gdb、make/Makefile
- 引言
- 调试器gdb
- 介绍
- 常用指令
- 自动化构建工具make/Makefile
- 介绍
- 使用
- 依赖关系与依赖方法
- 编辑Makefile
- 伪目标
- 总结
引言
在上一篇文章中介绍了Linux中的编辑器vim与编译器gcc与g++:
戳我看vim与gcc详解哦
在本篇文章中将继续来介绍Linux中的工具:调试器gdb与项目自动化构建工具make/Makefile
调试器gdb
介绍
在Windows环境中,我们使用vs时,常常会逐过程与逐语句地调试代码以更高效地寻找到错误的位置。在Linux中也有其调试器,即gdb:
前面我们应该知道,程序的发布版本有两种,即调试版本Debug与发布版本Release。Debug版本中包含有调试信息,所以可以支持调试;而Release版本中不包含调试信息,同时还进行了一些优化。
在vs中我们可以调整发布版本:

在Linux中默认的发布版本为Release版本,无法直接进行调试,需要以Debug版本发布才可以:
使用 gcc 原文件 -o 可执行文件 -g 就可以实现按照Dubeg版本发布:
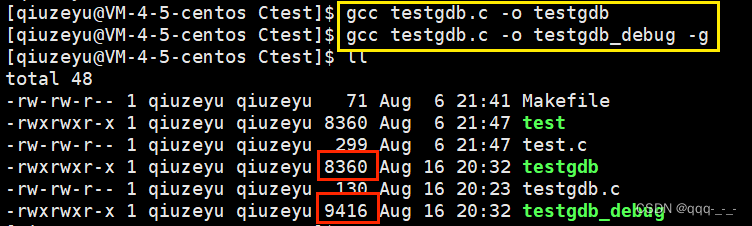
显然,Release版本比ebug版本多占一些空间,即调试信息所占的空间。
常用指令
为方便展示,使用vim编辑一段代码:

-
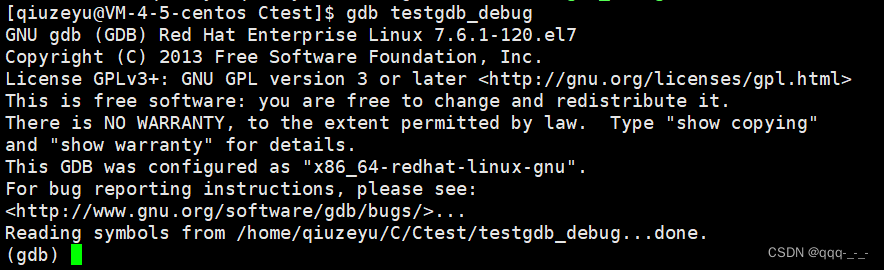
gdb 可执行程序名进入调试环境:
-
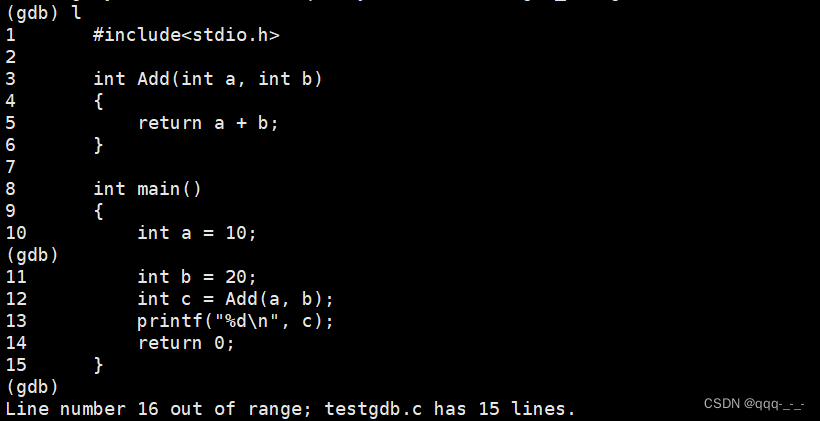
list/l 行号:从某行开始显示源代码,不加行号默认从第一行开始显示,连续l接着上次的位置往下列(可以直接回车默认输入上次的指令),每次列10行:
-
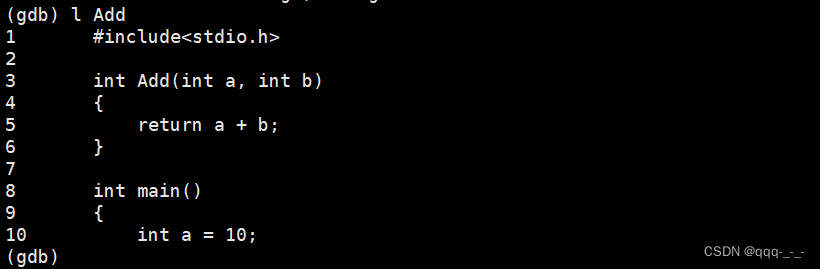
list/l 函数名:列出某个函数的源代码,其实就是从某个函数开始显示10行代码,也可以继续向下显示:
-
r/run:运行程序,就相当于我们vs环境中调试时的f5,从头开始执行程序,遇到断点会停止运行:
continue / c:从当前位置开始连续执行程序,遇到断点会停止运行

-
break/b 行号:在某一行设置断点
设置断点后,再r运行程序时就会在断点处停下:

-
break/b 函数名:在某个函数开头设置断点
设置后断点的行数为函数的第一行代码:

-
info/i break/b:查看断点信息

-
delete breakpoints n / d n:删除序号为n的断点

-
delete breakpoints / d:删除所有断点

-
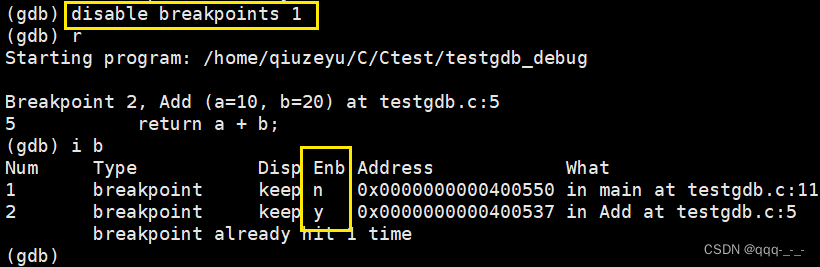
disable breakpoints:禁用断点
断点在禁用后,断点会继续保留,但是在运行时并不会在该断点处停止:
-
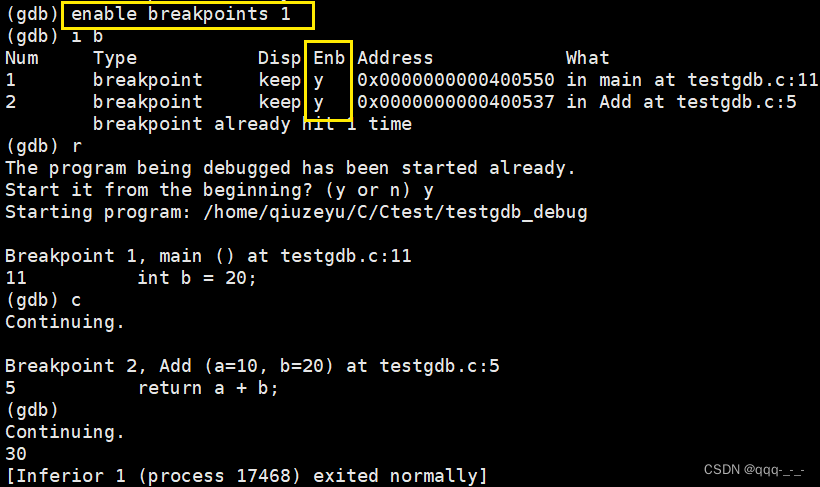
enable breakpoints:启用断点
-
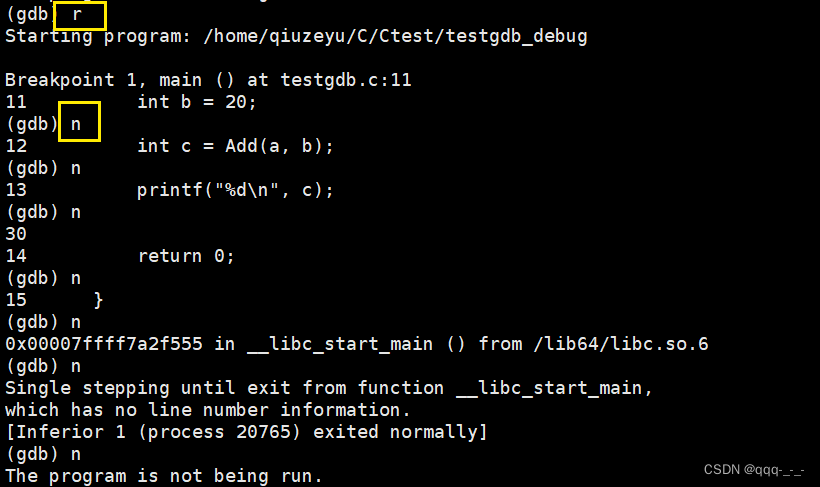
n / next:逐过程执行
相当于vs环境中的f10,即不进入函数,逐过程执行。在执行时会显示当前执行的语句,返回值:
(在使用逐过程逐语句执行时,首先需要r运行起来,从断点处开始执行)
-
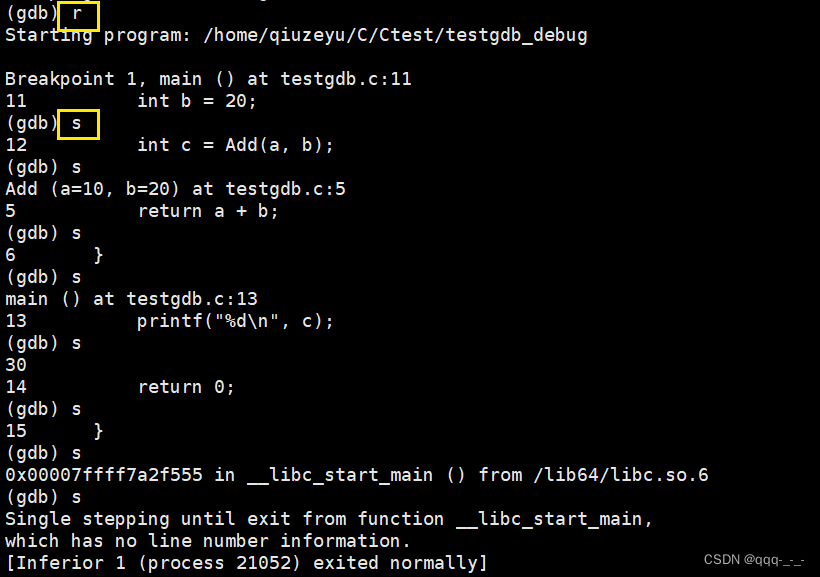
s / step:逐语句执行
相当于vs环境中的f11,即进入函数,逐语句执行。在执行时会显示当前执行的语句,返回值:
-
finish:执行到当前函数返回,然后停下来等待命令
有时候在进入函数后,其中的代码过于繁琐,这时再逐过程的执行到结束就会很麻烦,所以finish就可以直接执行到函数结束:
假设存在一函数func:
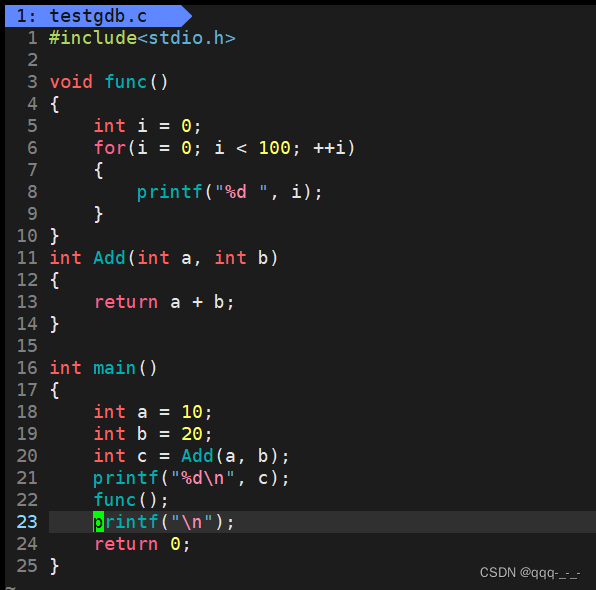
在进入这个函数后就可以finish到函数结束:

-
p 变量名:打印变量值

-
set var 变量名 = val:修改变量的值
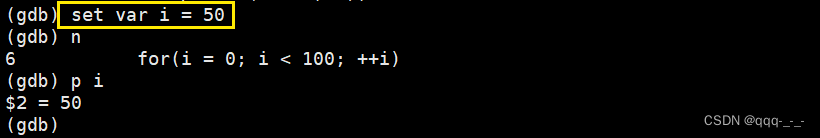
-
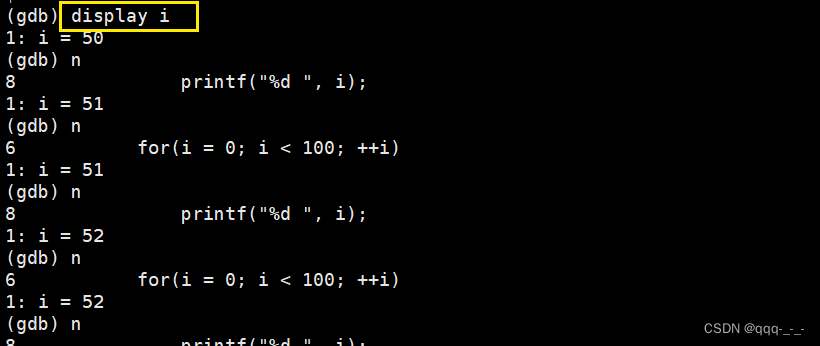
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
跟踪显示变量时,也是有序号的。
-
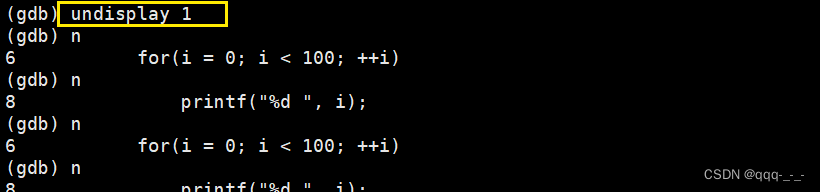
undisplay 序号:取消对变量的跟踪显示
通过序号取消跟踪:
-
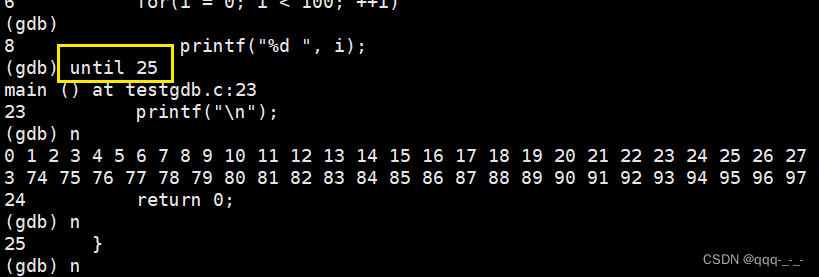
until X行号:运行至X行
-
quit/ q:退出gdb

自动化构建工具make/Makefile
介绍
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建:
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作;
makefile带来的好处就是自动化编译,我们写好之后,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是一个命令工具,能够解释makefile中指令。一般来说,大多数的IDE(集成开发环境)都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。
在使用make命令后,会在当前工作目录下寻找makefile文件并进行自动的解释构建
使用
依赖关系与依赖方法
我们在通过原文件生成目标文件时,目标文件需要依赖原文件在可以产生,没有原文件就没有目标文件,这就是依赖关系;而如何通过原文件生成目标文件的方法即依赖方法。
例如我们有头文件test.h与源文件test.c,要生成一个可执行文件test。 其中test依赖test.h与test.c就是依赖关系,gcc test.h test.c -o test 就是对应的依赖方法。
编辑Makefile
寻找逻辑:
- 当
make在当前工作目录下找到makefile / Makefile文件后 ,会找到其开始的第一个文件为目标文件; - 如果目标文件不存在,或是其所依赖原文件的文件修改时间要比目标文件新,就会执行后面所定义的命令(依赖方法)来生成目标文件;
- 如果目标文件所依赖的原文件不存在,那么
make会在Makefile中继续寻找目标为该原文件的依赖关系与依赖方法,以生成该文件; make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件;- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么
make就会直接退出,并报错。
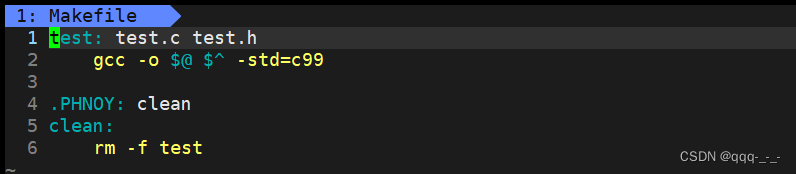
所以在编辑Makefile时,首先就要写出目标文件及其依赖文件:
test: test.c test.h
然后在其下一行写出其依赖方法,需要注意的是,依赖方法前的空格必须为Tab,否则会报错:
(在书写时,简便起见,所有目标文件可以用 $@ 表示,所有依赖文件可以用 $^表示)
gcc -o $@ $^ -std=c99

到现在,我们的Makefile就可以简单进行使用了(这里有一个简单的for循环来测试):

伪目标
make在使用时,当目标文件已经存在,且其最新修改时间比其依赖文件晚的话,连续make是不会生成多个目标文件的:

而伪目标是可以总是被执行的,即任何时候想要执行都是可以的,用.PHNOY修饰。
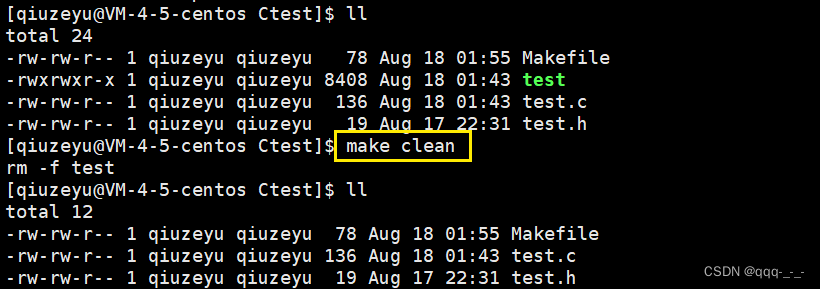
生成的工程是需要被清理的,但是清理操作显然不能因为该目标文件已存在就不执行。所以clean这样的目标文件就可以被声明成伪目标(clean这个目标文件不需要依赖文件,只需要借助它来执行其下的删除指令即可):
.PHNOY: clean //声明伪目标文件
clean: //依赖关系(无依赖文件)
rm -f test //依赖方法
有了伪目标后,就可以随时清理程序了。需要make clean命令:
总结
到此,关于Linux工具的基本知识就全部介绍完了
如果大家认为我对某一部分没有介绍清楚或者某一部分出了问题,欢迎大家在评论区提出
如果本文对你有帮助,希望一键三连哦
希望与大家共同进步哦





![[LeetCode]两数相加](https://img-blog.csdnimg.cn/c791a7d88278423fa9413d70fb51df18.png)





![java八股文面试[java基础]—— 重载 和 重写](https://img-blog.csdnimg.cn/30f1672b1a2c4c34836bb44068079a4d.png)