之前我们讲过Selenium使用教程,这一篇我们来学习元素定位的配置管理。
目的
Web自动化测试作为软件自动化测试领域中绕不过去的一个“香饽饽”,通常都会作为广大测试从业者的首选学习对象,相较于C/S架构的自动化来说,B/S有着其无法忽视的诸多优势,从行业发展趋、研发模式特点、测试工具支持,其整体的完整生态已经远远超过了C/S架构方面的测试价值。
接下来我们在上一次的基础之上,对已经初具雏形的自动化代码进行补充和优化,利用Python的特性来对定位元素的管理方法进行设计并讲解其中的思路与注意点。
管理方法
一般来说,界面元素的信息管理方法比较常见的有配置文件、持久化、专项平台和工具等。如何取舍大家也是众说纷纭,但既然我们使用了Python这门语言,那么就要好好利用其优势,将管理的成本(人力、耗时等)降到最低。
相较于一般文本,我们可以使用ini格式的配置文件来对已知晓具体信息的元素进行统一的管理,将业务代码与界面元素进行有效分离,减少后期因需求变动而发生的大量维护工作。
通过以上所说的方法,我们可以将大部分常用的元素信息录入进配置文件,即使后期产品或项目发生了变更,我们也可以灵活应对。
举个例子,如果产品或项目发生了逻辑与功能的变更,那么我们只修改业务代码即可;若是发生了UI变更,我们也只需要修改对应的配置文件。这样的低耦合自动化框架才可以有效的提升日常的测试团队工作效率。
另外,鉴于大部分团队内会有多名测开角色的存在,在定义配置文件之初,也应该有效的开展团队内的讨论,将配置文件的一些总要因素(编写与命名规范、存放路径等)进行充分的认知统一与整合。以防在后期使用时出现元素名不同而无法找到等等诸如此类的低级错误。
配置方法
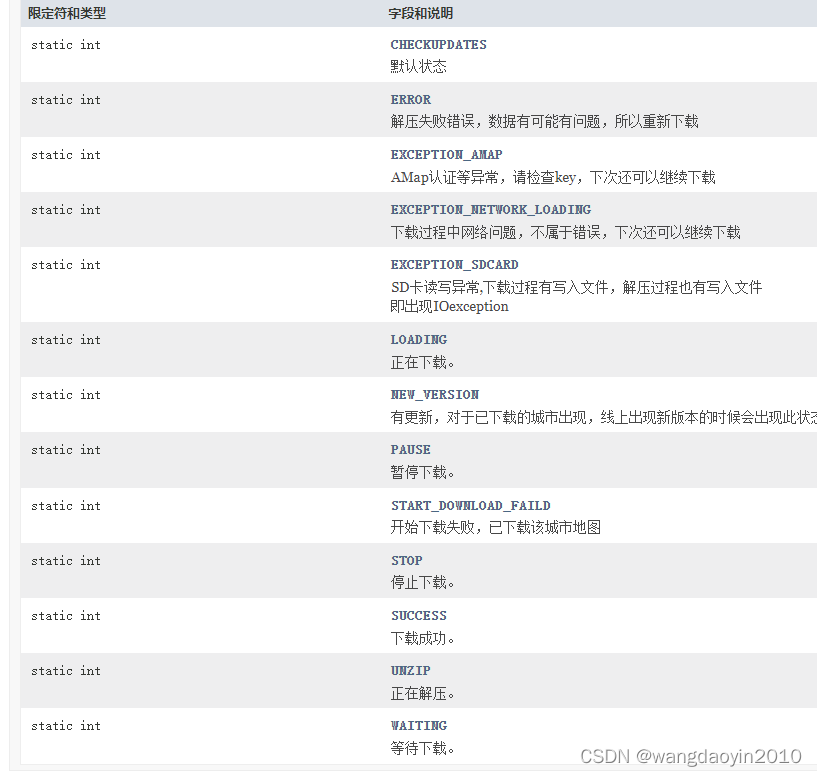
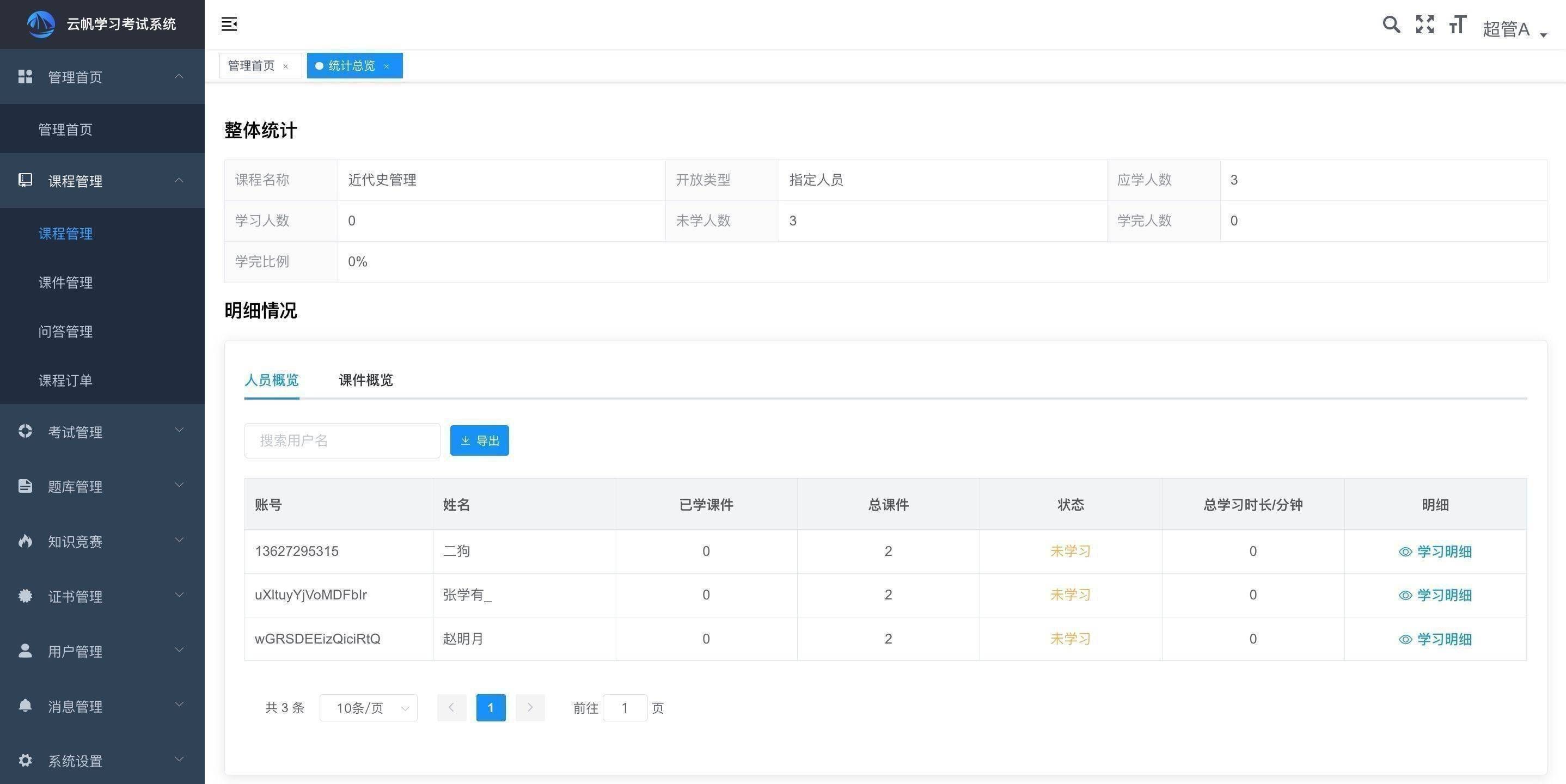
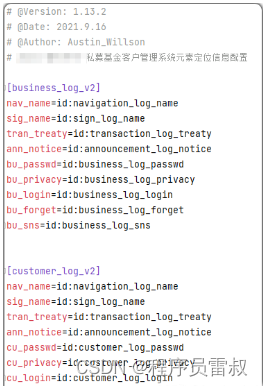
接下来我们先来看下一般的配置文件内都需要写哪些内容,下图展示的是登录页面的相关元素定位信息,这里还是给大家说一下,如果系统的规模不是太大的话建议还是把所有的元素信息放在一个配置文件内进行管理,不宜进行多路径多文件的分散处理。
文件的格式基本就是ini的配置格式,内容由多个section构成(方括号内),每个section内可以存在多个配置项,每一条配置项由配置项名称、定位方法、定位值组成。
配置项名称不用多解释,在代码中会直接使用到,可以简单的理解为类似变量名,后面的id则是定位方法,这里不拘泥于id,如果要使用其他的定位方式,改成对应的方法即可,具体的定位方法可以参看前一篇中的get_element方法。
当中的冒号则只是方便后期在业务代码中进行取值的分割,不强制使用冒号,其他符号均可。
最后的是定位值,也就是开发同学在开发界面中各类元素的对应属性的属性值,这里要注意的是,值必须和你前面指定的方法相对应,千万不能搞错。
这里举个简单的例子,比如LoginPageElement类中有一个get_element的方法,那我们将原有的业务代码内元素转化为配置文件的方法为:
log_pg_ele = LoginPageElement('chrome')log_pg_ele.get_element('id', 'transaction_log_treaty')
是不是很简单,因为在原有的get_element方法内,我们已经定义了相关的定位方法与定位值这两个参数,所以根据配置文件的配置项组成方式可以进行无缝转换,无须再进行额外的操作。
方法实现
有了对应的配置文件,我们就可以使用python来设计实现相关的配置解析与元素调用方法。这里我们先将对应的ini文件创建在各自项目指定的目录中,再啰嗦一次,如果是团队公用,文件名与存放路径需要统一。
假设我的配置文件名为FundManSys.ini,存放在项目的conf文件夹下。我们在使用Python解析配置文件之前,需要先安装对应的功能模块。
这里我们使用configparser这个库,它可以读取解析我们一般的ini类配置文件。
无论是python interpreter亦或是pip install都可以,安装完成之后我们开始进行整体的功能设计与实现。
首先,我们先将读取配置文件的功能进行实现。
这里我创建了一个类,但没有写出来,我们直接展示其内的方法,名字什么的大家可以自由发挥, 构造函数中将需要指定的节点名称带入,如果不指定名称,则带入特定值。
第二段代码通过调用方法ConfigParser来读取解析配置文件,read()内填写配置文件的路径与文件名,这里设置了变量,最后将整个对象返回出来。
def __init__(self, section=None):
if section:
self.section = section
else:
self.section = 'business_log_v2'
def load_ini(self):
cf = configparser.ConfigParser()
cf.read(ini_file)
return cf那么取得对象之后我们如何调用里面的信息呢,接下来就需要对其内进行进一步的处理实现。
这里使用了链式写法,不这么写的话也可以在构造函数中的定义一个变量来接收load_ini方法中返回的对象。section和key两个参数也不用多说了吧,分别对应的已经很明显了。
def get_data(self, key):
data = self.load_ini().get(self.section, key)
return data基本的配置文件解析功能就设计封装好了,是不是很简单?那么我们拿到想要数据之后如何实际结合至现有的元素操作代码中去呢,紧接着我们就可以开始将业务代码与实际配置功能进行对接了。
我们把之前设计的get_element方法进行优化,添加取得数据并处理的操作。
这里实例化的load_ini因为没有指定节点名,就会默认使用business_log_v2节点名。
这里已经将原来的方法参数进行变更,可以看到变更后的参数变少了,原有的by与ele两个参数也被配置项中的定位方法与定位值所替代,这也就是我们要达到的目的。
具体变化大家可以对比前一篇中的get_element方法。
def get_element(self, key):
element = None
load_ini = EleConfiguration()
data = load_ini.get_data(key)
by, ele = data.split(':')
try:
if by == 'id':
element = self.driver.find_element(By.ID, ele)
elif by == 'name':
element = self.driver.find_element(By.NAME, ele)
elif by == 'css':
element = self.driver.find_element(By.CSS_SELECTOR, ele)
elif by == 'class':
element = self.driver.find_element(By.CLASS_NAME, ele)
else:
element = self.driver.find_element(By.XPATH, ele)
except:
session.add(ele_err_msg)
session.commit()
return element至此我们的整体配置管理设计已经完成,真实的使用过程中我们只需要根据自己的实际场景进行页面业务逻辑的代码编写即可,无论是何种界面业务操作都可以直接实例化并调用get_element方法来进行元素定位了,并且由于真实元素信息与业务代码分开的关系,整体的可读性与维护性也是大大提升。
使用注意点
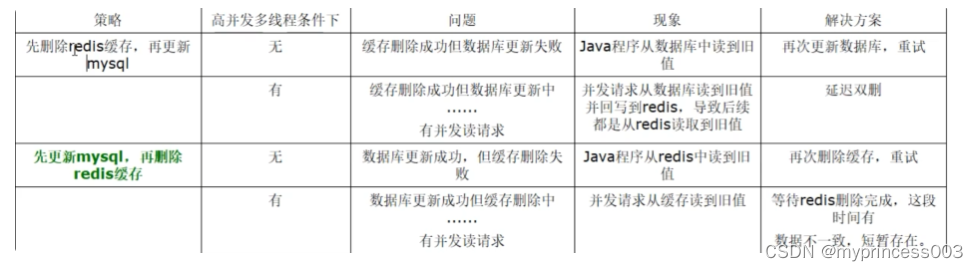
1、Python2与3的版本内configparser模块的名字不同,有大小写之分,需要注意,2是ConfigParser,3是configparser;
2、配置项内的键值对如果连接符号使用冒号,注意中英文状态,以免出现使用中文冒号而意外报错的情况出现;
3、配置文件中不要设置过多的section名,过多的名称容易让配置文件的内容过于混乱,不予与维护;
4、与其说注意更不如说是规范,配置文件内的各类名称尽量都使用英文来定义,和编写代码的命名意义差不多,拼音不应该出现在此类的配置文件内。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取