Index
数据库中的索引(Index)是一种数据结构,用于提高数据库查询性能和加速数据检索过程。索引可以看作是数据库表中某个或多个列的数据结构,类似于书中的目录,可以帮助数据库管理系统更快地定位和访问数据。它们是数据库优化的重要工具,特别是在处理大量数据时。
传统的Select搜索策略为:线性搜索,从数据集的开头开始,按顺序逐个比较每个元素,直到找到目标元素或者遍历完整个数据集。
而Index搜索策略为:B-Tree(平衡树)或者B+Tree。
B-Tree(平衡树)索引: B-Tree 是一种常见的索引数据结构,适用于范围查询和等值查询。B-Tree 索引在数据库中广泛使用,它保持树的平衡,使得在平均情况下,每次搜索都能在 O(log n) 时间内找到目标。
B+Tree(平衡加强树)索引: B+Tree 是 B-Tree 的变种,更适合数据库系统,特别是范围查询。B+Tree 的叶子节点形成一个有序链表,可以支持高效的范围查询操作。
执行 CREATE INDEX 语句可以为数据中某个字段构建索引:
CREATE INDEX index_name ON table_name (column_name);
-- 在这里,index_name 是索引的名称(唯一),table_name 是表的名称,column_name 是要创建索引的列名。
show index from table_name ;
-- 查看索引
drop index index_name on table_name;
--删除索引
另外需要注意,MySQL为了支持高速搜索,有一些字段或变量默认情况下会自动使用索引。
主键(Primary Key): 在创建表时指定的主键列会自动创建主键索引,确保该列的值唯一且非空。主键索引是一种特殊的唯一性索引,通常用于唯一标识表中的每一行数据。
唯一性约束(Unique Constraint): 在创建表时指定的唯一性约束会自动创建唯一性索引。唯一性索引确保该列的值在表中是唯一的,但允许包含空值。
外键(Foreign Key): 在创建外键时,被引用的列会自动创建索引,以加速连接操作。这个索引通常是 B-Tree 索引。
自动递增列(Auto-Increment Column): 在 MySQL 中,使用自动递增的整数值作为主键,例如 AUTO_INCREMENT 列,会自动创建 B-Tree 索引。
Index的优势与劣势
优势:
提高数据查询效率,降低数据的IO成本。
通过索引对数据进行排序,降低数据排序的成本,降低CPU消耗。
劣势:
索引会占用存储空间。
索引在大大提高查询效率的同时,也降低了insert,update,delete的效率。
B-Tree
B-Tree的结构:
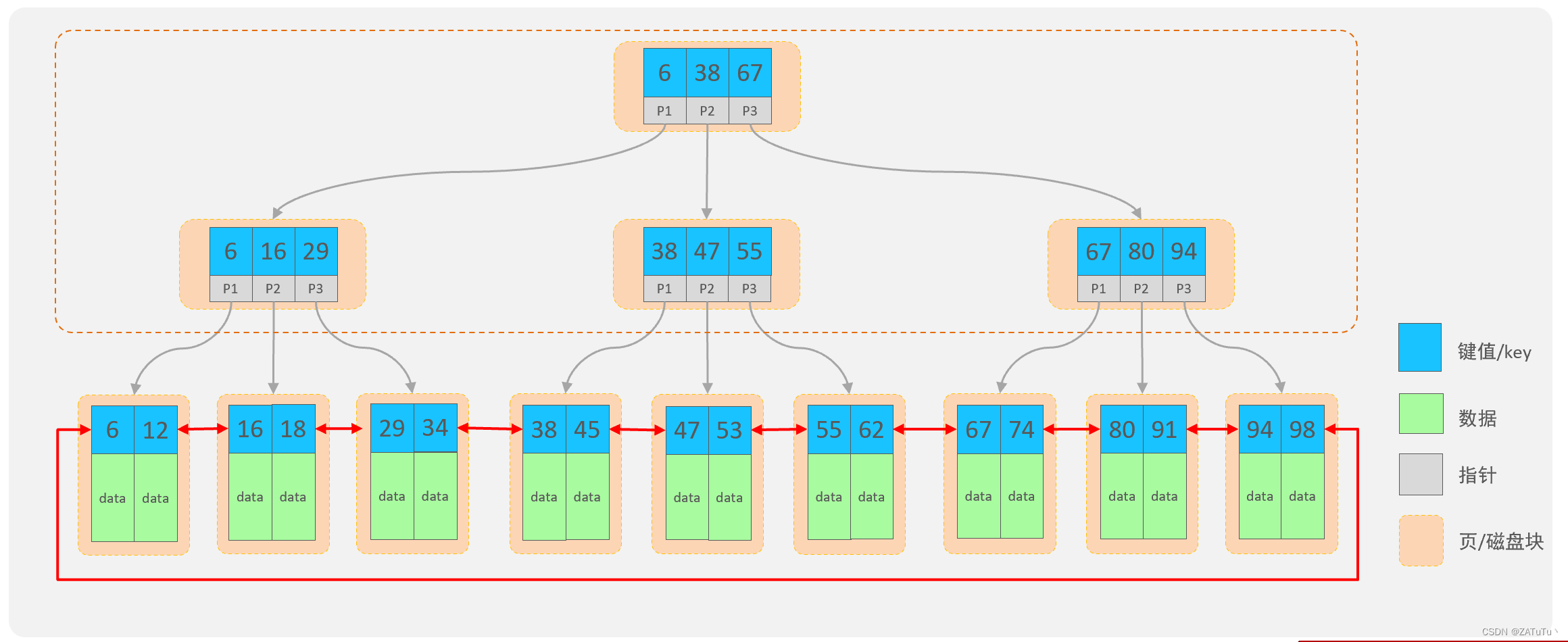
每个节点可以存储多个Key(有n个key就有n个指针)
所有数据都存储在叶子节点,非叶子节点仅用于索引数据
叶子节点形成一个双向链表,便于数据的排序以及区间范围的查询。
如下是B-Tree查询的伪代码
function search_btree(node, key):
// 在当前节点中查找 key
i = 1
while i <= node.num_keys and key > node.keys[i]:
i = i + 1
// 如果 key 等于节点中的某个 key,返回找到的节点
if i <= node.num_keys and key == node.keys[i]:
return node
// 如果是叶子节点,表示 key 不存在
if node.is_leaf:
return NULL
// 否则,继续在相应子节点中查找
else:
read child_node from disk at node.children[i]
return search_btree(child_node, key)
这个伪代码描述了 B-Tree 的查询操作。主要步骤包括:
在当前节点中查找给定的 key,找到一个最小的 i,使得 key 小于等于 node.keys[i]。
如果在当前节点中找到了 key,说明查询成功,返回当前节点。
如果在当前节点中未找到 key,且当前节点是叶子节点,表示 key 不存在,返回 NULL。
如果在当前节点中未找到 key,且当前节点不是叶子节点,进入相应的子节点,继续查找。
重复上述步骤,直到找到 key 或者到达叶子节点。
需要注意的是,B-Tree 的查询操作是一个递归过程,通过逐层查找直到叶子节点。这种策略可以在平均情况下保持 O(log n) 的时间复杂度,从而实现高效的数据检索。