导出文件流下载,拦截器统一处理配置
- 需求
- 以往实现的方法(各自的业务层写方法)
- 现在实现的方法(axios里拦截器统一配置处理)
- 把文章链接复制粘贴给后端,让大佬自己赏阅。
需求
之前实现的导出都是各自的业务层,调用接口,使用blob对象转换,最终a标签导出,需要自定义文件名跟文件后缀。
现在统一在拦截器配置,根据后端返回的response.headers解析是否是文件流,统一做配置处理,然后对后端返回的filename进行转码,后端统一配置文件名及类型。前端只管a标签下载即可。
以往实现的方法(各自的业务层写方法)
//数据导出
indexExport() {
let statYear = {
statDate: this.form.statDate,
dataType: "1",
};
let infoMsg = this.$notify.info({
title: "消息",
message: "正在下载文件,勿退出,请稍后",
duration: 0,
});
gljyjcDataExport(statYear).then((res) => {
infoMsg.close(); //下载成功,等待下载提示框关闭
this.$notify({
title: "成功",
message: "下载完成",
type: "success",
});
let blob = new Blob([res], {
type: "",
});
let url = window.URL.createObjectURL(blob);
const link = document.createElement("a"); // 创建a标签
link.href = url;
link.download = "数据清单(" + this.form.statDate + ").xlsx"; // 重命名文件
link.click();
URL.revokeObjectURL(url); // 释放内存
});
},
现在实现的方法(axios里拦截器统一配置处理)
主要看注释行“文件下载”,因为后端返回流文件时候携带的response.headers会多Content-Disposition这个字段。然后拿到里边的filename后,对filename包含的信息进行转码就可
decodeURIComponent、decodeURI都可进行转码,具体二者有啥区别,水平有限没大看懂,可自行百度查阅符合选项
//拦截器里肯定有请求拦截代码axios.interceptors.request。怕展示代码冗余就不多贴了
...
axios.interceptors.response.use(
response => {
const res = response.data;
const config = response.config;
console.log(response.headers,"response.headers")//这块可以看一下response.headers究竟是什么
// 文件下载(主要看这块)
if (response.headers['content-disposition']) {
let downLoadMark = response.headers['content-disposition'].split(';');
if (downLoadMark[0] === 'attachment') {
// 执行下载
let fileName = downLoadMark[1].split('filename=')[1];
if (fileName) {
//fileName = decodeURIComponent(filename);//对filename进行转码
fileName = decodeURI(fileName);
if (window.navigator.msSaveOrOpenBlob) {
navigator.msSaveBlob(new Blob([res]), fileName);
} else {
let url = window.URL.createObjectURL(new Blob([res]));
let link = document.createElement('a');
link.style.display = 'none';
link.href = url;
link.setAttribute('download', fileName);
document.body.appendChild(link);
link.click();
return;
}
} else {
return res;
}
}
}
// 全局异常处理(获取code做正常的拦截操作,根据自己的业务层code写符合的就可)
if (res.code !== CODE_SUCCESS) {
if (res.code == '205') {
Message.error({ message: res.data || "登录失败" });
store.dispatch("user/logout").then(() => {
window.location.reload();
});
return
}
if (res.code === WARN_TIP) {
Message.warning({
message: res.message
});
}
if (res.code === LOGIN_FAIL) {
Message.error({ message: res.message || "登录失败" });
}
// 其他状态码特殊处理
return Promise.reject(new Error(res.message || "Error"));
}
return res;
}, error => {
// 防重复提交
if (error.message) {
allowRequest(reqList, error.message.url);
}
if (error.response) {
if (error.response.data.code == 600 && !tipCode) {
tipCode = true;
Message.error({ message: '系统登录身份令牌失效,请重新登录!' });
} else if (error.response.status == 500) {
Message.error({ message: '系统异常' });
}
}
return Promise.reject(error);
}
);

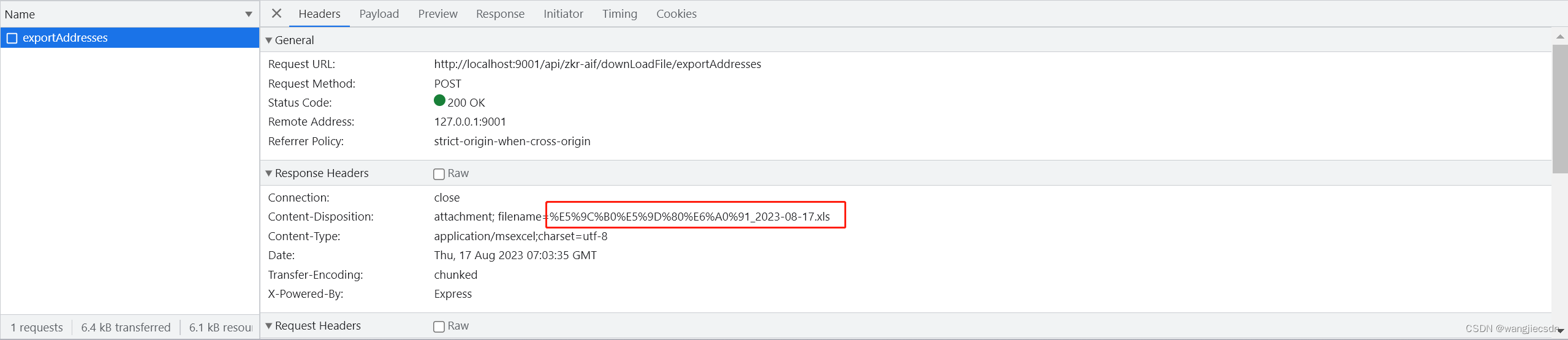
以上是未解析之前浏览器看到的文件夹名
经过decodeURIComponent或decodeURI解析后,前端就能获取到后端返回的中文文件名了。
把文章链接复制粘贴给后端,让大佬自己赏阅。
截止目前,前端能干的活就到此为止了。
那么有人就想问了,那后端response.headers里没返回我想要的Content-Disposition,前端怎么捕获。
对此呢,我又找我们后端大佬要了一下后端实现的代码,我就原封不动贴出来了,因为我根本看不懂说的是什么意思
Controller端代码(啥是Controller,根本不懂)
@PostMapping(value="/exportAddresses")
public Result exportAddresses(HttpServletResponse response){
String[] titles = new String[] {"id","tableCode","columnName"};
List<Map<String,Object>> objList = new ArrayList<>();
DownLoadFileController addressService;
List<NpColumns> npColumnsList = npColumnsService.findByTableCode("APP_TASK_CASE_INFO");
for(NpColumns item : npColumnsList){
Map<String,Object> tempMap = new HashMap<>();
tempMap.put("id", item.getId());
tempMap.put("tableCode", item.getTableCode());
tempMap.put("columnName", item.getColumnName());
objList.add(tempMap);
}
try {
FileUtils.exportExcel(response,"地址树",titles,objList);
return ResultGenerator.genSuccessResult("导出成功!");
}catch (Exception e){
e.printStackTrace();
return ResultGenerator.genFailResult("导出失败!");
}
}
工具类方法(啥是工具类,也不懂)
public static void exportExcel(HttpServletResponse response,String fileName,String[] titles,List<Map<String,Object>> result){
HSSFWorkbook wb;
OutputStream output = null;
String tempName = fileName;
try {
Date date = new Date();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
fileName +="_"+df.format(date)+".xls";
String encodedFilename = URLEncoder.encode(fileName, "UTF-8");
wb= new HSSFWorkbook();
HSSFSheet sh = wb.createSheet();
// 设置列宽
for(int i = 0; i < titles.length-1; i++){
sh.setColumnWidth( i, 256*15+184);
}
// 第一行表头标题,CellRangeAddress 参数:行 ,行, 列,列
HSSFRow row = sh.createRow(0);
HSSFCell cell = row.createCell(0);
cell.setCellValue(new HSSFRichTextString(tempName));
//cell.setCellStyle(fontStyle(wb));
sh.addMergedRegion(new CellRangeAddress(0, 0, 0,titles.length-1));
// 第二行
HSSFRow row3 = sh.createRow(1);
// 第二行的列
for(int i=0; i < titles.length; i++){
cell = row3.createCell(i);
cell.setCellValue(new HSSFRichTextString(titles[i]));
//cell.setCellStyle(fontStyle(wb));
}
//填充数据的内容 i表示行,z表示数据库某表的数据大小,这里使用它作为遍历条件
int i = 2, z = 0;
while (z < result.size()) {
row = sh.createRow(i);
Map<String,Object> map = result.get(z);
for(int j=0;j < titles.length;j++) {
cell = row.createCell(j);
if(map.get(titles[j]) !=null) {
cell.setCellValue(map.get(titles[j]).toString());
}else {
cell.setCellValue("");
}
}
i++;
z++;
}
output = response.getOutputStream();
response.reset();
response.addHeader("Content-Type","application/octet-stream;charset=utf-8");
response.setHeader("Content-disposition", "attachment; filename="+encodedFilename);
response.setContentType("application/msexcel");
wb.write(output);
output.flush();
output.close();
}catch (Exception e){
e.printStackTrace();
}
}
最后还有个中文处理乱码那块(这都是啥啥啥,还是不懂)
String encodedFilename = URLEncoder.encode(fileName, "UTF-8");设置文件名的中文编码
response.addHeader("Content-Type","application/octet-stream;charset=utf-8");//这里也设置了相同的编码格式
response.setHeader("Content-disposition", "attachment; filename="+encodedFilename);
大家有更好的实现方案话欢迎多交流



![java八股文面试[java基础]——String StringBuilder StringBuffer](https://img-blog.csdnimg.cn/84d235ec45c4452897adb62867caeaeb.png)






![[Flash CS6]使用AIR拓展屏幕](https://img-blog.csdnimg.cn/189d0b9fc0b4456c8d19112706603715.png)