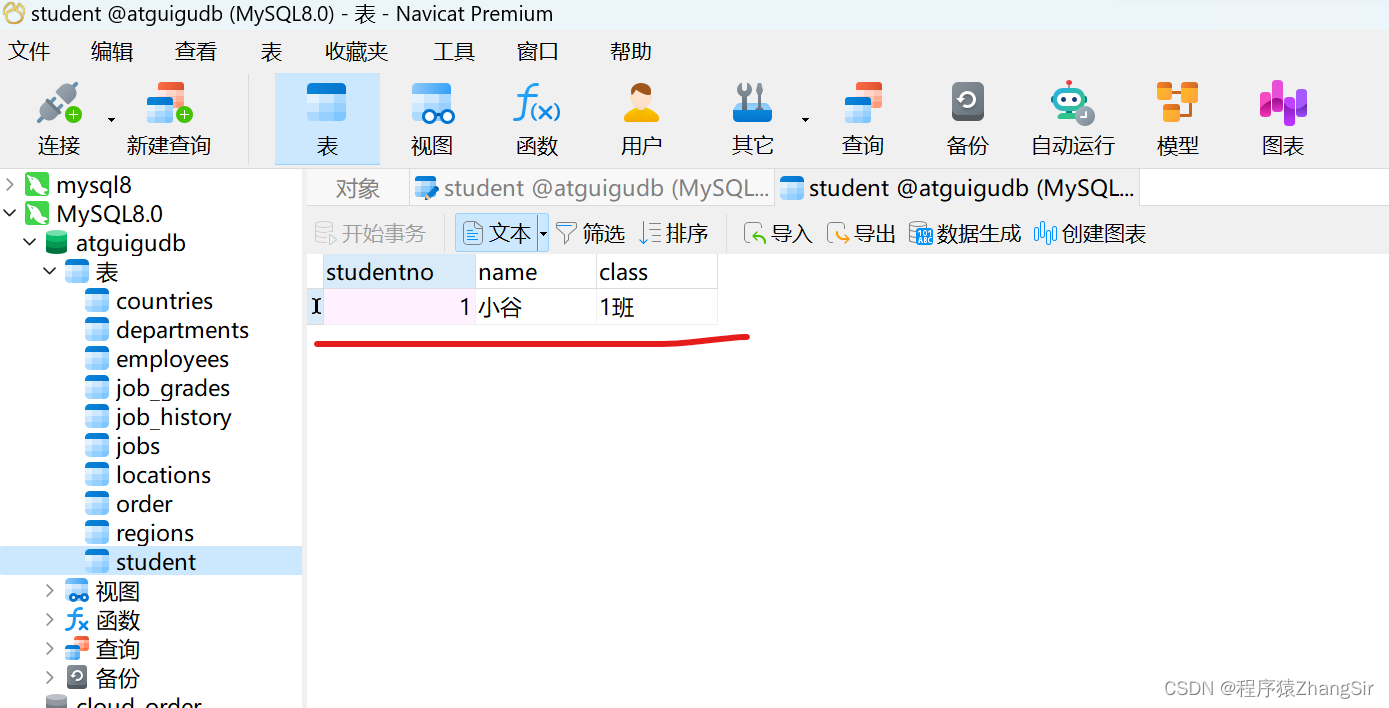
我们通过如下语句先创建一个 student 学生表。我就以对学生表的操作来解释什么是脏写,脏读,幻读,不可重复读

创建完成之后随便插入一条数据
1. 脏写?
对于两个事务 SessionA,SessionB,如果SessionA修改了另一个未提交的SessionB修改过的数据,这种现象我们称为脏读。过程如下图所示

假设我们对刚才的 student 学生表做一些操作,SessionA事务修改学号为1的姓名为张三,SessionB事务修改学号为1的姓名为李四。
第一步:SessionA开始了修改姓名这个事务操作;
第二步:SessionB也开始了修改姓名这个事务操作;
第三步:SessionB完成了修改姓名这一步操作,并在内存中进行了提交,但未保存至磁盘;
第四步:SessionA完成了修改姓名这一步操作,并在内存中进行了提交,也未保存至磁盘;
第五步:SessionA开始将数据写入磁盘,进行持久化保存;
第六步:SessionB事务中途出现了一些状况,事务回滚;
因为SessionA是在SessionB之后修改的姓名,SessionB回滚就会将SessionA所写的数据张三回滚成原来的小谷,这样的话,表面看来,SessionA顺利进行,实际上由于SessionB的回滚操作,导致我们SessionA的写操作根本没有成功,但我们得到的却会是SessionA事务执行成功,这种现象就是脏写。
2. 脏读?
对于两个事务SessionA,SessionB。SessionA读取了SessionB更新了但未提交的数据,之后若SessionB进行了回滚,那么SessionA读取到的数据就是临时而且无效的数据,这种现象称为脏读。过程如下图所示

假设事务SessionA要查询学号为1的学生信息,事务SessionB要修改学号为1的学生信息。
第一步:SessionA开始事务操作;
第二步:SessionB也开始事务操作;
第三步:SessionB修改了学号为1的学生信息,并在内存进行了暂时提交,未最终提交;
第四步:SessionA查询学号为1的学生信息,查询到的是SessionB刚刚修改过的信息;
第五步:SessionA查询之后,返回数据,并提交事务;
第六步:SessionB再提交的过程中出现错误,事务回滚;
因为SessionB进行了回滚,那么SessionB所作的修改都会被撤回,更新操作未成功,但是我们的SessionA中读取到的是SessionB暂时更新后的数据,此时查询到的数据与保存在数据库中的真实数据不相同,这种情况就称为脏读。
3. 不可重复读
两个事务 显式SessionA,隐式事务SessionB。(这里说一下,显式事务需要手动开启和提交,而隐式事务会自动开启和提交) SessionA从数据库读取到了一条数据,SessionB更新SessionA读取的那条数据并提交,此时SessionA事务再次进行查询该数据,发现这一次查询的结果与上一次不同,两者不一致,这种现象被称为不可重复读。过程如下图所示

第一步:SessionA开始事务;
第二步:SessionA查询学号为1的学生信息,查询到王五;
第三步:SessionB修改了学号为1的学生姓名;
第四步:SessionA再次查询,发现查询到的是SessionB修改后的张三,与刚才读到的数据王五不一致,后面第五第六步是再次修改和查询。
因为SessionA在查询到王五之后,可能去执行其他SQL语句了。然后SessionB对其作了修改,SessionA再次查询数据,发现数据不一致,这种情况称为不可重复读。这里注意,不可重复读重点关注的是每一行的数据是否一致,不过分关注读取到的数据量是否相同。
4. 幻读
两个事务 SessionA,SessionB。SessionA从一个表中读取到了某些字段的值,然后SessionB在表中添加了一些新的数据,SessionA再次去读的时候,发现多了一些数据,这种现象称为幻读。过程如下图所示

第一步:SessionA开启事务;
第二步:SessionA查询数据,之查询到了一条满足条件的数据张三;
第三步:SessionB向表中添加了一些新的数据;
第四步:SessionA再次查询数据,发现满足条件的数据变多了,像产生了幻觉一样,这种情况就是幻读。还有一种情况就是SessionB执行的是删除操作,当SessionA再次查询时,发现少了一些记录,也可以称作幻读。幻读主要关注读取到的数据量是否与之前一致,这一点与刚才的不可重复读略有区别。
5. 四种隔离级别
上面我们提到了脏写,脏读,不可重复读,幻读四种可能发生的并发问题,它们的严重程度也是有先后之分的,在我们看来,他们的严重程度是 脏写 > 脏读 > 不可重复度 > 幻读。
在我们的理想状态下,当然是希望将上面的四个问题全部解决,但是这样做,会导致我们数据库并发能力非常弱,这对于我们业务高并发是不兼容的,因此在实际开发过程中,我们通常会设置一些隔离级别,这些隔离级别越低,并发问题发生的就越多,但同时并发能力越高。
SQL 标准中一共设立了四种隔离级别。
READ UNCOMMITTED:读未提交,在这种隔离级别下,我们的事务可以读取到其他事务还没有提交的数据。不能避免脏读,不可重复读,幻读。
READ COMMITTED:读已提交,它满足了事务的简单特性,一个事务只能看到一个已经提交事务所作出的改变。这个隔离级别也是大多数数据库默认的隔离级别,可以避免不可重复读,幻读。
REPEATABLE READ:可重复读,当事务A读取到一条数据时,若事务B对该数据做了修改,事务A再次查询此数据,查询到的还是原来未修改的数据,解决了不可重复读,脏写,脏读的问题。
SERIALIZABLE:可串行化,确保一个事务可以从一个表中读取相同的行,在这个事务持续期间,其他事务不能对该表进行插入,修改,删除操作,所有的并发问题都得到了解决,但是效率确实非常的低。
上述四种隔离级别都解决了脏写的问题,因为脏写问题是最为严重的,所以上述四种隔离级别都解决了脏写问题,大致可以总结为以下一张图表

其实通过上面的介绍,同学们应该也能看出来一个特点,数据库的隔离程度越高,并发效率越低;数据库的隔离程度越低,并发效率越高。