学习数据血缘也好几个月了,网上的资料也看了很多,有了一些自己的理解,所以归纳一下,分享 出来,欢迎批评指正!
数据血缘是什么?
我觉得刚开始学习数据血缘肯定会有这样一个问题。比较官方、比较标准的解释是
数据血缘,是指数据的全生命周期中,数据从产生、处理、加工、融合、流转到最终消亡,
数据之间自然形成一种关系。其记录了数据产生的链路关系,
这些关系与人类的血缘关系比较相似,所以被成为数据血缘关系。
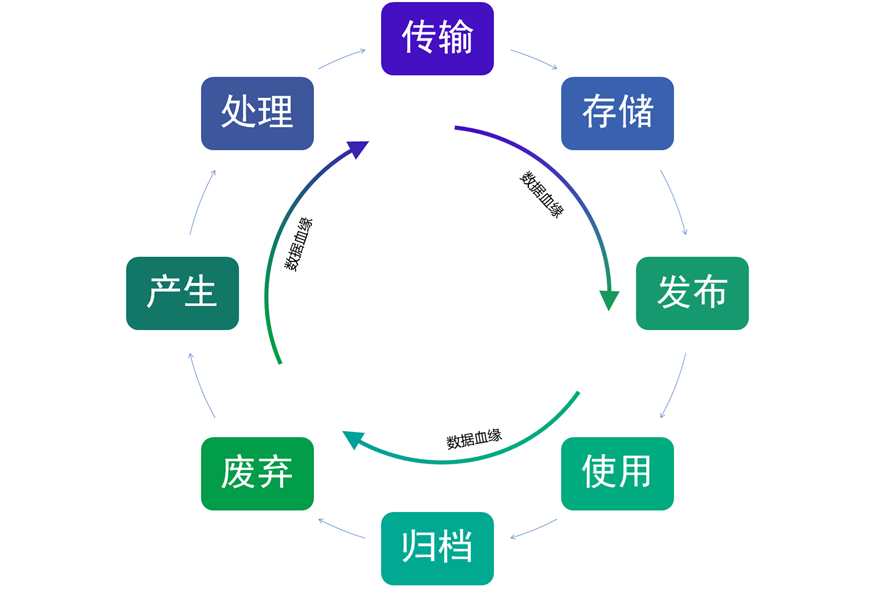
上面的解释可能有的抽象,我举个简单的例子
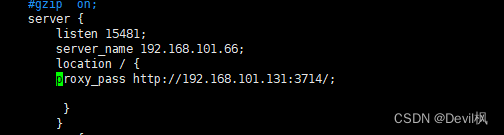
INSERT INTO student
(id, name, school_name)
SELECT
student_test.id,
student_test.name,
school.name
from student_test
global join school
on student_test.school_id = school.id;
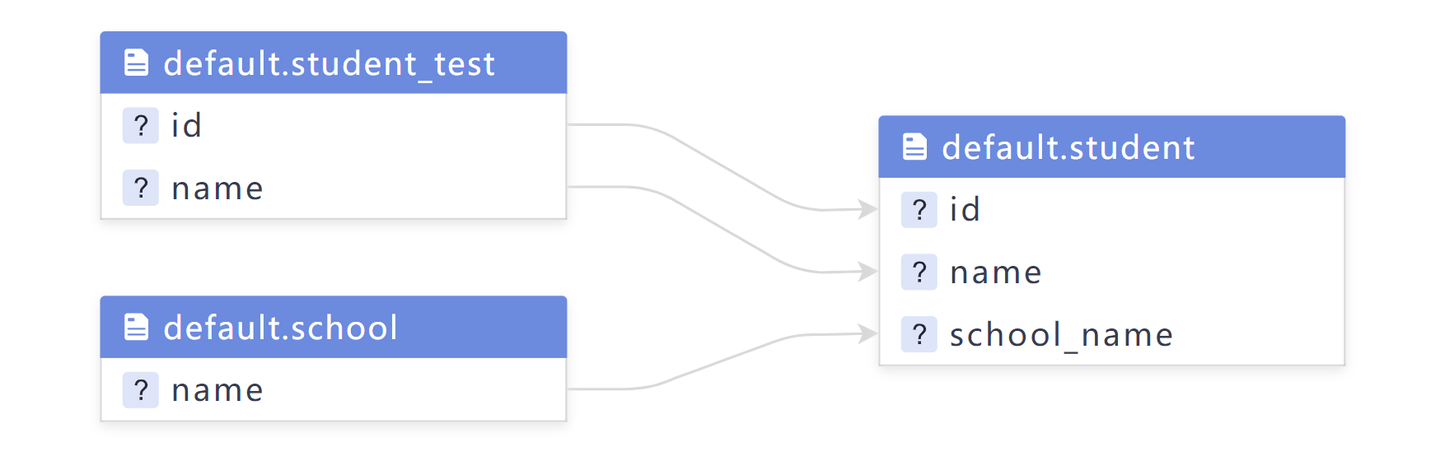
从上面的代码中,我们可以理解出student表的数据来自于student_test和school表,其字段层面的上下
级别关联关系,即字段血缘关系如下
数据血缘能用来干啥
数据溯源
依托于数据血缘的可塑性特点,根据血缘中的数据链路关系,可实现指定数据的来源、去向的追溯,可帮助用户理解数据含义、在全流程上定位数据问题、进行数据关联影响分析等,解决多层复杂逻辑处理后的数据难以理解、难以应用、出现问题难以定位的问题。
举个例子
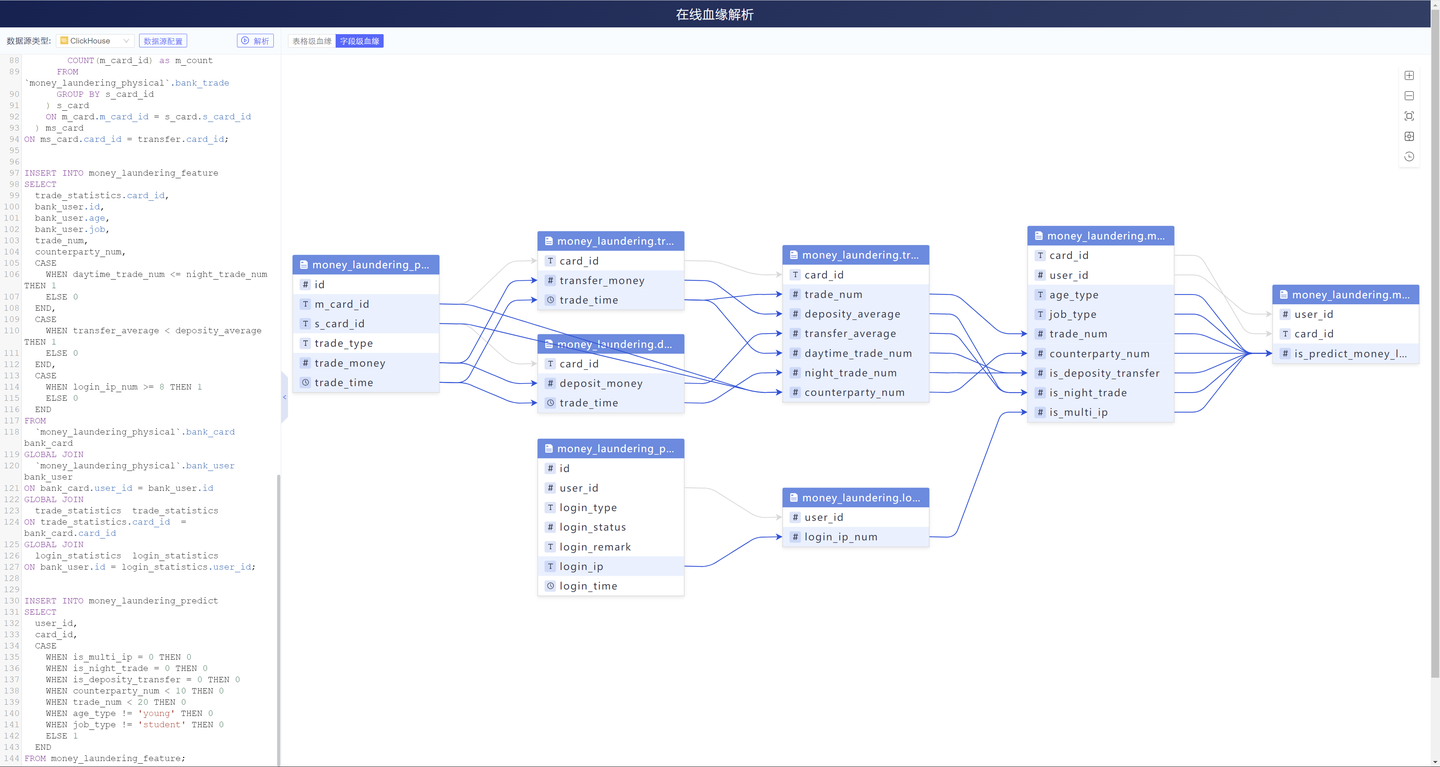
上面是一个较为复杂的字段血缘关系图,就不具体解释其业务含义。最后的is_predict_money_laundering
字段,是最后需要呈现的一个指标,通过字段血缘分析,可以很快速、高效得追溯出该字段与哪些字段相关联,
受哪些字段得影响,同时也可以帮助用户快速理解业务。
数据价值的评估
传统的数据价值评估,往往完全依靠相关法规要求和业务经验,缺少在具体应用场景中的评估依据,数据价值评
估脱离了数据的应用场景和真实的业务价值。而数据血缘则提供了一种基于数据实际应用的价值评估方法:使用者
越多(需求方)、使用量级越大、更新越频繁的数据往往更有价值。
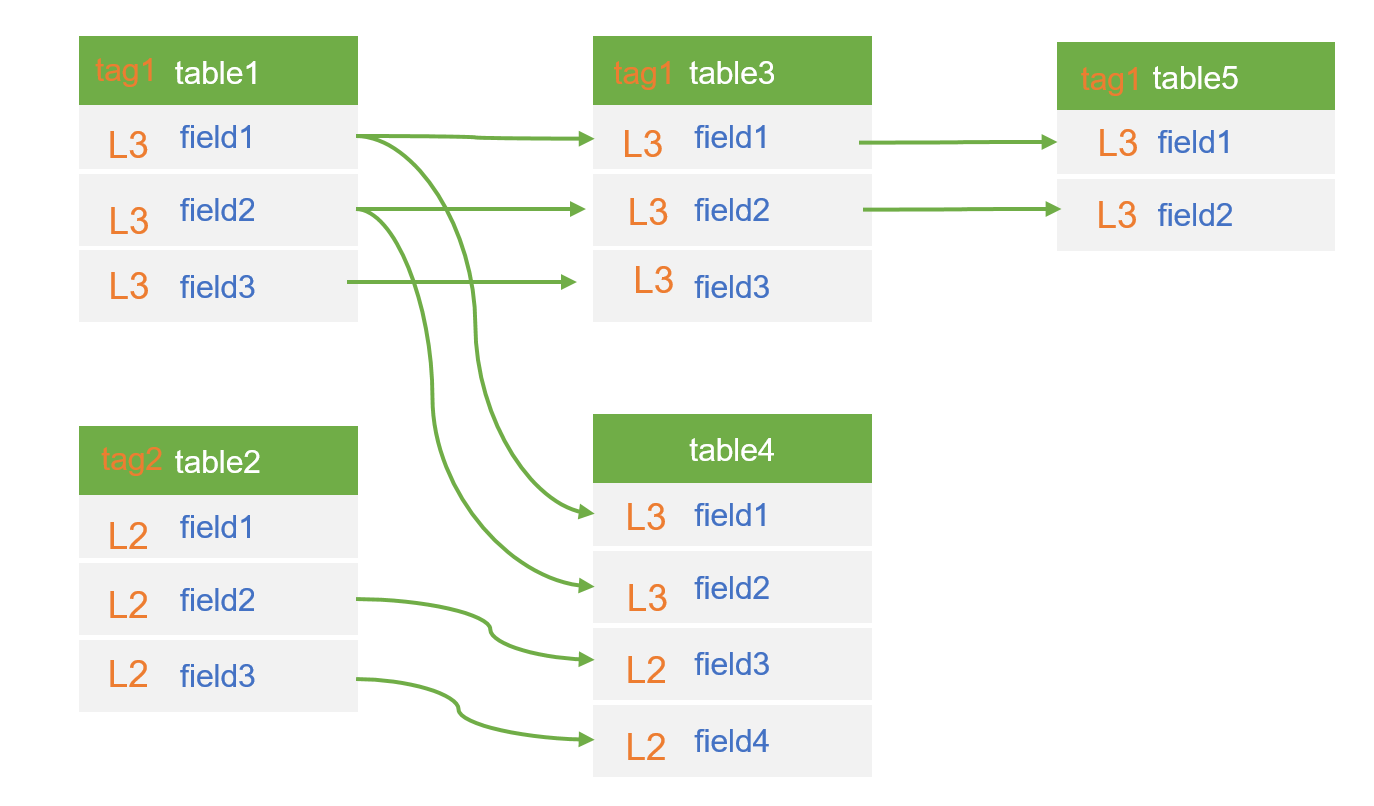
**1、数据受众:**在血缘关系图上,右边的数据流出节点表示受众,亦即数据需求方,数据需求方越多表示数据价值越大;
**2、数据更新量级:**数据血缘关系图中,数据流转线路的线条越粗,表示数据更新的量级越大,从一定程度上反映了数据价值的大小;
**3、数据更新频次:**数据更新越频繁,表示数据越鲜活,价值越高。在血缘关系图上,数据流转线路的线段越短,更新越频繁。
可以应用于数据治理,裁剪合并低价值表,缩短数据流ETL链路,从而降低维护成本,提升数据价值

数据打标
基于表血缘关系,可以自动为下游表打上与上游直系表相同的业务标签
同样基于字段血缘关系,可以自动为下游字段打上与上游直系字段相同的安全标签
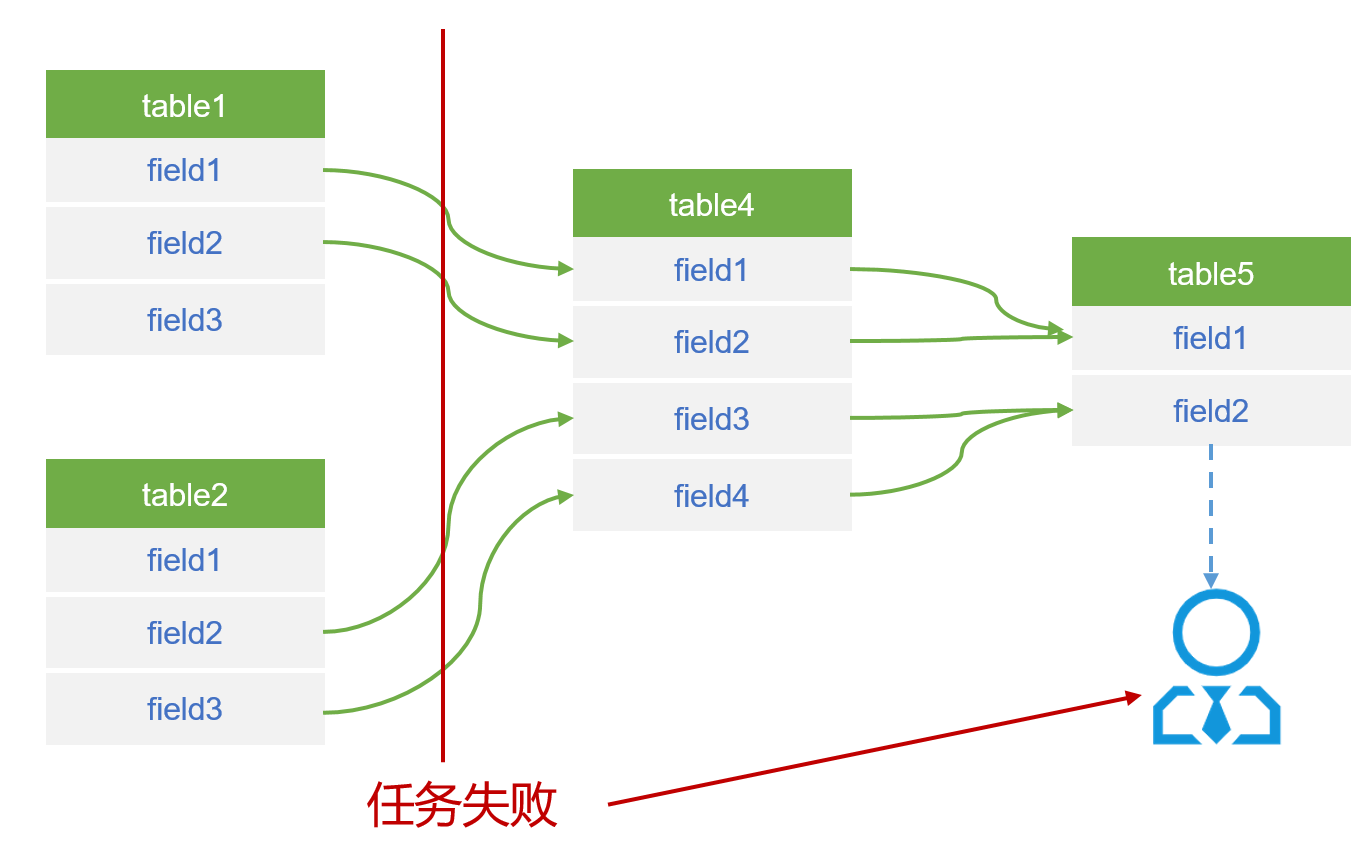
任务失败提示
数据质量中,上游任务失败或者字段发生变更时,通知下游表负责人
数据血缘与数据治理的关系
首先必须明确一点,数据血缘分析是数据治理的一个子范畴,上面也提到了,你可以基于血缘分析
的结果,进行数据链路的裁剪;进行数据溯源,快速定位问题的原因;在业务层面上,对数据进行
打标,从而对数据进行业务类别化。
数据血缘与数据质量的关系
其实我并不认为这两个有直接的关系。数据质量是去看数据有没有问题,某天的数据有没有丢失,
数据的同比、环比是不是正常。唯一可能有关联的是,某个数据质量的问题,会通过数据链路
进行扩散,我们需要借助血缘分析的结果,一步步得,有方向性得定位到质量有问题得数据根源。
数据血缘分析怎么做
数据血缘分析是我一直在投入做的事情,数据血缘分析,本质上是要对存储工具
(SQL、HIVE、SPARK、CLICKHOUSE)的查询语言, 进行有针对性的解析,从中解析出表血缘关系、字段血缘关系。
我自己做的一个数据血缘分析的工具,目前支持对clickhouse、mysql的血缘进行可视化解析,欢迎star
之江天枢/dlt
data_lineage_demo