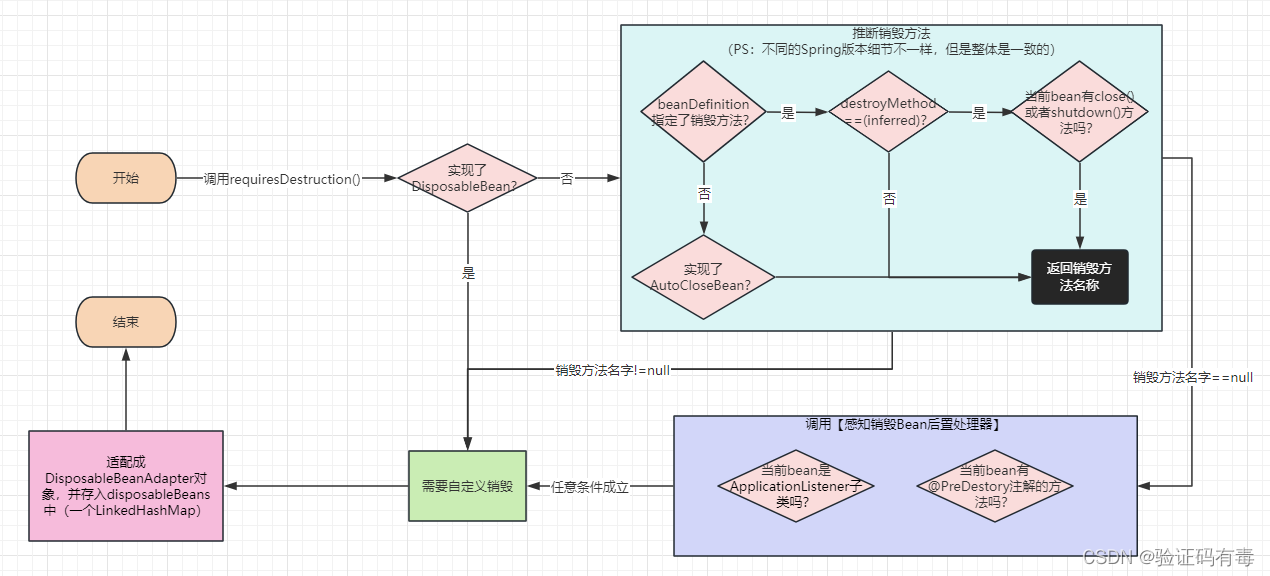
Q:Java 运行时数据区解构,哪些数据线程独占,哪些是线程共享?每个区域会产生GC和异常吗?
运行时数据区:
1、PC寄存器
2、堆区
3、JVM栈
4、Native栈
5、方法区
其中,PC寄存器、Native栈、JVM栈是线程独占的。
堆区、方法区是线程共享的。
PC寄存器 没有垃圾回收,没用任何异常
Native栈、JVM栈会抛出StackOverFlowError 和OutOfMemory:Stack 异常,没有GC
堆区分为新生代和老年代,新生代中的Eden区满触发YGC/Minor GC ,老年代满触发Major GC。
堆区有OutOfMemory :heap 异常
方法区:存在GC (Full GC),在JDK7 以前 存在OutOfMemory:PremGen
JDK8及其以后是 OutOfMemory:MetaSpace
【补充一条】 关于指令
零地址指令、基于栈的指令、基于寄存器的指令。
java字节码之所以能实现跨平台,主要是因为字节码可以被操作系统之上的JVM虚拟机识别,执行。
普通机器指令是基于CPU寄存器的,由于CPU架构不同,导致各个指令集有差异,有一地址,二地址等,这个地址指的就是寄存器地址:
比如 用汇编助记符表示: MOV 0x02 10 ;//这里写的很不严谨,只是为了好理解,这个指令第一个Mov表示操作为将数10,移动地址为0x02的寄存器上。
而零地址,是用基于栈的指令来实现的,因为栈是虚拟的数据结构,并不是实际的硬件。并且,它不需要地址来标记操作数,因为可以通过入栈和出栈来完成移动的效果。
基于栈的指令集就可以避免不同CPU架构造成的指令集不同引起的跨平台性。
但是基于栈的指令集也是有缺点的。
寄存器指令集:指令集大,但是完成一个操作所需要的指令少
栈指令:指令集小,完成一个操作所需要的指令很多,相对效率就低。
Q:具体说一说PC寄存器
设计参考CPU的PC寄存器,目的是存储指令相关的现场信息。
java的PC寄存器 准确的说理解为 指令计数器 (也有人翻译成程序钩子)。
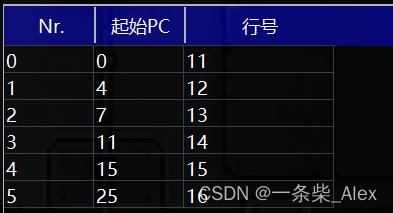
看一下这里的起始PC,其实就是指令对应的编号(地址),也就是将要被放在PC上的数据
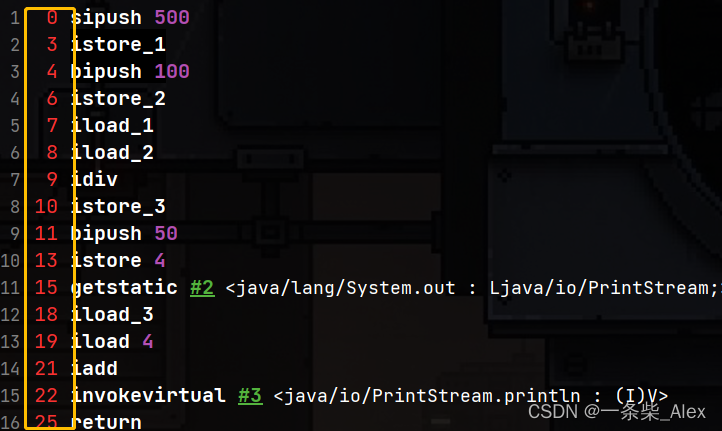
作用:PC 寄存器用来存储指向下一条指令的地址,也即将执行的指令代码。由执行引擎读取下一条指令。
PC上,没用GC,也没有任何异常。
Q:具体说一说虚拟机栈
一个线程有一个JVM栈,当这个线程中进行一次方法调用的时候,会形成一个栈帧。压入这个栈中。
当这个方法执行结束的时候,栈帧会被弹出JVM栈。随着线程的生命周期结束,它对应的JVM栈也会被销毁。
JVM Stack中的栈帧的结构:
局部变量表、操作数栈、方法返回地址、动态链接 和一些附加信息。
JVMStack 不涉及垃圾回收。
它在以下情况会抛出异常:
1、当栈的大小是固定的,当前线程中一个方法中不断的去嵌套式的调用其他方法(比如递归),
从内存的角度来说,就是不断的有栈帧被压入当前线程的JVM栈中,如果最后一次栈帧所需要的空间不足时,会抛出 StackOverFlowError
2、当栈的大小是动态扩容的,当前栈进行扩容时,如果物理内存空间小于栈要扩充的空间,就会抛出OutofMemory :stack 异常
栈帧内的结构说明:
局部变量表:
定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,
局部变量表在线程的栈上,是线程的私有数据,因此不存在数据安全问题。
局部变量表的容量大小是在编译期确定下来的(前段编译 javac 生成字节码),并保存在方法的Code属性的maximum local variables数据项中,
在方法运行期间是不会修改局部变量表的大小的。
在方法调用结束后,局部变量表会随着方法栈帧的弹出而销毁。
局部变量表的Slot,是其最基本的存储单元。
LV中存放着编译期可知的各种基本数据类型(8种),引用类型(reference),returnAddress类型的变量。
LV中,32位内的类型只占用一个slot,64位的类型(long double)占两个slot
byte short char 都会被转成int boolean也会转成int 0false 非0 表示true (字节码指令集里可以看到 bint,sint)
普通对象方法和构造函数的LV中,index0的变量是 this,而静态方法没用。
slot是可以被复用的比如:
public class SlotTest{
public void localVar(){
int a =0;
Sout(a);
int b=0;
}
public void localVar(){
{
int a =0; //a作用域在代码块中,出离了代码块,a这个局部变量就失去作用域,从LV角度来看,a的Slot位就空了,而下面的局部变量b可以対之复用
Sout(a);
}
int b=0;
}
}需要注意的一点是,局部变量表不存在系统默认初始化的过程,(这一点区别于静态变量)
所以,使用局部变量时,务必手动初始化。
局部变量也是可达性分析的根节点,只要是被局部变量表中直接或间接引用的对象,都不会被回收。
操作数栈、
方法返回地址、
动态链接
Q:具体说一说Java的堆
Q:具体说一说Java的方法区
Q:类加载系统
//单独开文
Q:执行引擎的结构和工作
//单独开文
Q:String的不可变性分析
首先说明String的几个问题:
String 是被final修饰的,表示它不可再被继承
jdk8及其以前 String 内部是 final char[] value,Jdk9 之后改成了 byte[]
真正想解释这个所谓的不可变性,还是得从JVM内存结构来分析。
不可变性的表现: 对字符串重新赋值时,需要重新制定内存区域赋值,不能使用原来的value进行赋值。
当对现有字符串进行链接操作时,也需要重新指定内存区域赋值,不能使用原来的value进行赋值。
调用String的replace() 修改指定字符或字符串时,同上
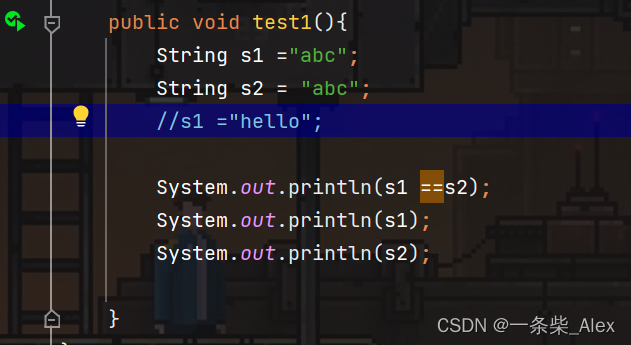
1、字面量创建一个字符串的过程:
此时字符串的值声明在字符串常量池中。
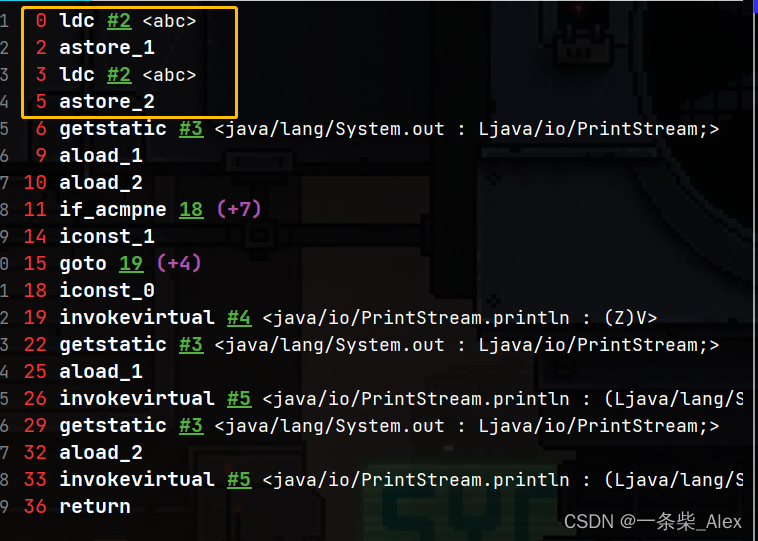
pc =0 ldc #2是什么?:
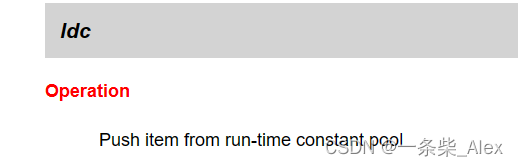
从运行时常量池中取一个元素进操作数栈。
紧接着:astore_1 表示 将操作数栈的引用型变量 保存入局部变量表index1的位置
如果运行时常量池中的条目是字符串常量,即对string类实例的引用,则将对该实例的引用value压入操作数栈。
注意点:
字符串常量池不会存储相同的字符串。
String的 String pool 是一个固定大小的Hashtable,默认长度是 1009,若放入的String 过多,会导致hash冲突严重,从而导致链表很长,链表最大的特点就是插入删除简单,但是遍历时间复杂度高,这样就导致调用String.intern性能大幅下降(intern是会先查重,再插入的,有个遍历过程)
可以使用-XX:StringTableSize设置StringTable的长度
jdk6 StringTableSize 默认1009,大小可以随便修改
jdk7 StringTableSize 默认是60013 大小可以随便设置
jdk8开始,设置StringTableSize长度,不可低于1009
2、new String("xxx")的过程
public void test2(){
String ok666 = new String("OK666");
}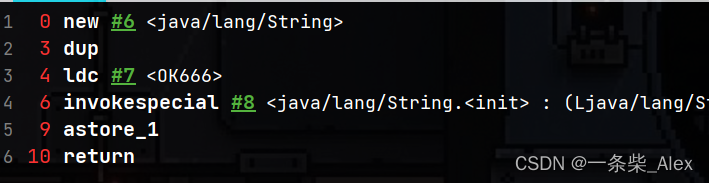
整个过程是 创建对象,从常量池里找到字符串实体对象的引用,通过构造函数给新建对象赋值。
所以:一次 new String(“XX”) 其实底层有两个对象
1、new 关键字在堆空间创建的对象
2、字符串常量池中的对象,字节码指令为 ldc
3、字符串连接符 +
1、常量与常量的拼接结果在常量池,原理是编译期的优化
2、常量池中不会存在相同内容的常量
3、只要其中一个是变量,结果就存在堆中。变量拼接的底层原理是Stringbuilder
4、如果拼接的结果调用了intern(),则主动将常量池中还没有的字符串对象放入常量池中,并返回此对象的地址。
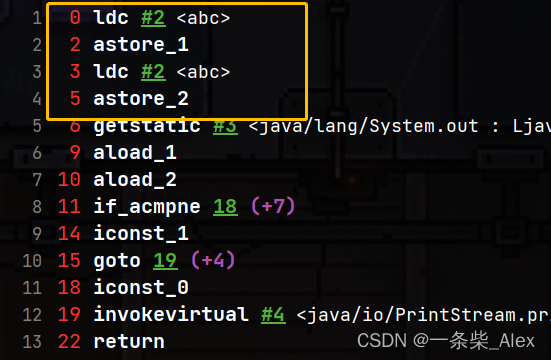
常量拼接
@Test
public void test3(){
String s1 ="a"+"b"+"c"; //常量拼接
String s2 ="abc";
System.out.println(s1 == s2); //true
}
带变量的拼接
@Test
public void test3(){
String s1 ="a"+"b"+"c"; //常量拼接
String s2 ="abc";
String s3 =s2+"test";
System.out.println(s1 == s2); //true
}字节码执行流程如下:
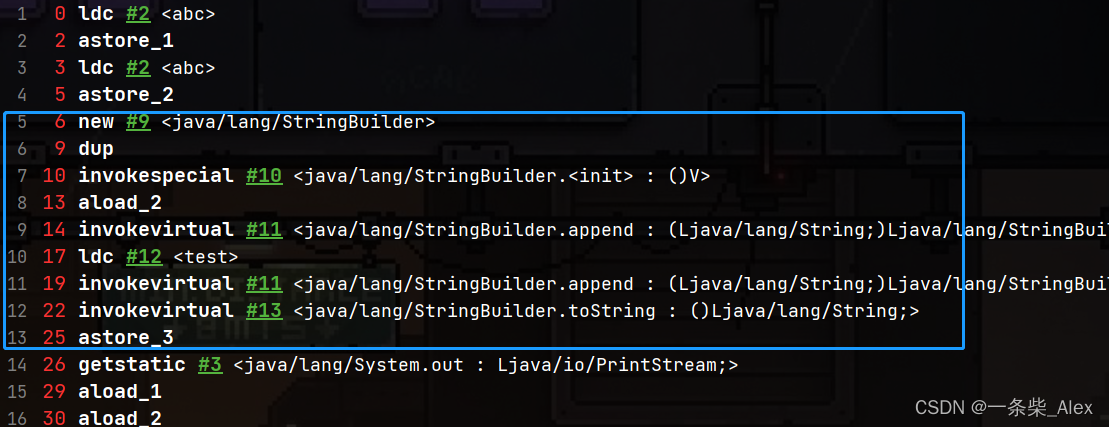
含有变量的字符串拼接操作,用的是Stringbuilder 对象,append()操作。 最后 toString()返回,存入局部变量表
问题:在new String("a")+new String("b")中,一共创建了几个对象?
5个:
new StringBuilder()
new String("a")
常量池里的a
常量池里的b
new String("b")
new String("ab")
特别强调!!
Stringbuilder的toString()被调用,并不会在常量池中生成 "ab"实例
这里有个细节:
通过查看字StringBuilder的toString()节码, 我们发现他和普通的new String()并不一样。它没用ldc指令。
这个是StringBuilder的 toString(),它的内部看上去好像就是new String(),但是看看他的字节码
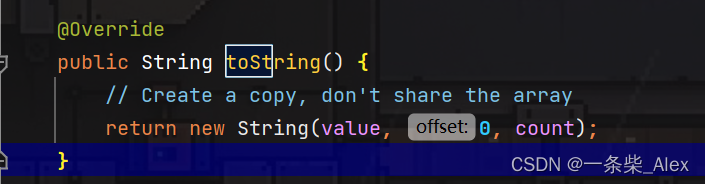
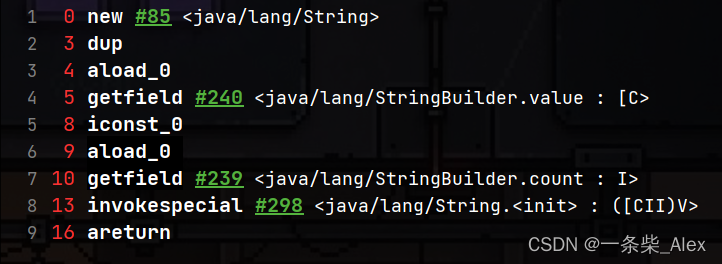
它并不是普通的new String("xx")构造法,会用ldc 从常量池加载一个字面量对象的引用变量入栈,直接进行 invokespecial <java/lang/String.<init>>操作。因此常量池在字节码编译期并没有创建一个字面常量对象 "ab"。
可以对比参考 2、new String("xxx")的过程
String intern()的使用
jdk6 中将这个字符串对象尝试放入常量池
+ 如果池中有,并不会放入。返回已有的池中对象的地址。
+ 如果没有,会把对象复制一份,放入池中,并返回池中对象的地址
jdk7 起 中将这个字符串对象尝试放入常量池
+ 如果池中有,并不会放入。返回已有的池中对象的地址。
+ 如果没有,则会把对象的引用地址复制一份,放入池中,并返回池中的引用地址。
之所以jdk7有这个改变,我分析原因如下:
jdk6(发布时间 2006年12月) Stringtable 和静态变量还是在堆外的,严格的放在方法区中(永久代)
jdk7(发布时间 2011年7月) 中 Oracle收购JRocket虚拟机(2008年)之后,重新定义了关于JVM的一些落地实现方案,
它把Stringtable 和静态变量移到了堆内,虽然这个时候方法区还是用的JVM内存,落地实现还叫永久代。
由于字符串常量已经放在了堆中,为了节省堆内存空间,就没用必要再在堆内常量池中再创建一个副本对象了,直接通过指针引用就可以了。
Q:i++和++i的底层理解
**首先,我是真的想问候一下出这种面试题的人,你们的目的何在?你认为一个普通程序员会去关注底层字节码吗?刷存在感呢?让程序员死记硬背这种问题有意思吗,活该你们一辈子当资本鹰犬,当奴才。
public void test1(){
int i =10;
i++;
System.out.println(i);
}上述方法:局部变量表最大slot数是2 index0 =this,index1 =i;
操作数栈的最大深度 2
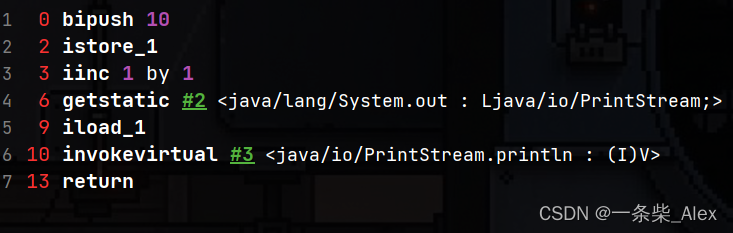
i++ 具体执行过程如图示
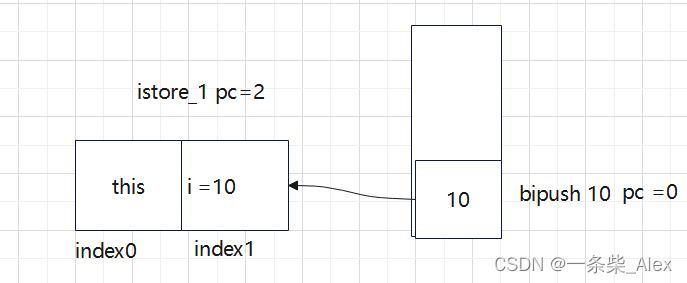

此时,index1位置的变量 i 变成 11
再看看++i
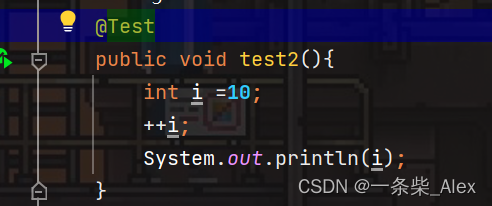
会发现执行结果是一致的:
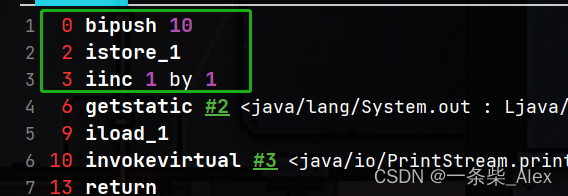
这里总结一句:
自加操作在底层字节码表示的方式是一致的,但是要注意,自加指令是 inc index by 1
这个操作是在局部变量表中完成的,并没有移入移出栈。这个原则会导致下面现象发生:
public void test3(){
int i =10;
i=i++;
System.out.println(i);
}输出结果是10,这里有个关键问题就是,自加操作,对变量i本身再次复制:
赋值操作实际上是将 操作数栈中最新的变量,去覆盖对应局部变量表中旧的变量。
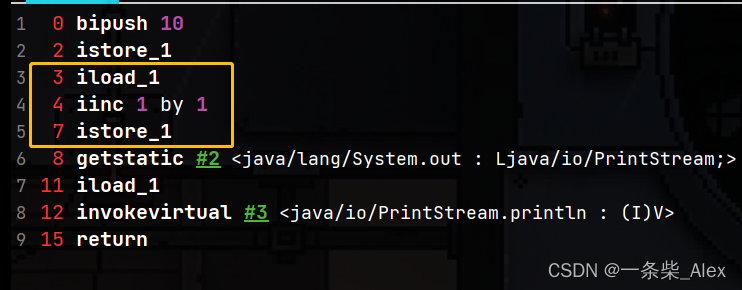
pc =3 iload_1 指把LV中 index1 的变量i 取到操作数栈中,
pc=4 iinc 1 by 1 ,LV中 index1 进行自加操作
pc=7 将操作数栈的内容写回 LV index=1的位置。
所以,此时出现取出i=10, i在局部变量表中自加(LV index1 i=11),写回i=10,重新覆盖了 局部变量表中的 i.