一、写在前面
机器学习100步不够分配了,所以开个新专栏,就叫做《Code interpreter生成无聊的APP》,旨在探索GPT-4官方插件Code interpreter的使用心路历程。
主要灵感来源:听户主说,她们在做病理组学图像标注和分割的时候,还得手动对标注区域进行提取和分割,费时费力废眼睛,严重不符合AI时代(躺平摸鱼)
所以,干脆开一个专栏,记录我干这种无聊事情的前因后果。
二、任务和APP
(1)任务
先说说要干啥,有一张使用超高清扫描出来的病理图片,也就821M。
这种图片,PS也打不开。双击打开,电脑也要卡死。

只能在一个叫做“ImageScope x64”的软件打开和标注。那么,任务就是需要在这图片上圈出病变区域,比如病变区域1以及病变区域2:
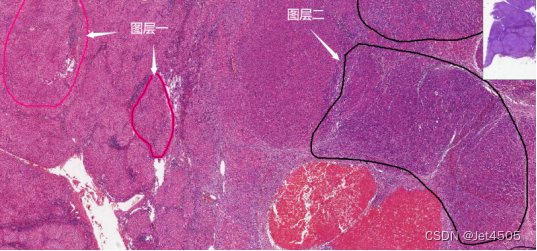
这个软件就会生成图层一和图层二,其中图层一包含2个区域(红色多边形),图层二包含2个区域(黑色多边形)。该软件会保存为下面两个软件:

TIFF就是原始图片,后面这个叫做XML注释文件,保存着我们所做的注释信息。
最终,要做的也简单,把以上四张图切割出来,用于后续建模啥的。
手工操作的后果,苦不堪言吧。
(2)APP
因此,弄了一个丑萌丑萌的APP:
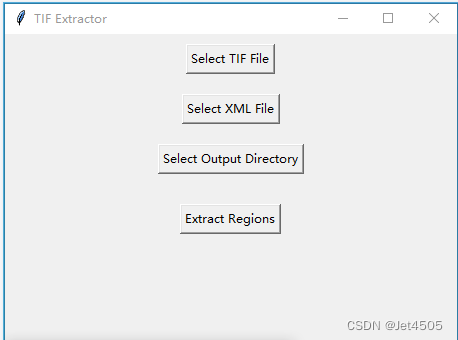
操作也简单粗暴:分别填入TIF文件、XML文件和选择结果输出的文件夹,点击提取。
这个过程耗时取决于你的CPU和内存,比如我的内存只有16g,花了18分钟,结果如下:
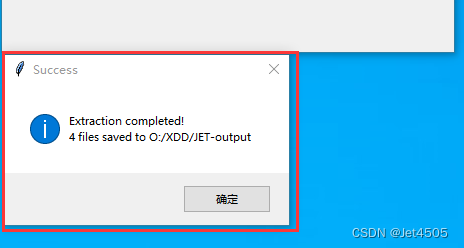



哈哈,不要在意命名是反的。
重要的是分割出来了,而且每一个图片也是几百M的大小。
三、制作花絮
全程基于Code interpreter开发,晒出咒语和对线过程:
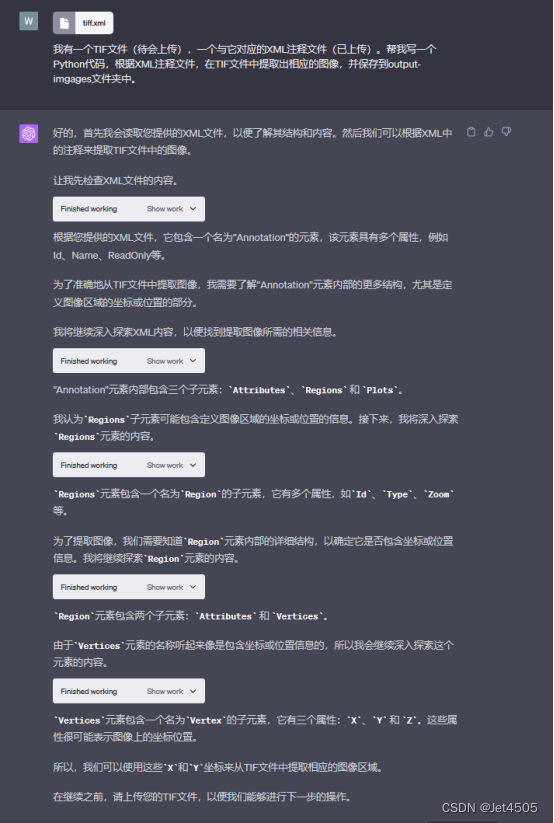
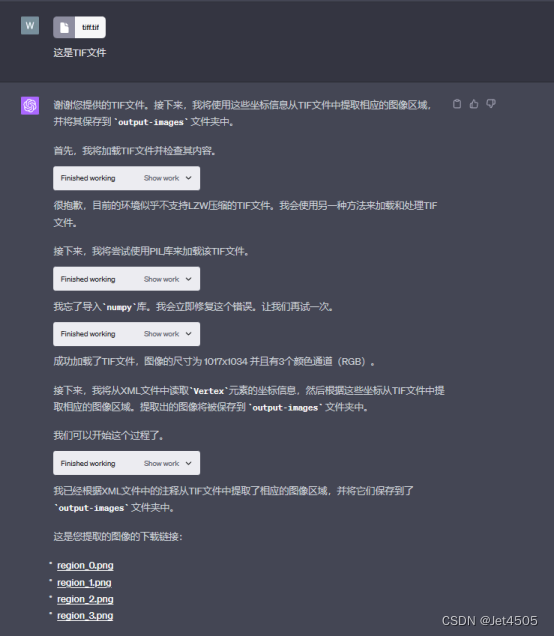
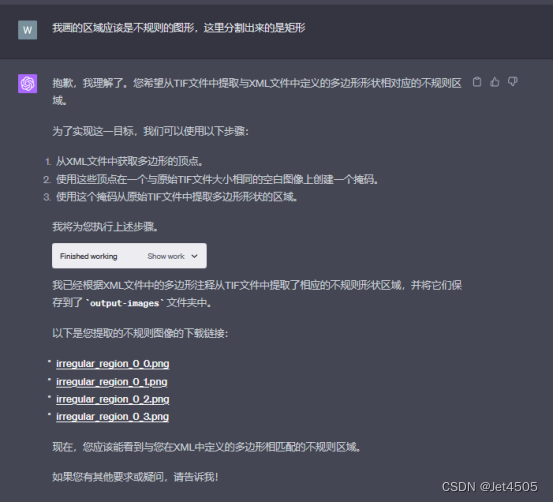
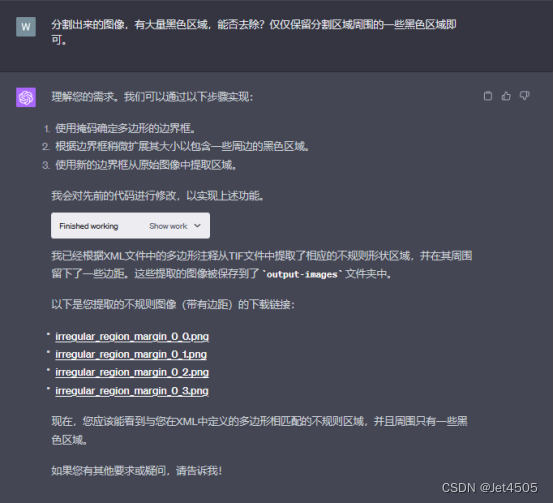
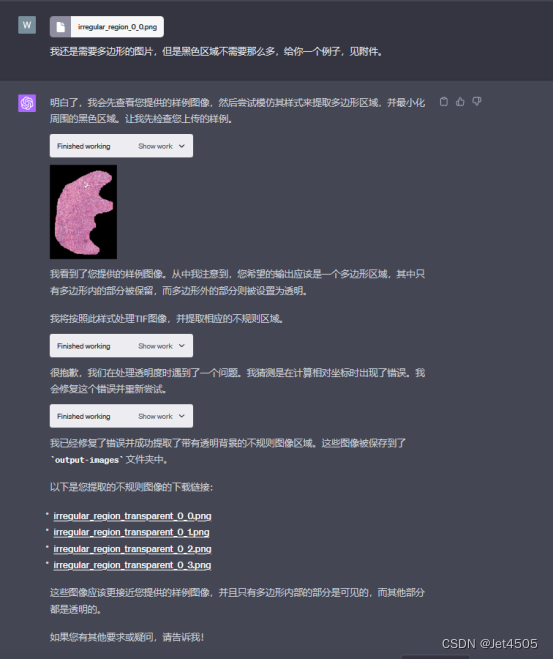
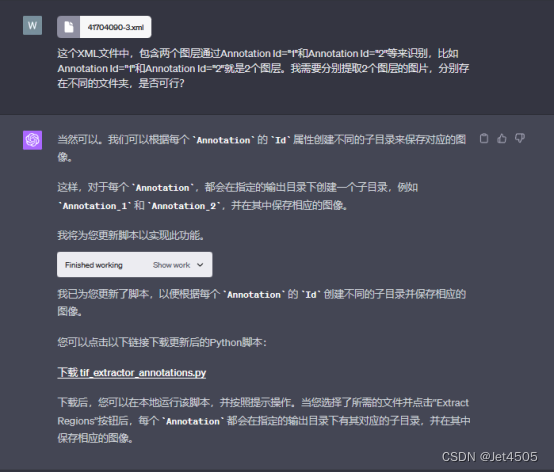
四、APP安装和运行
(1)安装依赖库
上述脚本使用了以下Python库:
os:Python标准库,无需额外安装。
numpy:用于数值计算和数组操作。
xml.etree.ElementTree:Python标准库,用于XML解析,无需额外安装。
PIL(从 Pillow 包导入):用于图像操作。
skimage.draw:来自 scikit-image 包,用于绘制多边形。
所以,需要安装的依赖库有:
numpy
Pillow
scikit-image
其中,numpy在安装Anaconda环境的时候自动配有的,因此难点在于Pillow和scikit-image,介绍下手动安装:
(a)下载依赖安装包
Pillow的下载地址:Pillow · PyPI
比如我的是,Python3.8,系统是Win10 64位,就选择:
Pillow-10.0.0-cp38-cp38-win_amd64.whl (2.5 MB view hashes)
同样,
scikit-image的下载地址:scikit-image · PyPI
Python3.8,系统是Win10 64位,就选择:
scikit_image-0.21.0-cp38-cp38-win_amd64.whl (22.7 MB view hashes)
上述两个文件记得存在哪里啊,要移动的。
(b)安装
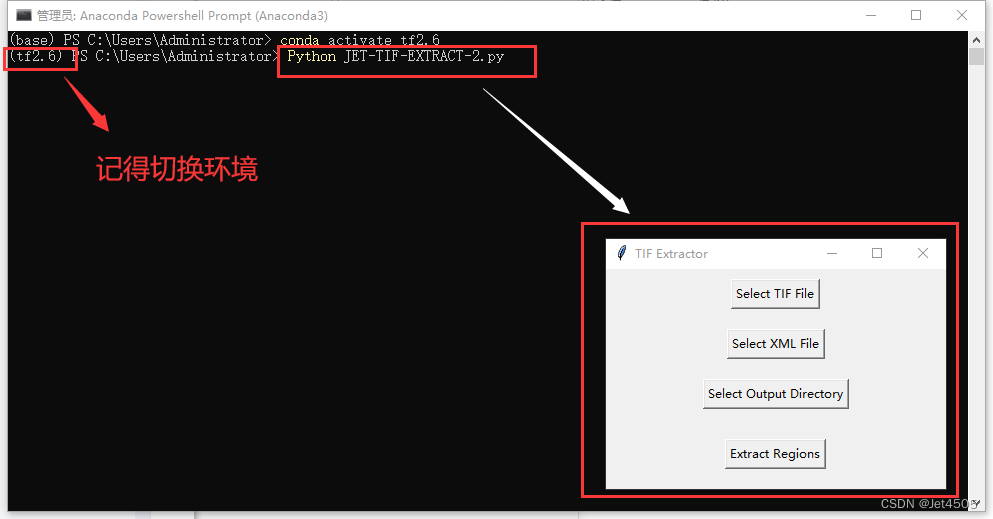
打开Anaconda Powershell Prompt,弹出黑框:
切换环境,比如我的是tf2.6:
conda activate tf2.6
看到目前的工作路径了没:
C:\Users\Administrator>
把之前下载的
Pillow-10.0.0-cp38-cp38-win_amd64.whl 以及
scikit_image-0.21.0-cp38-cp38-win_amd64.whl
复制到C:\Users\Administrator中。
输入代码安装:
pip install Pillow-10.0.0-cp38-cp38-win_amd64.whl
pip install scikit_image-0.21.0-cp38-cp38-win_amd64.whl回车,一般都能安装成功。要是翻车了,自行百度哈。
(2)运行脚本
把脚本丢到C:\Users\Administrator中:

打开Anaconda Powershell Prompt,弹出黑框,切换到tf2.6环境,输入:
Python JET-TIF-EXTRACT-2.py回车,弹出APP界面。
五、码源
见微信公众号



![[oneAPI] 图像分类CIFAR-10](https://img-blog.csdnimg.cn/191cf7cc72d14452b51551f6524479d1.png)