ordered
三十、SpringCloud Config是什么?有什么用处?
config是分布式配置中心,分布式系统面临的问题是,微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
比如你现在有40个微服务都用的一个叫test的数据库,如果我们修改了数据库的名字,那还要每个微服务的配置文件都改一遍吗,所以我们需要Config进行集中式管理。
三十一、SpringCloud中,使用过全局事件总线bus吗?如果使用过请简单的谈一谈
bus一般配合config进行使用,config配置中心具有一个痛点,就是当你改了配置文件,你需要一个个的手动去通知到下面的服务,这样很麻烦。而bus就轻松的解决了这点,Spring Cloud Bus目前支持RabbitMQ和Kafka。
ConfigClient实例都会监听MQ中同一个topic(默认是Spring Cloud Bus)。当一个服务刷新数据的时候,它会把这个信息放入到Topic中,这样其它监听同一Topic的服务就能得到通知,然后去更新自身的配置。
三十二、SpringCloud中,使用过Stream消息驱动吗?如果使用过请简单的谈一谈
常见MQ(消息中间件):
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
有没有一种新的技术诞生,让我们不再关注具体MQ的细节,我们只需要用一种适配绑定的方式,自动的给我们在各种MQ内切换。(类似于Hibernate)
Cloud Stream是什么?屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。
其实Hibernate就是这个意思,我们不用关心它用的是oracle还是mysql,它给我们提供了session.create(),我们用就好了,不用关心具体的语法,我们也不可能所有数据库都精通。
比方说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,像RabbitMQ有exchange,kafka有Topic和Partitions分区。
这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候Spring Cloud Stream给我们提供了—种解耦合的方式。
三十三、假如说我们的分布式项目链路很多,有很多节点,那么如何跟踪这些链路呢?
使用SpringCloud Sleuth技术。在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。通过Sleuth技术可以通过页面来对各个节点链路进行跟踪,哪个节点出了问题,都会有所展现。
三十四、除了Eureka、Zookeeper、Consul,你还知道什么服务注册中心的组件吗?
知道,还有阿里出的Nacos。Nacos就是注册中心+配置中心的组合 -> Nacos = Eureka+Config+Bus。可以替代Eureka做服务注册中心,还可以替代Config做服务配置中心。
三十五、你刚刚提到Nacos,那与其它几种注册中心组件有什么区别吗?
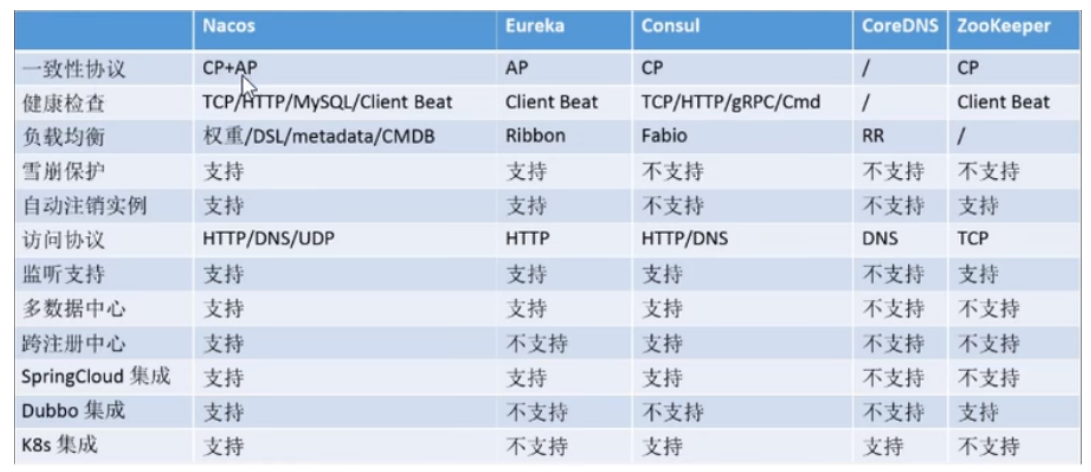
Nacos支持AP和CP模式的切换。
三十六、Hystrix与Sentinel有什么区别吗?
首先它们俩都相当于断路器的作用,用来服务降级、服务熔断、流量控制等功能。
区别在于:
Hystrix
需要我们程序员自己手工搭建监控平台。
没有一套web界面可以给我们进行更加细粒度化得配置流控、速率控制、服务熔断、服务降级。
Sentinel
单独一个组件,可以独立出来。
直接界面化的细粒度统一配置。
三十七、简单说一说Sentinel都有哪些流控规则?
(1)QPS:当每秒超过设定的QPS就会失败。
(2)线程数:表示一个时间段只能有1个(自己随便设定)线程数访问。
(3)关联:当关联的资源达到阈值时,就限流自己。当与A关联的资源B达到阈值时,就限流A自己。B惹事,A挂了。
(4)预热:一个系统最怕平常访问量是0,然后突然一秒钟那一瞬间访问量是10万,这时候就不太好了,应该先预热一下。