文章目录
- 原理
- 代码
- 结果
- 参考
原理
同时训练两个网络:辨别器Discriminator 和 生成器Generator
Generator是 造假者,用来生成假数据。
Discriminator 是警察,尽可能的分辨出来哪些是造假的,哪些是真实的数据。
目的:使得判别模型尽量犯错,无法判断数据是来自真实数据还是生成出来的数据。
GAN的梯度下降训练过程:

上图来源:https://arxiv.org/abs/1406.2661
Train 辨别器: m a x max max l o g ( D ( x ) ) + l o g ( 1 − D ( G ( z ) ) ) log(D(x)) + log(1 - D(G(z))) log(D(x))+log(1−D(G(z)))
Train 生成器: m i n min min l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))
我们可以使用BCEloss来计算上述两个损失函数
BCEloss的表达式:
m
i
n
−
[
y
l
n
x
+
(
1
−
y
)
l
n
(
1
−
x
)
]
min -[ylnx + (1-y)ln(1-x)]
min−[ylnx+(1−y)ln(1−x)]
具体过程参加代码中注释
代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter # to print to tensorboard
class Discriminator(nn.Module):
def __init__(self, img_dim):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
nn.Linear(img_dim, 128),
nn.LeakyReLU(0.1),
nn.Linear(128, 1),
nn.Sigmoid(),
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, z_dim, img_dim): # z_dim 噪声的维度
super(Generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(z_dim, 256),
nn.LeakyReLU(0.1),
nn.Linear(256, img_dim), # 28x28 -> 784
nn.Tanh(),
)
def forward(self, x):
return self.gen(x)
# Hyperparameters
device = 'cuda' if torch.cuda.is_available() else 'cpu'
lr = 3e-4 # 3e-4是Adam最好的学习率
z_dim = 64 # 噪声维度
img_dim = 784 # 28x28x1
batch_size = 32
num_epochs = 50
disc = Discriminator(img_dim).to(device)
gen = Generator(z_dim, img_dim).to(device)
fixed_noise = torch.randn((batch_size, z_dim)).to(device)
transforms = transforms.Compose( # MNIST标准化系数:(0.1307,), (0.3081,)
[transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081,))] # 不同数据集就有不同的标准化系数
)
dataset = datasets.MNIST(root='dataset/', transform=transforms, download=True)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
opt_disc = optim.Adam(disc.parameters(), lr=lr)
opt_gen = optim.Adam(gen.parameters(), lr=lr)
# BCE 损失
criterion = nn.BCELoss()
# 打开tensorboard:在该目录下,使用 tensorboard --logdir=runs
writer_fake = SummaryWriter(f"runs/GAN_MNIST/fake")
writer_real = SummaryWriter(f"runs/GAN_MNIST/real")
step = 0
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(loader):
real = real.view(-1, 784).to(device) # view相当于reshape
batch_size = real.shape[0]
### Train Discriminator: max log(D(real)) + log(1 - D(G(z)))
noise = torch.randn(batch_size, z_dim).to(device)
fake = gen(noise) # G(z)
disc_real = disc(real).view(-1) # flatten
# BCEloss的表达式:min -[ylnx + (1-y)ln(1-x)]
# max log(D(real)) 相当于 min -log(D(real))
# ones_like: 用1填充得到y=1, 即可忽略 min -[ylnx + (1-y)ln(1-x)]中的后一项
# 得到 min -lnx,这里的x就是我们的real图片
lossD_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake).view(-1)
# max log(1 - D(G(z))) 相当于 min -log(1 - D(G(z)))
# zeros_like用0填充,得到y=0,即可忽略 min -[ylnx + (1-y)ln(1-x)]中的前一项
# 得到 min -ln(1-x),这里的x就是我们的fake噪声
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
lossD = (lossD_real + lossD_fake) / 2
disc.zero_grad()
lossD.backward(retain_graph=True)
opt_disc.step()
### Train Generator: min log(1-D(G(z))) <--> max log(D(G(z))) <--> min - log(D(G(z)))
# 依然可使用BCEloss来做
output = disc(fake).view(-1)
lossG = criterion(output, torch.ones_like(output))
gen.zero_grad()
lossG.backward()
opt_gen.step()
if batch_idx == 0:
print(
f"Epoch [{epoch}/{num_epochs}] \ "
f"Loss D: {lossD:.4f}, Loss G: {lossG:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise).reshape(-1, 1, 28, 28)
data = real.reshape(-1, 1, 28, 28)
img_grid_fake = torchvision.utils.make_grid(fake, normalize=True)
img_grid_real = torchvision.utils.make_grid(data, normalize=True)
writer_fake.add_image(
"Mnist Fake Images", img_grid_fake, global_step=step
)
writer_real.add_image(
"Mnist Real Images", img_grid_real, global_step=step
)
step += 1
结果
训练50轮的的损失
Epoch [0/50] \ Loss D: 0.7366, Loss G: 0.7051
Epoch [1/50] \ Loss D: 0.2483, Loss G: 1.6877
Epoch [2/50] \ Loss D: 0.1049, Loss G: 2.4980
Epoch [3/50] \ Loss D: 0.1159, Loss G: 3.4923
Epoch [4/50] \ Loss D: 0.0400, Loss G: 3.8776
Epoch [5/50] \ Loss D: 0.0450, Loss G: 4.1703
...
Epoch [43/50] \ Loss D: 0.0022, Loss G: 7.7446
Epoch [44/50] \ Loss D: 0.0007, Loss G: 9.1281
Epoch [45/50] \ Loss D: 0.0138, Loss G: 6.2177
Epoch [46/50] \ Loss D: 0.0008, Loss G: 9.1188
Epoch [47/50] \ Loss D: 0.0025, Loss G: 8.9419
Epoch [48/50] \ Loss D: 0.0010, Loss G: 8.3315
Epoch [49/50] \ Loss D: 0.0007, Loss G: 7.8302
使用
tensorboard --logdir=runs
打开tensorboard:
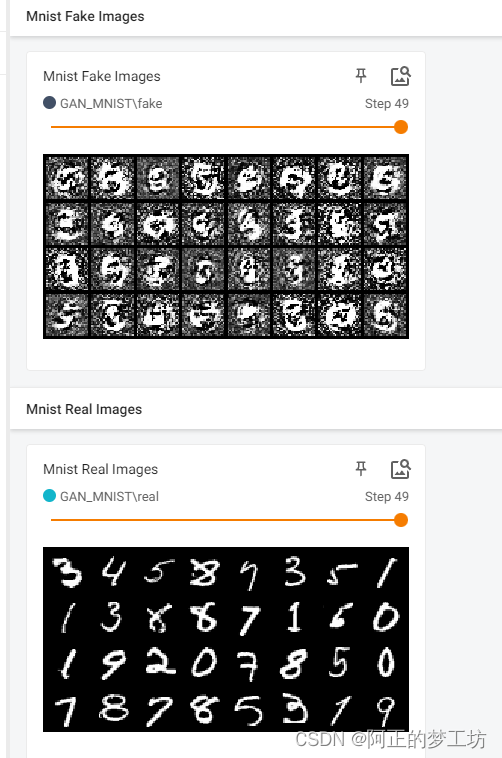
可以看到效果并不好,这是由于我们只是采用了简单的线性网络来做辨别器和生成器。后面的博文我们会使用更复杂的网络来训练GAN。
参考
[1] Building our first simple GAN
[2] https://arxiv.org/abs/1406.2661