皮爷咖啡(Peet’s Coffee)是美国精品咖啡品牌,于2017年进入中国,为中国消费者带来传统经典咖啡饮品,并特别呈现更加丰富的品质咖啡饮品体验。通过深入应用亚马逊云科技云原生数据库产品Amazon Redshift以及Amazon DMS等数据库产品,皮爷咖啡在1个月内,快速构建了敏捷的数据架构,加速数据治理进程。

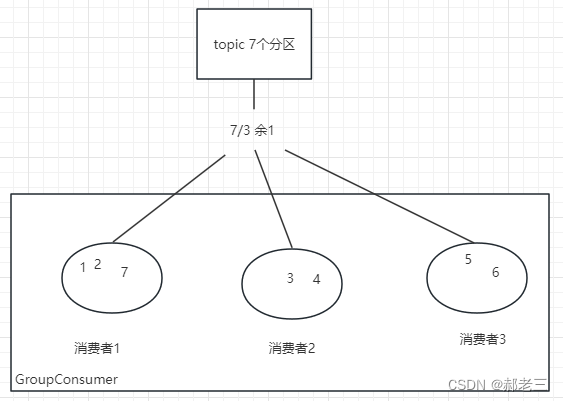
皮爷咖啡采用的亚马逊云科技的产品及服务包括:Amazon Redshift、Amazon Kinesis Data Streams、Amazon Lambda、Amazon Glue、Amazon Athena、Amazon Lake formation、Amazon DMS。
机会:未经治理的数据“一口水,一口井”
皮爷咖啡是包装和连锁咖啡巨头JDE旗下的精品咖啡品牌,始终秉承着打造极致咖啡体验的理念。在中国,皮爷咖啡也在迅速发展,伴随着业务的迅速扩张,皮爷咖啡迅速意识到需要构建对应的数据治理机制,去建设大数据平台。皮爷咖啡数据架构师冯亚东强调:“2023年是皮爷咖啡的数字化里程碑的一年,我们对数据治理的要求非常明确,就是敏捷。敏捷的定义是:没什么做不了,没什么不能改,不需要从头来,不需要等太久。我们做数据,数据驱动是绕不开的话题,如果驱动不好做,十有八九是不够敏捷。”
皮爷咖啡对于数据治理的要求非常明确:打破数据孤岛,构建敏捷的数据系统,具备高效的数据整合与流动能力,实现业务部门对数据平台建设的较高参与度。在这之中,主要挑战有如下几点:
-
业务数据库繁杂、分散:由于历史原因,皮爷业务数据库有本地IDC的服务器、也包含其他云平台的服务器,数仓种类包含RDB、NoSQL等,种类繁多,场景类别多样。因此需要一个通用的、非线性方式解决数据集成问题;
-
数据治理:数据血缘元数据产品的核心能力,是大数据系统的老大难问题。数据血缘管理、数据质量监控、数据指标管理,都需要优化迭代,并适配皮爷咖啡的开源解决方案;
-
数据应用:皮爷咖啡在搭建数据中台的关键思考就是需要满足现有场景,并赋能业务人员可以省心省时省力运用和分析数据。
解决方案:1个月构建敏捷弹性的智能湖仓架构,打破数据孤岛
针对以上痛点,亚马逊云科技与皮爷咖啡进行深入讨论,最终确认了围绕“以订单系统为核心的数据主线”完成一期开发,添枝加叶,完善服务。
数据摄入:Serverless免运维架构,构建数据摄入能力
针对于皮爷咖啡多样的数据源类型,亚马逊云科技将数据源分成三种类别:面对热数据、结构化数据,也是高实时要求的数据,皮爷咖啡充分利用Amazon DMS自动化迁移功能,实现数据库和分析工作负载的快速迁移和CDC(自动数据摄取),并尽可能减少停机时间和杜绝数据丢失,并经由Amazon DMS直接进入云原生数据仓库AmazonRedshift进行分析;面对企业应用端、更加复杂的非结构化热数据,则通过Amazon Kinesis Data Streams进行实时的流数据分析,并通过Serverless架构的Amazon Lambda,对数据进行处理;而面对冷数据、存取比比较低的非结构化数据,则通过Amazon Glue存储在数据湖Amazon S3中,从而降低计算成本和存储成本,最终实现良好的冷、热、温数据分层和隔离。
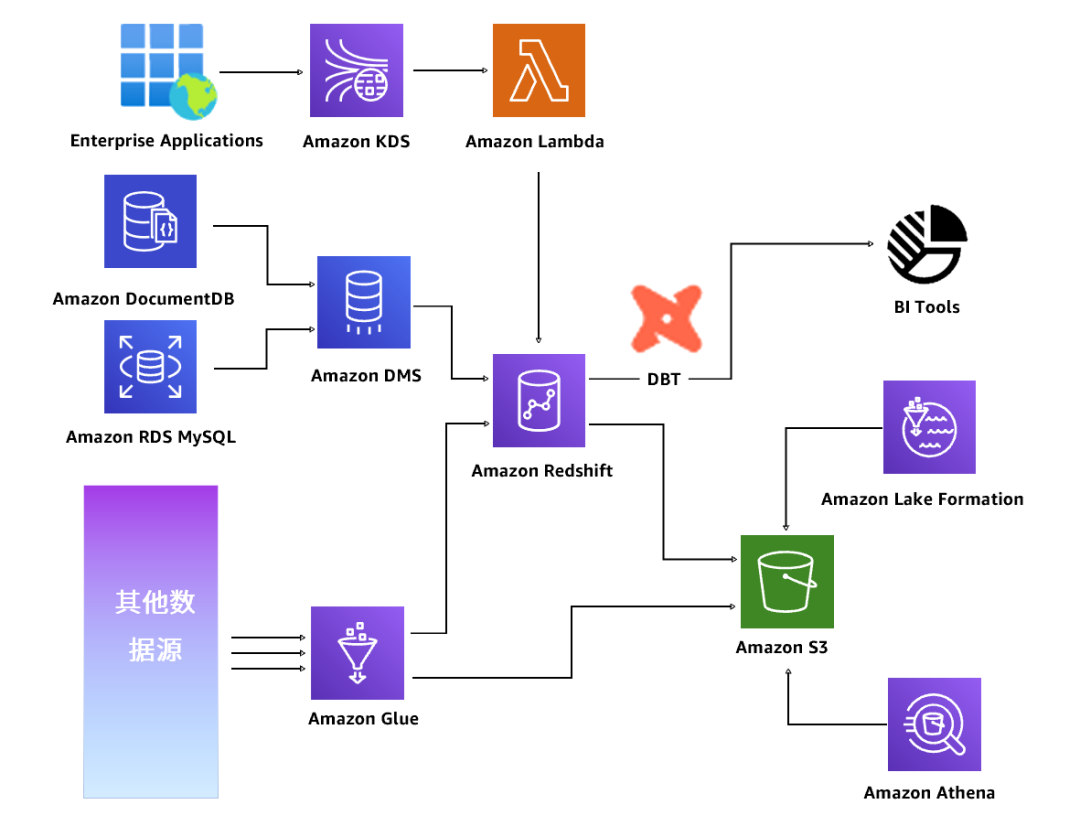
数据分析:运用冷热分离的智能湖仓架构实现降本增效
为了将不同结构、不同类型、不同来源的皮爷咖啡相关数据汇总起来并加以分析、获得见解,亚马逊云科技运用Amazon S3、Amazon Lake formation、Amazon Redshift构建起了冷热分离的湖仓一体架构,数据通过Amazon S3在亚马逊云科技体系及开源体系流转。其中,云原生数据仓库Amazon Redshift可提供强大的SQL功能,对智能湖仓存储内的超大型数据集进行快速在线分析处理(OLAP)。
此外,该数据库还提供并发扩展功能,可在几秒钟内启动更多瞬态集群,借此支持几乎无限数量的并发查询,最终在Amazon Redshift的帮助下,皮爷咖啡能够轻松实现2分钟之内完成两天增量的计算任务。冯亚东肯定道:“现阶段我们积累了皮爷咖啡从成立到现在所有时期不同的迭代版本数据的全面打通,不同数据源都落地在Amazon Redshift节点中,实现了数据的联邦查询。”
最后,冷热分离的湖仓一体架构支持分层存储,从而帮助皮爷咖啡实现成本的高度优化,数据湖与数据仓库之间的原生集成,可以允许客户从仓库存储中移出大量访问频率较低的历史数据,并降低存储成本。
数据开发:开源DBT构建数据开发流程,实现数据血缘
针对于数据开发层面,基于Amazon Redshift Data Sharing的能力,数据开发工程师可以在不同的Redshift集群之间共享数据,并在这个过程中对数据进行脱敏。
凭借该能力,皮爷咖啡的开发工程师可以基于开源工具DBT(Data Build Tool)进行数据开发,形成数据管道脚本。并在开发结束后,经过CI/CD(持续集成,持续部署)流程进行数据提交,保障提交到生产环境的数据没有质量问题,最终,将整个数据的语义层信息,包括数据目录、血缘关系、数据质量检测的结果都通过统一的途径发布给数据的消费者——也就是业务人员,让业务人员可以快速根据语义信息,业务含义搜索到数据资产,查看数据质量,并通过血缘关系找到数据的来龙去脉,从而对数据进行分析。
成果:优雅、敏捷数据架构,让咖啡师也能上手做数据分析
凭借亚马逊云科技智能湖仓架构,皮爷咖啡实现了数据资产的快速落地,从规划到整个中台系统搭建完成,皮爷咖啡只用了1个月的时间就实现了生产数据的上线,如果按照传统的方式进行建设,这个时间可能会延长30%-40%。
现如今,皮爷咖啡的业务单元正在逐步接入大数据平台中,包含HR系统、订单管理系统、ERP系统、会员中心、订单中心以及营销中心等。以DBT为例,该系统中,皮爷咖啡目前已经可以提供超过260个模型为业务部门使用,实现了数据分析的工程化、数据中台的产品化,并提供给更多的业务部门复用。正如冯亚东所预言的那样,皮爷咖啡的大数据平台正在枝繁叶茂的方向迈进。
未来,皮爷咖啡将会继续基于一条数据主线的架构,打开局面,基于Data Vault建模方法,对来自多个系统的的数据进行长期历史存储,添加更多功能,让整个技术架构向更优雅的方向演进。