📖 前言:决策树(Decision Tree)是一种通过对历史数据进行测算,实现对新数据进行分类和预测的算法。机器学习中,决策树是一个预测模型,代表的是对象属性与对象值之间的一种映射关系。该算法由于逻辑结构为树形结构,所以被称为“决策树”。在做重要决策时,我们通常会听取多个专家而不是一个人的意见。综合多个不同专家的意见通常好过只听一个人的意见,即所谓的“群智”。类似地,在机器学习中,可以训练多个学习器来完成预测任务(分类或回归),然后通过结合多个学习器的预测结果得到最终的结果,这就是集成学习(ensemble learning)。

目录
- 🕒 1. 不同分类器的特点
- 🕘 1.1 K近邻
- 🕘 1.2 逻辑回归
- 🕘 1.3 决策树
- 🕒 2. 决策树概述
- 🕘 2.1 离散值
- 🕘 2.2 连续值
- 🕒 3. 创建决策树
- 🕘 3.1 结构
- 🕘 3.2 信息熵与信息增益
- 🕘 3.3 流程
- 🕘 3.4 划分(对不纯度的度量)
- 🕤 3.4.1 分类误差率
- 🕤 3.4.2 熵
- 🕤 3.4.3 基尼指数
- 🕤 3.4.4 三者联系
- 🕒 4. 修剪决策树
- 🕘 4.1 预剪枝
- 🕘 4.2 后剪枝
- 🕒 5. 决策树小结
- 🕘 5.1 优缺点
- 🕘 5.2 语法
- 🕒 6. 集成学习
- 🕘 6.1 概述
- 🕒 7. 袋装(Bagging)
- 🕘 7.1 概述
- 🕘 7.2 错误率与特征重要度
- 🕘 7.3 语法
- 🕘 7.4 随机森林(RF)
- 🕤 7.4.1 语法
- 🕘 7.5 超随机森林
- 🕤 7.5.1 语法
- 🕒 8. 提升(Boosting)
- 🕘 8.1 概述
- 🕘 8.2 AdaBoost
- 🕤 8.2.1 决策树桩
- 🕤 8.2.2 AdaBoost 伪码(了解)
- 🕤 8.2.3 语法
- 🕘 8.3 梯度提升(了解)
- 🕤 8.3.1 伪码
- 🕤 8.3.2 模型调节
- 🕤 8.3.3 语法
- 🕤 8.3.4 损失函数
- 🕒 9. 堆叠(Stacking)
- 🕘 9.1 概述
- 🕒 10. 综合案例:泰坦尼克号乘客生还预测
- 🕘 10.1 可视化决策树
- 🕘 10.2 特征重要度
- 🕘 10.3 训练和选择模型
- 🕤 10.3.1 决策树
- 🕤 10.3.2 随机森林
- 🕤 10.3.3 AdaBoost
- 🕤 10.3.4 梯度提升树
- 🕤 10.3.5 投票聚合模型
- 🕒 11. 课后习题
🕒 1. 不同分类器的特点
🕘 1.1 K近邻
- 模型就是训练数据
- 拟合训练数据很快
- 只是存储数据
- 预测比较慢
- 需要计算大量的距离
- 判定边界较灵活
🕘 1.2 逻辑回归
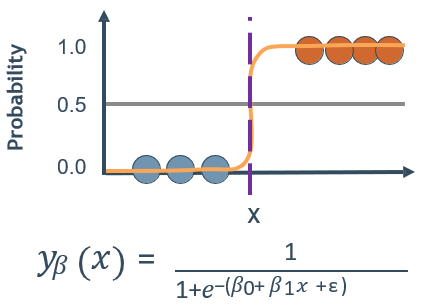
- 模型就是参数
- 拟合训练数据可能较慢
- 必须找到最优参数
- 预测较快
- 计算期望值
- 判定边界较简单,缺乏灵活性
🕘 1.3 决策树
决策树是一种最基本的分类与回归方法,与其他模型相比,决策树的原理浅显易懂,计算复杂度较小,而且具有可解释性,在现实中应用广泛。
🕒 2. 决策树概述
🕘 2.1 离散值
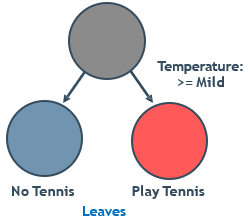
我们继续上次打网球的例子
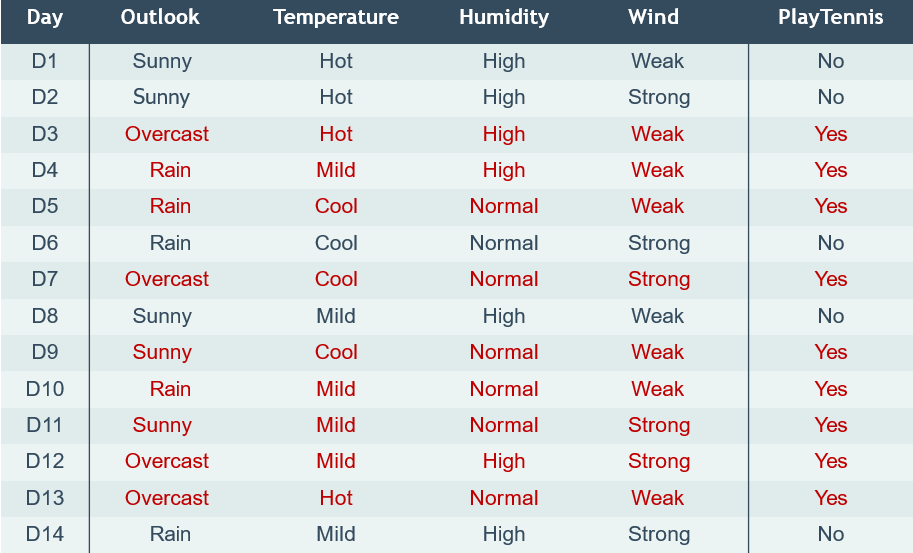
- 想要根据temperature, humidity, wind, outlook来预测是否打网球
- 使用特征来划分数据,进而预测结果
预测类别结果的决策树:
🕘 2.2 连续值
- 例如:使用喜马拉雅山脉的坡度和高度
- 预测平均降水量(连续值)
- 叶子节点的值是其所有成员的平均值
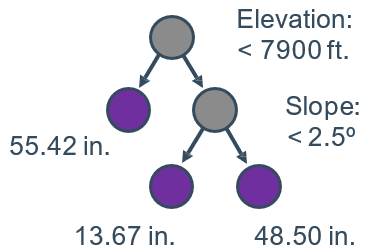
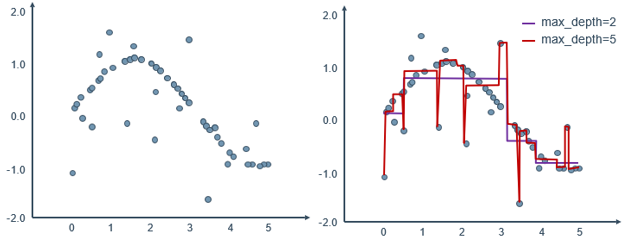
在线文档:🔎 预测连续值的回归树的语法
决策树是一种将实际问题“分而治之”的学习策略。机器可以通过逐一判断多个特征的取值,顺着决策树找到对应的分支,直至作出最终的决策。这种方法通常用于处理分类问题。例如,判断邮箱中的邮件是否为垃圾邮件、图片中的生物是动物还是植物等。
值得注意的是,决策树与回归分析有着显著的不同:决策树一般用于处理离散型数据的问题,如判断是否出游、是否买下商品等;而回归分析一般用于处理连续型数据的问题,如预测最终购买商品的价格、明天下雨的概率等。
🕒 3. 创建决策树
🕘 3.1 结构
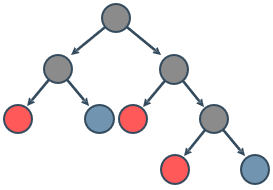
随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的纯度(purity)越来越高。
🕘 3.2 信息熵与信息增益
信息是很抽象的概念。人们常说信息量很大或很小,但却很难说清楚信息量到底有多少。比如,一本50万字的中文书籍到底包含多少信息量?直到1948年,克劳德·香农(Claude Shannon)提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是香农从热力学中借用的。热力学中的热熵是表示分子状态混乱程度的物理量,香农则用信息熵的概念来描述信息量的不确定度。
信息熵(entropy)是度量样本集合纯度的一种指标。假设当前样本集合
D
D
D中第
k
k
k类样本所占的比例为
p
k
(
k
=
1
,
2
,
⋯
,
∣
y
∣
)
p_{k}(k=1,2, \cdots,|y|)
pk(k=1,2,⋯,∣y∣),则
D
D
D的信息熵定义为:
Ent
(
D
)
=
−
∑
k
=
1
∣
y
∣
p
k
log
2
p
k
\operatorname{Ent}(D)=-\sum_{k=1}^{|y|} p_{k} \log _{2} p_{k}
Ent(D)=−k=1∑∣y∣pklog2pk
计算得到的值越小,
D
D
D的纯度越高。
假定离散特征
a
a
a有
V
V
V个可能的取值
{
a
1
,
a
2
,
⋯
,
a
v
}
\left\{a^{1}, a^{2}, \cdots, a^{v}\right\}
{a1,a2,⋯,av},若使用
a
a
a来对样本集进行划分,则会产生
V
V
V个分支节点,其中第
v
v
v个分支节点包含了
D
D
D中所有在属性
a
a
a上取值为
a
v
a^v
av的样本,记为
D
v
D^v
Dv 。可根据上面的公式计算出
D
v
D^v
Dv的信息熵。考虑到不同的分支节点所包含的样本数不同,需要给分支节点赋予权重
∣
D
v
∣
∣
D
∣
\frac{|D^v|}{|D|}
∣D∣∣Dv∣,即样本数越多的分支节点影响越大,于是可计算出用属性
a
a
a对样本集
D
D
D进行划分所获得的信息增益Gain(
D
,
a
D, a
D,a) :
Gain
(
D
,
a
)
=
Ent
(
D
)
−
∑
v
=
1
V
∣
D
′
∣
D
Ent
(
D
v
)
\operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{\prime}\right|}{D} \operatorname{Ent}\left(D^{v}\right)
Gain(D,a)=Ent(D)−v=1∑VD∣D′∣Ent(Dv)
一般而言,信息增益越大,意味着使用特征 a a a来进行划分所获得的“纯度提升”越大。因此,可以用信息增益来选择决策树的划分属性。著名的ID3决策树学习算法就是以信息增益为准则来选择决策树的划分属性的。
🕘 3.3 流程
选取一个特征,把数据分成两部分,构成一个二叉树;之后继续选取特征,划分数据
直到:
- 叶子节点纯了—仅包含一类实例
- 达到最大深度
- 达到某一性能指标
最后,给出每个叶节点的预测值。分类任务使用集合中样例个数最多的类别作为预测结果;回归任务则使用集合中所有样例的平均值作为预测结果。
🕘 3.4 划分(对不纯度的度量)
使用贪婪搜索:每一步寻找最优划分
🕤 3.4.1 分类误差率
分类误差率是指集合中任一样例被分错类别的概率。它是不纯度最直接的度量方法。
给定决策树中的一个节点 t t t,它预测的类别应该是 t t t中包含样例个数最多的类别。因为 t t t中所有的样例都被预测为出现概率最大的那个类别,所以 t t t的分类误差率,记为Error(t) ,我们也习惯称为分类错误(Classification Error):
E ( t ) = 1 − max [ p ( i ∣ t ) ] E(t) =1-\max [p(i \mid t)] E(t)=1−max[p(i∣t)]
式中, p ( i ∣ t ) p(i \mid t) p(i∣t)为集合 t t t中任一样例属于类别 i i i的概率。当 t t t中所有样例都属于同一类别,即最纯时,Error(t)取最小值0;当 t t t中各类别分布均匀,即各类别包含的样例个数相等时, p ( i ∣ t ) = 1 n ( i = 1 , 2 , … , n ) p(i \mid t)=\frac{1}{n} \ (i=1,2,…,n) p(i∣t)=n1 (i=1,2,…,n),Error(t)取最大值( 1 − 1 n 1-\frac{1}{n} 1−n1)。

可以看到,分类错误没有任何变化,也就是说,不纯度不变。由此可以看出,分类误差率对分类概率的改变不够敏感,导致生成低效的决策树。
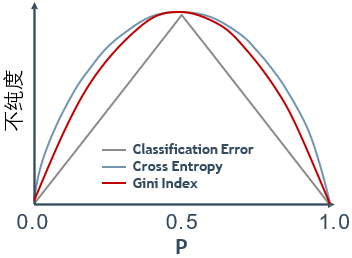
实际中更常用的度量不纯度的方法是熵和基尼指数。例如在当前流行的决策树构建算法中,ID3和C4.5都是基于熵的,而分类与回归树(classification and regression tree,CART)使用基尼指数度量节点的不纯度。
🕤 3.4.2 熵
设随机变量 X X X有 n n n个可能的取值 X i , ( i = 1 , 2 , … , n ) X_i,(i=1,2,…,n) Xi,(i=1,2,…,n),每个取值的概率是 p i ( i = 1 , 2 , … … , n ) p_i(i=1,2,……,n) pi(i=1,2,……,n),则 X X X的熵 H ( X ) H(X) H(X)为:
H ( X ) = − ∑ i = 1 n p i log 2 p i H(X) =-\sum_{i=1}^{n} p_i \log _{2}p_i H(X)=−i=1∑npilog2pi
给定决策树中的一个节点 t t t,其包含 n n n个类别的样例,每个类别出现的概率是 p ( i ∣ t ) ( i = 1 , 2 , … … , n ) p(i \mid t)(i=1,2,……,n) p(i∣t)(i=1,2,……,n),则节点 t t t的熵 E n t r o p y ( t ) Entropy(t) Entropy(t)的计算公式如下:
H ( t ) = − ∑ i = 1 n p ( i ∣ t ) log 2 p ( i ∣ t ) H(t) =-\sum_{i=1}^{n} p(i \mid t) \log _{2}p(i \mid t) H(t)=−i=1∑np(i∣t)log2p(i∣t)

类似于分类误差率,当节点中的所有样例都属于同一类别时,节点的熵取最小值0;当节点中各类别分布均匀,即各类别包含的样例个数相等时,节点的熵最大,等于 l o g 2 n log_2n log2n。
基于熵的划分允许继续分裂下去,最终达到叶子节点同质的目标(熵为0)
为什么熵可以达到这一目标,而分类错误不行?
🕤 3.4.3 基尼指数
基尼指数(Gini index),又称基尼系数,是国际上通用的衡量一个国家或地区居民收人分配不平等程度的常用指标。基尼指数是0~1之间的一个比值,其值越大,表示不平等程度越高。用基尼指数来衡量一个节点不纯度的计算方法如下。
给定决策树中的一个节点 t t t,其包含 n n n个类别的样例,每个类别出现的概率是 p ( i ∣ t ) ( i = 1 , 2 , … … , n ) p(i \mid t)(i=1,2,……,n) p(i∣t)(i=1,2,……,n),则节点 t t t的基尼指数 G i n i ( t ) Gini(t) Gini(t)的计算公式如下:
Gini ( t ) = ∑ i = 1 n p ( i ∣ t ) [ 1 − p ( i ∣ t ) ] = 1 − ∑ i = 1 n p ( i ∣ t ) 2 \operatorname{Gini}(\mathrm{t}) =\sum_{i=1}^{n} p(i \mid t)[1-p(i \mid t)]=1-\sum_{i=1}^{n} p(i \mid t)^{2} Gini(t)=i=1∑np(i∣t)[1−p(i∣t)]=1−i=1∑np(i∣t)2
即节点 t t t的基尼指数,等于从 t t t中随机抽取两个样例,其类别不一样的概率。因而 t t t的基尼指数越小,表明其纯度越高,当 t t t中所有样例的类别都一样时,基尼指数达到最小值0;而 t t t的基尼指数越高,表明其不纯度越高,当 t t t中所有类别都包含相同个数的样例时,基尼指数达到最大值( 1 − 1 n 1-\frac{1}{n} 1−n1)。

🕤 3.4.4 三者联系
分类错误VS熵:
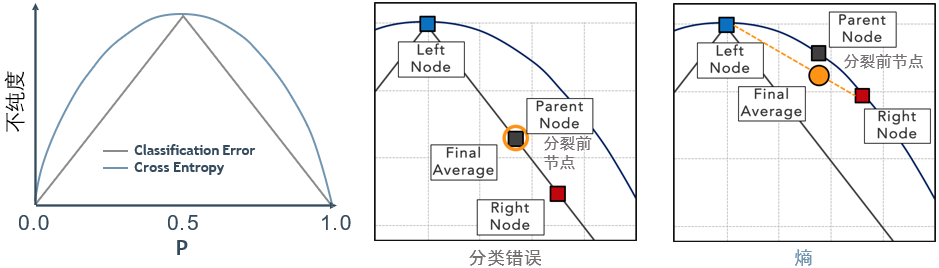
分类错误是一个平坦函数,在中心点达到最大值,中心点表示的是50 | 50的歧义划分,分类指标偏向于远离中心点的结果。最终的平均分类错误(分类后的左右节点加权平均)很有可能与父节点的分类错误相等(橙色圆圈),从而导致提前停止。
熵具有相同的最大值,函数有个“鼓包”,使得子节点的平均熵(橙色圆圈)少于父节点的熵,从而产生信息增益,曲度使得分裂可以继续到叶子节点纯了为止。
实际中,常使用基尼指数做分裂,其函数类似于熵——也有“鼓包”,但没有对数。
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
🕒 4. 修剪决策树
在决策树学习中,为了尽可能正确预测训练样例,节点划分过程将不断重复,直至叶节点纯了为止,这样通常会造成对训练数据的过拟合,数据微小的变化能对预测结果产生较大的影响,也就是高方差(high variance),导致学习出的决策树泛化能力较低。解决决策树过拟合问题的主要方法是剪枝。剪枝的基本策略有预剪枝(pre-pruning)和后剪枝(post-pruning)。
🕘 4.1 预剪枝
在决策树构建过程中,依据预先设定的条件,提前终止树的生长。
Scikit-Learn中可以设定的条件有:
- 决策树的最大深度(max_depth)
- 决策树的最大叶子数(max_leaf_nodes)
- 可分裂节点应包含的最少样例数(min_samples_split)
- 叶节点应包含的最少样例数(min_samples_leaf)
- 不纯度减少的最小量(min_impurity_decrease)
预剪枝使得决策树的很多分支都没有展开,不仅降低了过拟合的风险,还显著减少了决策树的训练时间。但另一方面,预剪枝可能会产生欠拟合。
🕘 4.2 后剪枝
在决策树构建完成之后进行剪枝,得到一棵简化的树。
自底向上地考察每个非叶节点,如果将其子树剪去,成为一个叶节点,能带来决策树泛化性能提升,则将该子树替换为叶节点。如何判断决策树泛化性能是否提升呢?可以使用留出法,预留一部分数据做“验证集”,验证泛化性能(叶节点剪去前后是否会降低错误率)这种最基本的后剪枝方法称为错误率降低剪枝 (reduced-error pruning, REP)
代价复杂度剪枝(cost-complexity, CCP)策略中,代价指在剪枝过程中一个非叶节点(子树)被替换为一个叶节点而带来的预测错误的增加;复杂度具体指子树中所包含的叶节点的个数。剪枝算法定义了一个参数 α α α来衡量剪枝的代价和复杂度降低之间的关系。 α α α的具体计算公式如下:
α = C ( t ) − C ( T t ) ∣ T t ∣ − 1 \alpha =\frac{\mathrm{C}(\mathrm{t})-\mathrm{C}\left(T_{t}\right)}{\left|T_{t}\right|-1} α=∣Tt∣−1C(t)−C(Tt)
T t T_t Tt为以 t t t为根节点的子树; ∣ 𝑇 𝑡 ∣ |𝑇_𝑡| ∣Tt∣为子树中叶节点的个数; C ( 𝑇 𝑡 ) C(𝑇_𝑡) C(Tt)和 C ( t ) C(t) C(t)分别是剪枝前后该子树的预测错误(sk-learn使用所有叶节点的不纯度之和来代替预测错误),sk-learn实现的后剪枝算法是先计算树中每个非叶节点的 α α α值,然后循环剪掉具有最小 α α α值的子树,直到最小 α α α值大于用户预先给定的参数值ccp_alpha为止。
- 复杂度:叶节点个数
- 剪枝代价:剪枝后预测错误(不纯度)的增加
- 策略基本思想,如果α(=代价/复杂度)足够小的话,则剪枝。
一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝训练时间比未剪枝和预剪枝决策树都要大得多。
🕒 5. 决策树小结
🕘 5.1 优缺点
优点:
- 容易实现和解释(if … then … else的逻辑)
- 可以处理任何数据类型(二值、序数、连续值)
- 几乎不需要数据预处理和缩放
缺点:非常容易过拟合,导致泛化能力不强
🕘 5.2 语法
导入包含分类方法的类:
from sklearn.tree import DecisionTreeClassifier
创建该类的一个对象:
DTC = DecisionTreeClassifier(criterion='gini’,max_features=10, max_depth=5)
# max_features:默认为null,使用所有特征(特征数小于50建议使用)
拟合训练数据,并预测:
DTC = DTC.fit(X_train, y_train)
y_predict = DTC.predict(X_test)
用交叉验证来调参,使用DecisionTreeRegressor做回归
在线文档:🔎 决策树分类器的语法
主要参数设置:
| 参数 | 说明 |
|---|---|
| criterion (划分条件选择标准) | DecisionTreeClassifier 的缺省值是 “gini”(基尼指数),也可以是 “entropy”(熵);DecisionTreeRegressor 的缺省值是 “mse"(均方误差),也可以是 “mae”(平均绝对值误差)。 |
| splitter (划分条件选择策略) | 缺省值是 “best", 即选取最优划分条件,也可以是 “random”,表示随机选取划分条件。 |
| max_depth(决策树的最大深度) | 缺省值没有深度限制。设置树的最大深度是为了防止过拟合。 |
| min_samples_split (节点可分裂的最少样例数) | 缺省值是 2。一个节点可以进一步分裂必须最少包含 min_samples_split 个样例。为了防止过拟合, 可以增大此值。 |
| min_samples_leaf (叶子节点的最少样例数) | 缺省值是1 。一个叶子节点必须最少包含 min_samples_leaf 个样例。 如果增大此值,可以及早停止过于细分叶子节点,防止过拟合。 |
| max_features (选择划分条件可考虑的最大特征数) | 缺省值没有最大特征数的限制,即可以考虑数据集中的所有特征。减少考虑的特征数,一来可以减少决策树的生成时间;二来可以增大决策树的随机性,有利于提升随机森林等集成学习模型的效果。 |
| max_leaf_nodes (最大叶节点个数) | 缺省值是不限制叶节点的个数。它和树的最大深度类似,可以防止过拟合。 |
| min_impurity_decrease (最小不纯度减少量) | 如果用某一划分条件划分节点带来的不纯度的减少量小于这个阈值,则不用此划分条件划分该节点。 |
| ccp_alpha (最小代价复杂度前枝方法中的 α \alpha α参数值) | 非负小数,缺省值0.0,即不进行后剪枝。 |
🕒 6. 集成学习
前面我们提到过决策树容易过拟合的问题,而剪枝有助于将方差减少到一定程度,但通常使模型泛化的效果并不显著。
解法方案:创建许多棵不同的树,结合所有树的预测来降低方差
🕘 6.1 概述
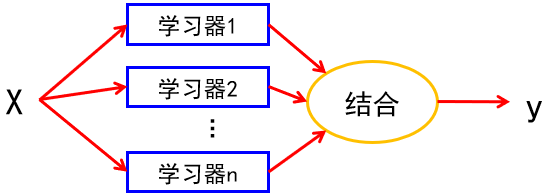
集成学习采用多个学习器对数据集进行预测,从而提高整体学习器的泛化能力。
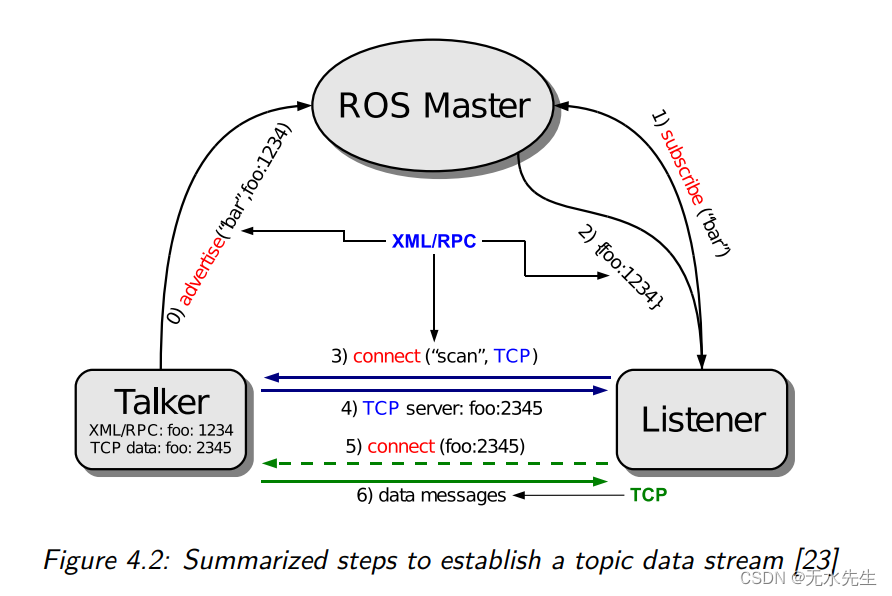
如下图,假设给定一个预测任务,训练了多个不同的学习器(1,2,…,m)。它们可以是同一种模型,例如都是决策树;也可以是不同种模型,例如学习器1是逻辑回归,学习器2是支持向量机,学习器3是决策树,学习器4是K近邻,等等。给定一个待预测样例X,每个学习器会产生一个预测结果,系统使用某种结合策略将这多个结果结合成一个最终结果y输出。
-
对于回归问题(数值预测):常用简单平均法。
-
对于分类问题(类别预测),常用多数投票法,即每个分类器预测出一个类别标签,相当于投该类别一票,得票最多的类别作为最终结果。
-
这种使用类别标签的投票又称硬投票(hard voting)。
-
有些类型的分类器可以输出类别的概率值,使用类别概率值的投票称软投票(soft voting)。
虽然分类器估计出的类别概率值一般不准确,但基于类别概率值的软投票往往比硬投票的性能更好,因为它相当于给分类器更确信的类别更大的权重。
这样一种将多个学习器结合在一起的集成学习器常常会获得比最好的单一学习器更好的性能。而且即使每个学习器都是弱学习器(即性能只比随机预测稍好的学习器),将它们集成起来却可以得到一个强学习器(即预测精度非常高的学习器),只要集成足够多的弱学习器,并且这些弱学习器之间的差异足够大,就像俗语说的“三个臭皮匠,顶个诸葛亮”。
“群智”预测成功要素:
- 问题:简单,且有唯一正确答案;
- 预测者:独立、有差异的个体(学习器)
可以用抛硬币的实验来简单类比。假设抛一枚有点儿偏斜的硬币,它落下来是正面的概率为51%,负面的概率为49%。也就是说,抛1 000次一般会得到大约510次正面和490次反面,正面占多数。事实上,重复抛1 000次硬币,正面占多数的概率接近75%,而且抛的次数越多,正面占多数的概率就越大,例如重复抛10 000次,正面占多数的概率将超过97%。这是由于大数定律:抛硬币的次数越来越多时,正面出现的次数比例就越来越接近它的概率(51%)。类似地,假设你集成了1 000个弱分类器,每个弱分类器的正确率是51%(即比随机猜测好一点点),用多数投票的结合方法,得到的集成学习器将达到75%的精度!但前提是各个学习器之间是完全独立的。因为所有学习器都是为解决同一个问题训练出来的,所以它们不可能完全独立。而要获得最佳的集成性能需要多个学习器尽可能相互独立或者说有差异,因而,集成学习的一个关键问题就是如何构建多个有差异的学习器。
如何构建一组有差异的学习器?
- 训练不同的机器学习模型,如决策树、K近邻、逻辑回归和支持向量机等。
- 训练同一种机器学习模型,但使用不同的数据集、不同的特征选择,或者不同的参数等,从而生成多个差异性学习器。
- 不同的数据集:在原有数据集上采用抽样技术获得多个训练数据集,从而生成多个差异性学习器。流行的方法有袋装和提升。
- 不同的特征选择:对训练数据抽取不同的输入特征子集分别进行训练,从而构建具有差异性的学习器。
- 不同的参数:通过改变一个模型的参数来生成有差异性的学习器,比如改变神经网络的网络拓扑结构就可以构建出不同的学习器。
同种类型的个体学习器的集成(比如学习器全是决策树)是“同质”的(homogeneous)、同质集成中的个体学习器亦称“基学习器”(base learner),相应的学习算法称为“基学习算法”(base learning algorithm)。集成也可包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成是“异质”的(heterogenous)。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法;相应的,个体学习器一般不称为基学习器,常称为“组件学习器”(component learner)或直接称为个体学习器。
下面主要讨论袋装、提升和堆叠三种最流行的集成学习方法。
🕒 7. 袋装(Bagging)
🕘 7.1 概述
袋装是是一种并行式的,通过对弱学习器(这里可一并视为弱学习器)进行综合来提升能力的集成学习方法。
首先,它使用自助采样法(bootstrapped sampling,一种有放回的随机抽样法)给定包含 n n n个样例的数据集,有放回的重复随机抽取 n n n次之后,就得到一个和原数据集一样大的数据集,去除重复出现的样例,新数据集包含原数据集中大约63.2%的样例。因为在包含 n n n个样例的数据集中,每个样例被随机抽到的概率是 1 n \frac{1}{n} n1,不被抽到的概率为 1 − 1 n 1-\frac{1}{n} 1−n1,则在 n n n次采样中都没被抽到的概率是 ( 1 − 1 n ) n (1-\frac{1}{n})^n (1−n1)n。当 n n n足够大时, ( 1 − 1 n ) n (1-\frac{1}{n})^n (1−n1)n值接近 1 e \frac{1}{e} e1,约等于0.368。也就是说, n n n次采样之后,原数据集中大约有36.8%的样例没被抽到,这些样例称为袋外(out-of-bag)样例,可用于评估学习器泛化性能,无须额外的验证集或做交叉验证。所以用自助采样法得到的数据集只包含原数据集中大约 2 3 \frac{2}{3} 32的样本。重复这一过程,由于是随机抽样,就可以得到多个不同的数据子集。
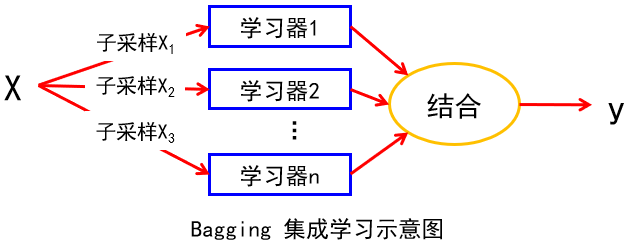
- 目标:降低方差(常见应用:不剪枝决策树和神经网络)
- 特点:并行执行、互不相干,代价与训练单一学习器相近,高效。
- 与决策树相同,输入数据可以是异构的,不要求预处理
由于只用 2 3 \frac{2}{3} 32的数据进行训练,每个基学习器的偏差会比使用整个数据集训练的单一学习器的偏差大,但是将这多个“较差”的学习器结合起来会降低整体的偏差和方差。
小结:一般地,Bagging比用整个数据集训练单一学习器可显著改善模型的方差,但对偏差未必有改善。
🕘 7.2 错误率与特征重要度
以决策树为例,bootstrapped样本为每棵决策树提供了内置的错误率估算,在数据子集上创建决策树,用未使用的样例来计算那棵树的错误率,称作袋外错误率。
拟合一个袋装模型不能像逻辑回归一样产生系数,特征的重要性因而要用袋外错误率来估算,为某一特征随机地排列数据,并计算精度的变化,用以衡量其重要性。
- RF(Random Forest):袋外数据排列检验。具体是打乱袋外数据中的特征项(加入噪声),打乱前后误差的绝对值反映了该特征的重要性。(下面会介绍)
- GBDT:特征的全局重要性是所有树中该特征重要性的均值,而单棵树中特征重要性等于该特征分裂导致的基尼不纯度减少之和。
- XGB:根据特征被选中为分裂节点的次数和来判断特征重要性。
Bagging模型的性能随着树的数目m增大而改进(m增加,整体模型的方差减少,防止过拟合的能力增强,模型的准确度得到提高。)一般在大约50棵树时获得最大的改进,150棵树以上性能基本保持不变。
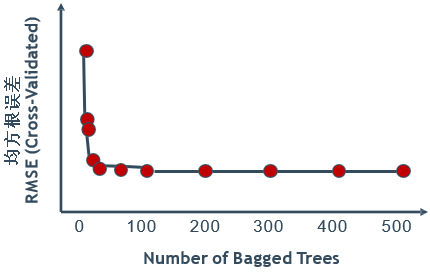
实际应用中,也可根据特征维数D设置学习器数目:分类问题为sqrt(D),回归问题为D/3。
🕘 7.3 语法
导入包含分类方法的类:
from sklearn.ensemble import BaggingClassifier # 分类器
#from sklearn.ensemble import BaggingRegressor # 回归器
创建该类的一个对象:
BC = BaggingClassifier(n_estimators=50)
拟合训练数据,并预测:
BC = BC.fit(X_train, y_train)
y_predict = BC.predict(X_test)
使用交叉验证调参。回归用BaggingRegressor。
在线文档:🔎 Bagging分类器的语法
主要参数设置:
| 参数 | 说明 |
|---|---|
| base_estimator (基学习器) | 在采样得到的数据子集上训练的基学习器。缺省值是None(使用决策树做基学习器)。 |
| n_estimators (基学习器个数) | 用于集成的基学习器的个数。缺省值是10。 |
| max_samples(最大样例个数) | 从训练集中随机抽取的,用于训练每个基学习器的样例数目。缺省值是1.0。整数值表示抽取样例的个数;小数值表示抽取样例数占训练集的总样例数的比重。 |
| max_features(最大特征数) | 从训练集中随机抽取的,用于训练每个基学习器的特征数目。缺省值是1.0。整数值表示抽取特征的个数;小数值表示抽取特征数占训练集的总特征数的比重。 |
| bootstrap(自助采样抽取样例) | 缺省值是True。 |
| bootstrap_features(自助采样抽取特征) | 缺省值是False。 |
| oob_score(是否使用袋外样例评估学习器的泛化错误 | 缺省值是False。 |
| n_jobs(并行运行的作业个数) | 缺省值是1。等于-1时,并行的作业个数设置为CPU的核数。 |
在sk-learn中,如果创建一个BaggingClassifier对象时,设置参数oob_score等于True,则系统会在训练时自动计算出整个集成学习器的袋外评估分数,存放在集成学习器的oob_score_变量中。
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
🕘 7.4 随机森林(RF)
定义:以决策树为基学习器的Bagging集成学习模型。
它先用Bagging 的随机抽样方法生成多个不同的训练数据集,然后在每个训练数据集上训练一棵决策树,再将多棵决策树的预测结果结合起来作为最终结果。与一般的决策树训练不同的是,它在决策树训练中引入了更大的随机性,因而获得了比一般的 Bagging集成模型更好的性能。
一般决策树考虑每个节点划分条件时,是从所有特征中选择一个最优的条件;而随机森林中的决策树是先从所有特征中随机抽取出一个特征子集,然后从这个特征子集中选择一个最优的条件。
特征个数为 m m m:
- 分类: m \sqrt{m} m
- 回归:介于 m 3 \frac{m}{3} 3m和 m m m之间的数
这样做会产生更多样的决策树,好处是避免一个非常强大的特征主导,从而产生相似的决策树。虽然每棵决策树的偏差增大了,但将它们结合起来会更大地降低整体方差,从而能得到更好的性能。
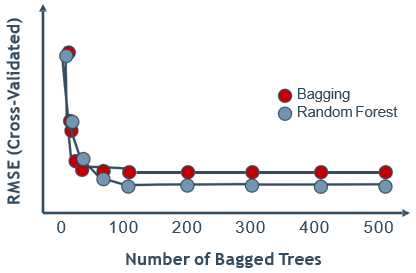
小结:在随机森林中,每棵决策树都是由一个数据集的子集和一个特征集的子集构建的。这种方法允许每棵决策树只考虑一个子集的特征,从而提高了随机森林的多样性,进而提高了模型的泛化能力。
🕤 7.4.1 语法
导入包含分类方法的类:
from sklearn.ensemble import RandomForestClassifier
创建该类的一个对象:
RC = RandomForestClassifier(n_estimators=100, max_features=10)
拟合训练数据,并预测:
RC = RC.fit(X_train, y_train) y_predict = RC.predict(X_test)
使用交叉验证调参数。回归用RandomForestRegressor。
在线文档:🔎 随机森林的语法
主要参数设置:
| 参数 | 说明 |
|---|---|
| n_estimators (基学习器个数,森林中树的个数) | 缺省值是10。 |
| criterion (分裂条件选择标准) | DecisionTreeClassifier 的缺省值是 “gini”(基尼指数),也可以是 “entropy”(熵);DecisionTreeRegressor 的缺省值是 “mse"(均方误差),也可以是 “mae”(平均绝对值误差)。 |
| max_features(选择分裂条件时考虑的最大特征数) | 有以下多种可能的取值:
|
| max_depth(决策树的最大深度) | 缺省值是None。如果为None,则节点会一直分裂下去直到每个叶节点都纯了或者叶节点包含的样例个数少于min_samples_split。 |
| min_samples_split (节点可分裂的最少样例数) | 缺省值是 2。一个节点可以进一步分裂必须最少包含的样例数。如果是小数,表示最少样例数占总样例数的比重。 |
| min_samples_leaf (叶节点的最少样例数) | 缺省值是1 。一个叶节点必须最少包含的样例数。如果是小数,表示最少样例数占总样例数的比重。 |
| max_leaf_nodes (最大叶节点个数) | 缺省值None,即不限制叶节点的个数。用最佳优先方式生长出最多包含max_leaf_nodes个叶节点的树。最佳优先指按不纯度降低量从大到小选择要分裂的节点。 |
| min_impurity_decrease (最小不纯度减少量) | 缺省值是0。如果用某一测试条件划分节点带来的不纯度的减少量小于这个阈值,则不用此测试条件划分该节点。 |
| bootstrap(自助采样抽取样例) | 缺省值是False。 |
| oob_score(是否使用袋外样例评估学习器的泛化错误 | 缺省值是False。 |
| n_jobs(并行运行的作业个数) | 缺省值是1。等于-1时,并行的作业个数设置为CPU的核数。 |
注:max_samples(固定为1.0)和 base_estimator(固定为DecisionTreeClassifier)。
🕘 7.5 超随机森林
超随机森林比随机森林拥有更多的随机性,每个节点是随机划分而不使用贪婪划分(即最优划分)。这样几乎完全随机生成的决策树必然会有更大偏差,但是具有更小的方差。不过无法断言超随机森林一定比随机森林性能更好或更坏。一般地,比较两者性能好坏的唯一方法是实际应用并通过交叉验证等方法来比较。另外,超随机森林模型比随机森林模型的训练更快,因为寻找最优条件更耗时。
🕤 7.5.1 语法
导入包含分类方法的类:
from sklearn.ensemble import ExtraTreesClassifier # 分类
from sklearn.ensemble import ExtraTreesRegressor # 回归
创建该类的一个对象:
EC = ExtraTreesClassifier(n_estimators=100, max_features=10)
拟合训练数据,并预测:
EC = EC.fit(X_train, y_train)
y_predict = EC.predict(X_test)
使用交叉验证调参。回归用ExtraTreesRegressor。
在线文档:🔎 超随机森林分类器的语法
🕒 8. 提升(Boosting)
🕘 8.1 概述
定义:提升是是一种串行式的,通过对弱学习器进行综合来提升能力的集成学习方法。它源于弱可学习和强可学习的等价性证明。与袋装不同,提升模型关注于改善模型的偏差。
一个概念(类)如果存在一个多项式时间内的学习算法(强学习算法)能够学习它,且正确率高,称其为强可学习;如果正确率不高,仅比随机猜测好(弱学习算法),称其为弱可学习。
等价性:其证明思路就是构造一个多项式时间算法,将弱学习算法可以提升为强学习算法。该算法即最初的Boosting算法。
当前最流行的两种 Boosting算法是AdaBoost(Adaptive Boosting)和梯度提升(Gradient Boosting)。大部分Boosting算法的基本思路都是依次训练一系列的弱学习器,每个弱学习器力图纠正前面学习器所犯的错误(不相互独立),最后将多个弱学习器加权结合起来。(笨鸟先飞)
🕘 8.2 AdaBoost
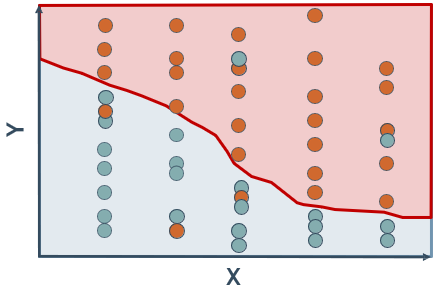
AdaBoost是最具代表性的Boosting算法。它通过调整训练集中样本的权重,使得下一个弱学习器的训练更多地关注被前面学习器预测错的样本(自适应提升),从而达到纠正错误的目的。
如下图所示,先用初始训练集训练出一个弱学习器;然后在训练集上做预测;增大预测错的样本的权重,使得这些样本在训练下一个弱学习器中得到更多的重视;接着用调整过样本权重的训练集训练下一个弱学习器等,如此重复下去(串行执行),直到训练得到的弱学习器个数达到预先设定的数目M。最后将这M个弱学习器加权结合。(举例:考完试后针对错误率高的知识点勤加练习)

🕤 8.2.1 决策树桩
决策树桩:Boosting算法的基学习器
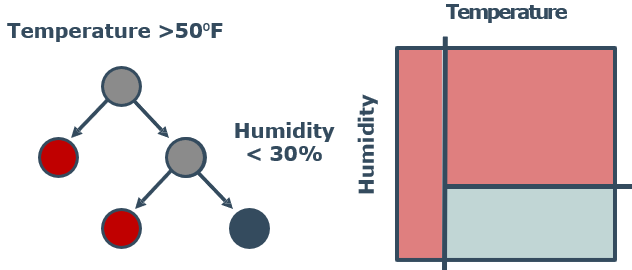
创建初始的决策树桩(①),拟合数据并计算残差,调整样例点的权重(红圈),发现新的决策树桩(②)来拟合加权残差,用新的决策树桩来拟合当前残差,计算误差,并修改数据点的权重(蓝圈),发现新的决策树桩(③)来拟合加权残差,用新的决策树桩来拟合当前残差。
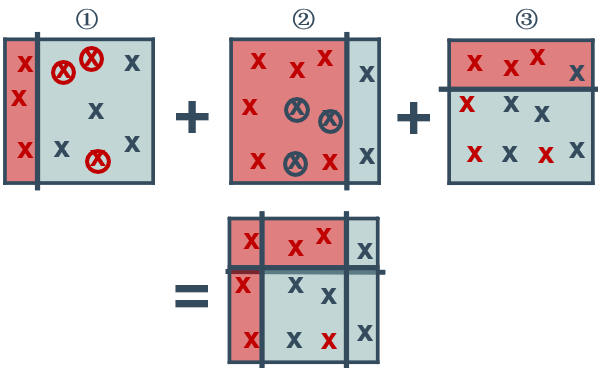
最后将多个决策树桩结合成一个分类器。可以看到仍有一个点是分类错误的。
预测结果等于多个分类器结果的加权和,相继的分类器加权λ(学习率),使用<1.0的学习率有助于防止过拟合(正则化)
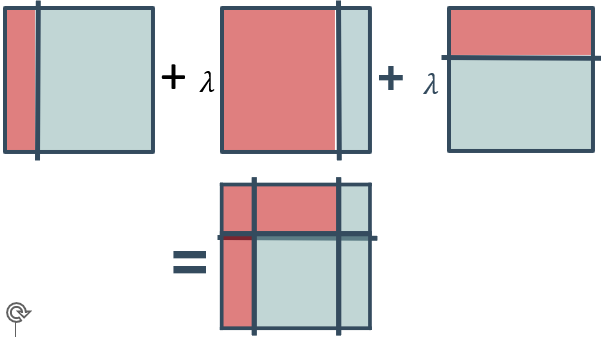
🕤 8.2.2 AdaBoost 伪码(了解)
下面用伪码方式给出AdaBoost 更细节的算法流程
- 给定包含n个样本的训练集 { x 1 , x 2 , … , x n x_1, x_2, …, x_n x1,x2,…,xn},初始化每个样本的权重 w i = 1 n ( i = 1 , 2 , . . . , n ) w_i = \frac{1}{n}(i=1,2,...,n) wi=n1(i=1,2,...,n)。
- 分别设
m
=
1
,
2
,
…
,
M
m = 1, 2, …, M
m=1,2,…,M,重复下面的步骤(a~f):
(a):在当前训练集上训练一个弱学习器: 𝐶 ( 𝑚 ) 𝐶^{(𝑚)} C(m)
(b):用训练出的弱学习器预测训练集中每个样例的类别: 𝐶 ( 𝑚 ) ( X i ) 𝐶^{(𝑚)}(X_i) C(m)(Xi);
(c):计算该弱学习器的加权错误率:
err ( m ) = ∑ i = 1 n w i I ( C ( m ) ( x i ) ≠ y i ) ∑ i = 1 n w i \operatorname{err}^{(m)}=\frac{\sum_{i=1}^{n} w_{i} \mathbf{I}\left(C^{(m)}\left(x_{i}\right) \neq y_{i}\right)}{\sum_{i=1}^{n} w_{i}} err(m)=∑i=1nwi∑i=1nwiI(C(m)(xi)=yi)
其中 I ( C ( m ) ( x i ) ≠ y i ) \mathbf{I}\left(C^{(m)}\left(x_{i}\right) \neq y_{i}\right) I(C(m)(xi)=yi)是指示函数,当 C ( m ) ( x i ) ≠ y i C^{(m)}\left(x_{i}\right) \neq y_{i} C(m)(xi)=yi成立时,值为1,否则为0。
(d):计算该弱学习器的权重值:
α ( m ) = η log ( 1 − e r r ( m ) ) e r r ( m ) \alpha^{(m)}=\eta \log \frac{\left(1-e r r^{(m)}\right)}{e r r^{(m)}} α(m)=ηlogerr(m)(1−err(m))
其中 η \eta η是学习率(权重缩减系数),是一个可以调节的超参数。一般0.0-1.0,默认1.0,缩减每个基学习器对最终结果的贡献。更小的学习率意味需训练更多的弱学习器。弱学习器的加权错误率越小,即预测越精准,它的投票权重越大。
(e):修改训练集中每个样例的权重: w i = w i exp ( α ( m ) I ( C ( m ) ( x i ) ≠ y i ) ) , i = 1 , 2 , … , n w_{i}=w_{i} \exp \left(\alpha^{(m)} \mathbf{I}\left(C^{(m)}\left(x_{i}\right) \neq y_{i}\right)\right), \quad i=1,2, \ldots, n wi=wiexp(α(m)I(C(m)(xi)=yi)),i=1,2,…,n
(f):归一化 w i w_{i} wi
w i = w i ∑ i = 1 n w i w_{i}=\frac{w_{i}}{ \sum_{i=1}^{n} w_{i}} wi=∑i=1nwiwi - 将M个训练好的弱学习器用加权投票法结合起来,得到最终的集成学习器C:
C ( x ) = argmax k ∑ m = 1 M α ( m ) I ( C ( m ) ( x ) = k ) C(x)=\underset{k}{\operatorname{argmax}} \sum_{m=1}^{M} \alpha^{(m)} \mathbf{I}\left(C^{(m)}(x)=k\right) C(x)=kargmaxm=1∑Mα(m)I(C(m)(x)=k)
其中, k k k为分类类别; argmax k \underset{k}{\operatorname{argmax}} kargmax表示选择得票最多的类别 k k k。
🕤 8.2.3 语法
导入包含该分类方法的类:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
创建该类的一个对象:
ABC = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(),learning_rate=0.1, n_estimators=200) # 基学习器可以被手工设置,这里也可以设置最大深度
拟合训练数据,并预测:
ABC = ABC.fit (X_train, y_train)
y_predict = ABC.predict(X_test)
使用交叉验证调节参数。回归用AdaBoostRegressor
在线文档:🔎 AdaBoost分类器的语法
主要参数设置:
| 参数 | 说明 |
|---|---|
| base_estimator (基学习器) | 缺省是使用决策树做基学习器。要求基学习器支持样本加权。 |
| n_estimators (基学习器个数) | 缺省值是50。集成的基学习器的最大个数。或者说算法的最大迭代次数,如果已经完美拟合数据了,则会提前停止。 |
| learning_rate(学习率) | 缺省值是1.0。一般设为0到1之间的值,收缩每个基学习器对最终结果的贡献量,也即每个基学习器的权重缩减系数。它和n_estimators之间存在一个折衷,一起来决定算法的拟合效果。如果要达到一定的拟合效果,更小的学习率意味着要训练更多的弱学习器。 |
| algorithm(AdaBoost分类算法(仅用于AdaBoostClassifier)) | 可能取值:“SAMME”或“SAMME.R”,缺省值是“SAMME.R”。Scikit-Learn中实现的AdaBoost分类算法实际是一个被称作SAMME的多分类算法版本,当只有两个类别时,SAMME就等同于AdaBoost。如果基学习器可以估算类别概率值(即它们有一个predict_prob()方法),则可以使用SAMME的一个变体SAMME.R(R表示“real”,即实数),它基于类别概率值而不是类别标签来计算弱学习器的权重。通常它比SAMME算法收敛更快,且测试错误率更低,但要求基学习器必须支持类别概率值的计算。 |
| loss(损失函数(仅用于AdaBoostRegressor)) | 可能取值:“linear”,“square”或“exponential”,缺省值是“linear”。每一轮调整样本权重时需要用到的损失函数,用于计算每一轮训练出的弱学习器在训练集中每个样本上的预测值与真实值之间的误差,可以是线性误差,平方误差或指数误差。 |
🕘 8.3 梯度提升(了解)
与AdaBoost基本类似,下面是不同点
- AdaBoost:修改样本的权重,关注前面学习器预测错误的样本
- 梯度提升(Gradient Boosting)算法:拟合前面学习器的残差(residual errors),以使结合起来的学习器误差更小。而为了消除残差,可以在残差减少的梯度方向上拟合一个新的模型。
加性模型(additive model):
F
(
x
)
=
∑
m
=
1
M
γ
m
h
m
(
x
)
\mathrm{F}(\mathrm{x})=\sum_{m=1}^{M} \gamma_{m} h_{m}(x)
F(x)=m=1∑Mγmhm(x)
其中, h m ( x ) h_m(x) hm(x)是基学习器,在 Boosting 集成中它们都是弱学习器;最终集成学习器 F ( x ) F(x) F(x)是由 m m m个弱学习器加权求和得到的; y m y_m ym是每个弱学习器的权重。
类似于其他Boosting方法,梯度提升算法也是使用前向分步方式来构建加性模型的,即每一步训练一个弱学习器,累加到总的学习器上。
F m ( x ) = F m − 1 ( x ) + γ m h m ( x ) \mathrm{F}_{m}(\mathrm{x})=\mathrm{F}_{m-1}(\mathrm{x})+\gamma_{m} h_{m}(x) Fm(x)=Fm−1(x)+γmhm(x)
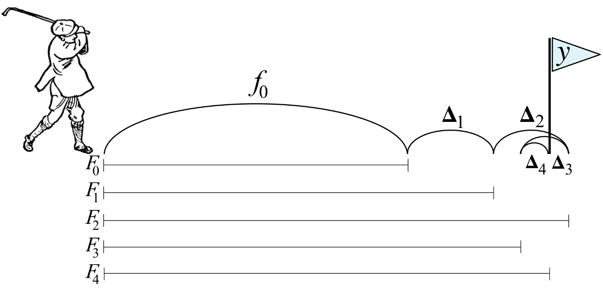
每一步弱学习器
h
m
(
x
)
h_m(x)
hm(x)的训练目标是减少当前模型的预测值
F
m
−
1
(
x
)
F_{m-1}(x)
Fm−1(x)和目标值
y
y
y之间的差距,更一般地,即最小化损失函数
L
(
y
,
F
m
−
1
(
x
)
+
h
m
(
x
)
)
L\left(y, F_{m-1}(x)+h_{m}(x)\right)
L(y,Fm−1(x)+hm(x)):
h m ( x ) = argmin h m ∑ i = 1 n L ( y i , F m − 1 ( x i ) + h m ( x i ) ) h_{m}(\mathrm{x})=\underset{h_{m}}{\operatorname{argmin}} \sum_{i=1}^{n} \mathrm{~L}\left(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)+h_{m}\left(x_{i}\right)\right) hm(x)=hmargmini=1∑n L(yi, Fm−1(xi)+hm(xi))
如果L是平方误差,则 h m ( x i ) ≈ y i − F m − 1 ( x i ) h_{m}\left(x_{i}\right) \approx \mathrm{y}_{i}-\mathrm{F}_{m-1}\left(x_{i}\right) hm(xi)≈yi−Fm−1(xi),右式即前 m − 1 m-1 m−1个学习器拟合后的残差。
对于任意可微的损失函数L,采用最速下降法来数值化地近似求解最小化问题,最速下降方向即损失函数在当前模型 F m − 1 F_{m-1} Fm−1下的负梯度,则
F m ( x ) = F m − 1 ( x ) − γ m ∑ i = 1 n ∇ F m − 1 L ( y i , F m − 1 ( x i ) ) \mathrm{F}_{m}(\mathrm{x})=\mathrm{F}_{m-1}(\mathrm{x})-\gamma_{m} \sum_{i=1}^{n} \nabla_{F_{m-1}} \mathrm{~L}\left(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)\right) Fm(x)=Fm−1(x)−γmi=1∑n∇Fm−1 L(yi, Fm−1(xi))
即每一步沿损失函数在当前模型的负梯度方向前进一定距离ym,以使得损失函数进一步减少。损失函数在当前模型的负梯度值可以被视为残差的近似值,称为伪残差(pseudo residuals)
因而对于任意可微的损失函数,梯度提升算法选择 h h h函数去拟合伪残差。
h m ( x i ) ≈ − [ ∂ L ( y i , F ( x i ) ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) h_{m}\left(x_{i}\right) \approx-\left[\frac{\partial L\left(y_{i}, F\left(\boldsymbol{x}_{\boldsymbol{i}}\right)\right)}{\partial F\left(\boldsymbol{x}_{i}\right)}\right]_{F(\boldsymbol{x})=F_{m-1}(\boldsymbol{x})} hm(xi)≈−[∂F(xi)∂L(yi,F(xi))]F(x)=Fm−1(x)
然后 γ m \gamma_m γm可以用线搜索方法通过下面公式计算出来:
γ m = argmin γ ∑ i = 1 n L ( y i , F m − 1 ( x i ) − γ ∑ i = 1 n ∇ F m − 1 L ( y i , F m − 1 ( x i ) ) ) \gamma_{m}=\underset{\gamma}{\operatorname{argmin}} \sum_{i=1}^{n} \mathrm{~L}\left(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)-\gamma \sum_{i=1}^{n} \nabla_{F_{m-1}} \mathrm{~L}\left(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)\right)\right) γm=γargmini=1∑n L(yi, Fm−1(xi)−γi=1∑n∇Fm−1 L(yi, Fm−1(xi)))
🕤 8.3.1 伪码
下面用伪码方式给出梯度提升算法的基本流程
-
初始化弱学习器为一个常数值:
F 0 ( x ) = argmin γ ∑ i = 1 n L ( y i , γ ) \mathrm{F}_{0}(\mathrm{x})=\underset{\gamma}{\operatorname{argmin}} \sum_{i=1}^{n} \mathrm{~L}\left(\mathrm{y}_{i}, \gamma\right) F0(x)=γargmini=1∑n L(yi,γ) -
分别设 m = 1 , 2 , … , M m = 1, 2, …, M m=1,2,…,M,重复下面的步骤:
(a):计算伪残差,即损失函数在当前模型 F m − 1 ( x ) F_{m-1}(x) Fm−1(x)下的负梯度:
r i m = − [ ∂ L ( y i , F ( x i ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) i = 1 , 2 , … , n r_{i m}=-\left[\frac{\partial \mathrm{L}\left(\mathrm{y}_{i}, F\left(x_{i}\right)\right.}{\partial F\left(x_{i}\right)}\right]_{F(x)=F_{m-1}(\mathrm{x})} \quad i=1,2, \ldots, n rim=−[∂F(xi)∂L(yi,F(xi)]F(x)=Fm−1(x)i=1,2,…,n
(b):训练一个弱学习器 h 𝑚 ( 𝑥 ) ℎ_𝑚 (𝑥) hm(x)拟合伪残差,即用训练集 { ( x i , r i m ) } i = 1 n \left\{\left(x_{i}, r_{i m}\right)\right\}_{i=1}^{n} {(xi,rim)}i=1n训练
(c):求解下面的一维优化问题得到 γ 𝑚 \gamma_𝑚 γm:
γ m = argmin γ ∑ i = 1 n L ( y i , F m − 1 ( x i ) − γ ∑ i = 1 n ∇ F m − 1 L ( y i , F m − 1 ( x i ) ) ) \left.\gamma_{m}=\underset{\gamma}{\operatorname{argmin}} \sum_{i=1}^{n} \mathrm{~L}\left(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)-\gamma \sum_{i=1}^{n} \nabla_{F_{m-1}} \mathrm{~L}(\mathrm{y}_{i}, \mathrm{~F}_{m-1}\left(x_{i}\right)\right)\right) γm=γargmini=1∑n L(yi, Fm−1(xi)−γi=1∑n∇Fm−1 L(yi, Fm−1(xi)))
(d):更新模型:
F m ( x ) = F m − 1 ( x ) + γ m h m ( x ) \mathrm{F}_{m}(\mathrm{x})=\mathrm{F}_{m-1}(\mathrm{x})+\gamma_{m} h_{m}(x) Fm(x)=Fm−1(x)+γmhm(x) -
输出最终模型: F M ( x ) \mathrm{F}_{M}(\mathrm{x}) FM(x)
🕤 8.3.2 模型调节
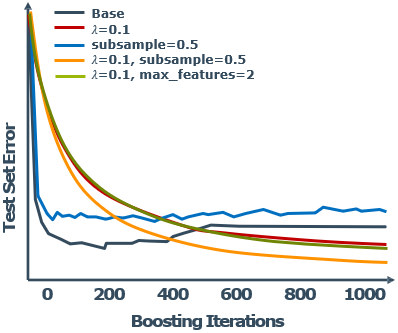
Boosting是递加的,所以可能过拟合,因此使用交叉验证来设置决策树的个数
- 学习率( γ \gamma γ):设为<1.0用于正则化。又称作“shrinkage”
- 子采样: γ \gamma γ设为<1.0,只使用部分数据用于训练基学习器(stochastic gradient boosting)
- 最大特征数:基学习器分裂时考虑的特征数目
🕤 8.3.3 语法
导入包含分类方法的类:
from sklearn.ensemble import GradientBoostingClassifier
创建该类的一个对象:
GBC = GradientBoostingClassifier(learning_rate=0.1,
max_features=1, subsample=0.5, n_estimators=200)
拟合训练数据,并预测:
GBC = GBC.fit (X_train, y_train)
y_predict = GBC.predict(X_test)
使用交叉验证调节参数,回归用GradientBoostingRegressor
在线文档:🔎 梯度提升分类器的语法
主要参数设置:
| 参数 | 说明 |
|---|---|
| loss (损失函数) | 分类和回归的损失函数不同。 对于分类,可以是对数似然损失“deviance”或者指数损失“exponential”,缺省值是“deviance”。使用“exponential”则等同于AdaBoost算法。 对于回归,可以是平方损失“ls”、绝对损失“lad”、Huber损失“huber”或分位数损失“quantile”,缺省值是“ls”。一般来说,如果数据的噪音点不多,用默认的“ls”比较好。如果噪音点较多,则推荐使用抗噪音的“huber”损失函数。如果我们需要对训练集进行分段预测时,则采用“quantile”损失函数。 |
| n_estimators (基学习器个数) | 缺省值是100。集成的基学习器的个数。或者说算法的迭代次数。 |
| learning_rate(学习率) | 缺省值是0.1。一般设为0到1之间的值,缩减每个基学习器对最终结果的贡献量,即每个基学习器的权重缩减系数,也称步长。它和n_estimators之间存在一个折衷,一起来决定算法的拟合效果。如果要达到一定的拟合效果,更小的学习率意味着要训练更多的弱学习器。 |
| subsample(子采样) | 用于训练每个基学习器的样本数量占整个训练集的比例。 缺省值是1.0,即用全部数据训练基学习器。小于1.0则是随机梯度提升。小于1.0的值会降低系统的方差,防止过拟合,但会增大系统的偏差。 |
| loss(损失函数(仅用于AdaBoostRegressor)) | 可能取值:“linear”,“square”或“exponential”,缺省值是“linear”。每一轮调整样本权重时需要用到的损失函数,用于计算每一轮训练出的弱学习器在训练集中每个样本上的预测值与真实值之间的误差,可以是线性误差,平方误差或指数误差。 |
注:Hubber损失是平方损失和绝对损失两者的折衷,即对目标值附近的点用平方损失,对远离目标值的点采用绝对损失。因为平方损失虽然可以被高效计算,但由于对误差的惩罚力度大,对离群值较敏感,不稳定,Hubber损失更鲁棒些。
🕤 8.3.4 损失函数
Boosting:
- Boosting使用不同的损失函数
- 每一步,为每个数据点确定分类间距(margin)
- 正确分类的点,间距是正的;错误分类的点,间距是负的
- 损失函数的值从间距计算得到
- 例如二分类的margin: yf(x), 其中y=1, -1
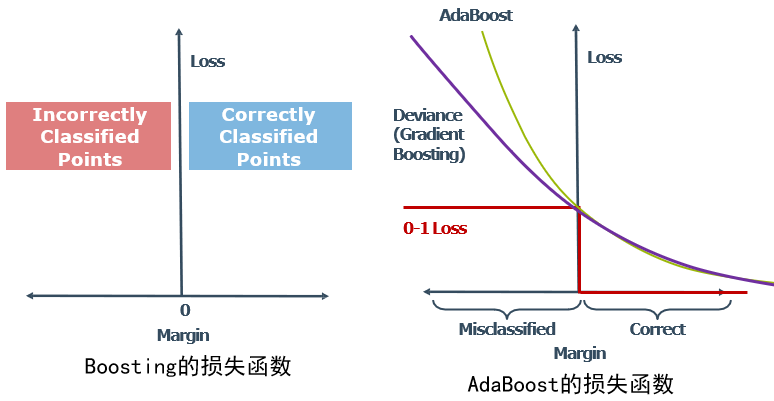
0-1损失函数:错误分类的点损失值为 1,正确分类的点被忽略,理论上“理想的”损失函数,实际难以优化—非平滑和非凸函数
AdaBoost:
- 损失函数是指数函数: 𝑒 ( − 𝑚 𝑎 𝑟 𝑔 𝑖 𝑛 ) 𝑒^{(−𝑚𝑎𝑟𝑔𝑖𝑛)} e(−margin)
- 使AdaBoost比其他类型的Boosting算法对离群点更敏感
- 一般化的boosting方法,可以使用不同的损失函数,常见的实现使用二项式对数似然损失函数(偏差):
l o g ( 1 + 𝑒 ( − 𝑚 𝑎 𝑟 𝑔 𝑖 𝑛 ) ) log(1 +𝑒^{(−𝑚𝑎𝑟𝑔𝑖𝑛)} ) log(1+e(−margin)) - 比AdaBoost对离群值更鲁棒
Bagging vs. Boosting
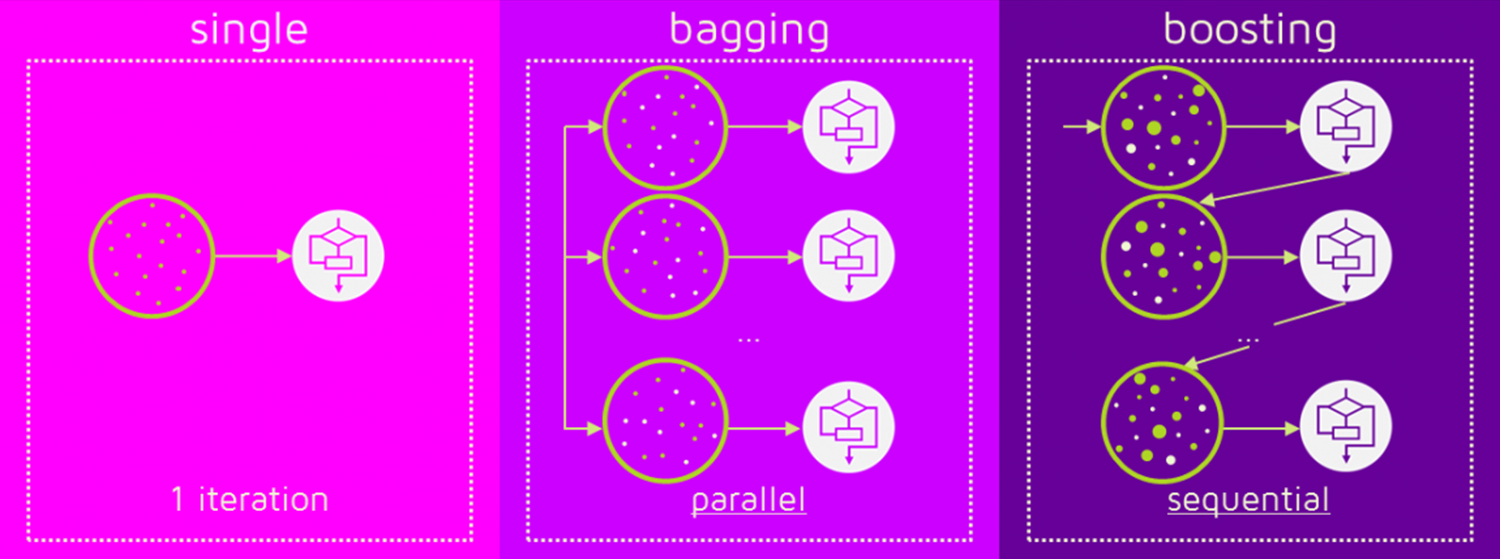
Bagging
- Bootstrap产生的样本
- 独立创建的基本树
- 只考虑数据点
- 不使用权重
- 多余的树不会造成过拟合
- 主要关注降低方差
Boosting
- 拟合全部数据集
- 相继创建的基本树
- 利用前面创建的模型的残差
- 增加错误分类点的权重
- 当心过拟合
- 主要关注降低偏差
🕒 9. 堆叠(Stacking)
🕘 9.1 概述
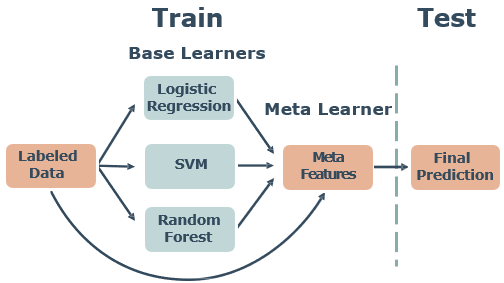
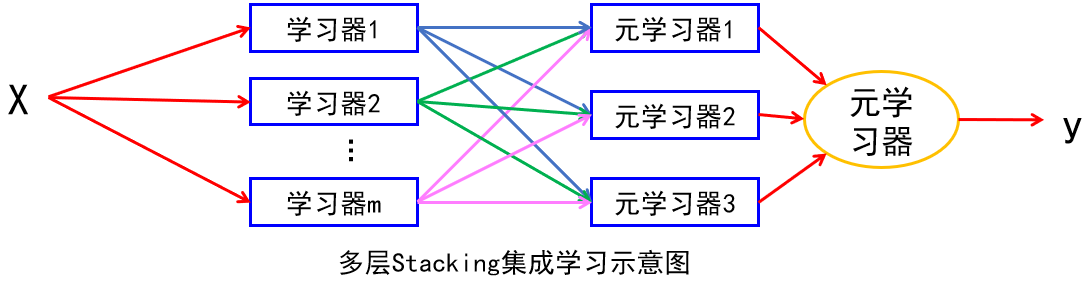
Bagging 和 Boosting集成学习方法主要着力于如何生成多个有差异的基学习器,然后再用投票法(分类)或平均法(回归)把多个基学习器的预测结果结合起来得到最终的结果。与它们不同,Stacking 集成学习方法的着眼点不在基学习器的生成上,而在如何结合多个基学习器的结果上。它不是使用简单的函数(如投票或平均),而是训练一个机器学习模型(又称Meta元学习器)来将多个基学习器的预测结果作为元学习器的输入特征(元学习器可以选择将原输入特征与其拼接/不拼接在一起作为元学习器的输入特征)。
基学习器的输出可以用多数投票或加权和等方式结合起来,如果元学习器有参数,则需要另外取出的数据做预测,当心增加的模型复杂度。
特点:基学习器可以是不同类型的学习器
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
🕒 10. 综合案例:泰坦尼克号乘客生还预测
导入库和数据
import pandas as pd
url = 'titanic.csv'
titanic = pd.read_csv(url)
titanic.head() # 显示前5行

titanic.shape # 行数和列数: (891,12)
titanic.info() # 简单数据分析
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId
\hspace{0.5cm}
891 non-null int64
Survived
\hspace{1cm}
891 non-null int64
Pclass
\hspace{1.3cm}
891 non-null int64
Name
\hspace{1.4cm}
891 non-null object
Sex
\hspace{1.7cm}
891 non-null object
Age
\hspace{1.7cm}
714 non-null float64
SibSp
\hspace{1.5cm}
891 non-null int64
Parch
\hspace{1.5cm}
891 non-null int64
Ticket
\hspace{1.5cm}
891 non-null object
Fare
\hspace{1.7cm}
891 non-null float64
Cabin
\hspace{1.6cm}
204 non-null object
Embarked
\hspace{1cm}
889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
由此可知,训练集中共有891行和12项。这12项的具体含义如下表所示。
1 PassengerId 乘客编号 2 Survived 是否生还 (1 为生还, 0 为末生还) 3 Pclass 船舱等级 4 Name 乘客姓名 5 Sex 乘客性别 6 Age 乘客年龄 7 SibSp 乘客在船上的兄弟姐妺及配偶数量 8 Parch 乘客在船上的父母和子女数量 9 Ticket 船票编号 10 Fare 票价 11 Cabin 舱位 12 Embarked 登船港口 \begin{array}{|c|c|c|} \hline 1 & \text { PassengerId } & \text { 乘客编号 } \\ \hline 2 & \text { Survived } & \text { 是否生还 (1 为生还, 0 为末生还) } \\ \hline 3 & \text { Pclass } & \text { 船舱等级 } \\ \hline 4 & \text { Name } & \text { 乘客姓名 } \\ \hline 5 & \text { Sex } & \text { 乘客性别 } \\ \hline 6 & \text { Age } & \text { 乘客年龄 } \\ \hline 7 & \text { SibSp } & \text { 乘客在船上的兄弟姐妺及配偶数量 } \\ \hline 8 & \text { Parch } & \text { 乘客在船上的父母和子女数量 } \\ \hline 9 & \text { Ticket } & \text { 船票编号 } \\ \hline 10 & \text { Fare } & \text { 票价 } \\ \hline 11 & \text { Cabin } & \text { 舱位 } \\ \hline 12 & \text { Embarked } & \text { 登船港口 } \\ \hline \end{array} 123456789101112 PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 乘客编号 是否生还 (1 为生还, 0 为末生还) 船舱等级 乘客姓名 乘客性别 乘客年龄 乘客在船上的兄弟姐妺及配偶数量 乘客在船上的父母和子女数量 船票编号 票价 舱位 登船港口
可以看到,12列中有7列是数值型特征(其中 PassengerId,Survived,Pclass,SibSp,Parch是整数类型,Age和Fare是小数类型),5列是非数值型特征(即Name,Sex,Ticket,Cabin和 Embarked)。一些列,即 Age,Cabin和 Embarked,有值项的个数小于891,说明这些列中存在缺失值。Age列和Cabin列的缺失值较多,Embarked列只有两个缺失值。
对于数值型特征(整数或小数),可以使用describe方法显示每列的基本描述统计信息,如最大最小值、均值、标准差和计数等。
titanic.describe()
Passengerld Survived Pclass Age SibSp Parch Fare count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000 mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208 std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429 min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000 25 % 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400 50 % 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200 75 % 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200 \begin{array}{rrrrrrrr} & \text { Passengerld } & \text { Survived } & \text { Pclass } & \text { Age } & \text { SibSp } & \text { Parch } & \text { Fare } \\ \hline \text { count } & 891.000000 & 891.000000 & 891.000000 & 714.000000 & 891.000000 & 891.000000 & 891.000000 \\ \text { mean } & 446.000000 & 0.383838 & 2.308642 & 29.699118 & 0.523008 & 0.381594 & 32.204208 \\ \text { std } & 257.353842 & 0.486592 & 0.836071 & 14.526497 & 1.102743 & 0.806057 & 49.693429 \\ \text { min } & 1.000000 & 0.000000 & 1.000000 & 0.420000 & 0.000000 & 0.000000 & 0.000000 \\ \text{25 \%} & 223.500000 & 0.000000 & 2.000000 & 20.125000 & 0.000000 & 0.000000 & 7.910400 \\ \text{50 \%} & 446.000000 & 0.000000 & 3.000000 & 28.000000 & 0.000000 & 0.000000 & 14.454200 \\ \text{75 \%} & 668.500000 & 1.000000 & 3.000000 & 38.000000 & 1.000000 & 0.000000 & 31.000000 \\ \text { max } & 891.000000 & 1.000000 & 3.000000 & 80.000000 & 8.000000 & 6.000000 & 512.329200 \end{array} count mean std min 25 %50 %75 % max Passengerld 891.000000446.000000257.3538421.000000223.500000446.000000668.500000891.000000 Survived 891.0000000.3838380.4865920.0000000.0000000.0000001.0000001.000000 Pclass 891.0000002.3086420.8360711.0000002.0000003.0000003.0000003.000000 Age 714.00000029.69911814.5264970.42000020.12500028.00000038.00000080.000000 SibSp 891.0000000.5230081.1027430.0000000.0000000.0000001.0000008.000000 Parch 891.0000000.3815940.8060570.0000000.0000000.0000000.0000006.000000 Fare 891.00000032.20420849.6934290.0000007.91040014.45420031.000000512.329200
如上显示,乘客中年龄最大的是80岁,最小的不满半岁。
对于类别特征(即取离散值,可以编码成数值或者字符串),可以使用value.counts方法查看一个特征列所有不同取值的个数。例如,下面显示 Embarked特征列有三种不同的取值“S”“C”“Q”,它们出现的次数分别是644次、168次和77次。
titanic.Embarked.value_counts()
S
\hspace{0.5cm}
644
C
\hspace{0.5cm}
168
Q
\hspace{0.5cm}
77
Name: Embarked, dtype: int64
处理数据,经过初步的数据分析,选择使用Pclass,Sex,Age和 Embarked四个特征来预测乘客是否生还。在正式训练模型之前,还需对数据做一些预处理。常见的预处理包括:异常值处理、缺失值处理、特征编码转换、特征缩放、特征创建等。
本例中,Age和 Embarked列存在缺失值,分别使用均值和最频繁的值填充两列。
# 用均值填充Age列的缺失值
titanic.Age.fillna(titanic.Age.median(), inplace=True)
# 用最频繁的值'S'填充Embarked列的缺失值
titanic.Embarked.fillna('S', inplace=True)
大部分机器学习模型只能处理数值型数据,所以非数值型特征需要转换为可供模型计算的数值型编码。另外,对于数值型编码的类别特征,为了使模型中计算的距离更合理,一般应该将其转换为独热编码(one-hot encoding)。一个有N种不同取值的类别特征列,转换为独热编码后将生成N个二值特征列(取值为0或1),每个二值特征列对应一种取值。
本例中,Sex和 Embarked是非数值型特征,将它们转换为相应的数值型编码,便于模型的高效计算。注意,Embarked特征有三个不同取值:“C”“Q”“S”,转换为独热编码后,生成了三个二值特征列Embarked_C,Embarked_Q和 Embarked_S,可以去掉第一列,因为它是冗余的。再把新生成的两列 Embarked_Q和Embarked_S拼接到原数据集中,则原数据集变成了14列。
# 将Sex列的值转换为0和1
titanic.Sex = titanic.Sex.map({'female':0, 'male':1})
# 将Embarked列的值转换为独热编码
embarked_dummies = pd.get_dummies(titanic.Embarked, prefix='Embarked', drop_first=True)
# 将独热编码后的多个列,即embarked_dummies,拼接到原数据中
titanic = pd.concat([titanic, embarked_dummies], axis=1)
不同的特征通常具有不同的取值范围,例如Age通常不超过100岁,而Fare可以是几万、几十万甚至几百万。在计算距离时,取值范围大的特征会主导距离的计算结果,因而需要将各特征的取值范围缩放到相近的范围。特征缩放对一些基于距离计算的机器学习模型非常关键,如使用径向基核函数的支持向量机模型和K近邻模型等。使用决策树模型,一般无须对特征进行缩放。
除了选择数据中已有的特征列做预测,还可以创建一些对预测有帮助的新特征。在本例中,我们没有创建任何新的特征。
处理好数据之后,我们抽取出 Pclass,Sex,Age,Embarked_Q和 Embarked_S列作为机器学习模型的特征输入,Survived列是模型预测的目标列。
# 生成X和y
feature_cols = ['Pclass', 'Sex', 'Age', 'Embarked_Q', 'Embarked_S']
X = titanic[feature_cols]
y = titanic.Survived
训练和选择模型。这里我们创建一棵最大深度等于3的分类决策树。
from sklearn.tree import DecisionTreeClassifier
treeclf = DecisionTreeClassifier(max_depth=3, random_state=1) # random_state,对连续特征,为了得到更好的分类间隔引入随机数计算分割点。
treeclf.fit(X, y) # 训练
参数:DecisionTreeClassifier(class_weight=None, criterion=‘gini’, max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=1,
splitter=‘best’)
为了防止过拟合,这里可以用GridSearchCV可以对模型的超参数进行自动调优。下面会提到。
🕘 10.1 可视化决策树
可视化决策树需要先安装python-graphviz库,使用conda安装的命令如下: conda install python-graphviz
没有意外的话应该是失败的( ̄▽ ̄)~*
你们也可以试试,万一呢
下面提供另一种方法
Windows环境下安装graphviz:
网站:🔎 graphviz官网
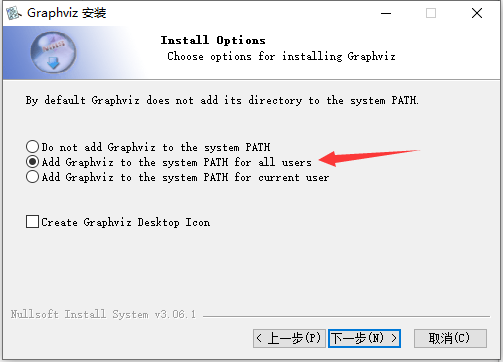
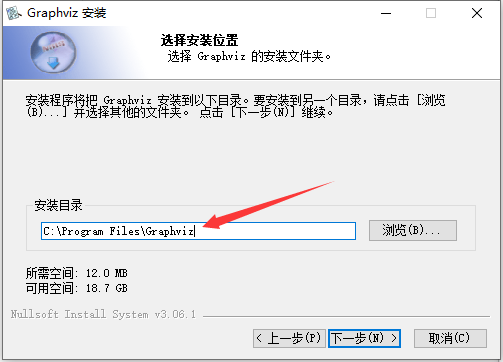
安装的时候下一步,有些步骤注意一下
记住你的安装目录,备用
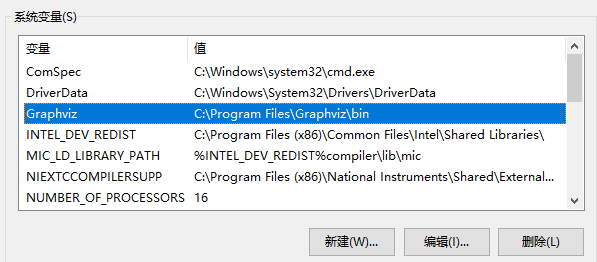
配置环境变量:控制面板-系统-高级系统设置-高级-环境变量-系统变量-path-编辑-新建:C:\Program Files\Graphviz\bin
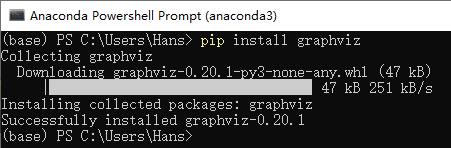
在Anaconda中安装Graphviz库,打开Anaconda Powershell Prompt (Anaconda3),运行如下命令:pip install graphviz
重启一下anaconda,这样就可在jupyter里导入graphviz啦:import graphviz
import graphviz
from sklearn import tree
dot_data = tree.export_graphviz(treeclf, out_file=None,
feature_names=feature_cols,
class_names="Survived",
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
# graph.render("titanic")
graph
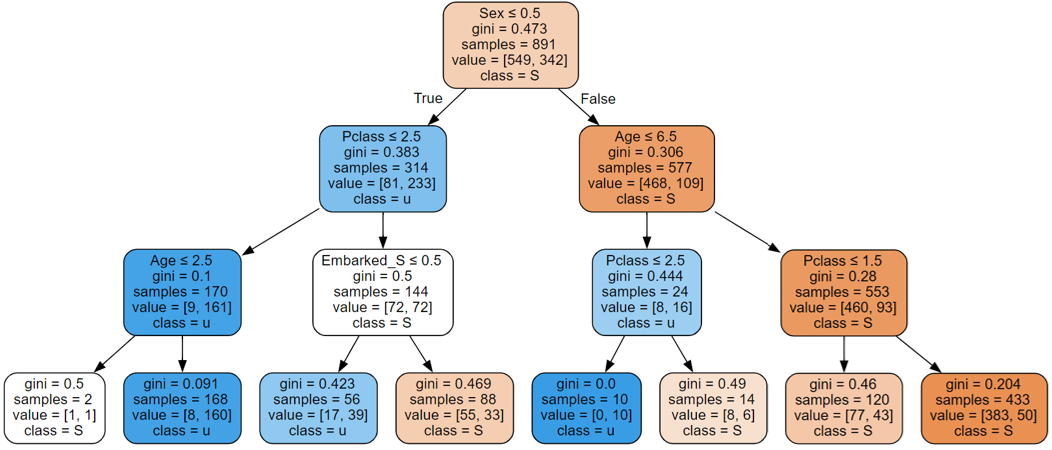
节点信息:
- samples:非叶节点:分裂前该节点包含的样例个数;叶节点:该节点包含的样例个数
- gini:该节点的基尼指数
- rule:用于分裂该节点的规则(为真走左子树,为假走右子树)
- value:该节点包含的负例的个数和正例的个数
- class:该节点预测的类别(S表示生还,u表示没有生还)
注意最右下的分裂,两个子节点预测的是相同的类。该分裂没有减少分类错误率,但是它提高了类别的纯度,这样可以提高分类预测准确的概率。
🕘 10.2 特征重要度
训练好的决策树还可以给出每个特征的重要性。对分类越重要的特征,重要性得分越高。特征重要性的计算是基于特征所带来的不纯度减少量,又称基尼重要性。具体地,决策树的每个节点都是关于一个特征的判断条件,这个判断条件造成节点的分裂,并且分裂后的基尼不纯度低于分裂前的基尼不纯度,即造成基尼不纯度的减少。一个特征在树中可能有多次出现,将所有出现带来的基尼不纯度的减少量加起来,就是该特征的基尼重要性。
pd.DataFrame({'feature':feature_cols, 'importance':treeclf.feature_importances_})
feature importance 0 Pclass 0.242664 1 Sex 0.655584 2 Age 0.064494 3 Embarked_Q 0.000000 4 Embarked_S 0.037258 \begin{array}{rrr} & \text { feature } & \text { importance } \\ \hline 0 & \text { Pclass } & 0.242664 \\ 1 & \text { Sex } & 0.655584 \\ 2 & \text { Age } & 0.064494 \\ 3 & \text { Embarked\_Q } & 0.000000 \\ 4 & \text { Embarked\_S } & 0.037258 \\ \end{array} 01234 feature Pclass Sex Age Embarked_Q Embarked_S importance 0.2426640.6555840.0644940.0000000.037258
🕘 10.3 训练和选择模型
接下来我们对比五种模型的使用和预测效果
每种模型都使用带交叉验证的网格搜索(GridSearchCV)方法自动选择最优的超参数组合,并训练出该参数组合下的最优模型,然后在预先留出的测试数据集上评测其性能。
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
🕤 10.3.1 决策树
# 用GridSearchCV方法训练决策树模型,并选择最优的决策树深度
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
parameters = {'max_depth':[1, 3, 5, 10,15, 20, 30]}
tree_clf = GridSearchCV(DecisionTreeClassifier(), parameters, scoring='accuracy')
tree_clf.fit(X_train, y_train)
参数:GridSearchCV(cv=None, error_score=‘raise’,
estimator=DecisionTreeClassifier(class_weight=None, criterion=‘gini’, max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter=‘best’),
fit_params=None, iid=True, n_jobs=1,
param_grid={‘max_depth’: [1, 3, 5, 10, 15, 20, 30]},
pre_dispatch=‘2*n_jobs’, refit=True, return_train_score=‘warn’,
scoring=‘accuracy’, verbose=0)
# 显示网格搜索到的最佳决策树深度和得分
print(tree_clf.best_params_) # {'max_depth': 20}
print(tree_clf.best_score_) # 得分:0.810593900482
# 用上面得到的最佳决策树预测测试数据
y_pred = tree_clf.predict(X_test)
# 输出对测试数据预测的精度、查准率、查全率和F1分数
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
print(accuracy_score(y_test, y_pred)) # 预测精度:0.791044776119
print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.80 0.88 0.84 164 1 0.77 0.65 0.71 104 avg / total 0.79 0.79 0.79 268 \hspace{2cm}\text{precision \qquad recall \qquad f1-score \qquad support} \\ {} \\ \hspace{1cm}0 \hspace{1.2cm} 0.80 \hspace{1.2cm} 0.88 \hspace{1.2cm} 0.84 \hspace{1.3cm} 164 \\ \hspace{1cm}1 \hspace{1.2cm} 0.77 \hspace{1.2cm} 0.65 \hspace{1.2cm} 0.71 \hspace{1.3cm} 104 \\ {} \\ \hspace{0.1cm} \text{ avg / total } \hspace{0.5cm} 0.79 \hspace{1.2cm} 0.79 \hspace{1.2cm} 0.79 \hspace{1.3cm} 268 precision recall f1-score support00.800.880.8416410.770.650.71104 avg / total 0.790.790.79268
🕤 10.3.2 随机森林
# 用GridSearchCV方法训练随机森林模型,并选择最优的决策树个数
from sklearn.ensemble import RandomForestClassifier
parameters = {'n_estimators':[20, 30, 50, 100, 150, 200, 300, 400]}
forest_clf = GridSearchCV(RandomForestClassifier(oob_score=True),
parameters, scoring='accuracy')
forest_clf.fit(X_train, y_train)
参数:GridSearchCV(cv=None, error_score=‘raise’,
estimator=RandomForestClassifier(bootstrap=True, class_weight=None, criterion=‘gini’,
max_depth=None, max_features=‘auto’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=True, random_state=None, verbose=0, warm_start=False),
fit_params=None, iid=True, n_jobs=1,
param_grid={‘n_estimators’: [20, 30, 50, 100, 150, 200, 300, 400]},
pre_dispatch=‘2*n_jobs’, refit=True, return_train_score=‘warn’,
scoring=‘accuracy’, verbose=0)
# 显示网格搜索到的最佳森林的决策树个数、得分和袋外错误率
print(forest_clf.best_params_) # {'n_estimators': 30}
print(forest_clf.best_score_) # 0.821829855538
print(forest_clf.best_estimator_.oob_score_) # 0.802568218299
# 用上面得到的最佳森林预测测试数据
y_pred = forest_clf.predict(X_test)
# 输出对测试数据预测的精度、查准率、查全率和F1分数
print(accuracy_score(y_test, y_pred)) # 0.80223880597
print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.82 0.87 0.84 164 1 0.77 0.70 0.73 104 avg / total 0.80 0.80 0.80 268 \hspace{2cm}\text{precision \qquad recall \qquad f1-score \qquad support} \\ {} \\ \hspace{1cm}0 \hspace{1.2cm} 0.82 \hspace{1.2cm} 0.87 \hspace{1.2cm} 0.84 \hspace{1.3cm} 164 \\ \hspace{1cm}1 \hspace{1.2cm} 0.77 \hspace{1.2cm} 0.70 \hspace{1.2cm} 0.73 \hspace{1.3cm} 104 \\ {} \\ \hspace{0.1cm} \text{ avg / total } \hspace{0.5cm} 0.80 \hspace{1.2cm} 0.80 \hspace{1.2cm} 0.80 \hspace{1.3cm} 268 precision recall f1-score support00.820.870.8416410.770.700.73104 avg / total 0.800.800.80268
可以看到随机森林的测试精度高于决策树,说明其可以避免过拟合,泛化性能较好。另外可以看到,随机森林在训练过程中得到的袋外错误率比较接近最后在测试集上得到的预测精度,因此可以使用袋外错误率较准确地估计其泛化性能。
🕤 10.3.3 AdaBoost
# 用GridSearchCV方法训练AdaBoost模型,并选择最优的决策树个数和学习率
from sklearn.ensemble import AdaBoostClassifier
parameters = {'n_estimators':[20, 50, 100, 200, 300, 400],
'learning_rate':[0.1, 0.01, 0.001]}
ada_clf = GridSearchCV(AdaBoostClassifier(DecisionTreeClassifier(max_depth=3, max_features=3)),
param_grid=parameters, scoring='accuracy')
ada_clf.fit(X_train, y_train)
参数:GridSearchCV(cv=None, error_score=‘raise’,
estimator=AdaBoostClassifier(algorithm=‘SAMME.R’,
base_estimator=DecisionTreeClassifier(class_weight=None, criterion=‘gini’, max_depth=3,
max_features=3, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter=‘best’),
learning_rate=1.0, n_estimators=50, random_state=None),
fit_params=None, iid=True, n_jobs=1,
param_grid={‘n_estimators’: [20, 50, 100, 200, 300, 400], ‘learning_rate’: [0.1, 0.01, 0.001]},
pre_dispatch=‘2*n_jobs’, refit=True, return_train_score=‘warn’,
scoring=‘accuracy’, verbose=0)
# 显示网格搜索到的最佳AdaBoost模型的决策树个数、学习率和得分
print(ada_clf.best_params_) # {'learning_rate': 0.1, 'n_estimators': 20}
print(ada_clf.best_score_) # 0.815409309791
# 用上面得到的最佳AdaBoost模型预测测试数据
y_pred = ada_clf.predict(X_test)
# 输出对测试数据预测的精度、查准率、查全率和F1分数
print(accuracy_score(y_test, y_pred)) # 0.809701492537
print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.79 0.95 0.86 164 1 0.87 0.60 0.71 104 avg / total 0.82 0.81 0.80 268 \hspace{2cm}\text{precision \qquad recall \qquad f1-score \qquad support} \\ {} \\ \hspace{1cm}0 \hspace{1.2cm} 0.79 \hspace{1.2cm} 0.95 \hspace{1.2cm} 0.86 \hspace{1.3cm} 164 \\ \hspace{1cm}1 \hspace{1.2cm} 0.87 \hspace{1.2cm} 0.60 \hspace{1.2cm} 0.71 \hspace{1.3cm} 104 \\ {} \\ \hspace{0.1cm} \text{ avg / total } \hspace{0.5cm} 0.82 \hspace{1.2cm} 0.81 \hspace{1.2cm} 0.80 \hspace{1.3cm} 268 precision recall f1-score support00.790.950.8616410.870.600.71104 avg / total 0.820.810.80268
🕤 10.3.4 梯度提升树
# 用GridSearchCV方法训练梯度提升树模型,并选择最优的决策树个数、学习率、子采样、决策树的最大深度、最大特征数
from sklearn.ensemble import GradientBoostingClassifier
parameters = {'n_estimators':[20, 50, 100, 200, 300, 400],
'learning_rate':[0.1, 0.01, 0.001],
'subsample':[0.5, 0.6, 0.8],
'max_depth':[1, 2, 3],
'max_features':[3, 4, 5]}
gtb_clf = GridSearchCV(GradientBoostingClassifier(),param_grid=parameters, scoring='accuracy')
gtb_clf.fit(X_train, y_train)
参数:
GridSearchCV(cv=None, error_score=‘raise’,
estimator=GradientBoostingClassifier(criterion=‘friedman_mse’, init=None,
learning_rate=0.1, loss=‘deviance’, max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
presort=‘auto’, random_state=None, subsample=1.0, verbose=0,
warm_start=False),
fit_params=None, iid=True, n_jobs=1,
param_grid={‘n_estimators’: [20, 50, 100, 200, 300, 400], ‘learning_rate’: [0.1, 0.01, 0.001], ‘subsample’: [0.5, 0.6, 0.8], ‘max_depth’: [1, 2, 3], ‘max_features’: [3, 4, 5]},
pre_dispatch=‘2*n_jobs’, refit=True, return_train_score=‘warn’,
scoring=‘accuracy’, verbose=0)
# 显示网格搜索到的最佳梯度提升树模型的参数和得分
print(gtb_clf.best_params_) # {'learning_rate': 0.1, 'max_depth': 2, 'max_features': 3, 'n_estimators': 300, 'subsample': 0.5}
print(gtb_clf.best_score_) # 0.836276083467
# 用上面得到的最佳梯度提升树模型预测测试数据
y_pred = gtb_clf.predict(X_test)
# 输出对测试数据预测的精度、查准率、查全率和F1分数
print(accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.80 0.90 0.84 164 1 0.80 0.64 0.71 104 avg / total 0.80 0.80 0.79 268 \hspace{2cm}\text{precision \qquad recall \qquad f1-score \qquad support} \\ {} \\ \hspace{1cm}0 \hspace{1.2cm} 0.80 \hspace{1.2cm} 0.90 \hspace{1.2cm} 0.84 \hspace{1.3cm} 164 \\ \hspace{1cm}1 \hspace{1.2cm} 0.80 \hspace{1.2cm} 0.64 \hspace{1.2cm} 0.71 \hspace{1.3cm} 104 \\ {} \\ \hspace{0.1cm} \text{ avg / total } \hspace{0.5cm} 0.80 \hspace{1.2cm} 0.80 \hspace{1.2cm} 0.79 \hspace{1.3cm} 268 precision recall f1-score support00.800.900.8416410.800.640.71104 avg / total 0.800.800.79268
🕤 10.3.5 投票聚合模型
sk-learn中提供了一种简单的投票聚合模型,可以将多个不同模型(可以是不同种类的模型)的结果用投票(硬投票或软投票)方式聚合成一个最终结果,进一步提高性能。
下面将前面训练得到的最佳随机森林模型和梯度提升树模型用软投票方式聚合在一起,并测试该聚合模型在测试数据集上的性能。
# 将前面训练得到的最好随机森林模型和梯度提升树模型用软投票方式聚合在一起
from sklearn.ensemble import VotingClassifier
vote_clf = VotingClassifier(estimators=[('rf', forest_clf.best_estimator_), ('gtb', gtb_clf.best_estimator_)], voting='soft')
vote_clf.fit(X_train, y_train)
参数:VotingClassifier(estimators=[(‘rf’, RandomForestClassifier(bootstrap=True, class_weight=None, criterion=‘gini’,
max_depth=None, max_features=‘auto’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_we… presort=‘auto’, random_state=None, subsample=0.5, verbose=0,
warm_start=False))],
flatten_transform=None, n_jobs=1, voting=‘soft’, weights=None)
# 用投票聚合模型预测测试数据
y_pred = vote_clf.predict(X_test)
# 输出对测试数据预测的精度、查准率、查全率和F1分数
print(accuracy_score(y_test, y_pred)) # 0.813432835821
print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.81 0.91 0.86 164 1 0.82 0.66 0.73 104 avg / total 0.81 0.81 0.81 268 \hspace{2cm}\text{precision \qquad recall \qquad f1-score \qquad support} \\ {} \\ \hspace{1cm}0 \hspace{1.2cm} 0.81 \hspace{1.2cm} 0.91 \hspace{1.2cm} 0.86 \hspace{1.3cm} 164 \\ \hspace{1cm}1 \hspace{1.2cm} 0.82 \hspace{1.2cm} 0.66 \hspace{1.2cm} 0.73 \hspace{1.3cm} 104 \\ {} \\ \hspace{0.1cm} \text{ avg / total } \hspace{0.5cm} 0.81 \hspace{1.2cm} 0.81 \hspace{1.2cm} 0.81 \hspace{1.3cm} 268 precision recall f1-score support00.810.910.8616410.820.660.73104 avg / total 0.810.810.81268
该投票聚合模型在预留出的测试数据上的预测精度高于它聚合的随机森林模型和梯度提升树模型。
在线文档:🔎 投票分类器的语法
🕒 11. 课后习题
-
【单选题】与逻辑回归等分类模型相比,决策树具有( )的特点
A. 原理浅显易懂,计算复杂度较小,具有可解释性,方差较大
B. 原理浅显易懂,计算复杂度较大,具有可解释性,偏差较大
C. 原理浅显易懂,计算复杂度较小,具有可解释性,方差较小
D. 原理浅显易懂,计算复杂度较小,具有可解释性,偏差较小 -
【多选题】在训练决策树时,为了防止过拟合,可以采取以下措施( )
A. 调整预剪枝超参数,减小决策树最大高度
B. 调整后剪枝超参数,提高代价复杂度参数
C. 设置最大叶节点个数,减少该数值
D. 提高叶子节点的最小样例数,及早停止节点分裂
E. 减少训练样本数量 -
【判断题】分类决策树在训练时,其节点分裂的目的是减少节点不纯度。
-
【判断题】在分类决策树的输入数据中,所有取值空间为连续空间的特征的特征值都必须经过预处理,规范化后才能使用于训练或测试。
-
【判断题】分类决策树训练结束后所有的叶子节点的不纯度值都为0,即所有叶子节点内部的样本类别都相同。
-
【判断题】对于同一问题同训练集训练出来的分类模型,决策树可具有比逻辑回归更灵活和复杂的分类边界。
-
【判断题】对于同一问题同训练集训练出来的分类模型,决策树比逻辑回归的模型结构更易受训练数据分布变化的影响。
-
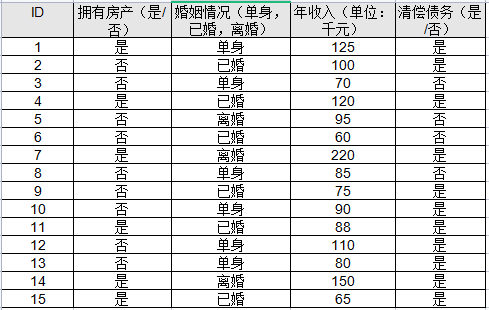
【判断题】以下是一个房贷客户信息的样本数据集。
以基尼指数为不纯度指标训练一个最高高度为3的决策树,用于预测客户是否能偿还房贷,决策树graphviz图形化输出结果如下:
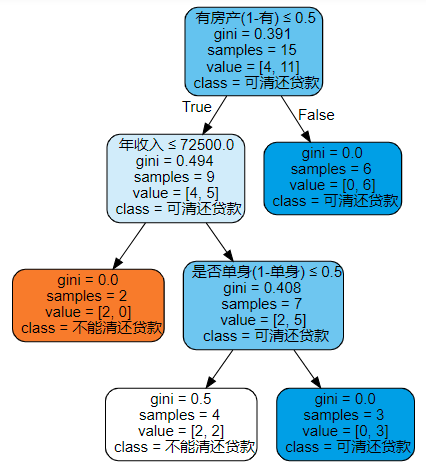
现有一个年收入98000,无房产,已婚的客户申请房贷,使用以上决策树预测其能否偿还房贷,预测结果为“可清还贷款”。 -
【单选题】如果随机森林模型现处于欠拟合状态,则下列哪个操作(调整预设参数)可以提升其性能?
A. 增加叶子节点的最小样本数
B. 增大决策树的最大深度
C. 增加中间节点分裂的最小样本数
D. 降低叶子节点数上限
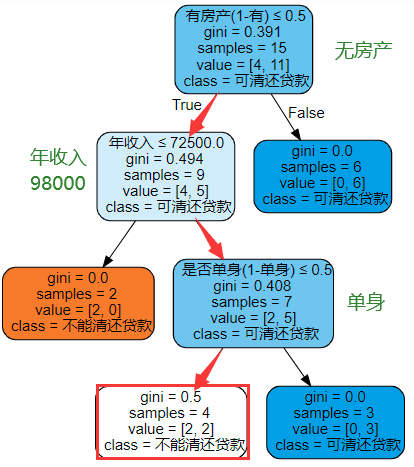
答案:1.A(解析:由于决策树只考虑当前数据的特征来做出决策,因此它的决策可能会受到数据中的噪声和异常值的影响,导致模型的方差较大。) 2.ABCD 3.√(解析:训练过程中每次节点分裂都会把一个节点的数据集划分为若干个较为纯的子集,这样可以有效减少模型的错误率。) 4.×(解析:划分的三种方法(分类错误、熵、基尼指数)就足矣,不需要预处理) 5.× 6.√ 7.√ 8.×(解析见下图) 9.B(解析:ACD都会加重欠拟合的发生)
OK,以上就是本期知识点“决策树与集成学习”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页







![[MySQL]-主从同步实战](https://img-blog.csdnimg.cn/8091e5e0eebd4706bb338b806cecbce7.png#pic_center)