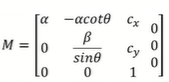本文分享了一个「传统机器学习算法」在实际业务中的使用场景。

前言
如果嫌麻烦,你可以直接跳到正题观看~
最近无论是在工作中的交谈,还是在日常刷屏的新闻,铺天盖地的都是大模型。我横竖是看不明白,费了大劲终于从字缝里看到了两个字,玄学。仿佛回到了我的学生时代。
还记得6年前刚进入研究生实验室时,师兄兴奋的对我说:小伙子,欢迎来到我们的修仙世界!——当时学校跟英伟达合作,刚刚从英伟达那里弄了500块Tesla显卡,供各个实验室申请使用。这,是我们崭新的炼丹炉。经过3年的研究生生涯,我对深度学习的理解,仅仅到能够使用深度学习模型的程度。期间也有一些小成绩,包括一篇CCF B类会议论文和一篇KBS期刊(影响因子8.038) ,文章内容主要是使用LSTM对用户兴趣偏好和用户兴趣迁移建模,以此来搭建一个推荐算法模型。
我们通过对各种神经网络模型的堆叠以及反复的对比实验,确实发现LSTM模型的能够在准确率、召回率等指标上有比较突出的效果。但是有一个很大的问题拦在我面前:我如何去解释它?确实,我们没法从直观定性的角度去解释,也没有数学逻辑能解释。索性我们当时就套用了大家统一的口径,解释说LSTM具有长短时记忆能力,因此能够归纳随着时间轴变化的数据规律。还好当时的审稿人并没有对我们的解释提出质疑,也可能不只是我一个,而是大家的论文都没有很好的解释它。
无论是简单的FC、CNN、RNN、LSTM这些模型,还是当下最火的所谓的大模型依赖的Transformer模型,都是基于梯度下降和反向传播进行训练,至于为什么通过这样的训练就能让模型中参数自动自洽,到如今也没有人能够证明。我们只是知道通过这样去构造模型确实行之有效。
相反,很多传统的机器学习算法,要么有严格的数学证明,要么是直观就能观察到算法的过程。相比于深度学习模型,我认为能够提出这些传统机器学习算法的前辈们更加值得敬佩。因此,本文主要是简单的分享一个所谓「传统机器学习算法」在实际业务中的使用场景。当然,我再次声明我对深度学习的理解尚浅,如有表述不当之处,可以互相交流。

正题
在计划域中,有很多很有意思的问题需要解决,包括如何制定中长期采购计划?如何制定短期补货计划?仓库库存偏仓怎么办,如何配平,是否需要调拨?我能预测一下未来一段时间某个货能卖多少吗?解决每一个问题,都能给供应链的效率和损益带来巨大价值。
那我们以调拨计划为例,看看这些算法是怎么优雅地解决这个问题的——这里说到的算法,都是传统的机器学习算法。
▐ 模型定义:如何用数学模型定义一个调拨业务,并将业务目标变成模型目标函数
为了降低问题的复杂度,便于大家理解,这里我们的对问题的定义进行了一定的简化,比如不考虑未来销售可能存在的波动、偏仓造成的销售机会损失、货物在运输途中存在损毁概率等等。并且,下面的案例只给了一个调出仓、一个调入仓。实际业务中问题更复杂,定义约束也更多,求解的模型可能会不一样。算法大佬们轻喷~
前置知识
偏仓:在仓库存在全国各个仓分布不均衡,是否均衡的判断标准是该仓覆盖范围内潜在的购买量和仓库已有库存量是否匹配
调拨:将货物从A仓集中搬运到B仓
发货:从仓库出库+运输+末端派送至消费者
跨区发货:消费者所在区域的仓缺货需要换仓从其他大区的仓发货给消费者
业务分析
当在仓库存偏仓的时候,会造成跨区发货,跨区发货的快递成本比非跨区发货高
如果能提前通过集中调拨的方式将货物配平(即批量的将货物先配送到用户所在的地区的仓),且满足:单件集中调拨成本+单件发货成本 < 单件跨区发货成本
仓库的出库能力、收货能力、干线运输能力有上限限制
调出仓需要优先满足本仓覆盖范围内的潜在消费者
建模

业务目标:我们要最小化货物从仓库到消费者手中的物流成本
成本函数:发货成本
假设有N个货品货品

调出仓A
调入仓B
约束1:对任意一个货品,从A仓调出量小于A仓库存-A仓自身需求量,即
 ,其中
,其中 表示货品
表示货品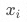 从A仓的调出至B仓的量。
从A仓的调出至B仓的量。 表示货品
表示货品 在A仓的库存,
在A仓的库存, 在仓库A覆盖范围内的预计售卖量表示货品
在仓库A覆盖范围内的预计售卖量表示货品
约束2:对任意一个货品,调入B仓的量小于B仓覆盖范围内的预计售卖量-B仓已有的在仓库存,即
 ,字符含义同上。
,字符含义同上。约束3:一次调拨的量,要小于A仓到B仓的干线运输能力,即
 ,其中
,其中 是一个常量,表示最大的干线运输能力
是一个常量,表示最大的干线运输能力目标函数:
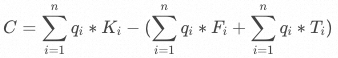
其中
 是个常量,表示货品
是个常量,表示货品 通过跨区发货到消费者手中的发货成本,
通过跨区发货到消费者手中的发货成本, 是个常量,表示货品
是个常量,表示货品 从A仓调拨到B仓的调拨成本,
从A仓调拨到B仓的调拨成本, 表示提前将货品从A仓调拨到B仓,避免跨区发货而节省的成本。因此,我们要「最小化货物从仓库到消费者手中的物流成本」,即,最大化节省的金额
表示提前将货品从A仓调拨到B仓,避免跨区发货而节省的成本。因此,我们要「最小化货物从仓库到消费者手中的物流成本」,即,最大化节省的金额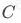 。
。
宗上所述,模型定义如下:

到这里,整个建模过程就结束了。实际上我们忽略了很多细节,但是并不影响我们理解这个调拨模型。至于模型怎么求得每一个调拨量 以保证最大化收益,就要对这个模型进行求解了。
以保证最大化收益,就要对这个模型进行求解了。
▐ 模型求解:怎么才能算出目标函数最优时的参数解
明确求解目标
既然要求解,我们就要明确到底要求解什么?即,在上面定义的数学模型中要明确哪些是常量哪些是变量。
很明显,我们需要求解的变量是 ,即每个货品需要从A仓调拨多少件到B仓。这里为了方便解释,我们就假设一共就两个货品
,即每个货品需要从A仓调拨多少件到B仓。这里为了方便解释,我们就假设一共就两个货品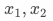 ,相应的我们需要求解的变量就
,相应的我们需要求解的变量就 。
。
求解算法

根据约束条件看,解空间就在坐标轴圈定的阴影范围内。实际上,最简单的求解方法就是暴力枚举所有可能的结果,然后求出函数值最大时对应的参数即可。
当然了,现实的问题中求解的参数量一定是远远大于2个的,因此参数求解的时间复杂度呈指数级上升,以当前的算力,可能直到生命的尽头可能都得不到答案。生命是宝贵的,对于这种问题,有没有快速的解法呢?有,这里我们就要引出一个算法概念——启发式搜索算法,这是一种算法理念的统称,具体的实现有很多种,比如模拟退火算法、遗传算法、蚁群算法等。宗旨就是在有限的时间内,得到一个近似的最优解。
这里以遗传算法为例,我们来学习它的求解过程:
遗传算法(Genetic Algorithm)遵循『适者生存』、『优胜劣汰』的原则,是一类借鉴生物界自然选择和自然遗传机制的随机化搜索算法。遗传算法模拟一个人工种群的进化过程,通过选择(Selection)、交叉(Crossover)以及变异(Mutation)等机制,在每次迭代中都保留一组候选个体,重复此过程,种群经过若干代进化后,理想情况下其适应度达到近似最优的状态。算法具体逻辑可参考:https://zhuanlan.zhihu.com/p/460368294这类算法不仅很有效,而且是可理解可证明的。记得多年前,第一次接触到这种算法类型的时候,深深地感受到了前人的智慧。
在实际应用中,我们可以使用一些现成的算法求解器,例如cplex。至此,通过问题定义、建模、求解。调拨模型中,从A仓到底要调拨多少量到B仓才能节省更多的成本的问题就解决了。

展望
面对一个需要优化的业务问题,传统的思路是从问题定义、建模再到求解。而深度学习模型的思路是:
向量化:无论什么类型的数据,文字、图片、视频、声音,首先是将数据向量化,比如文字可以使用word2vec转换成一串01向量。
将训练数据的目标结果也向量化:一般来说输入的数据和目标结果是同一种数据类型,也可以不一样。
选定目标函数:一般来说目标函数针对不同的任务类型有其固定的目标函数。比如常见的RMSE、Cross-Entropy、Categorical-Cross-Entropy等等。
训练模型:将模型输出的结果向量与目标结果向量代入目标函数,计算loss。同时计算梯度值,调整模型参数。直到在训练集上的loss足够小或者每次迭代的loss不再变低为止,训练结束。
可以理解为,无论什么问题只要将数据向量化,就可以通过深度学习模型求解。其中建模的过程可以省略,模型求解也是固定的范式。然后问题就解决了,我对这种神经网络模型也大为震撼。
人类的很多发明创造,都是从自然中学来的。比如机翼模仿的是鸟的翅膀,让上下两侧的气流速度不一样来形成向上的气压差;疏水材料模仿的是荷叶表面纹理仿制的。前面提到的启发式搜索算法,也是对自然界动植物等的模拟衍生出来的算法,原来很多问题在没有数学的时候,就能够通过生物本能的解决这个问题。同理,现在的深度学习模型,大家都说这是对人脑神经元与神经突触的模拟,同样的,我们接触的声音、视觉画面、文字等等都是通通转换成电信号,经过重重神经元之后,变成了我们可以理解的一个个具象的东西——一首歌、一部电影、一只小狗...... 神经网络模型跟这确实也有异曲同工之妙。
所以我并不觉得神经网络模型不对,只是我们对模仿的本体——大脑的科学认知都不够,那么通过模仿出来的神经网络模型让人更加不可理解,不可证明、也不可证伪。或许,现在所谓的神经网络模型压根就是错误的?或许等我们的脑科学有更大进步的时候,会有一种全新的能够科学证明的神经网络模型出现?
现在很多人把深度学习当做一个框,什么都往里装,以为深度学习就是万能解药,特别是一些神奇的大V发的文章,看多了总归有些不适。我们现在使用大模型的过程,就像三体里的火鸡科学家一样,在黑夜中不断摸索规律。至于这个规律是真理还是深坑,不得而知。大模型能发展到什么地步,那就要看后人的智慧了。

团队介绍
我们是大淘宝技术-品牌供给技术部,目前主要负责消费电子、家装家居、天猫优品等行业的供应链业务。团队致力于解决采购、调拨、仓储、履约等多环节的业务优化问题,为平台商家和集团自营业务提供极致的供应链体验。将仿真优化、运筹学、机器学习和智能AI算法与实际业务场景相结合,为供应链降本提效、提升消费者物流体验提供一站式解决方案。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法